Azure AI Studio を使用して Meta Llama モデルをデプロイする方法
重要
この記事で説明する機能の一部は、プレビューでのみ使用できる場合があります。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、Meta Llama モデルについて説明します。 また、Azure AI Studio を使用して、従量課金制でサーバーレス API またはマネージド コンピューティングに、このセットのモデルをデプロイする方法についても学習します。
重要
Azure AI モデル カタログで現在利用可能な Meta Llama 3 モデルの発表の詳細については、Microsoft Tech Community ブログと Meta 発表ブログをお読みください。
Meta Llama 3 のモデルとツールは、規模が 80 億から 700 億個のパラメーターの範囲の、事前トレーニングおよび微調整された生成テキスト モデルのコレクションです。 モデル ファミリには、人間のフィードバックによる強化学習 (RLHF) を使用した対話のユース ケース用に最適化された、Meta-Llama-3-8B-Instruct や Meta-Llama-3-70B-Instruct と呼ばれる微調整バージョンも含まれています。 次の GitHub サンプルを参照し、LangChain、LiteLLM、OpenAI、Azure API との統合を確認します。
Meta Llama モデルをサーバーレス API としてデプロイする
モデル カタログ内の特定のモデルは、従量課金制でサーバーレス API としてデプロイでき、企業のセキュリティとコンプライアンス組織のニーズを維持しながら、サブスクリプションでホストせずに API として使用する方法が提供されます。 このデプロイ オプションでは、サブスクリプションからのクォータを必要としません。
Meta Llama 3 モデルは、Microsoft Azure Marketplace を通じて従量課金制でサーバーレス API としてデプロイされ、使用条件と価格が追加される可能性があります。
Azure Marketplace モデルオファリング
従量課金制のサービスとしてデプロイするときは、Llama 3 のモデルを Azure Marketplace で入手できます。
別のモデルをデプロイする必要がある場合は、代わりにマネージド コンピューティングにデプロイします。
前提条件
有効な支払い方法を持つ Azure サブスクリプション。 無料または試用版の Azure サブスクリプションは機能しません。 Azure サブスクリプションを持っていない場合は、始めるために有料の Azure アカウントを作成してください。
-
重要
Meta Llama 3 モデルでは、従量課金制モデルのデプロイ オファリングは、米国東部 2 およびスウェーデン中部リージョンで作成されたハブでのみ利用できます。
Azure AI Studio の AI Studio プロジェクト。
Azure AI Studio での操作に対するアクセスを許可するには、Azure ロールベースのアクセス制御 (Azure RBAC) を使います。 この記事の手順を実行するには、ユーザー アカウントに、Azure サブスクリプションの所有者か共同作成者ロールを割り当てる必要があります。 別の方法として、アカウントに、次のアクセス許可を持つカスタム ロールを割り当てることができます。
Azure サブスクリプションで - 各プロジェクトについて 1 回、オファリングごとに、AI Studio プロジェクトを Azure Marketplace オファリングにサブスクライブするため:
Microsoft.MarketplaceOrdering/agreements/offers/plans/readMicrosoft.MarketplaceOrdering/agreements/offers/plans/sign/actionMicrosoft.MarketplaceOrdering/offerTypes/publishers/offers/plans/agreements/readMicrosoft.Marketplace/offerTypes/publishers/offers/plans/agreements/readMicrosoft.SaaS/register/action
リソース グループで - SaaS リソースを作成して使用するため:
Microsoft.SaaS/resources/readMicrosoft.SaaS/resources/write
AI Studio プロジェクトで - エンドポイントをデプロイするため (Azure AI 開発者ロールには、次のアクセス許可が既に含まれています):
Microsoft.MachineLearningServices/workspaces/marketplaceModelSubscriptions/*Microsoft.MachineLearningServices/workspaces/serverlessEndpoints/*
アクセス許可について詳しくは、「Azure AI Studio でのロールベースのアクセス制御」をご覧ください。
新しいデプロイを作成する
デプロイを作成するには:
Azure AI Studio にサインインします。
Azure AI Studio のモデル カタログからデプロイするモデルを選びます。
または、AI Studio でプロジェクトから開始して、デプロイを始めることもできます。 プロジェクトを選び、[デプロイ]>[+ 作成] を選択します。
モデルの [詳細] ページで、[デプロイ] を選択し、[Azure AI Content Safety を使用したサーバーレス API] を選びます。
モデルをデプロイするプロジェクトを選びます。 従量課金制モデルのデプロイ オファリングを使用するには、ワークスペースが米国東部 2 またはスウェーデン中部リージョンに属している必要があります。
デプロイ ウィザードで、リンク [Azure Marketplace の使用条件] を選択して、使用条件の詳細を確認します。 [Marketplace オファーの詳細] タブを選択して、選択したモデルの価格について確認することもできます。
プロジェクトにモデルを初めてデプロイする場合は、Azure Marketplace から特定のオファリング (Meta-Llama-3-70B など) 用のプロジェクトをサブスクライブする必要があります。 この手順は、前提条件に記載されている Azure サブスクリプションのアクセス許可とリソース グループのアクセス許可がアカウントに付与されていることを必要とします。 プロジェクトごとに、特定の Azure Marketplace オファリングへの固有のサブスクリプションがあり、それを使って支出を管理および監視できます。 [サブスクライブしてデプロイ] を選択します。
Note
プロジェクトを特定の Azure Marketplace オファリング (この場合、Meta-Llama-3-70B) にサブスクライブするには、プロジェクトが作成されるサブスクリプション レベルの共同作成者または所有者アクセス権をアカウントが持っている必要があります。 別の方法として、「前提条件」に記載されている Azure サブスクリプションのアクセス許可とリソース グループのアクセス許可を持つカスタム ロールをユーザー アカウントに割り当てることもできます。
特定の Azure Marketplace オファリングのプロジェクトにサインアップすると、"同じ" プロジェクト内の "同じ" オファリングの以降のデプロイで再度サブスクライブする必要はありません。 そのため、以降のデプロイに対するサブスクリプション レベルのアクセス許可を持つ必要はありません。 このシナリオが該当する場合は、[デプロイを続行] を選択します。
デプロイに名前を付けます。 この名前は、デプロイ API URL の一部になります。 この URL は、Azure リージョンごとに一意である必要があります。
展開 を選択します。 デプロイの準備ができるまで待つと、[デプロイ] ページにリダイレクトされます。
[プレイグラウンドで開く] を選んで、モデルの操作を始めます。
[デプロイ] ページに戻ってデプロイを選び、エンドポイントの [ターゲット] URL とシークレット [キー] を記録できます。これを使ってデプロイを呼び出し、入力候補を生成できます。
プロジェクト ページに移動し、左側のメニューから [デプロイ] を選択すれば、いつでもエンドポイントの詳細、URL、アクセス キーを確認できます。
従量課金制でデプロイされる Meta Llama モデルの課金については、「サービスとしてデプロイされた Llama 3 モデルのコストとクォータに関する考慮事項」を参照してください。




Meta Llama モデルをサービスとして使用する
サービスとしてデプロイされるモデルは、デプロイしたモデルの種類に応じて、チャットまたは入力候補 API を使用して消費できます。
プロジェクトまたはハブを選び、左側のメニューから [デプロイ] を選択します。
作成したデプロイを見つけて選択します。
[プレイグラウンドで開く] を選択します。
[コードの表示] を選び、[エンドポイント] の URL と [キー] の値をコピーします。
デプロイしたモデルの種類に基づいて API 要求を行います。
Meta-Llama-3-8Bなどの入力候補モデルの場合は、/completionsAPI を使用します。Meta-Llama-3-8B-Instructなどのチャット モデルの場合は、/chat/completionsAPI を使用します。
API の使用方法の詳細については、リファレンスのセクションを参照してください。
サービスとしてデプロイされた Meta Llama モデルのリファレンス
Llama モデルは、ルート /chat/completions の Azure AI Model Inference API または /v1/chat/completions の Llama Chat API の両方を受け入れます。 同様に、テキスト入力候補は、ルート /completions の Azure AI Model Inference API または /v1/completions の Llama Completions API を使って生成できます
Azure AI Model Inference API スキーマは、チャット入力候補のリファレンスの記事にあり、OpenAPI 仕様はエンドポイント自体から取得できます。
入力候補 API
メソッド POST を使用して、/v1/completions ルートに要求を送信します:
Request
POST /v1/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
要求スキーマ
ペイロードは、次のパラメーターを含む JSON 形式の文字列です:
| キー | Type | Default | 説明 |
|---|---|---|---|
prompt |
string |
既定値はありません。 この値は指定する必要があります。 | モデルに送信するプロンプト。 |
stream |
boolean |
False |
ストリーミングを使用すると、生成されたトークンが使用可能になるたびに、データのみのサーバー送信イベントとして送信できます。 |
max_tokens |
integer |
16 |
完了で生成されるトークンの最大数。 プロンプトのトークン数と max_tokens の合計は、モデルのコンテキスト長を超えることはできません。 |
top_p |
float |
1 |
核サンプリングと呼ばれる、温度によるサンプリングの代替の場合、モデルでは top_p 確率質量を持つトークンの結果が考慮されます。 したがって、0.1 は、上位 10% の確率質量を含むトークンのみが考慮されることを意味します。 一般に、top_p と temperature の両方ではなく、いずれかを変更することをお勧めします。 |
temperature |
float |
1 |
使うサンプリング温度 (0 から 2)。 値が大きいほど、モデルはトークンの分布をより広くサンプルすることを意味します。 ゼロは、最長一致のサンプリングを意味します。 これと top_p の両方ではなく、いずれかを変更することをお勧めします。 |
n |
integer |
1 |
プロンプトごとに生成する入力候補の数。 注: このパラメーターにより多くの入力候補が生成されるため、トークン クォータがすぐに消費される可能性があります。 |
stop |
array |
null |
API がそれ以降のトークンの生成を停止する単語を含む文字列または文字列のリスト。 返されるテキストに停止シーケンスは含まれません。 |
best_of |
integer |
1 |
サーバー側で best_of 入力候補を生成し、"最適なもの" (トークンあたりの対数確率が最低のもの) を返します。 結果をストリーミングすることはできません。 n とともに使用すると、best_of は入力候補の数を制御し、n は返す数を指定します。best_of は n より大きくする必要があります。 注: このパラメーターにより多くの入力候補が生成されるため、トークン クォータがすぐに消費される可能性があります。 |
logprobs |
integer |
null |
logprobs に含める、最も可能性の高いトークンと選択したトークンの対数確率を示す数値。 たとえば、logprobs が 10 の場合、API は最も可能性が高い 10 個のトークンの一覧を返します。 API は、常にサンプリングされたトークンの logprob を返します。そのため、応答には、最大 logprobs+ 1 個の要素が含まれる可能性があります。 |
presence_penalty |
float |
null |
-2.0 ~ 2.0 の数。 正の値は、新しいトークンがこれまでのテキストに表示されているかどうかに基づいてペナルティを課し、モデルが新しいトピックについて話す可能性を高めます。 |
ignore_eos |
boolean |
True |
EOS トークンを無視し、EOS トークンの生成後もトークンの生成を続行するかどうかを指定します。 |
use_beam_search |
boolean |
False |
サンプリングの代わりにビーム検索を使用するかどうかを指定します。 この場合、best_of は 1 より大きく、temperature は 0 である必要があります。 |
stop_token_ids |
array |
null |
生成されると、以降のトークンの生成を停止するトークンの ID の一覧。 返される出力には、停止トークンが特殊なトークンでない限り、停止トークンが含まれます。 |
skip_special_tokens |
boolean |
null |
出力内の特別なトークンをスキップするかどうかを指定します。 |
例
本文
{
"prompt": "What's the distance to the moon?",
"temperature": 0.8,
"max_tokens": 512
}
応答スキーマ
応答ペイロードは、次のフィールドを持つディクショナリです。
| キー | Type | 説明 |
|---|---|---|
id |
string |
チャット入力候補の一意識別子。 |
choices |
array |
入力プロンプト用にモデルが生成した入力候補の一覧。 |
created |
integer |
入力候補が作成されたときの Unix タイムスタンプ (秒単位)。 |
model |
string |
入力候補に使用される model_id。 |
object |
string |
オブジェクトの種類。これは常に text_completion です。 |
usage |
object |
入力候補要求の使用状況の統計情報。 |
ヒント
ストリーミング モードでは、応答のチャンクごとに、ペイロード [DONE] によって終了される最後のチャンクを除き、finish_reason は常に null です。
choices オブジェクトは、次のフィールドを持つディクショナリです。
| キー | Type | 説明 |
|---|---|---|
index |
integer |
選択肢インデックス。 best_of> 1 のとき、この配列内のインデックスは順序が整っていない可能性があり、0 から n-1 ではない可能性があります。 |
text |
string |
入力候補の結果。 |
finish_reason |
string |
モデルがトークンの生成を停止した理由。 - stop: モデルが自然な停止ポイント、または指定された停止シーケンスに達した場合。 - length: トークンの最大数に達した場合。 - content_filter: RAI がモデレートを行い、CMP がモデレーションを強制するとき。 - content_filter_error: モデレーション中にエラーが発生し、応答を決定できなかった場合。 - null: API 応答がまだ進行中であるか未完了の場合。 |
logprobs |
object |
出力テキスト内の生成されたトークンのログ確率。 |
usage オブジェクトは、次のフィールドを持つディクショナリです。
| キー | Type | Value |
|---|---|---|
prompt_tokens |
integer |
プロンプト内のトークンの数。 |
completion_tokens |
integer |
入力候補に生成されたトークンの数。 |
total_tokens |
integer |
トークンの合計数。 |
logprobs オブジェクトは、次のフィールドを持つディクショナリです:
| キー | Type | Value |
|---|---|---|
text_offsets |
array の integers |
入力候補出力内の各トークンの位置またはインデックス。 |
token_logprobs |
array の float |
top_logprobs 配列内のディクショナリから選択された logprobs。 |
tokens |
array の string |
選択されたトークン。 |
top_logprobs |
array の dictionary |
ディクショナリの配列。 各ディクショナリでは、キーはトークンであり、値は prob です。 |
例
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "text_completion",
"created": 217877,
"choices": [
{
"index": 0,
"text": "The Moon is an average of 238,855 miles away from Earth, which is about 30 Earths away.",
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 7,
"total_tokens": 23,
"completion_tokens": 16
}
}
チャット API
メソッド POST を使用して、/v1/chat/completions ルートに要求を送信します。
Request
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
要求スキーマ
ペイロードは、次のパラメーターを含む JSON 形式の文字列です:
| キー | Type | Default | 説明 |
|---|---|---|---|
messages |
string |
既定値はありません。 この値は指定する必要があります。 | モデルにプロンプトを表示するために使用するメッセージまたはメッセージの履歴。 |
stream |
boolean |
False |
ストリーミングを使用すると、生成されたトークンが使用可能になるたびに、データのみのサーバー送信イベントとして送信できます。 |
max_tokens |
integer |
16 |
完了で生成されるトークンの最大数。 プロンプトのトークン数と max_tokens の合計は、モデルのコンテキスト長を超えることはできません。 |
top_p |
float |
1 |
核サンプリングと呼ばれる、温度によるサンプリングの代替の場合、モデルでは top_p 確率質量を持つトークンの結果が考慮されます。 したがって、0.1 は、上位 10% の確率質量を含むトークンのみが考慮されることを意味します。 一般に、top_p と temperature の両方ではなく、いずれかを変更することをお勧めします。 |
temperature |
float |
1 |
使うサンプリング温度 (0 から 2)。 値が大きいほど、モデルはトークンの分布をより広くサンプルすることを意味します。 ゼロは、最長一致のサンプリングを意味します。 これと top_p の両方ではなく、いずれかを変更することをお勧めします。 |
n |
integer |
1 |
プロンプトごとに生成する入力候補の数。 注: このパラメーターにより多くの入力候補が生成されるため、トークン クォータがすぐに消費される可能性があります。 |
stop |
array |
null |
API がそれ以降のトークンの生成を停止する単語を含む文字列または文字列のリスト。 返されるテキストに停止シーケンスは含まれません。 |
best_of |
integer |
1 |
サーバー側で best_of 入力候補を生成し、"最適なもの" (トークンあたりの対数確率が最低のもの) を返します。 結果をストリーミングすることはできません。 n とともに使用すると、best_of は入力候補の数を制御し、n は返す数を指定します。best_of は n より大きくする必要があります。 注: このパラメーターにより多くの入力候補が生成されるため、トークン クォータがすぐに消費される可能性があります。 |
logprobs |
integer |
null |
logprobs に含める、最も可能性の高いトークンと選択したトークンの対数確率を示す数値。 たとえば、logprobs が 10 の場合、API は最も可能性が高い 10 個のトークンの一覧を返します。 API は、常にサンプリングされたトークンの logprob を返します。そのため、応答には、最大 logprobs+ 1 個の要素が含まれる可能性があります。 |
presence_penalty |
float |
null |
-2.0 ~ 2.0 の数。 正の値は、新しいトークンがこれまでのテキストに表示されているかどうかに基づいてペナルティを課し、モデルが新しいトピックについて話す可能性を高めます。 |
ignore_eos |
boolean |
True |
EOS トークンを無視し、EOS トークンの生成後もトークンの生成を続行するかどうかを指定します。 |
use_beam_search |
boolean |
False |
サンプリングの代わりにビーム検索を使用するかどうかを指定します。 この場合、best_of は 1 より大きく、temperature は 0 である必要があります。 |
stop_token_ids |
array |
null |
生成されると、以降のトークンの生成を停止するトークンの ID の一覧。 返される出力には、停止トークンが特殊なトークンでない限り、停止トークンが含まれます。 |
skip_special_tokens |
boolean |
null |
出力内の特別なトークンをスキップするかどうかを指定します。 |
messages オブジェクトには次のフィールドがあります:
| キー | Type | Value |
|---|---|---|
content |
string |
メッセージの内容。 すべてのメッセージにはコンテンツが必要です。 |
role |
string |
メッセージの作成者の役割。 system、user、または assistant のいずれか。 |
例
本文
{
"messages":
[
{
"role": "system",
"content": "You are a helpful assistant that translates English to Italian."},
{
"role": "user",
"content": "Translate the following sentence from English to Italian: I love programming."
}
],
"temperature": 0.8,
"max_tokens": 512,
}
応答スキーマ
応答ペイロードは、次のフィールドを持つディクショナリです。
| キー | Type | 説明 |
|---|---|---|
id |
string |
チャット入力候補の一意識別子。 |
choices |
array |
入力メッセージ用にモデルが生成した入力候補の一覧。 |
created |
integer |
入力候補が作成されたときの Unix タイムスタンプ (秒単位)。 |
model |
string |
入力候補に使用される model_id。 |
object |
string |
オブジェクトの種類。これは常に chat.completion です。 |
usage |
object |
入力候補要求の使用状況の統計情報。 |
ヒント
ストリーミング モードでは、応答のチャンクごとに、ペイロード [DONE] によって終了される最後のチャンクを除き、finish_reason は常に null です。 各 choices オブジェクトで、messages のキーは delta で変更されます。
choices オブジェクトは、次のフィールドを持つディクショナリです。
| キー | Type | 説明 |
|---|---|---|
index |
integer |
選択肢インデックス。 best_of> 1 のとき、この配列内のインデックスは順序が整っていない可能性があり、0 から n-1 ではない可能性があります。 |
messages または delta |
string |
messages オブジェクトのチャットの入力候補結果。 ストリーミング モードを使用する場合は、 delta キーが使用されます。 |
finish_reason |
string |
モデルがトークンの生成を停止した理由。 - stop: モデルが自然な停止ポイント、または指定された停止シーケンスに達した場合。 - length: トークンの最大数に達した場合。 - content_filter: RAI がモデレートを行い、CMP がモデレーションを強制するとき - content_filter_error: モデレーション中にエラーが発生し、応答を決定できなかった場合 - null: API 応答がまだ進行中であるか未完了の場合。 |
logprobs |
object |
出力テキスト内の生成されたトークンのログ確率。 |
usage オブジェクトは、次のフィールドを持つディクショナリです。
| キー | Type | Value |
|---|---|---|
prompt_tokens |
integer |
プロンプト内のトークンの数。 |
completion_tokens |
integer |
入力候補に生成されたトークンの数。 |
total_tokens |
integer |
トークンの合計数。 |
logprobs オブジェクトは、次のフィールドを持つディクショナリです:
| キー | Type | Value |
|---|---|---|
text_offsets |
array の integers |
入力候補出力内の各トークンの位置またはインデックス。 |
token_logprobs |
array の float |
top_logprobs 配列内のディクショナリから選択された logprobs。 |
tokens |
array の string |
選択されたトークン。 |
top_logprobs |
array の dictionary |
ディクショナリの配列。 各ディクショナリでは、キーはトークンであり、値は prob です。 |
例
次に応答の例を示します。
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "chat.completion",
"created": 2012359,
"model": "",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Sure, I\'d be happy to help! The translation of ""I love programming"" from English to Italian is:\n\n""Amo la programmazione.""\n\nHere\'s a breakdown of the translation:\n\n* ""I love"" in English becomes ""Amo"" in Italian.\n* ""programming"" in English becomes ""la programmazione"" in Italian.\n\nI hope that helps! Let me know if you have any other sentences you\'d like me to translate."
}
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 40,
"completion_tokens": 30
}
}
Meta Llama モデルをマネージド コンピューティングにデプロイする
従量課金制のマネージド サービスを使用したデプロイとは別に、AI Studio で Meta Llama モデルをマネージド コンピューティングにデプロイすることもできます。 マネージド コンピューティングにデプロイするときは、使用する仮想マシンや、予想される負荷を処理するインスタンスの数などの、モデルを実行するインフラストラクチャに関するすべての詳細を選択できます。 マネージド コンピューティングにデプロイされるモデルでは、サブスクリプションからのクォータが使用されます。 Llama ファミリのすべてのモデルをマネージド コンピューティングにデプロイできます。
Azure AI Studio でリアルタイム エンドポイントに Llama-2-7b-chat などのモデルをデプロイするには、次の手順のようにします。
Azure AI Studio のモデル カタログからデプロイするモデルを選びます。
または、AI Studio でプロジェクトから開始して、デプロイを始めることもできます。 プロジェクトを選び、[デプロイ]>[+ 作成] を選択します。
モデルの [詳細] ページで、[ライセンスの表示] ボタンの横にある [デプロイ] を選択します。
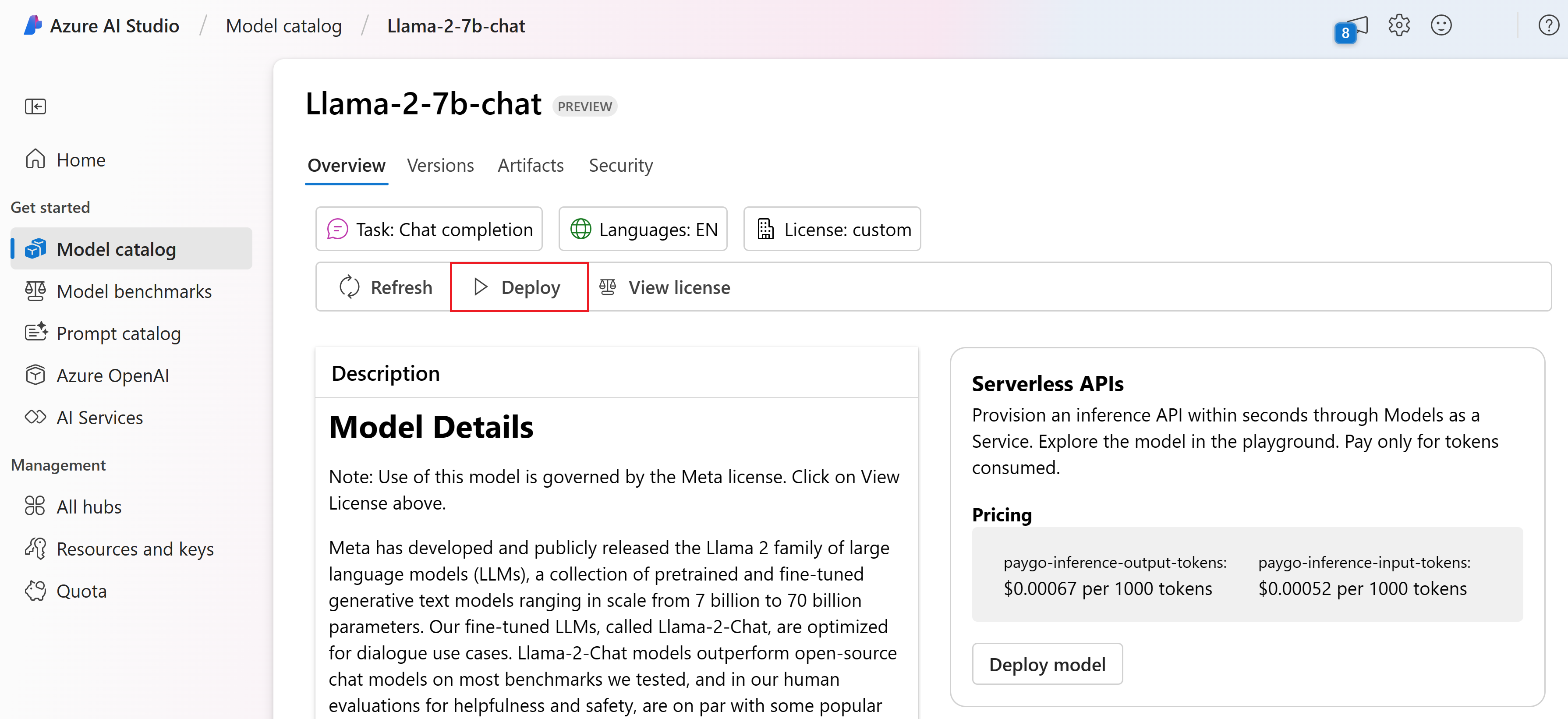
[Azure AI Content Safety でデプロイ (プレビュー)] ページで、[Skip Azure AI Content Safety] (Azure AI Content Safety をスキップする) を選択して、UI を使用したモデルのデプロイに進みます。
ヒント
一般に、Llama モデルのデプロイには [Azure AI Content Safety を有効にする (推奨)] を選択することをお勧めします。 このデプロイ オプションは現在、Python SDK を使用することでのみサポートされていて、ノートブックで行われます。
[続行] を選択します。
デプロイを作成するプロジェクトを選択します。
ヒント
選択したプロジェクトで十分なクォータを使用できない場合は、「共有クォータを使用するオプションを使用します。このエンドポイントは 168 時間以内に削除されることを確認します」オプションを使用できます。
デプロイに割り当てる [仮想マシン] と、[インスタンス数] を選択します。
このデプロイを新しいエンドポイントまたは既存のエンドポイントの一部として作成するかどうかを選択します。 エンドポイントは、複数のデプロイをホストしながら、リソース構成をデプロイごとに固有になるように維持できます。 同じエンドポイントの下のデプロイでは、エンドポイント URI とそのアクセス キーが共有されます。
推論データ収集 (プレビュー) を有効にするかどうかを指定します。
展開 を選択します。 しばらくすると、エンドポイントの [詳細] ページが開きます。
エンドポイントの作成とデプロイが完了するまで待ちます。 このステップには数分かかる場合があります。
デプロイの [使用] タブを選んで、デプロイされたモデルをアプリケーションで使うために使用できるコード サンプルを取得します。

マネージド コンピューティングにデプロイされた Llama 2 モデルを使用する
マネージド コンピューティングにデプロイされた Llama モデルを呼び出す方法については、Azure AI Studio のモデル カタログでモデルのカードを参照してください。 各モデルのカードには、モデルの説明、コード ベースの推論のサンプル、微調整、モデル評価を含む概要ページがあります。
推論のその他の例
| Package | サンプル ノートブック |
|---|---|
| CURL および Python Web 要求を使用した CLI - Command R | command-r.ipynb |
| CURL および Python Web 要求を使用した CLI - Command R+ | command-r-plus.ipynb |
| OpenAI SDK (試験段階) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Cohere SDK | cohere-sdk.ipynb |
| LiteLLM SDK | litellm.ipynb |
コストとクォータ
サービスとしてデプロイされる Llama モデルのコストとクォータに関する考慮事項
サービスとしてデプロイされた Llama モデルは、Azure Marketplace を通じて Meta によって提供され、使用するために Azure AI Studio と統合されます。 モデルをデプロイまたはモデルを微調整するときに、Azure Marketplace の価格を確認できます。
プロジェクトが Azure Marketplace から特定のオファーにサブスクライブするたびに、その消費に関連するコストを追跡するための新しいリソースが作成されます。 推論と微調整に関連するコストを追跡するために同じリソースが使用されますが、各シナリオを個別に追跡するために複数の測定値を使用できます。
コストの追跡方法について詳しくは、「Azure Marketplace を通じて提供されるモデルのコストを監視する」をご覧ください。

クォータはデプロイごとに管理されます。 各デプロイのレート制限は、1 分あたり 200,000 トークン、1 分あたり 1,000 個の API 要求です。 ただし、現在、プロジェクトのモデルごとに 1 つのデプロイに制限しています。 現在のレート制限がシナリオに十分でない場合は、Microsoft Azure サポートにお問い合わせください。
マネージド コンピューティングとしてデプロイされる Llama モデルのコストとクォータに関する考慮事項
マネージド コンピューティングを使用した Llama モデルのデプロイと推論には、リージョンごとにサブスクリプションに割り当てられている仮想マシン (VM) コア クォータを使います。 Azure AI Studio にサインアップすると、リージョンで使用可能な複数の VM ファミリに対する既定の VM クォータを受け取ります。 クォータ制限に達するまで、デプロイを作成し続けることができます。 この制限に達したら、クォータの引き上げを要求できます。
コンテンツのフィルター処理
従量課金制でサーバーレス API としてデプロイされるモデルは、Azure AI Content Safety によって保護されます。 マネージド コンピューティングにデプロイする場合は、この機能をオプトアウトできます。 Azure AI Content Safety を有効にすると、プロンプトと入力候補の両方が、有害なコンテンツ出力の検出と防止を目的とした一連の分類モデルを通過します。 コンテンツ フィルタリング システムは、入力プロンプトと (出力される) 入力候補の両方で、有害な可能性があるコンテンツ特有のカテゴリを検出し、アクションを実行します。 Azure AI Content Safety の詳細を確認します。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示