キャッシュのガイダンス
キャッシュは、システムのパフォーマンスとスケーラビリティを改善することを目的とする一般的な手法です。 頻繁にアクセスされるデータを、アプリケーションの近くにある高速ストレージに一時的にコピーすることで、データをキャッシュします。 この高速データ ストレージを元のソースよりもアプリケーションに近い場所に配置すると、キャッシュにより、データがよりすばやく提供され、クライアント アプリケーションの応答時間を大幅に改善できます。
キャッシュは、特に次のすべての条件が元のデータ ストアに適用される場合に、クライアント インスタンスが同じデータを繰り返し読み取る場合に最も効果的です。
- これは比較的静的なままです。
- キャッシュの速度に比べて遅い。
- 高レベルの競合が発生する可能性がある。
- ネットワーク待ち時間が原因でアクセスが遅くなる可能性がある場合は、遠く離れています。
分散アプリケーションでのキャッシュ
分散アプリケーションは、通常、データをキャッシュするときに、次の戦略のいずれかまたは両方を実装します。
- プライベート キャッシュを使用します。データは、アプリケーションまたはサービスのインスタンスを実行しているコンピューター上でローカルに保持されます。
- 共有キャッシュを使用し、複数のプロセスとマシンからアクセスできる共通のソースとして機能します。
どちらの場合も、キャッシュはクライアント側とサーバー側で実行できます。 クライアント側キャッシュは、Web ブラウザーやデスクトップ アプリケーションなどのシステムのユーザー インターフェイスを提供するプロセスによって行われます。 サーバー側キャッシュは、リモートで実行されているビジネス サービスを提供するプロセスによって実行されます。
プライベート キャッシュ
キャッシュの最も基本的な種類は、メモリ内ストアです。 これは 1 つのプロセスのアドレス空間に保持され、そのプロセスで実行されるコードによって直接アクセスされます。 この種類のキャッシュにすばやくアクセスできます。 また、少量の静的データを格納するための効果的な手段を提供することもできます。 通常、キャッシュのサイズは、プロセスをホストするマシンで使用可能なメモリの量によって制限されます。
メモリ内で物理的に可能なよりも多くの情報をキャッシュする必要がある場合は、キャッシュされたデータをローカル ファイル システムに書き込むことができます。 このプロセスは、メモリに保持されているデータよりもアクセスに時間がかかりますが、ネットワーク経由でデータを取得するよりも高速で信頼性が高いはずです。
このモデルを使用するアプリケーションの複数のインスタンスが同時に実行されている場合、各アプリケーション インスタンスには、データの独自のコピーを保持する独自の独立したキャッシュがあります。
キャッシュは、過去のある時点の元のデータのスナップショットと考えてください。 このデータが静的でない場合は、異なるアプリケーション インスタンスが異なるバージョンのデータをキャッシュに保持している可能性があります。 そのため、図 1 に示すように、これらのインスタンスによって実行されたのと同じクエリによって異なる結果が返される可能性があります。
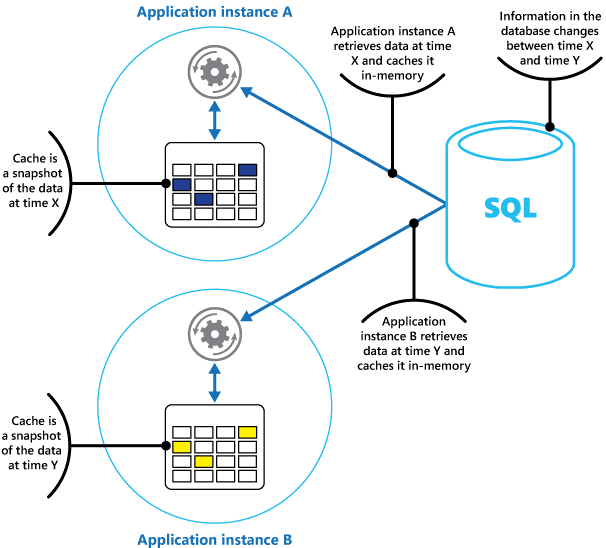
図 1: アプリケーションのさまざまなインスタンスでメモリ内キャッシュを使用する。
共有キャッシュ
共有キャッシュを使用すると、メモリ内キャッシュで発生する可能性がある各キャッシュでデータが異なる可能性があるという懸念を軽減できます。 共有キャッシュを使用すると、異なるアプリケーション インスタンスで、キャッシュされたデータの同じビューが確実に表示されます。 図 2 に示すように、キャッシュは別の場所に配置されます。これは通常、別のサービスの一部としてホストされます。
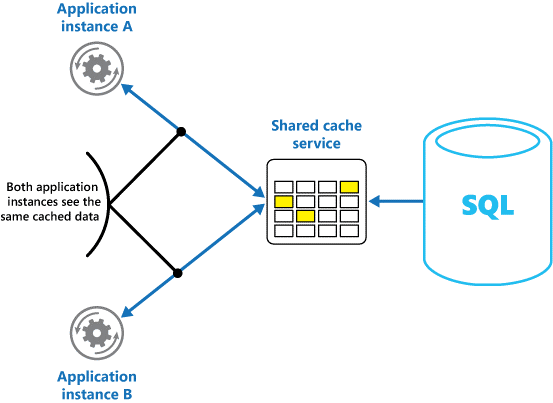
図 2: 共有キャッシュの使用。
共有キャッシュ アプローチの重要な利点は、それが提供するスケーラビリティです。 多くの共有キャッシュ サービスは、サーバーのクラスターを使用して実装され、ソフトウェアを使用してクラスター全体に透過的にデータを分散します。 アプリケーション インスタンスは、キャッシュ サービスに要求を送信するだけです。 基になるインフラストラクチャによって、クラスター内のキャッシュされたデータの場所が決まります。 サーバーを追加することで、キャッシュを簡単にスケーリングできます。
共有キャッシュアプローチには、主に次の 2 つの欠点があります。
- キャッシュは各アプリケーション インスタンスにローカルに保持されなくなったため、アクセスに時間がかかります。
- 別のキャッシュ サービスを実装する必要がある場合は、ソリューションが複雑になる可能性があります。
キャッシュの使用に関する考慮事項
以降のセクションでは、キャッシュの設計と使用に関する考慮事項について詳しく説明します。
データをキャッシュするタイミングを決定する
キャッシュにより、パフォーマンス、スケーラビリティ、可用性が大幅に向上します。 データが多くなり、このデータにアクセスする必要があるユーザーの数が多いほど、キャッシュの利点が大きくなります。 キャッシュにより、元のデータ ストアでの大量の同時要求の処理に関連する待機時間と競合が減少します。
たとえば、データベースでは、限られた数の同時接続がサポートされている場合があります。 ただし、基になるデータベースではなく、共有キャッシュからデータを取得すると、使用可能な接続の数が現在使い果たされている場合でも、クライアント アプリケーションはこのデータにアクセスできます。 さらに、データベースが使用できなくなった場合、クライアント アプリケーションはキャッシュに保持されているデータを使用して続行できる可能性があります。
頻繁に読み取られたが変更頻度の低いデータ (書き込み操作よりも読み取り操作の割合が高いデータなど) をキャッシュすることを検討してください。 ただし、重要な情報の権限のあるストアとしてキャッシュを使用することはお勧めしません。 代わりに、アプリケーションで失うことができないすべての変更が、常に永続的なデータ ストアに保存されるようにします。 キャッシュが使用できない場合でも、アプリケーションは引き続きデータ ストアを使用して動作でき、重要な情報は失われません。
データを効果的にキャッシュする方法を決定する
キャッシュを効果的に使用する鍵は、キャッシュする最も適切なデータを決定し、適切なタイミングでキャッシュすることです。 データは、アプリケーションが初めて取得する際に必要に応じてキャッシュに追加できます。 アプリケーションは、データ ストアから 1 回だけデータをフェッチする必要があり、その後のアクセスはキャッシュを使用して満たすことができます。
または、キャッシュには、一般的にアプリケーションの起動時 (シード処理と呼ばれるアプローチ) に、事前にデータを部分的または完全に設定することもできます。 ただし、この方法では、アプリケーションの実行開始時に元のデータ ストアに突然高い負荷がかかる可能性があるため、大規模なキャッシュのシード処理を実装することはお勧めしません。
多くの場合、使用パターンの分析は、キャッシュを完全に事前設定するか部分的に事前設定するか、キャッシュするデータを選択するかを決定するのに役立ちます。 たとえば、アプリケーションを定期的に (毎日) 使用する顧客の静的ユーザー プロファイル データをキャッシュにシード処理できますが、週に 1 回だけアプリケーションを使用する顧客にはシード処理できません。
通常、キャッシュは、変更できないデータや変更頻度の低いデータに適しています。 たとえば、eコマース アプリケーションの製品や価格情報などの参照情報や、構築にコストがかかる共有静的リソースなどがあります。 このデータの一部またはすべてをアプリケーションの起動時にキャッシュに読み込んで、リソースの需要を最小限に抑え、パフォーマンスを向上させることができます。 また、キャッシュ内の参照データを定期的に更新して、up-to日付であることを確認するバックグラウンド プロセスが必要になる場合もあります。 または、参照データが変更されたときに、バックグラウンド プロセスでキャッシュを更新できます。
キャッシュは動的データにはあまり役に立ちませんが、この考慮事項にはいくつかの例外があります (詳細については、この記事の後半の「高度に動的なデータをキャッシュする」セクションを参照してください)。 元のデータが定期的に変更されると、キャッシュされた情報はすぐに古くなるか、キャッシュを元のデータ ストアと同期するオーバーヘッドによってキャッシュの有効性が低下します。
キャッシュには、エンティティの完全なデータを含める必要はありません。 たとえば、データ項目が、名前、住所、口座残高を持つ銀行顧客などの複数値オブジェクトを表している場合、これらの要素の一部は、名前や住所など静的なままである可能性があります。 口座残高などの他の要素は、より動的な場合があります。 このような状況では、データの静的な部分をキャッシュし、必要なときに残りの情報のみを取得 (または計算) すると便利です。
パフォーマンス テストと使用状況分析を実行して、キャッシュの事前入力またはオンデマンド読み込み、またはその両方の組み合わせが適切かどうかを判断することをお勧めします。 決定は、データのボラティリティと使用パターンに基づく必要があります。 キャッシュ使用率とパフォーマンス分析は、負荷が高く、拡張性が高い必要があるアプリケーションで重要です。 たとえば、高度にスケーラブルなシナリオでは、キャッシュをシードして、ピーク時のデータ ストアの負荷を軽減できます。
キャッシュを使用して、アプリケーションの実行中に計算が繰り返されないようにすることもできます。 操作がデータを変換したり、複雑な計算を実行したりすると、操作の結果をキャッシュに保存できます。 後で同じ計算が必要な場合、アプリケーションは単にキャッシュから結果を取得できます。
アプリケーションは、キャッシュに保持されているデータを変更できます。 ただし、キャッシュは、いつでも消える可能性がある一時的なデータ ストアと考えるのをお勧めします。 キャッシュにのみ貴重なデータを格納しないでください。元のデータ ストアにも情報が保持されていることを確認します。 つまり、キャッシュが使用できなくなった場合、データが失われる可能性を最小限に抑えることができます。
非常に動的なデータをキャッシュする
急速に変化する情報を永続的なデータ ストアに格納すると、システムにオーバーヘッドが発生する可能性があります。 たとえば、状態やその他の測定値を継続的に報告するデバイスを考えてみましょう。 キャッシュされた情報がほぼ常に古くなっているという基準でこのデータをキャッシュしないことをアプリケーションが選択した場合、データ ストアからこの情報を格納して取得する場合も、同じ考慮事項が当てはまる可能性があります。 このデータの保存とフェッチにかかる時間は、変更されている可能性があります。
このような状況では、永続的なデータ ストアではなく、動的な情報をキャッシュに直接格納する利点を考慮してください。 データが重要でなく、監査を必要としない場合は、不定期の変更が失われるかどうかは関係ありません。
キャッシュ内のデータの有効期限を管理する
ほとんどの場合、キャッシュに保持されるデータは、元のデータ ストアに保持されているデータのコピーです。 元のデータ ストア内のデータがキャッシュされた後に変更され、キャッシュされたデータが古くなる可能性があります。 多くのキャッシュ システムを使用すると、データの有効期限が切れ、データが古くなっている可能性がある期間を短縮するようにキャッシュを構成できます。
キャッシュされたデータの有効期限が切れると、キャッシュから削除され、アプリケーションは元のデータ ストアからデータを取得する必要があります (新しくフェッチされた情報をキャッシュに戻すことができます)。 キャッシュを構成するときに、既定の有効期限ポリシーを設定できます。 多くのキャッシュ サービスでは、プログラムを使用してキャッシュに格納するときに、個々のオブジェクトの有効期限を指定することもできます。 一部のキャッシュでは、有効期限を絶対値として指定したり、指定した時間内にアイテムにアクセスしなかった場合にアイテムをキャッシュから削除したりするスライディング値として指定できます。 この設定は、指定されたオブジェクトに対してのみ、キャッシュ全体の有効期限ポリシーをオーバーライドします。
注
キャッシュの有効期限と、キャッシュに含まれるオブジェクトを慎重に検討してください。 短すぎると、オブジェクトの有効期限が早くなりすぎて、キャッシュを使用する利点が減ります。 期間が長すぎると、データが古くなるリスクがあります。
また、データが長期間常駐したままにすることが許可されている場合は、キャッシュがいっぱいになる可能性もあります。 この場合、キャッシュに新しい項目を追加する要求が発生すると、削除と呼ばれるプロセスで一部の項目が強制的に削除される可能性があります。 キャッシュ サービスは通常、最も使用頻度の低い (LRU) ベースでデータを削除しますが、通常は、このポリシーをオーバーライドして項目が削除されないようにすることができます。 ただし、この方法を採用すると、キャッシュで使用可能なメモリを超えるリスクがあります。 キャッシュに項目を追加しようとするアプリケーションは、例外で失敗します。
一部のキャッシュ実装では、追加の削除ポリシーが提供される場合があります。 削除ポリシーにはいくつかの種類があります。 これには以下が含まれます:
- 最近使用されたポリシー (データが再び必要になることが予想される場合)。
- 先入れ先出しポリシー (最も古いデータは最初に削除されます)。
- トリガーされたイベント (変更中のデータなど) に基づく明示的な削除ポリシー。
クライアント側キャッシュ内のデータを無効にする
通常、クライアント側キャッシュに保持されているデータは、クライアントにデータを提供するサービスの外部にあると見なされます。 サービスは、クライアント側キャッシュに対して情報の追加または削除をクライアントに直接強制することはできません。
つまり、適切に構成されていないキャッシュを使用するクライアントが、古い情報を引き続き使用する可能性があります。 たとえば、キャッシュの有効期限ポリシーが適切に実装されていない場合、クライアントは、元のデータ ソースの情報が変更されたときにローカルにキャッシュされる古い情報を使用する可能性があります。
HTTP 接続経由でデータを提供する Web アプリケーションを構築する場合は、Web クライアント (ブラウザーや Web プロキシなど) に最新の情報をフェッチするように暗黙的に強制できます。 これは、リソースの URI の変更によってリソースが更新された場合に行うことができます。 Web クライアントは通常、リソースの URI をクライアント側キャッシュのキーとして使用するため、URI が変更された場合、Web クライアントはリソースの以前にキャッシュされたバージョンを無視し、代わりに新しいバージョンをフェッチします。
キャッシュでのコンカレンシーの管理
キャッシュは、多くの場合、アプリケーションの複数のインスタンスによって共有されるように設計されています。 各アプリケーション インスタンスは、キャッシュ内のデータの読み取りと変更を行うことができます。 そのため、共有データ ストアで発生するのと同じコンカレンシーの問題もキャッシュに適用されます。 キャッシュに保持されているデータをアプリケーションで変更する必要がある場合は、アプリケーションの 1 つのインスタンスによって行われた更新によって、別のインスタンスによって行われた変更が上書きされないようにする必要がある場合があります。
データの性質と競合の可能性に応じて、コンカレンシーに次の 2 つの方法のいずれかを採用できます。
- オプティミスティック。 データを更新する直前に、アプリケーションは、キャッシュ内のデータが取得されてから変更されたかどうかを確認します。 データがまだ同じ場合は、変更を加えることができます。 それ以外の場合、アプリケーションはそれを更新するかどうかを決定する必要があります。 (この決定を推進するビジネス ロジックは、アプリケーション固有です)。この方法は、更新が頻繁に行われない状況や、競合が発生する可能性が低い状況に適しています。
- ペシミスティック。 データを取得すると、アプリケーションはキャッシュ内のデータをロックして、別のインスタンスがデータを変更できないようにします。 このプロセスにより、競合は発生しませんが、同じデータを処理する必要がある他のインスタンスをブロックすることもできます。 ペシミスティック コンカレンシーはソリューションのスケーラビリティに影響を与える可能性があり、有効期間の短い操作にのみ推奨されます。 この方法は、特にアプリケーションがキャッシュ内の複数の項目を更新し、これらの変更が一貫して適用されるようにする必要がある場合に、競合の可能性が高い状況に適している可能性があります。
高可用性とスケーラビリティを実装し、パフォーマンスを向上させる
キャッシュをデータのプライマリ リポジトリとして使用しないでください。これは、キャッシュが設定される元のデータ ストアのロールです。 元のデータ ストアは、データの永続化を保証する役割を担います。
ソリューションに共有キャッシュ サービスの可用性に重大な依存関係を導入しないように注意してください。 共有キャッシュを提供するサービスが使用できない場合、アプリケーションは引き続き機能できる必要があります。 キャッシュ サービスが再開されるのを待っている間、アプリケーションが応答しなくなったり、失敗したりしないようにする必要があります。
そのため、キャッシュ サービスの可用性を検出し、キャッシュにアクセスできない場合は元のデータ ストアにフォールバックするようにアプリケーションを準備する必要があります。 Circuit-Breaker パターンは、このシナリオの処理に役立ちます。 キャッシュを提供するサービスを復旧できます。キャッシュが使用可能になると、キャッシュ アサイド パターンなどの戦略に従って、元のデータ ストアからデータが読み取られると、キャッシュを再作成できます。
ただし、キャッシュが一時的に使用できないときにアプリケーションが元のデータ ストアにフォールバックすると、システムのスケーラビリティが影響を受ける可能性があります。 データ ストアの復旧中は、元のデータ ストアにデータの要求が殺到し、タイムアウトと接続の失敗が発生する可能性があります。
すべてのアプリケーション インスタンスがアクセスする共有キャッシュと共に、アプリケーションの各インスタンスにローカルのプライベート キャッシュを実装することを検討してください。 アプリケーションは、項目を取得するときに、最初にローカル キャッシュ、次に共有キャッシュ、最後に元のデータ ストアで確認できます。 ローカル キャッシュは、共有キャッシュ内のデータを使用するか、共有キャッシュが使用できない場合はデータベース内で設定できます。
この方法では、ローカル キャッシュが共有キャッシュに関して古くなりすぎないように、慎重な構成が必要です。 ただし、共有キャッシュに到達できない場合、ローカル キャッシュはバッファーとして機能します。 図 3 は、この構造を示しています。
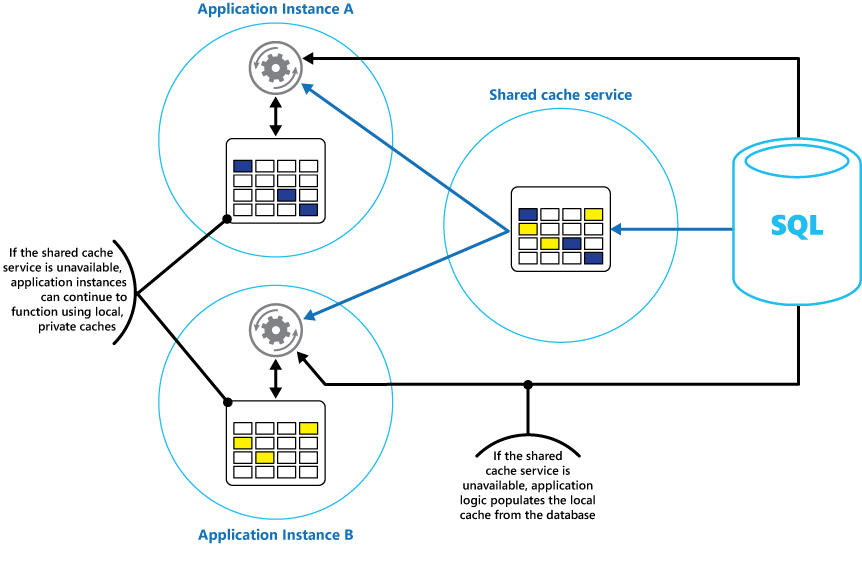
図 3: 共有キャッシュでのローカル プライベート キャッシュの使用。
比較的有効期間の長いデータを保持する大規模なキャッシュをサポートするために、一部のキャッシュ サービスには、キャッシュが使用できなくなった場合に自動フェールオーバーを実装する高可用性オプションが用意されています。 通常、この方法では、プライマリ キャッシュ サーバーに格納されているキャッシュされたデータをセカンダリ キャッシュ サーバーにレプリケートし、プライマリ サーバーで障害が発生した場合や接続が失われた場合にセカンダリ サーバーに切り替える必要があります。
複数の宛先への書き込みに関連する待機時間を短縮するために、プライマリ サーバー上のキャッシュにデータが書き込まれるときに、セカンダリ サーバーへのレプリケーションが非同期的に行われる場合があります。 この方法により、障害が発生した場合にキャッシュされた情報の一部が失われる可能性がありますが、キャッシュの全体的なサイズと比較して、このデータの割合は小さくする必要があります。
共有キャッシュが大きい場合は、キャッシュされたデータをノード間でパーティション分割して競合の可能性を減らし、スケーラビリティを向上させることが有益な場合があります。 多くの共有キャッシュでは、ノードを動的に追加 (および削除) し、パーティション間でデータを再調整する機能がサポートされています。 このアプローチには、ノードのコレクションがシームレスな単一キャッシュとしてクライアント アプリケーションに提示されるクラスタリングが含まれる場合があります。 ただし、内部的には、負荷を均等に分散する定義済みの分散戦略に従って、ノード間でデータが分散されます。 可能なパーティション分割戦略の詳細については、 データのパーティション分割に関するガイダンスを参照してください。
クラスタリングを使用すると、キャッシュの可用性を高めることもできます。 ノードが失敗した場合でも、キャッシュの残りの部分にアクセスできます。 クラスタリングは、レプリケーションとフェールオーバーと組み合わせて頻繁に使用されます。 各ノードをレプリケートでき、ノードに障害が発生した場合はレプリカをすばやくオンラインにすることができます。
多くの読み取り操作と書き込み操作には、単一のデータ値またはオブジェクトが含まれる可能性があります。 ただし、大量のデータを迅速に格納または取得することが必要になる場合があります。 たとえば、キャッシュのシード処理には、数百または数千の項目をキャッシュに書き込む必要があります。 アプリケーションでは、同じ要求の一部として、多数の関連項目をキャッシュから取得する必要がある場合もあります。
多くの大規模なキャッシュでは、これらの目的のためにバッチ操作が提供されます。 これにより、クライアント アプリケーションは大量の項目を 1 つの要求にパッケージ化でき、多数の小さな要求の実行に関連するオーバーヘッドが軽減されます。
キャッシュと最終的な整合性
キャッシュアサイド パターンを機能させるには、キャッシュを設定するアプリケーションのインスタンスが、最新かつ一貫性のあるバージョンのデータにアクセスできる必要があります。 最終的な整合性 (レプリケートされたデータ ストアなど) を実装するシステムでは、これは当てはまるとは限りません。
アプリケーションの 1 つのインスタンスがデータ項目を変更し、その項目のキャッシュされたバージョンを無効にすることができます。 アプリケーションの別のインスタンスがキャッシュからこの項目を読み取ろうとするとキャッシュ ミスが発生するため、データ ストアからデータが読み取られ、キャッシュに追加されます。 ただし、データ ストアが他のレプリカと完全に同期されていない場合、アプリケーション インスタンスはキャッシュの読み取りと古い値の設定を行うことができます。
データ整合性の処理の詳細については、「データ整合性の 概要」を参照してください。
キャッシュされたデータを保護する
使用するキャッシュ サービスに関係なく、キャッシュに保持されているデータを未承認のアクセスから保護する方法を検討してください。 次の 2 つの主な懸念事項があります。
- キャッシュ内のデータのプライバシー。
- キャッシュとキャッシュを使用しているアプリケーションの間を流れるデータのプライバシー。
キャッシュ内のデータを保護するために、キャッシュ サービスは、アプリケーションで次を指定する必要がある認証メカニズムを実装する場合があります。
- キャッシュ内のデータにアクセスできる ID。
- これらの ID が実行できる操作 (読み取りと書き込み)。
データの読み取りと書き込みに関連するオーバーヘッドを減らすために、ID にキャッシュへの書き込みアクセスまたは読み取りアクセス権が付与された後、その ID はキャッシュ内の任意のデータを使用できます。
キャッシュされたデータのサブセットへのアクセスを制限する必要がある場合は、次のいずれかの操作を行うことができます。
- (異なるキャッシュ サーバーを使用して) キャッシュをパーティションに分割し、使用を許可するパーティションの ID にのみアクセス権を付与します。
- 異なるキーを使用して各サブセットのデータを暗号化し、各サブセットにアクセスできる ID にのみ暗号化キーを提供します。 クライアント アプリケーションは引き続きキャッシュ内のすべてのデータを取得できますが、キーを持つデータのみを復号化できます。
また、キャッシュに入り出す際にデータを保護する必要もあります。 これを行うには、クライアント アプリケーションがキャッシュへの接続に使用するネットワーク インフラストラクチャによって提供されるセキュリティ機能に依存します。 クライアント アプリケーションをホストするのと同じ組織内のオンサイト サーバーを使用してキャッシュを実装する場合、ネットワーク自体の分離では、追加の手順を実行する必要がない可能性があります。 キャッシュがリモートに配置され、パブリック ネットワーク (インターネットなど) 経由の TCP または HTTP 接続が必要な場合は、SSL の実装を検討してください。
Azure でのキャッシュの実装に関する考慮事項
Azure Cache for Redis は、Azure データセンターでサービスとして実行されるオープン ソースの Redis キャッシュの実装です。 これは、アプリケーションがクラウド サービス、Web サイト、または Azure 仮想マシン内のいずれとして実装されているかに関係なく、任意の Azure アプリケーションからアクセスできるキャッシュ サービスを提供します。 キャッシュは、適切なアクセス キーを持つクライアント アプリケーションによって共有できます。
Azure Cache for Redis は、可用性、スケーラビリティ、セキュリティを提供する高パフォーマンスのキャッシュ ソリューションです。 通常、1 つ以上の専用マシンに分散されたサービスとして実行されます。 高速アクセスを確保するために、できるだけ多くの情報をメモリに格納しようとします。 このアーキテクチャは、低速の I/O 操作を実行する必要性を減らすことで、低待機時間と高スループットを提供することを目的としています。
Azure Cache for Redis は、クライアント アプリケーションで使用されるさまざまな API の多くと互換性があります。 オンプレミスで実行されている Azure Cache for Redis を既に使用している既存のアプリケーションがある場合、Azure Cache for Redis はクラウドでのキャッシュへの迅速な移行パスを提供します。
Redis の機能
Redis は単純なキャッシュ サーバー以上の機能です。 分散インメモリ データベースには、多くの一般的なシナリオをサポートする広範なコマンド セットが用意されています。 これらは、このドキュメントの「Redis キャッシュの使用」セクションで後述します。 このセクションでは、Redis が提供する主要な機能の一部をまとめます。
メモリ内データベースとしての Redis
Redis では、読み取り操作と書き込み操作の両方がサポートされています。 Redis では、書き込みをシステム障害から保護するには、ローカル スナップショット ファイルまたは追加専用ログ ファイルに定期的に格納します。 このような状況は、一時的なデータ ストアと見なす必要がある多くのキャッシュでは当たりません。
すべての書き込みは非同期であり、クライアントがデータの読み取りと書き込みをブロックすることはありません。 Redis は、実行を開始すると、スナップショットまたはログ ファイルからデータを読み取り、それを使用してメモリ内キャッシュを構築します。 詳細については、Redis Web サイトでの Redis の永続化 に関するページを参照してください。
注
致命的な障害が発生した場合、Redis ではすべての書き込みが保存されるとは限りませんが、最悪の場合は数秒分のデータしか失われない可能性があります。 キャッシュは権限のあるデータ ソースとして機能することを意図したものではなく、重要なデータが適切なデータ ストアに正常に保存されるようにするには、キャッシュを使用するアプリケーションの責任です。 詳細については、 キャッシュアサイド パターンを参照してください。
Redis データ型
Redis はキー値ストアです。値には、単純な型や、ハッシュ、リスト、セットなどの複雑なデータ構造を含めることができます。 これらのデータ型に対するアトミック操作のセットがサポートされています。 キーは永続的にすることも、限られた有効期間でタグ付けすることもできます。その時点で、キーとそれに対応する値はキャッシュから自動的に削除されます。 Redis のキーと値の詳細については、Redis Web サイトの Redis データ型と抽象化の概要 に関するページを参照してください。
Redis レプリケーションとクラスタリング
Redis では、可用性の確保とスループットの維持に役立つプライマリ/下位レプリケーションがサポートされています。 Redis プライマリ ノードへの書き込み操作は、1 つ以上の下位ノードにレプリケートされます。 読み取り操作は、プライマリまたは任意の下位ユーザーが処理できます。
ネットワーク パーティションがある場合、下位ユーザーは引き続きデータを提供し、接続が再確立されたときにプライマリと透過的に再同期できます。 詳細については、Redis Web サイトの レプリケーション ページを参照してください。
Redis にはクラスタリングも用意されています。これにより、サーバー間でデータをシャードに透過的にパーティション分割し、負荷を分散できます。 この機能により、新しい Redis サーバーを追加でき、キャッシュのサイズが大きくなるにつれてデータを再パーティション分割できるため、スケーラビリティが向上します。
さらに、クラスター内の各サーバーは、プライマリ/下位レプリケーションを使用してレプリケートできます。 これにより、クラスター内の各ノードで可用性が確保されます。 クラスタリングとシャーディングの詳細については、Redis Web サイトの Redis クラスターのチュートリアル ページ を参照してください。
Redis メモリの使用
Redis Cache には、ホスト コンピューターで使用可能なリソースに依存する有限のサイズがあります。 Redis サーバーを構成するときに、使用できるメモリの最大量を指定できます。 また、Redis キャッシュ内のキーに有効期限が設定されるように構成することもできます。その後、キーはキャッシュから自動的に削除されます。 この機能は、メモリ内キャッシュに古いデータや古いデータが格納されるのを防ぐのに役立ちます。
メモリがいっぱいになると、Redis は多数のポリシーに従うことで、キーとその値を自動的に削除できます。 既定値は LRU (最近使用したもの) ですが、ランダムにキーを削除したり、削除を完全にオフにしたりするなどの他のポリシーを選択することもできます (この場合、キャッシュに項目を追加しようとすると失敗します)。 詳細については、「 Redis を LRU キャッシュとして使用する 」ページを参照してください。
Redis のトランザクションとバッチ
Redis を使用すると、クライアント アプリケーションは、キャッシュ内のデータをアトミック トランザクションとして読み書きする一連の操作を送信できます。 トランザクション内のすべてのコマンドは順番に実行することが保証されており、他の同時実行クライアントによって発行されたコマンドはそれらの間に織り込まれるものはありません。
ただし、リレーショナル データベースがトランザクションを実行するため、これらは実際のトランザクションではありません。 トランザクション処理は 2 つのステージで構成されます。1 つ目はコマンドがキューに入れられたとき、2 つ目はコマンドが実行されたときです。 コマンド キュー ステージでは、トランザクションを構成するコマンドがクライアントによって送信されます。 この時点で何らかのエラーが発生した場合 (構文エラーやパラメーターの数が間違っている場合など)、Redis はトランザクション全体の処理を拒否し、破棄します。
実行フェーズ中に、Redis はキューに登録された各コマンドを順番に実行します。 このフェーズ中にコマンドが失敗した場合、Redis は次のキューに登録されたコマンドを続行し、既に実行されているコマンドの影響をロールバックしません。 この簡略化された形式のトランザクションは、パフォーマンスを維持し、競合によって発生するパフォーマンスの問題を回避するのに役立ちます。
Redis では、一貫性の維持に役立つオプティミスティック ロックの形式が実装されています。 Redis でのトランザクションとロックの詳細については、Redis Web サイトの トランザクション ページ を参照してください。
Redis では、要求の非トランザクション バッチ処理もサポートされています。 クライアントが Redis サーバーにコマンドを送信するために使用する Redis プロトコルを使用すると、クライアントは同じ要求の一部として一連の操作を送信できます。 これは、ネットワーク上のパケットの断片化を減らすのに役立ちます。 バッチが処理されると、各コマンドが実行されます。 これらのコマンドのいずれかが形式が正しくない場合は拒否されますが (トランザクションでは発生しません)、残りのコマンドは実行されます。 また、バッチ内のコマンドが処理される順序についても保証されません。
Redis のセキュリティ
Redis は純粋にデータへの高速アクセスを提供することに重点を置き、信頼されたクライアントのみがアクセスできる信頼できる環境内で実行するように設計されています。 Redis では、パスワード認証に基づく制限付きセキュリティ モデルがサポートされています。 (認証を完全に削除することは可能ですが、これはお勧めしません)。
認証されたすべてのクライアントは、同じグローバル パスワードを共有し、同じリソースにアクセスできます。 より包括的なサインイン セキュリティが必要な場合は、Redis サーバーの前に独自のセキュリティ レイヤーを実装する必要があります。すべてのクライアント要求がこの追加レイヤーを通過する必要があります。 Redis は、信頼されていないクライアントまたは認証されていないクライアントに直接公開しないでください。
コマンドへのアクセスを制限するには、コマンドを無効にするか、名前を変更します (また、特権クライアントにのみ新しい名前を付けます)。
Redis では、どの形式のデータ暗号化も直接サポートされないため、すべてのエンコードはクライアント アプリケーションで実行する必要があります。 さらに、Redis では、いかなる形式のトランスポート セキュリティも提供されません。 ネットワーク経由でデータを保護する必要がある場合は、SSL プロキシを実装することをお勧めします。
詳細については、Redis Web サイトの Redis セキュリティ ページを参照してください。
注
Azure Cache for Redis には、クライアントが接続するための独自のセキュリティ層が用意されています。 基になる Redis サーバーはパブリック ネットワークに公開されません。
Azure Redis Cache
Azure Cache for Redis は、Azure データセンターでホストされている Redis サーバーへのアクセスを提供します。 アクセス制御とセキュリティを提供するファサードとして機能します。 Azure portal を使用してキャッシュをプロビジョニングできます。
ポータルには、いくつかの定義済みの構成が用意されています。 これらの範囲は、SSL 通信をサポートする専用サービスとして実行される 53 GB のキャッシュ (プライバシー用) と、サービス レベル アグリーメント (SLA) が 99.9% 可用性を備えたマスター/下位レプリケーションから、共有ハードウェアで実行されるレプリケーションなしの 250 MB キャッシュ (可用性保証なし) までです。
Azure portal を使用して、キャッシュの削除ポリシーを構成し、提供されたロールにユーザーを追加してキャッシュへのアクセスを制御することもできます。 これらのロールは、メンバーが実行できる操作を定義します。これには、所有者、共同作成者、閲覧者が含まれます。 たとえば、所有者ロールのメンバーはキャッシュ (セキュリティを含む) とその内容を完全に制御でき、共同作成者ロールのメンバーはキャッシュ内の情報を読み書きでき、閲覧者ロールのメンバーはキャッシュからデータのみを取得できます。
ほとんどの管理タスクは、Azure portal を使用して実行されます。 このため、プログラムによる構成の変更、Redis サーバーのシャットダウン、追加の下位の構成、ディスクへのデータの強制的な保存など、標準バージョンの Redis で使用できる管理コマンドの多くは使用できません。
Azure portal には、キャッシュのパフォーマンスを監視できる便利なグラフィカル表示が含まれています。 たとえば、接続の数、実行されている要求の数、読み取りと書き込みの量、キャッシュ ヒットとキャッシュ ミスの数を表示できます。 この情報を使用すると、キャッシュの有効性を判断し、必要に応じて別の構成に切り替えたり、削除ポリシーを変更したりできます。
さらに、1 つ以上の重要なメトリックが想定範囲外の場合に、管理者に電子メール メッセージを送信するアラートを作成できます。 たとえば、キャッシュ ミスの数が過去 1 時間に指定した値を超えた場合に管理者に警告する必要がある場合は、キャッシュが小さすぎるか、データが削除される速度が速すぎる可能性があるためです。
キャッシュの CPU、メモリ、ネットワーク使用量を監視することもできます。
Azure Cache for Redis を作成して構成する方法を示す詳細と例については、Azure ブログの Azure Cache for Redis に関するページを参照してください。
セッション状態と HTML 出力のキャッシュ
Azure Web ロールを使用して実行 ASP.NET Web アプリケーションを構築する場合は、セッション状態情報と HTML 出力を Azure Cache for Redis に保存できます。 Azure Cache for Redis のセッション状態プロバイダーを使用すると、ASP.NET Web アプリケーションのさまざまなインスタンス間でセッション情報を共有できます。また、クライアントとサーバーのアフィニティが利用できない、メモリ内のセッション データのキャッシュが適切でない Web ファームの状況で非常に便利です。
Azure Cache for Redis でセッション状態プロバイダーを使用すると、次のようないくつかの利点があります。
- ASP.NET Web アプリケーションの多数のインスタンスとのセッション状態の共有。
- スケーラビリティの向上。
- 複数のリーダーと 1 つのライターに対して、同じセッション状態データへの制御された同時アクセスをサポートします。
- 圧縮を使用してメモリを節約し、ネットワーク パフォーマンスを向上させます。
詳細については、 Azure Cache for Redis ASP.NET セッション状態プロバイダーに関するページを参照してください。
注
Azure 環境の外部で実行される ASP.NET アプリケーションでは、Azure Cache for Redis のセッション状態プロバイダーを使用しないでください。 Azure の外部からキャッシュにアクセスする待機時間により、データをキャッシュするパフォーマンス上の利点を排除できます。
同様に、Azure Cache for Redis の出力キャッシュ プロバイダーを使用すると、ASP.NET Web アプリケーションによって生成された HTTP 応答を保存できます。 Azure Cache for Redis で出力キャッシュ プロバイダーを使用すると、複雑な HTML 出力をレンダリングするアプリケーションの応答時間を短縮できます。 同様の応答を生成するアプリケーション インスタンスでは、この HTML 出力を新たに生成するのではなく、キャッシュ内の共有出力フラグメントを使用できます。 詳細については、 Azure Cache for Redis ASP.NET 出力キャッシュ プロバイダーに関するページを参照してください。
カスタム Redis キャッシュの構築
Azure Cache for Redis は、基になる Redis サーバーのファサードとして機能します。 Azure Redis キャッシュの対象ではない高度な構成 (53 GB を超えるキャッシュなど) が必要な場合は、Azure Virtual Machines を使用して独自の Redis サーバーを構築してホストできます。
レプリケーションを実装する場合は、プライマリ ノードと下位ノードとして機能する複数の VM を作成する必要があるため、これは複雑になる可能性があるプロセスです。 さらに、クラスターを作成する場合は、複数のプライマリサーバーと下位サーバーが必要です。 高可用性とスケーラビリティを提供する最小限のクラスター化レプリケーション トポロジは、プライマリ/下位サーバーの 3 つのペアとして編成された少なくとも 6 つの VM で構成されます (クラスターには少なくとも 3 つのプライマリ ノードが含まれている必要があります)。
各プライマリと下位のペアは、待機時間を最小限に抑えるために、近くに配置する必要があります。 ただし、キャッシュされたデータを使用する可能性が最も高いアプリケーションの近くに配置する場合は、ペアの各セットを異なるリージョンにある異なる Azure データセンターで実行できます。 Azure VM として実行されている Redis ノードの構築と構成の例については、「Azure での CentOS Linux VM での Redis の実行」を参照してください。
注
この方法で独自の Redis Cache を実装する場合は、サービスの監視、管理、セキュリティ保護を行う必要があります。
Redis キャッシュのパーティション分割
キャッシュをパーティション分割するには、複数のコンピューターにキャッシュを分割する必要があります。 この構造では、次のような 1 つのキャッシュ サーバーを使用する場合よりもいくつかの利点があります。
- 1 台のサーバーに格納できるキャッシュよりもはるかに大きいキャッシュを作成する。
- サーバー間でデータを分散し、可用性を向上させます。 1 台のサーバーで障害が発生したり、アクセスできなくなったりした場合、そのサーバーが保持しているデータは使用できませんが、残りのサーバー上のデータには引き続きアクセスできます。 キャッシュの場合、これは重要ではありません。キャッシュされたデータは、データベースに保持されているデータの一時的なコピーに過ぎません。 アクセス不能になったサーバー上のキャッシュされたデータは、代わりに別のサーバーにキャッシュできます。
- サーバー間で負荷を分散し、パフォーマンスとスケーラビリティを向上させます。
- データにアクセスするユーザーの近くにデータを地理的に割り当て、待機時間を短縮します。
キャッシュの場合、パーティション分割の最も一般的な形式はシャーディングです。 この戦略では、各パーティション (またはシャード) は独自の Redis キャッシュです。 データはシャーディング ロジックを使用して特定のパーティションに転送されます。このロジックでは、さまざまな方法を使用してデータを分散できます。 シャーディング パターンは、シャーディングの実装に関する詳細情報を提供します。
Redis キャッシュにパーティション分割を実装するには、次のいずれかの方法を使用できます。
- サーバー側のクエリ ルーティング。 この手法では、クライアント アプリケーションは、キャッシュ (おそらく最も近いサーバー) を構成する Redis サーバーのいずれかに要求を送信します。 各 Redis サーバーには、保持するパーティションを記述するメタデータと、他のサーバーに配置されているパーティションに関する情報が格納されます。 Redis サーバーは、クライアント要求を調べます。 ローカルで解決できる場合は、要求された操作が実行されます。 それ以外の場合は、要求が適切なサーバーに転送されます。 このモデルは Redis クラスタリングによって実装され、Redis Web サイトの Redis クラスターのチュートリアル ページで詳しく説明されています。 Redis クラスタリングはクライアント アプリケーションに対して透過的であり、クライアントを再構成しなくても、追加の Redis サーバーをクラスターに追加 (および再パーティション分割) できます。
- クライアント側のパーティション分割。 このモデルでは、クライアント アプリケーションには、要求を適切な Redis サーバーにルーティングするロジック (場合によってはライブラリの形式) が含まれています。 この方法は、Azure Cache for Redis で使用できます。 複数の Azure Cache for Redis (データ パーティションごとに 1 つ) を作成し、要求を正しいキャッシュにルーティングするクライアント側ロジックを実装します。 パーティション分割スキームが変更された場合 (たとえば、追加の Azure Cache for Redis が作成された場合)、クライアント アプリケーションの再構成が必要になる場合があります。
- プロキシによるパーティション分割。 このスキームでは、クライアント アプリケーションは中間プロキシ サービスに要求を送信します。これにより、データのパーティション分割方法が理解され、要求が適切な Redis サーバーにルーティングされます。 この方法は、Azure Cache for Redis でも使用できます。プロキシ サービスは、Azure クラウド サービスとして実装できます。 この方法では、サービスを実装するためにさらに複雑なレベルが必要です。要求の実行には、クライアント側のパーティション分割を使用するよりも時間がかかる場合があります。
ページ のパーティション分割: Redis Web サイト上の複数の Redis インスタンス間でデータを分割する方法 は、Redis でのパーティション分割の実装に関する詳細情報を提供します。
Redis Cache クライアント アプリケーションを実装する
Redis では、多数のプログラミング言語で記述されたクライアント アプリケーションがサポートされています。 .NET Framework を使用して新しいアプリケーションをビルドする場合は、StackExchange.Redis クライアント ライブラリを使用することをお勧めします。 このライブラリには、Redis サーバーへの接続、コマンドの送信、応答の受信の詳細を抽象化する .NET Framework オブジェクト モデルが用意されています。 これは、Visual Studio で NuGet パッケージとして使用できます。 この同じライブラリを使用して、Azure Cache for Redis または VM でホストされているカスタム Redis キャッシュに接続できます。
Redis サーバーに接続するには、Connect クラスの静的ConnectionMultiplexer メソッドを使用します。 このメソッドによって作成される接続は、クライアント アプリケーションの有効期間を通じて使用するように設計されており、同じ接続を複数の同時実行スレッドで使用できます。 Redis 操作を実行するたびに再接続および切断しないでください。これはパフォーマンスが低下する可能性があるためです。
Redis ホストのアドレスやパスワードなど、接続パラメーターを指定できます。 Azure Cache for Redis を使用する場合、パスワードは、Azure portal を使用して Azure Cache for Redis 用に生成されるプライマリ キーまたはセカンダリ キーです。
Redis サーバーに接続したら、キャッシュとして機能する Redis データベース上のハンドルを取得できます。 Redis 接続には、これを行う GetDatabase メソッドが用意されています。 その後、 StringGet メソッドと StringSet メソッドを使用して、キャッシュから項目を取得し、キャッシュにデータを格納できます。 これらのメソッドは、キーをパラメーターとして受け取り、一致する値 (StringGet) を持つキャッシュ内の項目を返すか、このキー (StringSet) を使用して項目をキャッシュに追加します。
Redis サーバーの場所によっては、要求がサーバーに送信され、応答がクライアントに返される間、多くの操作で待機時間が発生する可能性があります。 StackExchange ライブラリには、クライアント アプリケーションの応答性を維持するために公開されている多くのメソッドの非同期バージョンが用意されています。 これらのメソッドは、.NET Framework の タスク ベースの非同期パターン をサポートします。
次のコード スニペットは、 RetrieveItemという名前のメソッドを示しています。 Redis と StackExchange ライブラリに基づくキャッシュアサイド パターンの実装を示します。 このメソッドは文字列キー値を受け取り、 StringGetAsync メソッド ( StringGetの非同期バージョン) を呼び出して、Redis キャッシュから対応する項目を取得しようとします。
項目が見つからない場合は、 GetItemFromDataSourceAsync メソッド (StackExchange ライブラリの一部ではなくローカル メソッド) を使用して、基になるデータ ソースからフェッチされます。 その後、 StringSetAsync メソッドを使用してキャッシュに追加されるため、次回より迅速に取得できます。
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
StringGetメソッドとStringSet メソッドは、文字列値の取得または格納に限定されません。 バイト配列としてシリアル化された任意の項目を受け取ることができます。 .NET オブジェクトを保存する必要がある場合は、それをバイト ストリームとしてシリアル化し、 StringSet メソッドを使用してキャッシュに書き込むことができます。
同様に、 StringGet メソッドを使用して.NET オブジェクトとして逆シリアル化することで、キャッシュからオブジェクトを読み取ることができます。 次のコードは、IDatabase インターフェイスの一連の拡張メソッド (Redis 接続の GetDatabase メソッドが IDatabase オブジェクトを返します)、これらのメソッドを使用して BlogPost オブジェクトを読み取り、キャッシュに書き込むサンプル コードを示しています。
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
次のコードは、 RetrieveBlogPost という名前のメソッドを示しています。これらの拡張メソッドを使用して、キャッシュアサイド パターンに従って、シリアル化可能な BlogPost オブジェクトを読み取り、キャッシュに書き込みます。
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis では、クライアント アプリケーションが複数の非同期要求を送信する場合、コマンド パイプライン処理がサポートされます。 Redis では、厳密な順序でコマンドを受信して応答するのではなく、同じ接続を使用して要求を多重化できます。
この方法は、ネットワークをより効率的に使用することで待機時間を短縮するのに役立ちます。 次のコード スニペットは、2 人の顧客の詳細を同時に取得する例を示しています。 コードは 2 つの要求を送信し、結果の受信を待機する前に他の処理 (表示されません) を実行します。 キャッシュ オブジェクトの Wait メソッドは、.NET Framework Task.Wait メソッドに似ています。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Azure Cache for Redis を使用できるクライアント アプリケーションの作成の詳細については、 Azure Cache for Redis のドキュメントを参照してください。 詳細については、 StackExchange.Redis も参照してください。
同じ Web サイトのページ パイプラインとマルチプレクサー は、Redis と StackExchange ライブラリを使用した非同期操作とパイプライン処理に関する詳細情報を提供します。
Redis キャッシュの使用
キャッシュに関する Redis の最も簡単な使用方法は、キーと値のペアです。ここで、値は任意の長さの解釈されていない文字列であり、任意のバイナリ データを含めることができます。 (基本的には、文字列として扱うことができるバイトの配列です)。 このシナリオは、この記事の前の「Redis Cache クライアント アプリケーションを実装する」セクションで説明しました。
キーには解釈されないデータも含まれているため、任意のバイナリ情報をキーとして使用できます。 ただし、キーが長いほど、格納に要する領域が多くなり、検索操作の実行にかかる時間が長くなります。 使いやすさとメンテナンスを容易にするために、キースペースを慎重に設計し、意味のある (詳細ではない) キーを使用します。
たとえば、"customer:100" などの構造化キーを使用して、単に "100" ではなく ID 100 の顧客のキーを表します。 このスキームを使用すると、異なるデータ型を格納する値を簡単に区別できます。 たとえば、キー "orders:100" を使用して、ID 100 の注文のキーを表すこともできます。
1 次元のバイナリ文字列とは別に、Redis キーと値のペアの値は、リスト、セット (並べ替え済みおよび並べ替えなし)、ハッシュなど、より構造化された情報を保持することもできます。 Redis には、これらの型を操作できる包括的なコマンド セットが用意されています。これらのコマンドの多くは、StackExchange などのクライアント ライブラリを介して .NET Framework アプリケーションで使用できます。 「Redis Web サイトでの Redis データ型と抽象化の概要 」ページでは、これらの型の詳細な概要と、それらを操作するために使用できるコマンドについて説明します。
このセクションでは、これらのデータ型とコマンドの一般的なユース ケースをいくつかまとめます。
アトミック操作とバッチ操作を実行する
Redis では、文字列値に対する一連のアトミックな取得および設定操作がサポートされています。 これらの操作により、個別の GET コマンドと SET コマンドを使用する場合に発生する可能性のある競合の危険性が排除されます。 使用できる操作は次のとおりです。
INCR、INCRBY、DECR、およびDECRBY。整数の数値データ値に対してアトミックインクリメントおよびデクリメント演算を実行します。 StackExchange ライブラリには、これらの操作を実行し、キャッシュに格納されている結果の値を返すために、IDatabase.StringIncrementAsyncメソッドとIDatabase.StringDecrementAsyncメソッドのオーバーロードされたバージョンが用意されています。 次のコード スニペットは、これらのメソッドの使用方法を示しています。ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET: キーに関連付けられている値を取得し、新しい値に変更します。 StackExchange ライブラリを使用すると、IDatabase.StringGetSetAsyncメソッドを使用してこの操作を使用できるようになります。 次のコード スニペットは、このメソッドの例を示しています。 このコードは、前の例のキー "data:counter" に関連付けられている現在の値を返します。 その後、同じ操作の一部として、このキーの値がすべて 0 にリセットされます。ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETとMSET。文字列値のセットを 1 回の操作として返したり変更したりできます。 次の例に示すように、この機能をサポートするために、IDatabase.StringGetAsyncメソッドとIDatabase.StringSetAsyncメソッドがオーバーロードされています。ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
この記事の前の「Redis トランザクションとバッチ」セクションで説明したように、複数の操作を 1 つの Redis トランザクションに結合することもできます。 StackExchange ライブラリは、 ITransaction インターフェイスを介したトランザクションのサポートを提供します。
ITransaction メソッドを使用して、IDatabase.CreateTransaction オブジェクトを作成します。
ITransaction オブジェクトによって提供されるメソッドを使用して、トランザクションに対してコマンドを呼び出します。
ITransaction インターフェイスは、すべてのメソッドが非同期である点を除き、IDatabase インターフェイスがアクセスするメソッドのセットにアクセスできます。 これは、 ITransaction.Execute メソッドが呼び出されたときにのみ実行されることを意味します。
ITransaction.Execute メソッドによって返される値は、トランザクションが正常に作成された (true) か、失敗した (false) かを示します。
次のコード スニペットは、同じトランザクションの一部として 2 つのカウンターをインクリメントおよびデクリメントする例を示しています。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Redis トランザクションはリレーショナル データベースのトランザクションとは異なる点に注意してください。
Executeメソッドは、実行するトランザクションを構成するすべてのコマンドをキューに入れ、いずれかの形式が正しくない場合は、トランザクションが停止されます。 すべてのコマンドが正常にキューに登録されている場合、各コマンドは非同期的に実行されます。
コマンドが失敗しても、他のコマンドは引き続き処理を続行します。 コマンドが正常に完了したことを確認する必要がある場合は、上記の例に示すように、対応するタスクの Result プロパティを使用してコマンドの結果をフェッチする必要があります。 Result プロパティを読み取ると、タスクが完了するまで呼び出し元のスレッドがブロックされます。
詳細については、「 Redis のトランザクション」を参照してください。
バッチ操作を実行するときは、StackExchange ライブラリの IBatch インターフェイスを使用できます。 このインターフェイスは、すべてのメソッドが非同期である点を除き、 IDatabase インターフェイスがアクセスするメソッドと同様のメソッドのセットへのアクセスを提供します。
次の例に示すように、IBatch メソッドを使用してIDatabase.CreateBatch オブジェクトを作成し、IBatch.Execute メソッドを使用してバッチを実行します。 このコードは、単に文字列値を設定し、前の例で使用したのと同じカウンターをインクリメントおよびデクリメントして、結果を表示します。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
トランザクションとは異なり、バッチ内のコマンドが形式が正しくないために失敗した場合でも、他のコマンドが引き続き実行される可能性があることを理解しておくことが重要です。
IBatch.Execute メソッドは、成功または失敗の兆候を返しません。
起動およびキャッシュの削除操作を実行する
Redis では、コマンド フラグを使用して、ファイア アンド フォーゲット操作をサポートしています。 この状況では、クライアントは単に操作を開始しますが、結果には関心がなく、コマンドが完了するまで待機しません。 次の例は、INCR コマンドをファイア アンド フォーゲット操作として実行する方法を示しています。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
自動的に期限切れのキーを指定する
Redis キャッシュに項目を格納する場合、タイムアウトを指定すると、その後、項目がキャッシュから自動的に削除されます。
TTL コマンドを使用して、キーの有効期限が切れるまでの時間を照会することもできます。 このコマンドは、 IDatabase.KeyTimeToLive メソッドを使用して StackExchange アプリケーションで使用できます。
次のコード スニペットは、キーの有効期限を 20 秒に設定し、キーの残りの有効期間を照会する方法を示しています。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
また、stackExchange ライブラリで KeyExpireAsync メソッドとして使用できる EXPIRE コマンドを使用して、有効期限を特定の日時に設定することもできます。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
ヒント
IDatabase.KeyDeleteAsync メソッドとして StackExchange ライブラリから使用できる DEL コマンドを使用して、キャッシュから項目を手動で削除できます。
タグを使用してキャッシュされた項目を相互に関連付ける
Redis セットは、1 つのキーを共有する複数の項目のコレクションです。 SADD コマンドを使用してセットを作成できます。 SMEMBERS コマンドを使用して、セット内の項目を取得できます。 StackExchange ライブラリは、 IDatabase.SetAddAsync メソッドを使用して SADD コマンドを、 IDatabase.SetMembersAsync メソッドを使用して SMEMBERS コマンドを実装します。
また、SDIFF (差分セット)、SINTER (集合交差)、および SUNION (集合和集合) コマンドを使用して、既存のセットを結合して新しいセットを作成することもできます。 StackExchange ライブラリは、 IDatabase.SetCombineAsync メソッドでこれらの操作を統合します。 このメソッドの最初のパラメーターは、実行する set 操作を指定します。
次のコード スニペットは、関連する項目のコレクションをすばやく格納および取得するためにセットがどのように役立つのかを示しています。 このコードでは、この記事の「Redis Cache クライアント アプリケーションの実装」セクションで説明した BlogPost の種類を使用します。
BlogPost オブジェクトには、ID、タイトル、ランク付けスコア、タグのコレクションの 4 つのフィールドが含まれています。 次の最初のコード スニペットは、 BlogPost オブジェクトの C# リストの設定に使用されるサンプル データを示しています。
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
各 BlogPost オブジェクトのタグをセットとして Redis キャッシュに格納し、各セットを BlogPostの ID に関連付けることができます。 これにより、アプリケーションは特定のブログ投稿に属するすべてのタグをすばやく見つけることができます。 反対方向の検索を有効にし、特定のタグを共有するすべてのブログ投稿を検索するには、キー内のタグ ID を参照するブログ投稿を保持する別のセットを作成します。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
これらの構造を使用すると、多くの一般的なクエリを非常に効率的に実行できます。 たとえば、次のようにブログ投稿 1 のすべてのタグを見つけて表示できます。
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
次のように、設定された交差操作を実行することで、ブログ投稿 1 とブログ投稿 2 に共通するすべてのタグを見つけることができます。
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
また、特定のタグを含むすべてのブログ投稿を見つけることができます。
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
最近アクセスしたアイテムを検索する
多くのアプリケーションに必要な一般的なタスクは、最近アクセスされた項目を見つけることです。 たとえば、ブログ サイトでは、最近読んだブログ投稿に関する情報を表示できます。
この機能は、Redis リストを使用して実装できます。 Redis リストには、同じキーを共有する複数の項目が含まれています。 リストは、ダブルエンド キューとして機能します。 LPUSH (左プッシュ) コマンドと RPUSH (右プッシュ) コマンドを使用して、リストの末尾に項目をプッシュできます。 LPOP コマンドと RPOP コマンドを使用して、リストの両端から項目を取得できます。 LRANGE および RRANGE コマンドを使用して、一連の要素を返すこともできます。
次のコード スニペットは、StackExchange ライブラリを使用してこれらの操作を実行する方法を示しています。 このコードでは、前の例の BlogPost 型を使用します。 ユーザーがブログ投稿を読み取る場合、 IDatabase.ListLeftPushAsync メソッドは、Redis キャッシュ内のキー "blog:recent_posts" に関連付けられているリストにブログ投稿のタイトルをプッシュします。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
より多くのブログ投稿が読まれると、タイトルは同じリストにプッシュされます。 リストは、タイトルが追加された順序で並べ替えます。 最近読んだブログの投稿は、リストの左端にあります。 (同じブログ投稿を複数回読むと、リストに複数のエントリが含まれるようになります)。
IDatabase.ListRange メソッドを使用して、最近読んだ投稿のタイトルを表示できます。 このメソッドは、リスト、開始点、および終了ポイントを含むキーを受け取ります。 次のコードは、リストの左端にある 10 件のブログ投稿 (0 から 9 の項目) のタイトルを取得します。
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
ListRangeAsync メソッドはリストから項目を削除しません。 これを行うには、 IDatabase.ListLeftPopAsync メソッドと IDatabase.ListRightPopAsync メソッドを使用できます。
リストが無期限に拡大するのを防ぐために、リストをトリミングすることで定期的にアイテムをカリングできます。 次のコード スニペットは、一覧から 5 つの左端の項目を除くすべてを削除する方法を示しています。
await cache.ListTrimAsync(redisKey, 0, 5);
リーダー ボードを実装する
既定では、セット内の項目は特定の順序で保持されません。 順序付きセットは、ZADD コマンド (StackExchange ライブラリの IDatabase.SortedSetAdd メソッド) を使用して作成できます。 項目は、コマンドのパラメーターとして提供されるスコアと呼ばれる数値を使用して並べ替えられます。
次のコード スニペットは、ブログ投稿のタイトルを順序付きリストに追加します。 この例では、各ブログ投稿には、ブログ投稿のランキングを含むスコア フィールドもあります。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
IDatabase.SortedSetRangeByRankWithScoresメソッドを使用して、ブログ投稿のタイトルとスコアを昇順で取得できます。
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
注
StackExchange ライブラリには、スコア順にデータを返す IDatabase.SortedSetRangeByRankAsync メソッドも用意されていますが、スコアは返されません。
また、スコアの降順で項目を取得し、 IDatabase.SortedSetRangeByRankWithScoresAsync メソッドに追加のパラメーターを指定して返される項目の数を制限することもできます。 次の例では、上位 10 件のランク付けされたブログ投稿のタイトルとスコアを表示します。
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
次の例では、 IDatabase.SortedSetRangeByScoreWithScoresAsync メソッドを使用します。これを使用して、返される項目を特定のスコア範囲内に収まる項目に制限できます。
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
チャネルを使用したメッセージ
Redis サーバーは、データ キャッシュとして機能するだけでなく、高パフォーマンスのパブリッシャー/サブスクライバー メカニズムを介してメッセージングを提供します。 クライアント アプリケーションはチャネルをサブスクライブでき、他のアプリケーションまたはサービスはチャネルにメッセージを発行できます。 その後、サブスクライブしているアプリケーションはこれらのメッセージを受信し、処理できます。
Redis には、チャネルのサブスクライブに使用するクライアント アプリケーション用の SUBSCRIBE コマンドが用意されています。 このコマンドは、アプリケーションがメッセージを受け入れる 1 つ以上のチャネルの名前を受け入れます。 StackExchange ライブラリには、 ISubscription インターフェイスが含まれています。これにより、.NET Framework アプリケーションはチャネルをサブスクライブして発行できます。
redis サーバーへの接続のISubscriptionメソッドを使用して、GetSubscriber オブジェクトを作成します。 次に、このオブジェクトの SubscribeAsync メソッドを使用して、チャネル上のメッセージをリッスンします。 次のコード例は、"messages:blogPosts" という名前のチャネルをサブスクライブする方法を示しています。
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Subscribe メソッドの最初のパラメーターは、チャネルの名前です。 この名前は、キャッシュ内のキーで使用されるのと同じ規則に従います。 名前には任意のバイナリ データを含めることができますが、パフォーマンスと保守容易性を確保するために、比較的短く意味のある文字列を使用することをお勧めします。
また、チャネルによって使用される名前空間は、キーによって使用される名前空間とは別であることにも注意してください。 つまり、同じ名前のチャネルとキーを持つことができますが、これにより、アプリケーション コードの保守が困難になる可能性があります。
2 番目のパラメーターは Action デリゲートです。 このデリゲートは、チャネルに新しいメッセージが表示されるたびに非同期的に実行されます。 この例では、コンソールにメッセージを表示するだけです (メッセージにはブログ投稿のタイトルが含まれます)。
チャネルに発行するには、アプリケーションで Redis PUBLISH コマンドを使用できます。 StackExchange ライブラリには、この操作を実行するための IServer.PublishAsync メソッドが用意されています。 次のコード スニペットは、"messages:blogPosts" チャネルにメッセージを発行する方法を示しています。
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
パブリッシュ/サブスクライブ メカニズムについて理解しておく必要がある点がいくつかあります。
- 複数のサブスクライバーが同じチャネルにサブスクライブでき、そのチャネルに発行されたメッセージがすべて受信されます。
- サブスクライバーは、サブスクライブした後に発行されたメッセージのみを受信します。 チャネルはバッファリングされず、メッセージが発行されると、Redis インフラストラクチャによって各サブスクライバーにメッセージがプッシュされ、削除されます。
- 既定では、メッセージはサブスクライバーによって送信された順序で受信されます。 メッセージの数が多く、サブスクライバーやパブリッシャーが多い非常にアクティブなシステムでは、メッセージの順次配信が保証されると、システムのパフォーマンスが低下する可能性があります。 各メッセージが独立していて、順序が重要でない場合は、Redis システムによる同時処理を有効にすることができます。これは、応答性の向上に役立ちます。 これを StackExchange クライアントで実現するには、サブスクライバーによって使用される接続の PreserveAsyncOrder を false に設定します。
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
シリアル化に関する考慮事項
シリアル化形式を選択する場合は、パフォーマンス、相互運用性、バージョン管理、既存のシステムとの互換性、データ圧縮、メモリオーバーヘッドのトレードオフを検討してください。 パフォーマンスを評価するときは、ベンチマークがコンテキストに大きく依存していることを覚えておいてください。 実際のワークロードが反映されていない可能性があり、新しいライブラリやバージョンを考慮しない場合があります。 すべてのシナリオに対して 1 つの "最速" シリアライザーはありません。
考慮すべきオプションには次のようなものがあります:
プロトコル バッファー (protobuf とも呼ばれます) は、構造化データを効率的にシリアル化するために Google によって開発されたシリアル化形式です。 厳密に型指定された定義ファイルを使用してメッセージ構造を定義します。 これらの定義ファイルは、メッセージをシリアル化および逆シリアル化するために言語固有のコードにコンパイルされます。 Protobuf は、既存の RPC メカニズムで使用することも、RPC サービスを生成することもできます。
Apache Thrift は、厳密に型指定された定義ファイルとコンパイル 手順を使用して、シリアル化コードと RPC サービスを生成する同様のアプローチを使用します。
Apache Avro はプロトコル バッファーと Thrift と同様の機能を提供しますが、コンパイル手順はありません。 代わりに、シリアル化されたデータには、構造を記述するスキーマが常に含まれます。
JSON は、人間が判読できるテキスト フィールドを使用するオープン標準です。 広範なクロスプラットフォーム サポートがあります。 JSON ではメッセージ スキーマは使用されません。 テキストベースの形式であるため、ネットワーク上では非常に効率的ではありません。 ただし、場合によっては、キャッシュされた項目を HTTP 経由でクライアントに直接返す場合があります。その場合、JSON を格納すると、別の形式から逆シリアル化してから JSON にシリアル化するコストが節約される可能性があります。
binary JSON (BSON) は、JSON に似た構造を使用するバイナリシリアル化形式です。 BSON は、JSON に対して軽量で、スキャンが簡単で、シリアル化と逆シリアル化が高速に行われるよう設計されています。 ペイロードのサイズは JSON と同等です。 データによっては、BSON ペイロードが JSON ペイロードよりも小さいか大きくなる場合があります。 BSON には、JSON では使用できない追加のデータ型がいくつかあります。特に、BinData (バイト配列の場合) と Date です。
MessagePack は、ワイヤ経由の伝送用にコンパクトに設計されたバイナリ シリアル化形式です。 メッセージ スキーマやメッセージ型チェックはありません。
Bond は、スキーマ化されたデータを操作するためのクロスプラットフォーム フレームワークです。 言語間のシリアル化と逆シリアル化がサポートされています。 ここに示す他のシステムとの主な違いは、継承、型エイリアス、ジェネリックのサポートです。
gRPC は、Google によって開発されたオープンソース RPC システムです。 既定では、プロトコル バッファーを定義言語および基になるメッセージ交換形式として使用します。
次のステップ
- Azure Cache for Redis のドキュメント
- Azure Cache for Redis に関する FAQ
- タスク ベースの非同期パターン
- Redis のドキュメント
- StackExchange.Redis です。
- データパーティション分割ガイド
関連リソース
次のパターンは、アプリケーションにキャッシュを実装する場合のシナリオにも関連する可能性があります。
キャッシュアサイド パターン: このパターンでは、データ ストアからキャッシュにオンデマンドでデータを読み込む方法について説明します。 このパターンは、キャッシュに保持されているデータと元のデータ ストア内のデータとの間の一貫性を維持するのにも役立ちます。
シャーディング パターンは、大量のデータを格納してアクセスするときのスケーラビリティを向上させるために役立つ水平パーティション分割の実装に関する情報を提供します。