この記事では、Azure Kubernetes Service (AKS) 上の Valkey クラスターの回復性を検証する方法について説明します。
注
この記事には、Microsoft が既に使用しなくなった "マスター" という用語への言及が含まれています。 Valkey ソフトウェアからこの用語が削除された時点で、この記事から削除します。
Valkey 用のサンプル クライアント アプリケーションをビルドして実行する
次の手順では、Valkey 用のサンプル クライアント アプリケーションをビルドし、アプリケーションの Docker イメージを Azure Container Registry (ACR) にプッシュする方法を示しています。
サンプル クライアント アプリケーションでは、Locust ロード テスト フレームワークを使用して、Valkey クラスターでワークロードをシミュレートします。
Dockerfile と requirements.txt を作成し、次のコマンドを使用して新しいディレクトリに配置します。
mkdir valkey-client cd valkey-client cat > Dockerfile <<EOF FROM python:3.10-slim-bullseye COPY requirements.txt . COPY locustfile.py . RUN pip install --upgrade pip && pip install --no-cache-dir -r requirements.txt EOF cat > requirements.txt <<EOF valkey locust EOF次の内容を含む
locustfile.pyファイルを作成します。cat > locustfile.py <<EOF import time from locust import between, task, User, events,tag, constant_throughput from valkey import ValkeyCluster from random import randint class ValkeyLocust(User): wait_time = constant_throughput(50) host = "valkey-cluster.valkey.svc.cluster.local" def __init__(self, *args, **kwargs): super(ValkeyLocust, self).__init__(*args, **kwargs) self.client = ValkeyClient(host=self.host) def on_stop(self): self.client.close() @task @tag("set") def set_value(self): self.client.set_value("set_value") @task @tag("get") def get_value(self): self.client.get_value("get_value") class ValkeyClient(object): def __init__(self, host, *args, **kwargs): super().__init__(*args, **kwargs) with open("/etc/valkey-password/valkey-password-file.conf", "r") as f: self.password = f.readlines()[0].split(" ")[1].strip() self.host = host self.vc = ValkeyCluster(host=self.host, port=6379, password=self.password, username="default", cluster_error_retry_attempts=0, socket_timeout=2, keepalive=1 ) def set_value(self, key, command='SET'): start_time = time.perf_counter() try: result = self.vc.set(randint(0, 1000), randint(0, 1000)) if not result: result = '' length = len(str(result)) total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=length, ) except Exception as e: total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=0, exception=e ) result = '' return result def get_value(self, key, command='GET'): start_time = time.perf_counter() try: result = self.vc.get(randint(0, 1000)) if not result: result = '' length = len(str(result)) total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=length, ) except Exception as e: total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=0, exception=e ) result = '' return result EOFこの Python コードは、Valkey クラスターに接続し、"設定と取得" 操作を実行する、Locust ユーザー クラスを実装します。 このクラスを拡張して、より複雑な操作を実装できます。
Docker イメージをビルドし、
az acr buildコマンドを使用して ACR にアップロードします。az acr build --image valkey-client --registry ${MY_ACR_REGISTRY} .
Azure Kubernetes Service (AKS) 上の Valkey クラスターをテストする
kubectl applyコマンドを使用して、前の手順でビルドした Valkey クライアント イメージを使用するPodを作成します。 ポッド スペックには、クライアントが Valkey クラスターへの接続に使用する Valkey パスワードを含むシークレット ストア CSI ボリュームが含まれています。kubectl apply -f - <<EOF --- kind: Pod apiVersion: v1 metadata: name: valkey-client namespace: valkey spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: agentpool operator: In values: - nodepool1 containers: - name: valkey-client image: ${MY_ACR_REGISTRY}.azurecr.io/valkey-client command: ["locust", "--processes", "4"] volumeMounts: - name: valkey-password mountPath: "/etc/valkey-password" volumes: - name: valkey-password csi: driver: secrets-store.csi.k8s.io readOnly: true volumeAttributes: secretProviderClass: "valkey-password" EOFkubectl port-forwardコマンドを使用して、ポート 8089 をポート転送して、ローカル コンピューター上の Locust Web インターフェイスにアクセスします。kubectl port-forward -n valkey valkey-client 8089:8089http://localhost:8089の、Locust Web インターフェイスにアクセスしてテストを開始します。 ユーザーの数と生成速度を調整して、Valkey クラスターのワークロードをシミュレートできます。 次のグラフでは、ユーザーが 100 人で生成率は 10 を使用しています。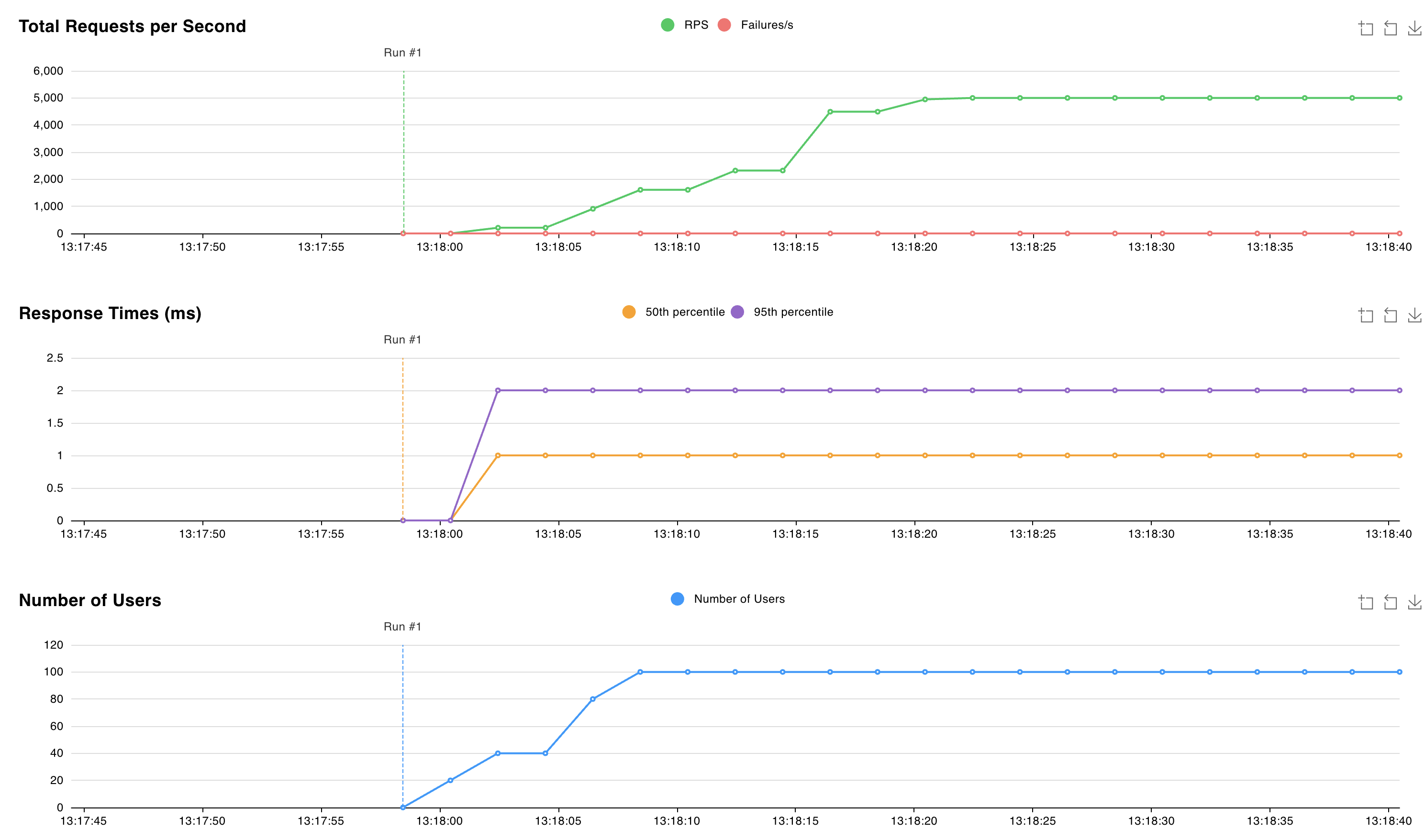
--cascade=orphanフラグを指定したkubectl deleteコマンドを使用してStatefulSetを削除することで、停止をシミュレートします。 目標は、StatefulSet で削除されたポッドが直ちに再作成されずに、1 つのポッドを削除できることです。kubectl delete statefulset valkey-masters --cascade=orphankubectl delete podコマンドを使用してvalkey-masters-0ポッドを削除します。kubectl delete pod valkey-masters-0kubectl get podsコマンドを使用して、ポッドの一覧を確認します。kubectl get pods出力は、ポッド
valkey-masters-0が削除されたことを示しているはずです。NAME READY STATUS RESTARTS AGE valkey-client 1/1 Running 0 6m34s valkey-masters-1 1/1 Running 0 16m valkey-masters-2 1/1 Running 0 16m valkey-replicas-0 1/1 Running 0 16m valkey-replicas-1 1/1 Running 0 16m valkey-replicas-2 1/1 Running 0 16mkubectl logs valkey-replicas-0コマンドを使用して、valkey-replicas-0ポッドのログを取得します。kubectl logs valkey-replicas-0出力で、完全なイベントが約 18 秒間続くのを確認します。
1:S 05 Nov 2024 12:18:53.961 * Connection with primary lost. 1:S 05 Nov 2024 12:18:53.961 * Caching the disconnected primary state. 1:S 05 Nov 2024 12:18:53.961 * Reconnecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:18:53.961 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:18:53.964 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:18:54.910 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:18:54.910 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:18:54.912 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:18:55.920 * Connecting to PRIMARY 10.224.0.250:6379 [..CUT..] 1:S 05 Nov 2024 12:19:10.056 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:10.057 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:10.058 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:19:10.709 * Node c44d4b682b6fb9b37033d3e30574873545266d67 () reported node 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () as not reachable. 1:S 05 Nov 2024 12:19:10.864 * NODE 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () possibly failing. 1:S 05 Nov 2024 12:19:11.066 * 10000 changes in 60 seconds. Saving... 1:S 05 Nov 2024 12:19:11.068 * Background saving started by pid 29 1:S 05 Nov 2024 12:19:11.068 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:11.068 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:11.069 # Error condition on socket for SYNC: Connection refused 29:C 05 Nov 2024 12:19:11.090 * DB saved on disk 29:C 05 Nov 2024 12:19:11.090 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB 1:S 05 Nov 2024 12:19:11.169 * Background saving terminated with success 1:S 05 Nov 2024 12:19:11.884 * FAIL message received from ba36d5167ee6016c01296a4a0127716f8edf8290 () about 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () 1:S 05 Nov 2024 12:19:11.884 # Cluster state changed: fail 1:S 05 Nov 2024 12:19:11.974 * Start of election delayed for 510 milliseconds (rank #0, offset 7225807). 1:S 05 Nov 2024 12:19:11.976 * Node d43f370a417d299b78bd1983792469fe5c39dcdf () reported node 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () as not reachable. 1:S 05 Nov 2024 12:19:12.076 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:12.076 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:12.076 * Currently unable to failover: Waiting the delay before I can start a new failover. 1:S 05 Nov 2024 12:19:12.078 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:19:12.581 * Starting a failover election for epoch 15. 1:S 05 Nov 2024 12:19:12.616 * Currently unable to failover: Waiting for votes, but majority still not reached. 1:S 05 Nov 2024 12:19:12.616 * Needed quorum: 2. Number of votes received so far: 1 1:S 05 Nov 2024 12:19:12.616 * Failover election won: I'm the new primary. 1:S 05 Nov 2024 12:19:12.616 * configEpoch set to 15 after successful failover 1:M 05 Nov 2024 12:19:12.616 * Discarding previously cached primary state. 1:M 05 Nov 2024 12:19:12.616 * Setting secondary replication ID to c0b5b2df8a43b19a4d43d8f8b272a07139e0ca34, valid up to offset: 7225808. New replication ID is 029fcfbae0e3e4a1dccd73066043deba6140c699 1:M 05 Nov 2024 12:19:12.616 * Cluster state changed: okこの 18 秒間に、削除されたポッドに属するシャードへの書き込みが失敗し、Valkey クラスターにより新しいプライマリが選択されていることが確認できます。 要求の待機時間は、この時間枠内で 60 ミリ秒に急増します。
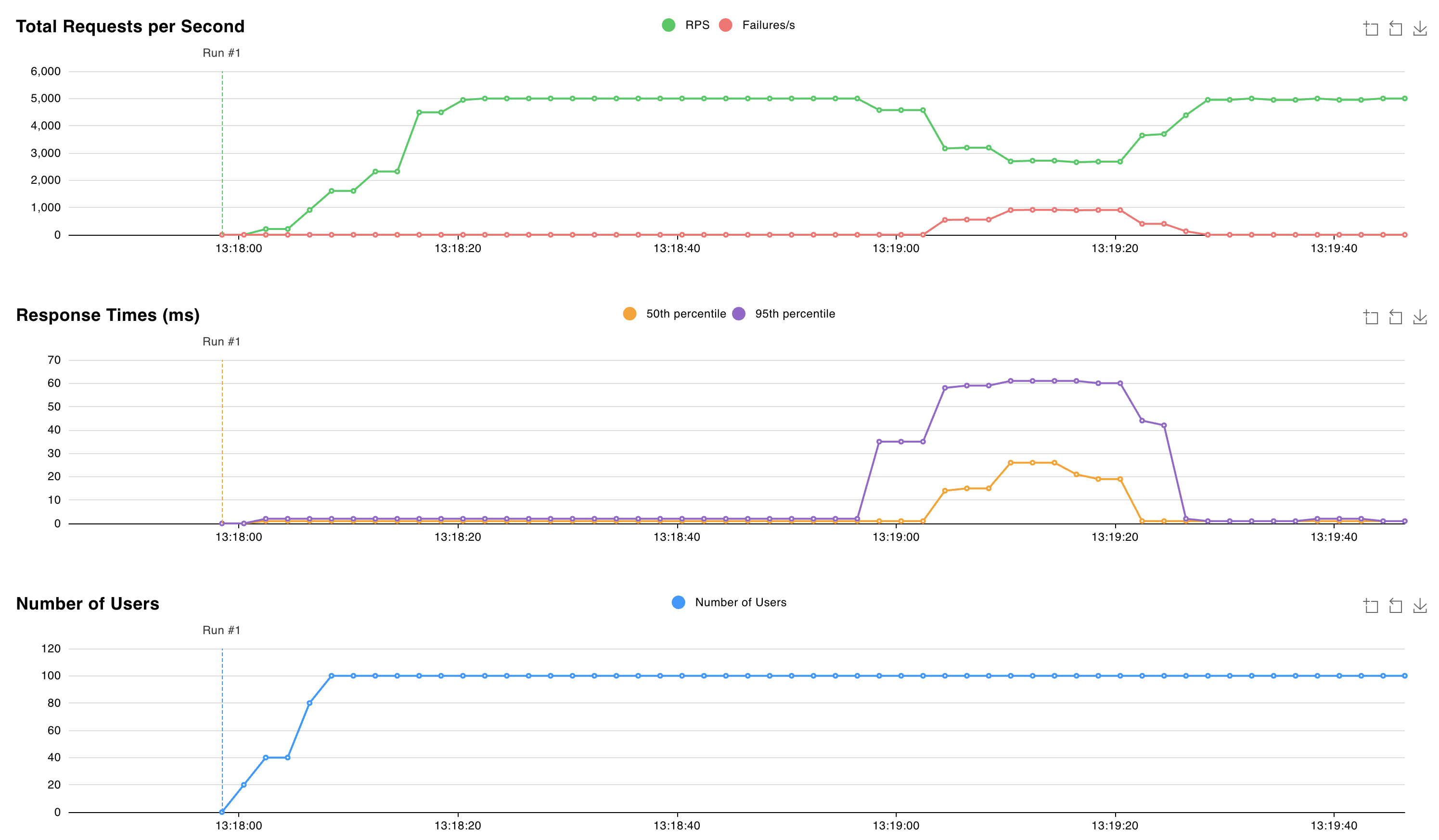
新しいプライマリが選択されると、Valkey クラスターは約 2 ミリ秒の待機時間で要求を処理し続けます。
次のステップ
この記事では、Locust を使用してテスト アプリケーションを構築する方法と、Valkey プライマリ ポッドの障害をシミュレートする方法について説明しました。 Valkey クラスターが障害から復旧し、待機時間に短期間の急増が見られたものの、要求を引き続き処理できることを確認しました。
Azure Kubernetes Service (AKS) を使用したステートフル ワークロードの詳細については、次の記事を参照してください。
- MongoDB クラスターを Azure Kubernetes Service (AKS) にデプロイする
- Azure CLI を使用して高可用性 PostgreSQL データベースを AKS にデプロイする
共同作成者
Microsoft では、この記事を保持しています。 最初の寄稿者は次のとおりです。
- Nelly Kiboi | サービス エンジニア
- Saverio Proto | プリンシパル カスタマー エクスペリエンス エンジニア
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。

Azure Kubernetes Service