Azure Kubernetes Service (AKS) でアプリケーションを実行する場合は、クラスター内のコンピューティング リソースの量を積極的に増減することが必要になる場合があります。 アプリケーション インスタンスの数を変更する際に、基になる Kubernetes ノードの数を変更することが必要になる場合があります。 また、多数の他のアプリケーション インスタンスをプロビジョニングする必要がある場合もあります。
この記事では、ポッドまたはノードの手動スケーリング、ポッドの水平オート スケーラの使用、クラスター オート スケーラーの使用、Azure Container Instances (ACI) との統合など、AKS アプリケーションでのスケーリングの主要な概念について説明します。
ポッドまたはノードを手動でスケーリングする
レプリカ、つまり、ポッドとノードを手動でスケーリングし、使用可能なリソースと状態の変化に対するアプリケーションの対応をテストできます。 リソースを手動でスケーリングすると、固定コストを維持するために使用するリソースのセット量 (ノード数など) を定義できます。 手動でスケーリングするには、レプリカまたはノード数を定義します。 その後、Kubernetes API は、そのレプリカまたはノード数に基づいて、より多くのポッドの作成またはノードのドレインをスケジュールします。
ノードをスケールダウンすると、Kubernetes API は、クラスターで使用されるコンピューティングの種類に関連付けられている関連する Azure Compute API を呼び出します。 たとえば、仮想マシン スケール セット上に構築されたクラスターの場合、削除するノードは仮想マシン スケール セット API によって決定されます。 スケールダウン時に削除対象のノードがどのように選択されるかの詳細については、「Virtual Machine Scale Sets の FAQ」を参照してください。
ノードの手動スケーリングを始めるには、AKS クラスターでのノードの手動スケーリングに関する記事をご覧ください。 ポッドの数の手動スケーリングについては、kubectl scale コマンドに関するページをご覧ください。
ポッドの水平オートスケーラー
Kubernetes は、ポッドの水平オートスケーラー (HPA) を使用して、リソース需要を監視し、ポッドの数を自動的にスケーリングします。 既定では、HPA はレプリカ数の必要な変更についてメトリック API を 15 秒ごとにチェックしますが、Metrics API は 60 秒ごとに Kubelet からデータを取得します。 その結果、HPA は 60 秒ごとに更新されます。 変更が必要な場合は、それに応じてレプリカの数がスケーリングされます。 HPA は、Kubernetes バージョン 1.8 以降の Metrics Server をデプロイした AKS クラスターと連携します。
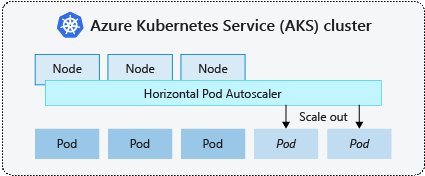
所定のデプロイ用に HPA を構成する場合、実行できるレプリカの最小値と最大数を定義します。 また、CPU 使用率など、監視およびスケーリングの決定に基づくメトリックも定義します。
AKS でポッドの水平オートスケーラーを開始するには、「ポッドを自動スケールする」を参照してください。
スケーリング イベントのクールダウン
HPA は 60 秒ごとに効果的に更新されるため、別のチェックが行われる前に、以前のスケール イベントが正常に完了しなかった可能性があります。 この動作のため、前のスケーリング イベントでアプリケーションのワークロードとリソースの需要を受け取ってそれに応じて調整できるようになる前に、HPA によってレプリカの数が変更される可能性があります。
競合イベントを最小限に抑えるために、遅延値が設定されます。 この値は、HPA がスケーリング イベント後に別のスケーリング イベントをトリガーできるまで待機する必要のある時間を定義します。 この動作により、新しいレプリカ数が有効になり、メトリックの API で配分されたワークロードを反映できるようになります。 Kubernetes 1.12 の時点では、スケールアップ イベントに遅延はありません。 ただし、スケール ダウン イベントの既定の遅延は 5 分です。
クラスター オートスケーラー
ポッドの需要の変化に対応するために、Kubernetes クラスター オートスケーラーは、ノード プール内で要求されるコンピューティング リソースに基づいてノードの数を調整します。 既定では、クラスター オートスケーラーは、必要なノード数の変更についてメトリック API サーバーを 10 秒ごとに確認します。 クラスター オートスケーラーで変更が必要だと判断されると、それに応じて AKS クラスター内のノードの数が増減されます。 クラスターオートスケーラーは、Kubernetes 1.10.x 以降を実行する Kubernetes RBAC 対応 AKS クラスターで動作します。
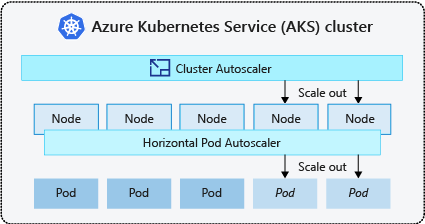
クラスター オートスケーラーは通常、ポッドの水平オートスケーラーと一緒に使用されます。 組み合わせた場合、ポッドの水平オートスケーラーはアプリケーションのポッド数を増減し、クラスター オートスケーラーは、これらの追加ポッドの実行に必要になるノードの数を調整します。
AKS でクラスター オートスケーラーを開始するには、「Azure Kubernetes Service のクラスター オートスケーラー (AKS) - プレビュー」を参照してください。
スケールアウト イベント
ノードに、要求されたポッドを実行するために十分なコンピューティング リソースがない場合、そのポッドではスケジューリング プロセスを進めることができません。 ノード プール内で使用可能なコンピューティング リソースが増えない限り、ポッドを起動できません。
ノード プールのリソース制約のためにスケジュール設定できないポッドが、クラスター オートスケーラーによって検出されると、追加のコンピューティング リソースを提供するため、ノード プール内のノードの数が増やされます。 ノードが正常にデプロイされ、ノード プール内で使用できるようになると、それらで実行するようにポッドがスケジュールされます。
アプリケーションを迅速にスケーリングする必要がある場合、一部のポッドは、クラスター オートスケーラーによってデプロイされたより多くのノードがスケジュールされたポッドを受け入れるまで、スケジュールされるのを待っている状態のままになることがあります。 高いバースト需要のあるアプリケーションの場合、仮想ノードと Azure Container Instances でスケーリングできます。
スケールイン イベント
クラスター オートスケーラーでは、最近新しいスケジュール要求を受け取っていないノードのポッド スケジューリング状態も監視されます。 このシナリオでは、ノード プールに必要以上のコンピューティング リソースがあり、ノードの数を削減できることが示されます。 10分間不要であるというしきい値を超えたノードは、既定では削除がスケジュールされます。 このような状況が発生した場合、ポッドは、ノード プール内の他のノードで実行するようにスケジュール設定され、クラスター オートスケーラーは、ノードの数を減らします。
クラスター オートスケーラーがノードの数を減らしたときに、ポッドは別のノード上にスケジュール設定されるので、アプリケーションに何からの中断が発生することがあります。 中断を最小限に抑えるには、単一のポッド インスタンスを使用するアプリケーションを使用しないでください。
Kubernetes イベント駆動型自動スケーリング (KEDA)
Kubernetes Event-driven Autoscaling (KEDA) は、ワークロードのイベントドリブン自動スケーリング用のオープンソース コンポーネントです。 受け取ったイベントの数に基づいてワークロードを動的にスケーリングします。 KEDA は、ScaledObject と呼ばれるカスタム リソース定義 (CRD) を使用して、特定のトラフィックに応じてどのようにアプリケーションをスケーリングするかを記述するよう Kubernetes を拡張します。
KEDA スケーリングは、ワークロードでトラフィックのバーストが発生したり、大量のデータを処理したりするシナリオで役立ちます。 KEDA はイベントドリブンであり、イベントの数に基づいてスケーリングされるのに対し、HPA はリソース使用率 (CPU やメモリなど) に基づいてメトリックに基づくため、KEDA はポッドの水平オートスケーラーとは異なります。
AKS で KEDA アドオンの使用を開始するには、KEDA の概要に関する記事を参照してください。
ノードの自動プロビジョニング
ノード自動プロビジョニング (プレビュー) (NAP) では、AKS クラスターで Karpenter を自動的にデプロイ、構成、管理するオープン ソースの Karpenter プロジェクトが使用されます。 NAP は、保留中のポッド リソース要件に基づいてノードを動的にプロビジョニングします。リアルタイムの需要を満たすために、最適な仮想マシン (VM) SKU と数量が自動的に選択されます。
NAP は、保留中のワークロードに最適な SKU を決定するための開始点として、定義済みの VM SKU の一覧を取得します。 より正確な制御のために、ユーザーはノード プールで使用されるリソースの上限と、複数のノード プールがある場合にワークロードをスケジュールする必要がある場所の基本設定を定義できます。
コントロール プレーンのスケーリングとセーフガード
Kubernetes には、ディメンションを表す各リソースの種類を含む多次元スケール エンベロープがあります。 すべてのリソースが似ているわけではありません。 たとえば、シークレットに対してウォッチが設定されることが一般的であり、その結果、kube-apiserverへのリスト呼び出しが行われ、コストが増加します。これは、ウォッチが設定されていないリソースに比べてコントロールプレーンに不均衡な負荷をもたらします。
コントロール プレーンはクラスター内のすべてのリソース スケーリングを管理するため、特定のディメンション内でクラスターをスケーリングするほど、他のディメンション内でのスケーリングは少なくなります。 たとえば、AKS クラスターで数十万個のポッドを実行すると、コントロール プレーンでサポートできるポッドのチャーンレート (ポッドの 1 秒あたりの変化) の量に影響します。 ベスト プラクティスを参照してください。
AKS は、クラスター内のコアの合計数や、コントロール プレーン コンポーネントの CPU またはメモリ負荷などの主要な信号に基づいて、コントロール プレーン コンポーネントを自動的にスケーリングします。
コントロール プレーンがスケールアップされたかどうかを確認するには、"large-cluster-control-plane-scaling-status" という名前の ConfigMap を確認します
kubectl describe configmap large-cluster-control-plane-scaling-status -n kube-system
コントロール プレーン セーフガード
高負荷のシナリオで API サーバーを自動的にスケーリングしても安定しない場合、AKS はマネージド API サーバー ガードをデプロイします。 このガードは、システム以外のクライアント要求を調整し、コントロール プレーンが完全に応答しなくなるのを防ぐことで、API サーバーを保護するための最後の手段として機能します。 kubelet などのコンポーネントからの API サーバーへのシステム クリティカルな呼び出しは、引き続き正常に機能します。
マネージド API サーバー ガードが適用されているかどうかを確認するには、 "aks-managed-apiserver-guard" FlowSchema と PriorityLevelConfiguration が存在するかどうかを確認します。
kubectl get flowschemas
kubectl get prioritylevelconfigurations
迅速な軽減のため、クラスターに "aks-managed-apiserver-guard" FlowSchema と PriorityLevelConfiguration が適用されている場合は、API サーバーと Etcd トラブルシューティング ガイドを参照してください。
Azure Container Instances (ACI) へのバースト
AKS クラスターを迅速にスケーリングするために、Azure Container Instances (ACI) と統合できます。 Kubernetes には、レプリカおよびノード数をスケーリングするコンポーネントが組み込まれています。 ただし、アプリケーションを迅速にスケーリングする必要がある場合は、 ポッドの水平オートスケーラー によって、ノード プール内の既存のコンピューティング リソースでサポートできるよりも多くのポッドがスケジュールされる可能性があります。 このシナリオを構成すると、 クラスター オートスケーラー がノード プールにさらに多くのノードをデプロイするようにトリガーされますが、それらのノードが正常にプロビジョニングされ、Kubernetes スケジューラでポッドが実行されるまでに数分かかる場合があります。
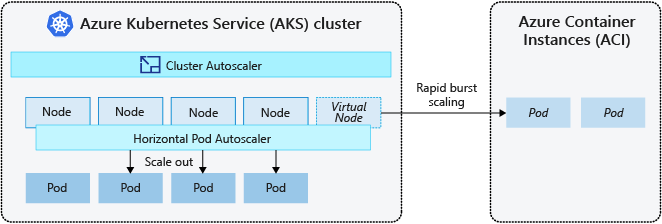
ACI を使うと、インフラストラクチャのオーバーヘッドを増やすことなく、コンテナー インスタンスを迅速にデプロイできます。 AKS で接続する場合、ACI は、AKS クラスターのセキュリティ保護された論理拡張機能になります。 仮想ノード コンポーネントは仮想 Kubelet に基づいており、仮想 Kubernetes ノードとして ACI を提示する AKS クラスターにインストールされます。 Kubernetes は続いて、直接 AKS クラスター内にある VM ノード上のポッドとしてではなく、仮想ノードを通じた ACI インスタンスとして実行するポッドをスケジュール設定できます。
アプリケーションは、仮想ノードを使用するために変更は不要です。 クラスター オートスケーラーが AKS クラスター内に新しいノードをデプロイするときに、デプロイは AKS と ACI にわたって遅延なくスケーリングできます。
仮想ノードは、AKS クラスターと同じ仮想ネットワーク内のその他のサブネットにデプロイされます。 この仮想ネットワーク構成は、ACI と AKS 間のトラフィックをセキュリティで保護します。 AKS クラスターと同様に、ACI インスタンスは、他のユーザーから分離されたセキュリティ保護された論理的なコンピューティング リソースです。
次のステップ
アプリケーションのスケーリングを始めるには、次のリソースを参照してください。
- ポッドまたはノードを手動でスケーリングする
- ポッドの水平オートスケーラーを使用する
- クラスター オートスケーラーを使用する
- Kubernetes Event-driven Autoscaling (KEDA) アドオンを使用する
Kubernetes と AKS の中心概念の詳細については、次の記事を参照してください。