クラウドで実行される分散アプリケーションとサービスは、その性質上、多数の変化する部分で構成される複雑なソフトウェアです。 運用環境では、ユーザーがシステムを使用する方法を追跡し、リソース使用率をトレースし、さらにシステムの正常性とパフォーマンスを全般的に監視できることが重要です。 ここに記載する情報を診断に使用して、問題の検出と修正を行うことができます。さらに、潜在的な問題を見つけてその発生を防止するために役立てることもできます。
監視と診断のシナリオ
監視を行うと、システムがどの程度正常に機能しているかを知ることができます。 監視は、サービス品質目標を維持するための非常に重要な要素です。 監視データを収集する一般的なシナリオは、次のとおりです。
- システムが正常な状態を保っていることの確認。
- システムとそのコンポーネント要素の可用性の追跡。
- 作業量が増加したときに、システムのスループットが予想外に低下しないことを保証するパフォーマンスの維持。
- 顧客と合意したサービス レベル アグリーメント (SLA) をシステムが満たしていることの保証。
- システム、ユーザー、およびそのデータのプライバシーとセキュリティの保護。
- 監査または規制を目的として実行される操作の追跡。
- システムの毎日の使用状況の監視と、対応しなかった場合に問題となる可能性がある傾向の発見。
- 発生した問題の追跡 (初期報告から、考えられる原因の分析、修正、ソフトウェア更新、およびデプロイメントに至るまで)。
- 操作のトレースとソフトウェア リリースのデバッグ。
注意
この一覧は包括的なものではありません。 このドキュメントでは、監視を実行するための最も一般的な状況として、これらのシナリオに注目します。 より一般的でないシナリオや、環境に固有のシナリオが存在する可能性もあります。
以降のセクションで、これらのシナリオについて詳しく説明します。 各シナリオの情報は、次の形式で説明されます。
- シナリオの概要。
- このシナリオの一般的な要件。
- シナリオをサポートするために必要な生のインストルメンテーション データと、その情報の考えられるソース。
- 生データの分析と結合を行って、意味のある診断情報を生成する方法。
正常性の監視
システムは、稼働して要求を処理できていれば、正常な状態にあります。 正常性監視の目的は、システムの現在の状態のスナップショットを生成して、システムのすべてのコンポーネントが予期されているとおりに動作していることを確認することです。
正常性を監視するための要件
システムの一部で正常でない状態が認められた場合は、オペレーターにただちに (瞬時に) 知らせる必要があります。 オペレーターは、システムのどの部分が正常に機能し、どの部分に問題が発生しているかを確認できる必要があります。 システムの正常性は、信号機システムを使用して強調表示できます。
- 異常は赤 (システムが停止)
- 部分的に正常は黄 (システムは実行されているが機能は制限される)
- 完全に正常は緑
オペレーターは、システムの包括的な正常性監視によって、システムをドリル ダウンしてサブシステムとコンポーネントの正常性の状態を確認できます。 たとえば、システム全体が部分的に正常な状態であると指示された場合、オペレーターはズーム インして、どの機能が現在使用できないかを判断できる必要があります。
データ ソース、インストルメンテーション、およびデータ収集の要件
正常性監視をサポートするために必要な生データは、以下の結果として生成できます。
- ユーザー要求の実行のトレース。 この情報は、どの要求が成功し、どれが失敗しているかに加え、各要求の所要時間を判断するために使用できます。
- 模擬ユーザーの監視。 このプロセスは、ユーザーが実行する手順をシミュレートし、定義済みの一連の手順に従います。 各手順の結果をキャプチャする必要があります。
- 例外、エラー、および警告のロギング。 この情報は、アプリケーション コードに埋め込まれたトレース ステートメントの結果としてキャプチャでき、システムが参照するすべてのサービスのイベント ログから情報を取得できます。
- システムが使用するすべてのサードパーティ サービスの正常性の監視。 この監視には、これらのサービスによって提供される正常性データを取得して解析しなければならない場合があります。 この情報は、さまざまな形式で提供される可能性があります。
- エンドポイントの監視。 このメカニズムについては、「可用性の監視」セクションで詳しく説明します。
- バック グラウンドでの CPU 使用率や (ネットワークを含む) I/Oアクティビティなどの環境パフォーマンス情報の収集。
正常性データの分析
正常性監視の主な目的は、システムが稼働しているかどうかをただちに示すことです。 即時データのホット分析は、重要なコンポーネントで異常が検出された場合はアラートをトリガーできます (たとえば、一連の ping に応答しない場合)。その後、オペレーターが適切な修正措置を実行できます。
より高度なシステムには、最近のワークロードと現在のワークロードのコールド分析を実行する予測要素が含まれることがあります。 コールド分析は、傾向を発見し、システムが正常な状態を維持できるかどうかや、追加リソースが必要かどうかを判断することができます。 この予測要素は、次のような重要なパフォーマンス メトリックに基づいている必要があります。
- 各サービスまたはサブシステムに送信される要求の割合。
- これらの要求の応答時間。
- 各サービス間で送受信されるデータの量。
いずれかのメトリックの値が定義されたしきい値を超えた場合、システムは、システムの正常性を維持するために必要な予防措置を取ることができるようにオペレーターにアラートを発行するか、使用可能な場合は自動スケールを実行します。 予防措置には、リソースの追加、エラーが発生している 1 つ以上のサービスの再起動、優先順位の低い要求に対する調整の適用などがあります。
可用性の監視
真に正常なシステムでは、システムを構成するコンポーネントとサブシステムが使用可能である必要があります。 可用性の監視は、正常性の監視と密接に関連しています。 ただし、正常性の監視はシステムの現在の正常性を提示しますが、可用性の監視は、システムとそのコンポーネントの可用性を追跡して、システムの稼働時間に関する統計情報を生成することに関係しています。
多くのシステムでは、一部のコンポーネント (データベースなど) は、重大なエラーまたは接続が失われた場合に迅速にフェールオーバーできる冗長性が組み込まれて構成されています。 理想的には、ユーザーはこのような障害が発生したことを認識すべきではありません。 しかし、可用性の監視の観点からは、このようなエラーに関する情報をできるだけ多く収集して原因を特定し、再発を防ぐための修正処置を取る必要があります。
可用性を追跡するために必要なデータは、さまざまな下位レベルの要因に依存します。 それらの要素の多くが、アプリケーション、システム、環境に固有のものである可能性があります。 効果的な監視システムは、これらの下位レベルの要因に対応する可用性データをキャプチャした後、それらを集積してシステムの全体像を提示します。 たとえば、e コマース システムでは、顧客からの受注を可能にするビジネス機能が、受注の詳細を保存するリポジトリと、受注の決済に関する金銭トランザクションを処理する決済システムに依存していることがあります。 このため、システムの受注部分の可用性は、リポジトリと決済サブシステムの可用性の関数になります。
可用性を監視するための要件
オペレーターは、各システムとサブシステムの可用性履歴を確認し、その情報を使用して、1 つ以上のサブシステムで定期的に障害を発生させる原因となる傾向を発見できる必要があります (たとえば、サービスのエラーが 1 日の特定の時間に始まるが、その時間は処理のピーク時間に対応している)。
監視ソリューションは、各サブシステムの現在と過去の可用性と非可用性を表示する能力を備えている必要があります。 1 つ以上のサービスが失敗した場合、またはユーザーがサービスに接続できない場合は、オペレーターにすぐに通知する能力も必要です。 これは、単に各サービスを監視すればよいという問題ではなく、ユーザーがサービスと通信しようとしたときに、ユーザーが実行しようとして失敗したアクションを調べる必要があることも意味します。 接続エラーはある程度一般的であり、一時的なエラーが原因の場合があります。 しかし、特定の期間に特定のサブシステムで発生した接続エラーの数に関するアラートをシステムが生成できるようにしておくと役に立つことがあります。
データ ソース、インストルメンテーション、およびデータ収集の要件
正常性の監視と同じように、可用性の監視をサポートするために必要な生データは、模擬ユーザーの監視と、発生したすべての例外、エラー、および警告のログの結果として生成できます。 さらに、エンドポイントの監視を実行することからも可用性データを取得できます。 アプリケーションは、それぞれがシステム内の機能領域へのアクセスをテストする 1 つ以上の正常性エンドポイントを公開できます。 監視システムは、定義されたスケジュールに従って各エンドポイントに対して ping を実行し、結果 (成功または失敗) を収集できます。
すべてのタイムアウト、ネットワーク接続エラー、および接続試行回数を記録する必要があります。 すべてのデータに、タイムスタンプを付ける必要があります。
可用性データの分析
次の種類の分析をサポートするには、インストルメンテーション データを集めて相関させる必要があります。
- システムとサブシステムの即時可用性。
- システムとサブシステムの可用性エラー率。 理想的には、オペレーターは、エラーを特定のアクティビティに相関させて、システムが失敗したときに何が発生したかを判断できる必要があります。
- 特定の期間中のシステムまたはサブシステムのエラー率の履歴ビュー、およびエラー発生時のシステムの負荷 (ユーザー要求の数など)。
- システムまたはサブシステムを使用できない理由。 たとえば、サービスが実行されていない、接続が失われた、接続したがタイムアウトした、接続したがエラーが返されたなど。
次の式を使用して、特定の期間のサービスの可用性の割合を計算できます。
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
これは SLA に対応するために役立ちます (SLA の監視については、このガイダンスの中で後述します)。"ダウンタイム" の定義は、サービスによって異なります。 たとえば、Visual Studio Team Services ビルド サービスでは、ダウンタイムはビルド サービスを利用できない期間 (合計した蓄積分数) として定義されます。 お客様が開始した操作を実行するように求めるビルド サービスに対するすべての HTTP 要求が 1 分間連続してエラー コードで終わるか、応答が返されなかった場合に、ビルド サービスは 1 分間使用できなかったと見なされます。
パフォーマンスの監視
ユーザー数が増えてシステムにかかるストレスが大きくなるにつれて、ユーザーがアクセスするデータセットのサイズが増加し、1 つ以上のコンポーネントでエラーが発生する可能性が高くなります。 多くの場合、コンポーネント エラーが発生する前にパフォーマンスが低下します。 このような低下を検出できれば、状況を改善するための手順を前もって実行できます。
システムのパフォーマンスは、さまざまな要因に依存します。 各要素は、通常、1 秒あたりのデータベースのトランザクションの数や特定の期間内に処理されたネットワーク要求のボリュームなどの主要業績評価指標 (KPI) を使用して測定されます。 これらの KPI の一部は具体的なパフォーマンス メジャーとして使用でき、一部はメトリックの組み合わせから派生させることができます。
注意
パフォーマンスの高低を判断するには、システムが実行する必要があるパフォーマンス レベルを理解しておく必要があります。 そのためには、一般的な負荷の下で機能しているシステムを観察し、特定の期間にわたる各 KPI のデータをキャプチャする必要があります。 これには、テスト環境の中でシミュレートされた負荷をかけてシステムを実行し、運用環境にシステムをデプロイする前に適切なデータを収集することが含まれます。
さらに、パフォーマンスを監視することが、システムに負荷をかけないことを確認する必要があります。 パフォーマンス監視プロセスで収集するデータの詳細レベルを動的に調整できる場合があります。
パフォーマンスを監視するための要件
システムのパフォーマンスを調べるには、オペレーターは通常は次の情報を確認する必要があります。
- ユーザー要求に対する反応率。
- 同時ユーザー要求の数。
- ネットワーク トラフィックのボリューム。
- ビジネス トランザクションの完了率。
- 要求の平均処理時間。
オペレーターが次の項目間の相関関係を発見できるツールを用意すると、役に立つ可能性があります。
- 同時ユーザー数と要求待機時間 (ユーザーが要求を送信した後、処理が開始されるまでの時間)。
- 同時ユーザー数と平均応答時間 (要求の処理が開始された後、完了するまでの時間)。
- 要求のボリュームと処理エラー数。
この高レベルの機能情報だけでなく、オペレーターはシステム内の各コンポーネントのパフォーマンスの詳細を取得できる必要があります。 このデータは、通常、次のような情報を追跡する低レベルのパフォーマンス カウンターを通じて提供されます。
- メモリの使用率。
- スレッド数。
- CPU 処理時間。
- 要求キューの長さ。
- ディスクまたはネットワークの I/O 率とエラー。
- 読み書きされたバイト数。
- キューの長さなどのミドルウェア インジケーター。
すべての視覚化は、オペレーターが期間を指定して実行できる必要があります。 表示されるデータは、現在の状況のスナップショットまたはパフォーマンス履歴ビューになる可能性があります。
オペレーターは、パフォーマンス メジャーに基づいて、指定した期間中の特定の値に対するアラートを生成できる必要があります。
データ ソース、インストルメンテーション、およびデータ収集の要件
高レベルのパフォーマンス データ (スループット、同時ユーザー数、ビジネス トランザクション数、エラー率など) は、ユーザーの要求がシステムに到着して通過するときの進行状況を監視することで収集できます。 これには、アプリケーション コードの重要なポイントにトレース ステートメントを計時情報と共に組み込むことが含まれます。 すべてのエラー、例外、警告を、それらの原因となった要求に関連付けることができるように、十分なデータと共にキャプチャする必要があります。 インターネット インフォメーション サービス (IIS) ログは、もう 1 つの有用なソースです。
可能であれば、アプリケーションが使用しているすべての外部システムのパフォーマンス データもキャプチャする必要があります。 これらの外部システムは、パフォーマンス データを要求するための独自のパフォーマンス カウンターやその他の機能を備えている場合があります。 これが可能でない場合は、外部システムに対して行われた各要求の開始時刻と終了時刻などの情報を、操作の状態 (成功、失敗、または警告) と共に記録してください。 たとえば、ストップウォッチ アプローチを使用して要求を計時できます。要求の開始時にタイマーを開始し、要求の完了時にタイマーを停止します。
システム内の個々のコンポーネントの低レベルのパフォーマンス データは、Windows のパフォーマンス カウンターや Azure Diagnostics などの機能とサービスを使用して入手できる可能性があります。
パフォーマンス データの分析
分析作業の大部分は、パフォーマンス データを、ユーザー要求の種類別や、各要求が送信されたサブシステムまたはサービス別に集計することです。 ユーザー要求の例としては、ショッピング カートへのアイテムの追加や e コマース システムでの清算処理の実行などがあります。
別の一般的な要件は、選択したパーセンタイルにパフォーマンス データを集約することです。 たとえば、要求の 99%、要求の 95%、要求の 70% の応答時間を決定します。 各パーセンタイルに、SLA 目標またはその他の目標が設定されている場合があります。 現時点での結果は、緊急の問題を検出できるようにリアルタイムに近いタイミングで継続的に報告される必要があります。 また、統計的な目的で、長期にわたって集計する必要もあります。
パフォーマンスに影響を与える待機時間に関する問題が発生した場合、オペレーターは、各要求によって実行される各手順の待機時間を調べることで、ボトルネックの原因を短時間で特定できる必要があります。 したがって、パフォーマンス データは、各ステップのパフォーマンスの測定値を、特定の要求に関連付ける手段を持っている必要があります。
視覚化要件によっては、生データのビューを含むデータ キューブを生成して保存しておくと有用である可能性があります。 このデータ キューブを使用すると、パフォーマンス情報の複雑なアドホック クエリと分析を実行できます。
セキュリティの監視
機密データが含まれているすべての商用システムは、セキュリティ構造を実装する必要があります。 セキュリティ メカニズムの複雑さは、通常はデータの機密性の関数です。 ユーザー認証を必要とするシステムでは、次の内容を記録する必要があります。
- すべてのサインイン試行。それらが失敗するか成功するか。
- 認証ユーザーによって実行されたすべての操作と、アクセスされたすべてのリソースの詳細。
- ユーザーがいつセッションを終了し、サインアウトしたか。
監視は、システムに対する攻撃を検出するために役立つ可能性があります。 たとえば、失敗した多数のサインイン試行は、ブルート フォース攻撃を示している場合があります。 要求の予想外の急増は、分散型サービス拒否 (DDoS) 攻撃の結果である可能性があります。 これらの要求のソースに関係なく、すべてのリソースに対するすべての要求を監視するように準備する必要があります。 サインインの脆弱性があるシステムは、ユーザーに実際にサインインすることを要求せずに、誤ってリソースを外部に公開する可能性があります。
セキュリティを監視するための要件
セキュリティ監視の最も重要な側面は、オペレーターが次の操作をすばやく実行できるようにすることです。
- 認証されていないエンティティによる侵入の試みを検出する。
- エンティティが、アクセス権を与えられていないデータに対して操作を実行しようとしていることを識別する。
- システムまたはシステムの一部が、外部または内部から攻撃を受けているかどうかを判断する (たとえば、悪意のある認証ユーザーによるシステム停止の試み)。
これらの要件をサポートするために、オペレーターは、次の場合に通知を受け取る必要があります。
- 指定した期間内に同じアカウントによって行われたサインイン試行が繰り返し失敗している。
- 指定した期間内に同じ認証アカウントが、禁止されているリソースに繰り返しアクセスしようとしている。
- 指定した期間内に未認証または未承認の大量の要求が発生している。
オペレーターに提供される情報には、各要求のソースのホスト アドレスが含まれている必要があります。 セキュリティ違反が特定のアドレスの範囲から定期的に発生する場合は、これらのホストをブロックできる可能性があります。
システムのセキュリティを維持するうえでの重要な要素は、通常のパターンから逸脱しているアクションを迅速に検出できることです。 失敗または成功したサインイン要求数などの情報を視覚的に表示すると、普通でない時間にアクティビティが急上昇しているかどうかを検出しやすくなります (業務の開始時間が午前 9 時なのに、午前 3 時にサインインがあり、多数の操作が実行されている場合など)。 この情報は、時間に基づく自動スケールを構成するためにも役立ちます。 たとえば、オペレーターは、多数のユーザーが 1 日の特定の時点に定期的にサインインすることに気付いた場合は、大量のサインインを処理するための追加認証サービスを開始し、ピークが過ぎた後で追加サービスをシャットダウンするように設定できます。
データ ソース、インストルメンテーション、およびデータ収集の要件
セキュリティは、ほとんどの分散システムの包括的な側面です。 関連データは、システム全体の複数のポイントで生成される可能性があります。 アプリケーション、ネットワーク機器、サーバー、ファイアウォール、ウイルス対策ソフトウェア、およびその他の侵入防止要素によって生成されるイベントに起因するセキュリティ関連情報を収集するために、Security Information and Event Management (SIEM) アプローチの採用を考慮する必要があります。
セキュリティの監視では、アプリケーションの一部ではないツールからのデータを組み込むことができます。 そのようなツールとして、外部機関によるポート スキャン アクティビティを識別するユーティリティや、アプリケーションとデータに対する認証されていないアクセスの試みを検出するネットワーク フィルターなどがあります。
どの場合でも、収集されるデータは、管理者が攻撃の性質を特定し、適切な対策を取れるものである必要があります。
セキュリティ データの分析
セキュリティ監視の特徴は、データの発生源が多様であることです。 多くの場合、形式や詳細レベルが違うために、キャプチャされたデータを理路整然とした情報としてまとめるには複雑なデータ分析が必要です。 最も単純なケース (多数の失敗したサインインや、重要なリソースに対して繰り返される不正なアクセスの試みの検出など) は別として、セキュリティ データの複雑な処理を自動化して実行することはできない可能性があります。 代わりに、タイムスタンプを付けること以外は元の形式のままで、保護されたリポジトリにデータを書き込み、エキスパートが手動で分析できるようにする方が望ましいこともあります。
SLA の監視
有料顧客をサポートする多くの商用システムは、システムのパフォーマンスに関する保証を SLA の形で行っています。 基本的には、SLA は、システムが定義した仕事量を合意したタイム フレームの中で処理でき、重要な情報を失うことはないと言明します。 SLA の監視は、システムが測定可能な SLA を満たすことができることの保証に関係します。
注意
SLA の監視は、パフォーマンスの監視と密接に関連しています。 しかし、パフォーマンスの監視はシステムが "最適" に機能することの保証に関心があり、SLA の監視は "最適" が実際に何を意味するかを定義している契約上の義務の管理に関心があります。
SLA には、しばしば次の条件が定義されます。
- システム全体の可用性。 たとえば、組織は、システムが 99.9% の時間使用可能であることを保証する場合があります。 これは、ダウンタイムが年に 9 時間、週に約 10 分を超えないことに相当します。
- 操作のスループット。 この側面は、多くの場合、1 つ以上の高水準のウォーターマークとして表現され、システムが最大 100,000 人の同時ユーザーの要求をサポートできることや、10,000 件の同時ビジネス トランザクションを処理できることの保証などがあります。
- 操作の応答時間。 さらに、システムは、要求の処理速度に関する保証を行う場合があります。 たとえば、ビジネス トランザクション全体の 99% が 2 秒以内に完了することや、終了まで 10 秒以上かかるトランザクションは 1 つもないといったことです。
注意
商用システムの一部の契約には、カスタマー サポートに関する SLA も含まれることがあります。 たとえば、すべてのヘルプデスクへの要求が 5 分以内に応答され、すべての問題の 99% が 1 営業日以内に完全に対処されるといったことです。 効率のよい 問題追跡 (このセクションで後述します) は、SLA のこれらの条件を満たすために重要です。
SLA を監視するための要件
最上位レベルでは、オペレーターは、合意された SLA をシステムが満たしているかどうかをひとめで判断できる必要があります。 満たしていない場合は、根本的な要因をドリルダウンして調査し、パフォーマンスが標準を下回っている理由を判断できる必要があります。
視覚的に表現できる一般的な高レベルのインジケーターを次に示します。
- サービスの稼働時間の割合。
- アプリケーションのスループット (1 秒あたりの成功したトランザクションや操作を測定)。
- アプリケーションの成功/失敗した要求の数。
- アプリケーションとシステムのエラー、例外、および警告の数。
これらのインジケーターは、すべて指定した時間でフィルター処理できる必要があります。
クラウド アプリケーションは、さまざまなサブシステムとコンポーネントで構成される可能性があります。 オペレーターは、高レベルのインジケーターを選択して、インジケーターが基になる要素の正常性からどのように構成されているかを確認できる必要があります。 たとえば、システム全体の稼働時間が許容される値を下回った場合、オペレーターはズームインして、どの要素がこのエラーの原因となっているかを判断できる必要があります。
注意
システムの稼動時間は、慎重に定義する必要があります。 冗長性を使用して最大の可用性を保証するシステムでは、要素の個々のインスタンスが失敗する場合がありますが、システムは機能を維持できます。 正常性の監視によって表されるシステムの稼働時間は、各要素の稼働時間の合計を示し、必ずしもシステムが実際に停止したかどうかを示すものではありません。 さらに、エラーを分離できる場合があります。 この場合は特定のシステムが使用不能になっても、システムの残りの部分は、機能が低下した状態で使用できる可能性があります (e コマース システムであれば、システムのエラーによって、顧客は注文できなくなるかもしれませんが、製品カタログは引き続き参照できる可能性があります)。
アラートを生成するため、システムは、高レベルのインジケーターが指定されたしきい値を超えた場合はイベントを発生できる必要があります。 高レベルのインジケーターを構成するさまざまな要因の下位レベルの詳細は、アラート システムに対するコンテキスト データとして使用できる必要があります。
データ ソース、インストルメンテーション、およびデータ収集の要件
SLA の監視をサポートするために必要な生データは、パフォーマンスの監視に必要な生データに似ており、ある面では、正常性の監視と可用性の監視で必要なデータに似ています (詳細については該当するセクションを参照してください)。このデータは、以下を行うことでキャプチャできます。
- エンドポイントの監視の実行。
- 例外、エラー、および警告のロギング。
- ユーザー要求の実行のトレース。
- システムで使用されるすべてのサードパーティ サービスの可用性の監視。
- パフォーマンス メトリックとカウンターの使用。
すべてのデータは、計時し、タイムスタンプを付ける必要があります。
SLA データの分析
システムのパフォーマンスの全体像を生成するには、インストルメンテーション データを集計する必要があります。 集計されたデータは、サブシステムのパフォーマンスを調べることができるように、ドリルダウンをサポートする必要があります。 たとえば、以下を実行できる必要があります。
- 特定期間のユーザー要求の合計数を計算し、これらの要求の成功率と失敗率を決定する。
- ユーザー要求の応答時間を結合して、システムの応答時間の全体図を生成する。
- ユーザー要求の進行状況を分析して、特定の要求の全体的な応答時間を、その要求に含まれる個々の作業の応答時間に分解する。
- システムの全体的な可用性を、特定期間の稼働時間のパーセンテージとして決定する。
- システム内の個々のコンポーネントとサービスの可用時間のパーセンテージを分析する。 これには、サードパーティのサービスによって生成されたログの解析が含まれる場合があります。
多くの商用システムは、SLA で合意した特定期間 (通常は 1 か月間) における実際のパフォーマンスの数値を報告する必要があります。 この情報は、その期間中に SLA が満たされなかった場合に、顧客に対する何らかの形の払い戻しを計算するために使用できます。 サービスの可用性は、「 可用性データの分析」セクションで説明したテクニックを使用して計算できます。
組織は、内部で使用するために、サービスが失敗する原因となったインシデントの数と性質も追跡する場合があります。 これらの問題を短時間で解決する方法または完全に削除する方法を知っておくと、ダウンタイムの短縮と SLA を満たすために役立ちます。
監査
アプリケーションの性質によっては、ユーザーの操作を監査し、すべてのデータ アクセスを記録するための要件を指定する法的規制が存在する場合があります。 監査は、顧客を特定の要求にリンクする証拠を提供できます。 否認不可は、顧客と、アプリケーションまたはサービスに責任がある組織との間で信頼を維持するために役立つ、多くの電子商取引システムの重要な要素です。
監査の要件
アナリストは、ユーザーによって実行された一連のビジネス オペレーションをトレースして、ユーザーの操作を再構築できる必要があります。 これは、単なる記録の問題として、またはフォレンジック調査の一環として必要な場合があります。
監査情報は、機密性が高い情報です。 多くの場合、システムのユーザーと実行されているタスクを識別できるデータが含まれています。 このため、監査情報はほとんどの場合、信頼されているアナリストのみが使用できるレポートの形式にされ、グラフィカルなドリルダウン操作をサポートする対話型システムは使用されません。 アナリストは、さまざまなレポートを生成できる必要があります。 たとえば、特定の期間に発生したすべてのユーザーのアクティビティの一覧、1 人のユーザーのアクティビティの詳細な履歴、1 つ以上のリソースに対して実行された連続する操作の一覧などのレポートです。
データ ソース、インストルメンテーション、およびデータ収集の要件
監査用の情報の主要ソースには、以下を含めることができます。
- ユーザー認証を管理するセキュリティ システム。
- ユーザー アクティビティを記録するトレース ログ。
- すべての識別可能または識別不能なネットワーク要求を追跡するセキュリティ ログ。
監査データの形式とその保存方法は、法的要件によって決まる可能性があります。 たとえば、データは決して消去してはならない場合があります (元の形式のまま記録する必要があります)。データが保持されているリポジトリへのアクセスは、改ざんを防ぐため、保護する必要があります。
監査データの分析
アナリストは、生データ全体に、元の形のままでアクセスできる必要があります。 一般的な監査レポートを生成するための要件とは別に、このデータを分析するためのツールは特化され、システムの外部で保持される傾向があります。
利用状況の監視
利用状況の監視は、アプリケーションのコンポーネントと機能がどのように使用されているかを追跡します。 収集されたデータを使用して、以下のことを実行できます。
使用頻度が高い機能を確認し、システム内の潜在的なホット スポットを決定する。 トラフィック量の多い要素は、機能的なパーティション分割または負荷を均等に分散するレプリケーションによって利益を得られる可能性があります。 ほとんど使用されないためにシステムの将来のバージョンで廃止または置き換えの候補にできる機能を確認するために、この情報を使用することもできます。
通常使用時のシステムの操作イベントに関する情報を取得する。 たとえば、e コマース サイトでは、トランザクションの数とそれらに関係する顧客のボリュームに関する統計情報を記録できます。 この情報は、顧客数が増えたときに容量計画で使用できます。
ユーザーの満足度とシステムの機能またはパフォーマンスを (できる限り間接的に) 検出する。 たとえば、e コマース システムで、多数の顧客がショッピング カートを放棄するのであれば、レジ機能に問題がある可能性があります。
課金情報の生成。 商用アプリケーションまたはマルチテナント サービスでは、顧客が使用するリソースの料金を顧客に請求する場合があります。
クォータの適用。 マルチテナント システムのユーザーが、指定された期間中の処理時間またはリソース使用の有料クォータを超えた場合、アクセスを制限するか、処理を調整できます。
使用状況を監視するための要件
システムの使用状況を調べるには、通常は次のような情報を確認する必要があります。
- 各サブシステムによって処理され、各リソースに送信される要求の数。
- 各ユーザーが実行している作業。
- 各ユーザーが占有しているデータ ストレージのボリューム。
- 各ユーザーがアクセスしているリソース。
オペレーターは、グラフも生成できる必要があります。 たとえば、最もリソースを消費しているユーザーや最も頻繁にアクセスされるリソースまたはシステム機能を示すグラフです。
データ ソース、インストルメンテーション、およびデータ収集の要件
使用状況の追跡は、相対的に高いレベルで実行できます。 各要求の開始時刻と終了時刻、要求の性質 (読み取りや書き込みなど。問題のリソースによって異なります) を記録できます。 この情報は、以下を実行することで取得できます。
- ユーザー アクティビティのトレース。
- 各リソースの使用率を測定するパフォーマンス カウンターのキャプチャ。
- 各ユーザーによるリソース消費の監視。
計測のために、どのユーザーがどの操作の実行を担当しているかや、これらの操作で使用されるリソースを識別できることも必要です。 収集される情報は、正確な課金を実行できるだけの詳細さを持っている必要があります。
問題追跡
顧客やその他のユーザーは、予期しないイベントまたは動作がシステムで発生した場合、問題を報告することがあります。 問題の追跡には、これらの問題を管理し、労力を関連付けてシステム内の隠れた問題を解決し、可能性のある解決策を顧客に通知することが関係します。
問題を追跡するための要件
問題の追跡は、多くの場合、オペレーターがユーザーから報告された問題の詳細を記録して報告できる独立したシステムを使用して実行されます。 これらの詳細には、ユーザーが実行しようとしたタスク、問題の症状、一連のイベント、発行されたエラー メッセージまたは警告メッセージなどが含まれる可能性があります。
データ ソース、インストルメンテーション、およびデータ収集の要件
問題追跡データの最初のデータ ソースは、問題を報告したユーザーです。 ユーザーは、次のような追加のデータを提供できる場合があります。
- クラッシュ ダンプ (アプリケーションにユーザーのデスクトップ上で実行されるコンポーネントが含まれている場合)。
- 画面のスナップショット。
- エラーが発生した日付と時刻や、ユーザーの場所などの、その他の環境情報。
これらの情報は、デバッグ時に活用でき、ソフトウェアの今後のリリースのためのバックログを構築するために役立ちます。
問題追跡データの分析
複数のユーザーが、同じ問題を報告する場合があります。 問題追跡システムは、共通性があるレポートを関連付ける必要があります。
各問題レポートには、デバッグ作業の進行状況を記録する必要があります。 問題が解決したら、解決策を顧客に通知できます。
ユーザーから報告された問題が、問題追跡システム内に既知の解決策が記録されている問題であれば、オペレーターは、その解決策をユーザーにすぐに通知できる必要があります。
操作のトレースとソフトウェア リリースのデバッグ
ユーザーが問題を報告するとき、ユーザーは多くの場合、自分の操作に対する直接的な影響のみを認識しています。 ユーザーは自分の経験の結果のみをシステムの管理責任者に報告できます。 これらの経験は、通常は、1 つ以上の根本的な問題の目に見える症状にすぎません。 多くの場合、アナリストは、一連の操作の履歴を掘り下げて、問題の根本原因を確立する必要があります (このプロセスを "根本原因分析" と呼びます)。
注意
根本原因分析によって、アプリケーションの設計の非効率な部分が明らかになることがあります。 そのような場合は、問題の要素を作り直して、今後のリリースの一部としてデプロイできる可能性があります。 このプロセスは慎重に管理する必要があり、更新後のコンポーネントを注意深く監視する必要があります。
トレースとデバッグのための要件
予期しないイベントやその他の問題をトレースするには、アナリストがこれらの問題の発端までさかのぼって、発生した一連のイベントを再構築できるだけの十分な情報を監視データが提供できることが重要です。 この情報は、アナリストが問題の根本原因を診断できるものである必要があります。 その後、開発者は、再発を防ぐために必要な変更を行うことができます。
データ ソース、インストルメンテーション、およびデータ収集の要件
トラブルシューティングには、顧客が特定の要求を行ったときのシステムでの論理フローを表すツリーを構築するために、操作の一環として呼び出されるすべてのメソッド (およびそのパラメーター) のトレースも必要になる場合があります。 このフローの結果としてシステムによって生成された例外と警告をキャプチャして記録する必要があります。
デバッグをサポートするため、システムは、オペレーターがシステムの重要なポイントで状態情報をキャプチャできるフックを提供することができます。 または、選択された操作が進行しているときに詳細なステップ バイ ステップ情報を提供できます。 この詳細レベルでのデータのキャプチャは、システムに余分な負荷をかける可能性があり、一時的な処理である必要があります。 この処理が主に使用されるのは、再現が難しい非常に珍しい一連のイベントが発生する場合、またはシステムへの 1 つ以上の要素の新しいリリースで、要素が期待どおりに機能していることを入念に監視する必要がある場合です。
監視と診断のパイプライン
大規模な分散システムの監視は、大きな課題です。 前のセクションで説明した各シナリオは、必ずしも切り離して考慮すべきではありません。 それぞれの状況で必要な監視データと診断データは大幅に重複している傾向がありますが、データは異なる方法で処理して提示する必要がある可能性があります。 これらの理由から、監視と診断は、全体的な視点でとらえる必要があります。
監視と診断のプロセス全体は、図 1 に示すステージで構成されるパイプラインと考えることができます。
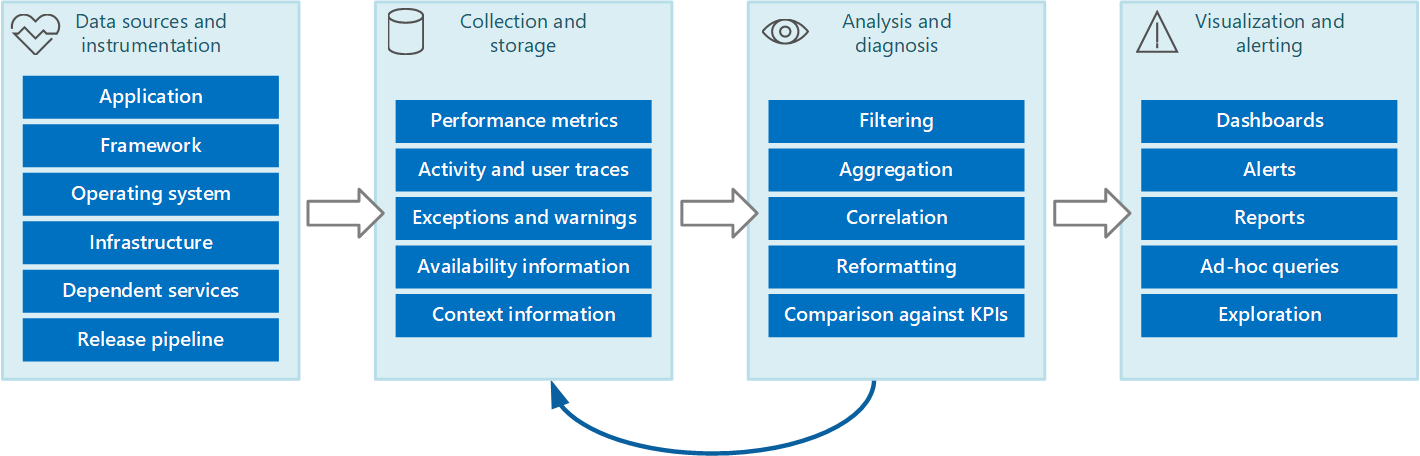
図 1 - 監視と診断のパイプライン内のステージ。
図 1 は、監視と診断用のデータ ソースがいかに多様であるかを示しています。 インストルメンテーション/収集ステージは、データをキャプチャする必要があるソースの特定、どのデータをキャプチャするかの判断、データのキャプチャ方法、調べやすいデータ形式の判断などに関係しています。 分析/診断ステージは、生データを受け取り、それを使用して、システムの状態を判断するために使用できる意味のある情報を生成します。 この情報を使用して、実行可能なアクションに関する意思決定を行い、その結果をインストルメンテーション/収集ステージにフィードバックできます。 視覚化/アラート ステージは、システム状態の参照可能なビューを提示します。 一連のダッシュボードを使用して、ほぼリアルタイムで情報を表示できます。 また、長期的な傾向の特定に役立つデータの履歴を表示するレポートやグラフを生成できる可能性があります。 KPI が許容範囲を超える可能性がある情報が示された場合、このステージでは、オペレーターにアラートをトリガーすることもできます。 場合によっては、修正措置を試行する自動化されたプロセス (自動スケールなど) をトリガーするために、アラートを使用することもできます。
これらの手順は、複数のステージが並行して発生する継続的なフロー プロセスを構成することに注意してください。 理想的には、すべてのフェーズが動的に構成可能である必要があります。 ある時点、特にシステムが新しくデプロイされたか問題が発生しているときは、広範なデータをより多くの頻度で収集する必要がある場合があります。 それ以外の場合でも、基本レベルの必須情報のキャプチャに戻って、システムが正常に機能していることを確認できる必要があります。
さらに、監視プロセス全体を、フィードバックの結果として微調整と改善の対象となる、生の現在進行中のソリューションであると考える必要があります。 たとえば、システムの正常性を判断するために、始めは多くの要因を測定するかもしれません。 時間が経過し、関連性のない測定を破棄するにつれて分析が洗練され、バックグラウンド ノイズを最小限に抑えながら必要なデータに正確に集中できるようになります。
監視と診断のデータ ソース
監視プロセスによって使用される情報は、図 1 に示したように、複数のソースから発生する可能性があります。 アプリケーション レベルでは、情報は、システムのコードに組み込まれたトレース ログから取得されます。 開発者は、コードをとおして制御フローを追跡するための標準的なアプローチに従う必要があります。 たとえば、メソッドへのエントリ時に、メソッドの名前、現在時刻、各パラメーターの値、その他の関連情報を指定するトレース メッセージを生成します。 開始時刻と終了時刻を記録することも有用であることがわかっています。
すべての例外と警告を記録し、入れ子になった例外と警告もすべてトレースされることを確認します。 理想的には、コードを実行しているユーザーを識別する情報をアクティビティの関連付け情報と共にキャプチャする必要もあります (要求がシステムを通過するときにそれらを追跡するため)。 また、メッセージ キュー、データベース、ファイル、その他の依存サービスなどのすべてのリソースに対するアクセスの試みも記録する必要があります。 この情報は、測定と監査のために使用できます。
多くのアプリケーションは、ライブラリとフレームワークを使用して、データ ストアへのアクセスやネットワーク通信などの一般的なタスクを実行します。 これらのフレームワークは、独自のトレース メッセージと、トランザクション レートやデータ転送の成功と失敗などの生の診断情報を提供するように構成できる場合があります。
注意
最新の多くのフレームワークは、パフォーマンスとトレース イベントを自動的に公開しています。 この情報をキャプチャすることは、取得して処理と分析を実行できる場所に保存する手段を提供するという問題にすぎません。
アプリケーションが実行されているオペレーティング システムは、I/O 率、メモリ使用率、CPU 使用率を示すパフォーマンス カウンターなどの低レベルでシステム全体の情報のソースです。 オペレーティング システム エラー (ファイルを正しく開くことができないなど) も報告される可能性があります。
その上でシステムが実行されているインフラストラクチャとコンポーネントも考慮する必要があります。 仮想マシン、仮想ネットワーク、およびストレージサービスは、すべてが重要なインフラストラクチャ レベルのパフォーマンス カウンターとその他の診断データのソースになることができます。
アプリケーションが Web サーバーやデータベース管理システムなどの外部サービスを使用する場合、これらのサービスが独自のトレース情報、ログ、およびパフォーマンス カウンターを発行することがあります。 例として、SQL Server データベースに対して実行された操作を追跡する SQL Server の動的管理ビューや、Web サーバーに対して行われた要求を記録する IIS のトレース ログがあります。
システムのコンポーネントを修正し、新しいバージョンをデプロイするときは、問題、イベント、メトリックを各バージョンに帰属できるようにすることが重要です。 この情報をリリース パイプラインに関連付けて、コンポーネントの特定のバージョンに関する問題を簡単に追跡して修復できるようにする必要があります。
セキュリティ上の問題は、システムのあらゆるポイントで発生する可能性があります。 たとえば、ユーザーが無効なユーザー ID またはパスワードでサインインしようとすることがあります。 認証ユーザーが、リソースに不正にアクセスしようとすることもあります。 また、ユーザーが暗号化された情報にアクセスするために、無効なキーや期限切れのキーを使用することもあります。 成功した要求と失敗した要求のセキュリティ関連情報を常に記録する必要があります。
キャプチャする必要がある情報については、「 アプリケーションのインストルメント化 」セクションで、さらにガイダンスが用意されています。 しかし、この情報を収集するには、次のようなさまざまな方法があります。
アプリケーション/システムの監視。 この戦略では、アプリケーション、アプリケーション フレームワーク、オペレーティング システム、およびインフラストラクチャ内の内部ソースを使用します。 アプリケーション コードは、クライアント要求のライフサイクル中の重要なポイントで、独自の監視データを生成できます。 アプリケーションに、状況に応じて選択的に有効化または無効化できるトレース ステートメントを含めることができます。 また、診断フレームワークを使用して診断を動的に挿入できる場合もあります。 これらのフレームワークは、通常は、コード内のさまざまなインストルメンテーション ポイントに接続し、それらのポイントでトレース データをキャプチャできるプラグインを備えています。
さらに、コードまたは基になるインフラストラクチャが、重要なポイントでイベントを発生させる可能性があります。 これらのイベントをリッスンするように構成された監視エージェントで、イベント情報を記録できます。
実在ユーザーの監視。 このアプローチでは、ユーザーとアプリケーションとの対話を記録し、各要求と応答のフローを監視します。 この情報には、2 つの目的を持たせることができます。各ユーザーの使用状況を測定するために使用でき、ユーザーが適切な品質のサービスを受け取っているかどうか (たとえば、迅速な応答、短い待機時間、最小限のエラー) を判断するために使用できます。 キャプチャされたデータは、エラーが最も頻繁に発生している懸案の分野を特定するために使用できます。 おそらくはアプリケーションのホット スポットまたはなんらかのボトルネックのせいでシステムが遅くなる要素を特定するために、データを使用することもできます。 このアプローチを慎重に実装した場合は、デバッグとテストを目的として、アプリケーションでのユーザーのフローを再構築できる可能性があります。
重要
実在ユーザーの監視によってキャプチャされたデータは、機密情報が含まれている場合があるため、非常に機密性が高いと見なす必要があります。 キャプチャしたデータを保存する場合は、セキュリティが確保されるように保管してください。 パフォーマンスの監視またはデバッグを目的としてデータを使用する場合は、その前に個人データをすべて除去する必要があります。
模擬ユーザーの監視。 このアプローチでは、ユーザーをシミュレートし、構成可能ではあるが一般的な一連の操作を実行する独自のテスト クライアントを記述します。 テスト クライアントのパフォーマンスを追跡して、システムの状態を判断するために役立てることができます。 さらに、テスト クライアントの複数のインスタンスを負荷テスト操作の一部として使用して、ストレス下でシステムがいかに応答し、どのような監視出力が生成されるかを確認できます。
注意
実在ユーザーと模擬ユーザーの監視は、メソッド呼び出しとアプリケーションのその他の重要な部分の実行をトレースして計時するコードを含めることによって実装できます。
プロファイリング。 このアプローチの主な目標は、アプリケーションのパフォーマンスを監視して向上させることです。 実在ユーザーと模擬ユーザーの監視の機能レベルでの操作ではなく、アプリケーションが実行されるときの下位レベルの情報をキャプチャします。 プロファイリングは、アプリケーションの実行状態を定期的にサンプリングする (特定の時点でアプリケーションが実行しているコード部分を決定する) ことによって実装できます。 また、重要な岐路のコード (メソッド呼び出しの開始と終了など) にプローブを挿入し、呼び出されたメソッド、呼び出された時刻、および各呼び出しの所要時間を記録するインストルメンテーションを使用することもできます。 その後、このデータを分析して、アプリケーションのどの部分がパフォーマンスの問題を引き起こす可能性があるかを判断できます。
エンドポイントの監視。 このテクニックでは、監視を有効にするためにアプリケーションによって特別に公開される 1 つ以上の診断エンドポイントを使用します。 エンドポイントは、アプリケーション コードへの通路を提供し、システムの正常性に関する情報を返すことができます。 さまざまなエンドポイントが、機能のさまざまな側面に対応します。 これらのエンドポイントに対して定期的な要求の送信と応答の取得を行う独自の診断クライアントを記述できます。 詳細については、「正常性エンドポイントの監視パターン」を参照してください。
情報の取得範囲を最大限にするために、これらのテクニックを組み合わせて使用する必要があります。
アプリケーションのインストルメント化
インストルメンテーションは、監視プロセスの重要な部分です。 そもそもパフォーマンスとシステムの正常性に関して意味のある決定を行うことを可能にするデータをキャプチャした場合にのみ、これらの決定を行うことができます。 インストルメンテーションを使用して収集する情報は、リモート運用サーバーへのサインインと手動のトレース (およびデバッグ) を実行せずに、パフォーマンスの評価、問題の診断、および意思決定を行うことができる情報である必要があります。 インストルメンテーション データは、通常は、トレース ログに書き込まれた情報とメトリックで構成されます。
トレース ログの内容は、アプリケーションによって書き込まれたテキスト形式のデータや、トレース イベントの結果として作成されたバイナリ データ (アプリケーションで Event Tracing for Windows (ETW) を使用している場合) の結果である場合があります。 また、Web サーバーなどのインフラストラクチャの一部から発生したイベントを記録するシステム ログから生成される場合もあります。 多くの場合、テキスト ログ メッセージは人間が判読できるように設計されていますが、同時に、自動システムによって簡単に解析できる形式で記述されている必要があります。
さらに、ログを分類する必要があります。 すべてのトレース データを 1 つのログに書き込まないでください。システムの異なる運用面から取得されるトレース出力は、別のログを使用して記録します。 そうすることで、1 つの大きなファイルを処理する代わりに適切なログから読み取ることによって、ログ メッセージをすばやくフィルター処理できます。 セキュリティ要件が異なる情報 (監査情報とデバッグ データなど) を同じログに書き込まないでください。
注意
ログは、ファイル システム上のファイルとして実装できる場合があります。または、BLOB などの他の形式で Blob Storage に保持されることもあります。 ログ情報は、テーブル内の行などのさらに構造化されたストレージに保持される場合もあります。
メトリックは、通常、特定の時点でのシステムのなんらかの面またはリソースの測定またはカウントであり、1 つ以上のタグまたはディメンションが関連付けられたものです ( "サンプル" と呼ばれる場合があります)。 メトリックの 1 つのインスタンスは、通常は単独では役に立ちません。 メトリックは、時間をかけてキャプチャする必要があります。 考慮すべき重要な問題は、どのメトリックをどの程度の頻度で記録するかです。 メトリックのデータの生成回数が多すぎるとシステムに大きな負荷がかかり、少なすぎると重大なイベントにつながる状況を見逃す可能性があります。 考慮することはメトリックごとに異なります。 たとえば、サーバーの CPU 使用率は秒単位で大幅に変化する可能性がありますが、高い使用率はそれが数分間続いた場合のみ問題になります。
データを相互に関連付けるための情報
個々のシステム レベルのパフォーマンス カウンターの監視、リソースのメトリックのキャプチャ、およびさまざまなログ ファイルからアプリケーションのトレース情報を取得することは簡単に実行できます。 しかし、一部の形式の監視では、監視パイプラインの分析/診断ステージで、複数のソースから取得されたデータを相関させる必要があります。 このデータは、生データではさまざまな形式である可能性があり、分析プロセスには、これらのさまざまな形式に対応できる十分なインストルメンテーション データを提供する必要があります。 たとえば、アプリケーション フレームワーク レベルでは、タスクはスレッド ID によって特定されます。 アプリケーション内では、同じ作業に、そのタスクを実行するユーザーのユーザー ID が関連付けられることがあります。
また、非同期操作で同じスレッドを再利用して 1 人以上のユーザーの代わりに操作を実行することがあるため、スレッドとユーザー要求が 1 対 1 で対応しないこともあります。 事態をさらに難しくしているのは、システムの実行フローで 1 つの要求が複数のスレッドによって処理される場合があることです。 可能であれば、各要求を、要求コンテキストの一部としてシステム全体に伝播される一意のアクティビティ ID に関連付けます (アクティビティ ID を生成してトレース情報に含めるテクニックは、トレース データをキャプチャするために使用されるテクノロジによって異なります)。
すべての監視データには、同じ方法でタイムスタンプを付ける必要があります。 一貫性を保つために、すべての日付と時刻は、世界協定時刻を使用して記録します。 これは、連続するイベントを簡単にトレースするために役立ちます。
注意
異なるタイム ゾーンとネットワークで稼働しているコンピューターは、同期されていないことがあります。 複数のコンピューターにまたがるインストルメンテーション データを相互に関連付けるときは、タイムスタンプのみに頼るべきではありません。
インストルメンテーション データに含める必要がある情報
収集する必要があるインストルメンテーション データを決定するときは、次の点を考慮します。
トレース イベントによってキャプチャされた情報は、コンピューターと人間が判読できるものにする必要があります。 この情報に対して適切に定義されたスキーマを採用して複数のシステムのログ データの自動処理を促進し、ログを読み取るオペレーション スタッフとエンジニアリング スタッフに一貫性を提供する必要があります。 デプロイ環境、プロセスを実行しているコンピューター、プロセスの詳細、呼び出しスタックなどの環境情報を含めてください。
プロファイリングは、システムで著しいオーバーヘッドを発生させる可能性があるため、必要な場合にのみ有効にする必要があります。 インストルメンテーションを使用するプロファイリングでは、イベント (メソッドの呼び出しなど) が発生するたびにそれを記録し、サンプリングでは、選択したイベントのみを記録します。 選択は、時間ベース (n 秒に 1 回) または頻度ベース (n 個の要求で 1 回) にすることができます。 イベントの発生頻度が非常に高い場合、インストルメンテーションによるプロファイリングでは負担が大きすぎて、それ自体が全体的なパフォーマンスに影響を与える可能性があります。 この場合は、サンプリング アプローチの方が適している可能性があります。 ただし、イベントの発生頻度が低い場合、サンプリングではイベントをキャプチャできないことがあります。 この場合は、インストルメンテーションの方がより優れたアプローチになる可能性があります。
開発者または管理者が各要求のソースを決定できるために十分なコンテキストを提供します。 この中には、要求の特定のインスタンスを識別するなんらかの形のアクティビティ ID が含まれる場合があります。 また、実行された計算作業と使用されたリソースにこのアクティビティを相関させるために使用できる情報が含まれる場合もあります。 この作業は、プロセスとコンピューターの境界を越える場合があることに注意してください。 測定では、要求が行われる原因となった顧客への参照をコンテキストに (直接的または他の関連情報を介して間接的に) 含める必要があります。 このコンテキストは、監視データがキャプチャされた時点のアプリケーションの状態に関する重要な情報を提供します。
すべての要求と、これらの要求の要求元となった場所または地域を記録します。 この情報は、場所に固有のホット スポットがあるかどうかの判断に役立ちます。 アプリケーションまたはそれが使用するデータを再パーティション化するかどうかの判断にも役立ちます。
例外の詳細を慎重に記録してキャプチャします。 不適切な例外処理の結果として重要なデバッグ情報が失われることがしばしばあります。 アプリケーションによってスローされる例外の詳細をすべてキャプチャします。すべての内部例外、その他のコンテキスト情報を含めます。 可能であれば、コール スタックも含めます。
アプリケーションのさまざまな要素がキャプチャするデータに一貫性を持たせます。これは、イベントを分析し、それらをユーザー要求と相関させるために役立ちます。 開発者がシステムの別の部分を実装したときと同じアプローチを採用することに依存するのではなく、包括的かつ構成可能なロギング パッケージを使用して情報を収集することを考慮します。 実行される I/O のボリューム、ネットワーク使用率、要求数、メモリの使用、CPU 使用率などの重要なパフォーマンス カウンターからデータを収集します。 一部のインフラストラクチャ サービスは、データベースへの接続数、トランザクションの実行速度、成功または失敗したトランザクションの数などの独自のパフォーマンス カウンターを備えています。 アプリケーションでも、独自のパフォーマンス カウンターを定義していることがあります。
データベース システム、Web サービス、インフラストラクチャの一部であるその他のシステム レベルのサービスなどの外部サービスに対して行われたすべての呼び出しを記録します。 各呼び出しの実行にかかった時間と、呼び出しの成功または失敗に関する情報を記録します。 可能であれば、すべての再試行と、発生した一時的なエラーに関する情報をキャプチャします。
製品利用統計情報システムとの互換性の確認
多くの場合、インストルメンテーションによって作成される情報は一連のイベントとして生成され、処理と分析のために個別の製品利用統計情報システムに渡されます。 製品利用統計情報システムは、通常は、特定のアプリケーションやテクノロジに依存しませんが、情報は一般にスキーマによって定義される特定の形式に従っていることが期待されています。 スキーマは、製品利用統計情報システムが取り込むことができるデータのフィールドと型を定義するコントラクトを効果的に指定します。 スキーマは、まざまなプラットフォームとデバイスから到着するデータに対応できるように一般化される必要があります。
共通スキーマには、イベント名、イベント時刻、送信者の IP アドレス、他のイベントと相関させるために必要な詳細 (たとえば、ユーザー ID、デバイス ID、アプリケーション ID) などの、すべてのインストルメンテーション イベントに共通するフィールドを含める必要があります。 イベントは任意の数のデバイスから発生する可能性があるため、スキーマはデバイスの種類に依存しないようにします。 さらに、同じアプリケーションのイベントが、異なるデバイスによって発生することがあります。これは、アプリケーションがローミングやその他のクロスデバイス配布をサポートしている場合に発生します。
スキーマには、異なるアプリケーションに共通する特定のシナリオに関連するドメイン フィールドが含まれることもあります。 これは、例外、アプリケーションの開始イベントと終了イベント、および Web サービス API 呼び出しの成功や失敗に関する情報である可能性があります。 同じドメイン フィールド セットを使用するすべてのアプリケーションは、共通するレポートと分析を構築できるように、同じイベント セットを送信する必要があります。
最後に、スキーマには、アプリケーション固有のイベントの詳細をキャプチャするためのカスタム フィールドを含めることができます。
アプリケーションをインストルメント化するためのベスト プラクティス
次の一覧は、クラウドで実行される分散アプリケーションをインストルメント化するためのベスト プラクティスについて説明しています。
ログは、読みやすく、簡単に解析できるようにします。 可能であれば、構造化されたロギングを使用します。 ログ メッセージは、簡潔でわかりやすくします。
すべてのログに、ソースを識別し、各ログ レコードが書き込まれたときのコンテキストと計時情報を提供します。
すべてのタイム スタンプで、同じタイム ゾーンと形式を使用します。 これは、別の地域で実行されているハードウェアとサービスにまたがる操作のイベントをj相関させるために役立ちます。
ログを分類し、適切なログ ファイルにメッセージを書き込みます。
システムに関する機密情報またはユーザーの個人情報を開示しないでください。 これらの情報はログに記録する前に取り除きますが、関連する詳細は保持されていることを保証します。 たとえば、ID とパスワードはデータベース接続文字列から削除しますが、残った情報をログに書き込んで、システムが適切なデータベースにアクセスしていることをアナリストが確認できるようにします。 すべての重大な例外を記録しますが、下位レベルの例外と警告のロギングは管理者がオンとオフを切り替えることができるようにします。 さらに、すべての再試行ロジック情報をキャプチャして記録します。 このデータは、システムの一時的な状態の監視に役立てることができます。
外部 Web サービスまたはデータベースへの要求などのプロセス外の呼び出しをトレースします。
セキュリティ要件が異なるログ メッセージを同じログ ファイルに混在させないでください。 たとえば、デバッグ情報と監査情報を同じログに書き込まないでください。
監査イベントを除いて、すべてのログ呼び出しは、ビジネス操作の進行状況をブロックすることがないファイア アンド フォーゲット操作にする必要があります。 監査イベントはビジネスに不可欠であり、ビジネス オペレーションの基本として分類できるため、例外になります。
ロギングは拡張可能であり、具体的なターゲットと直接的な依存関係を持っていない必要があります。 たとえば、System.Diagnostics.Trace を使用して情報を書き込むのではなく、ロギング メソッドを公開し、適切な手段を通じて実装できる抽象インターフェイス (ILogger など) を定義します。
すべてのロギングはフェールセーフであり、連鎖エラーをトリガーしない必要があります。 ロギングは例外をスローしない必要があります。
インストルメンテーションは、継続的で反復的なプロセスとして扱い、問題がある場合だけでなく定期的にログを見直します。
データの収集と保存
監視プロセスの収集ステージは、インストルメンテーションによって生成される情報の取得、取得したデータを分析/診断ステージで容易に使用できるようにするためのフォーマッティング、および変換後のデータを信頼できるストレージに保存することに関係します。 分散システムのさまざまな部分から収集したインストルメンテーション データは、さまざまな場所にさまざまな形式で保持される可能性があります。 たとえば、アプリケーション コードで、トレース ログ ファイルの生成とアプリケーション イベント ログ データの生成を行うと同時に、他のテクノロジを通じて、アプリケーションが使用しているインフラストラクチャの重要な側面を監視するパフォーマンス カウンターをキャプチャできます。 アプリケーションが使用するサードパーティのコンポーネントとサービスは、さまざまな形式で、別のトレース ファイル、Blob Storage、またはカスタム データ ストアを使用して、インストルメンテーション情報を提供する場合があります。
データ収集は、多くの場合、インストルメンテーション データを生成するアプリケーションから自律的に実行できる収集サービスを通じて実行されます。 図 2 は、このアーキテクチャの例を示しています。インストルメンテーション データ コレクションのサブシステムが強調されています。
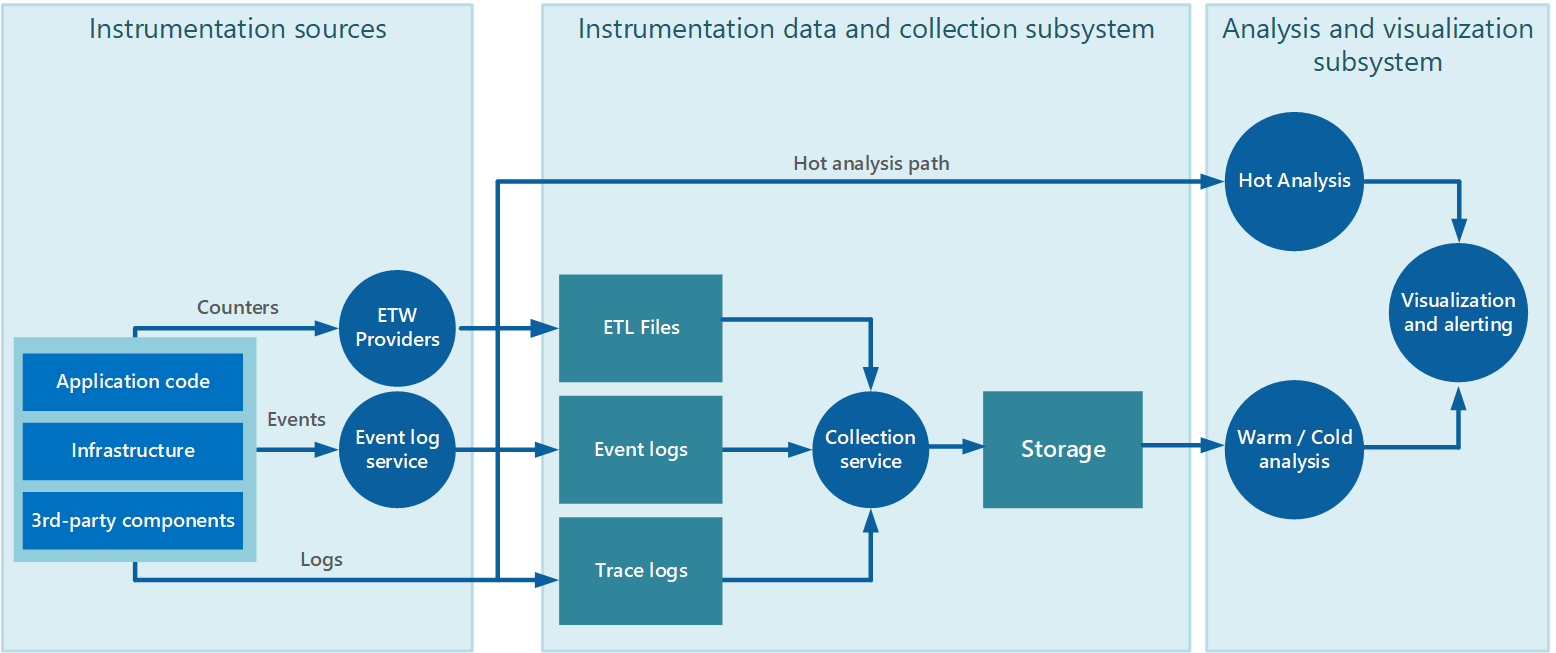
図 2 - インストルメンテーション データの収集。
これは概略図です。 収集サービスは必ずしも単一のプロセスである必要はなく、次のセクションで説明するように、別々のコンピューターで実行される多くの構成要素で構成される場合があります。 さらに、一部の製品利用統計情報データの分析を迅速に行う必要があるホット分析の場合 (「 ホット分析、ウォーム分析、コールド分析のサポート 」セクションで後述します)、収集サービスの範囲外で動作するローカル コンポーネントが分析タスクをすぐに実行することがあります。 図 2 は、選択したイベントに対するこの状況を示しています。 分析処理の後、結果を視覚化とアラートを行うサブシステムに直接送信できます。 ウォーム分析またはコールド分析の対象となるデータは、処理を待つ間ストレージに保持されます。
Azure のアプリケーションとサービスでは、Azure Diagnostics がデータをキャプチャするための 1 つの可能性のあるソリューションを提供します。 Azure Diagnostics は、各コンピューティング ノードの次のソースからデータを収集して集計した後、Azure Storage にアップロードします。
- IIS ログ
- IIS の失敗した要求ログ
- Windows イベント ログ
- パフォーマンス カウンター
- クラッシュ ダンプ
- Azure Diagnostics インフラストラクチャ ログ
- カスタム エラー ログ
- .NET EventSource
- マニフェスト ベースの ETW
詳しくは、Azure:製品利用統計情報の基本とトラブルシューティングに関する記事を参照してください。
インプリメンテーション データを収集するための戦略
クラウドの伸び縮みする性質を考慮して、製品利用統計情報データをシステムのすべてのノードから手動で取得しなくても済むように、データを 1 か所に転送して統合する必要があります。 複数のデータセンターにまたがるシステムでは、データを収集して統合し、リージョンごとに保存した後、リージョンのデータを 1 つのサーバーの中央システムに集めます。
帯域幅の使用を最適化するために、緊急度の低いデータをバッチとしてまとめて転送することを選択できます。 ただし、データに時間の影響を受ける情報が含まれている場合は、転送をいつまでも遅らせることはできません。
インストルメンテーション データのプルとプッシュ
インストルメンテーション データ収集サブシステムは、アプリケーションの各インスタンスのさまざまなログとその他のソースからアクティブにインストルメンテーション データを取得することができます ( プル モデル)。 または、アプリケーションの各インスタンスを構成するコンポーネントからデータが送信されるのを待つパッシブ受信者として機能することができます ( プッシュ モデル)。
プル モデルを実装するアプローチの 1 つは、アプリケーションの各インスタンスでローカルに実行される監視エージェントを使用することです。 監視エージェントは、ローカル ノードで収集された製品利用統計情報データを定期的に取得 (プル) し、その情報をアプリケーションのすべてのインスタンスによって共有される中央ストレージに直接書き込む、独立したプロセスです。 これは、Azure Diagnostics によって実装されるメカニズムです。 Azure Web ロールまたは worker ロールの各インスタンスは、ローカルに保存される診断情報とその他のトレース情報をキャプチャするように構成できます。 各インスタンスと共に実行される監視エージェントは、指定されたデータを Azure Storage にコピーします。 このプロセスの詳細については、「Azure Cloud Services での Azure 診断の有効化 」を参照してください。 IIS ログ、クラッシュ ダンプ、カスタム エラー ログなどの要素は Blob Storage に書き込まれます。 Windows イベント ログ、ETW イベント、およびパフォーマンス カウンターからのデータは、Table Storage に記録されます。 図 3 は、このメカニズムを示しています。
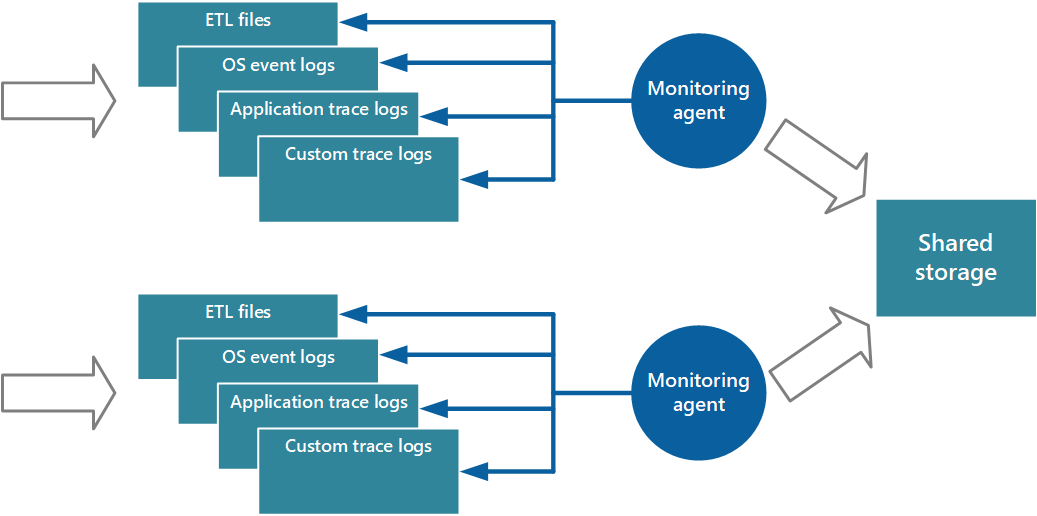
図 3 - 監視エージェントを使用した情報の取得と共有ストレージへの書き込み。
注意
監視エージェントの使用は、データ ソースから自然に取得されるインストルメンテーション データをキャプチャするのに最適です。 たとえば、SQL Server の動的管理ビューの情報や Azure Service Bus Queue の長さなどです。
1 つの場所の限定された数のノードで実行されている小規模なアプリケーションの製品利用統計情報データを保存するには、ここで説明したアプローチを使用するのが適しています。 ただし、複雑で拡張性の高いグローバルなクラウド アプリケーションでは、何百もの Web と worker ロール、データベース シャード、およびその他のサービスから、膨大な量のデータが生成されることがあります。 このデータの殺到は、1 つの一元化された場所で使用できる I/O 帯域幅ではすぐに対応できなくなる可能性があります。 したがって、製品利用統計情報ソリューションは、システムが拡張したときにボトルネックになることがないように拡張可能である必要があります。 理想的には、システムの一部で障害が発生した場合に重要な監視情報 (監査データや課金データなど) が失われるリスクを低減するために、冗長性が組み込まれている必要があります。
これらの問題に対応するために、キューを実装できます。図 4 を参照してください。 このアーキテクチャでは、ローカルの監視エージェント (適切に構成できる場合) またはカスタム データ コレクション サービス (適切に構成できない場合) がデータをキューにポストします。 非同期に実行している別のプロセス (図 4 のストレージ書き込みサービス) がこのキューのデータを取得し、それを共有ストレージに書き込みます。 メッセージ キューは、このシナリオに最適です。"少なくとも 1 回" のセマンティクスを提供し、ポスト後はキューに登録されたデータが失われないためです。 別個の worker ロールを使用して、ストレージ書き込みサービスを実装できます。
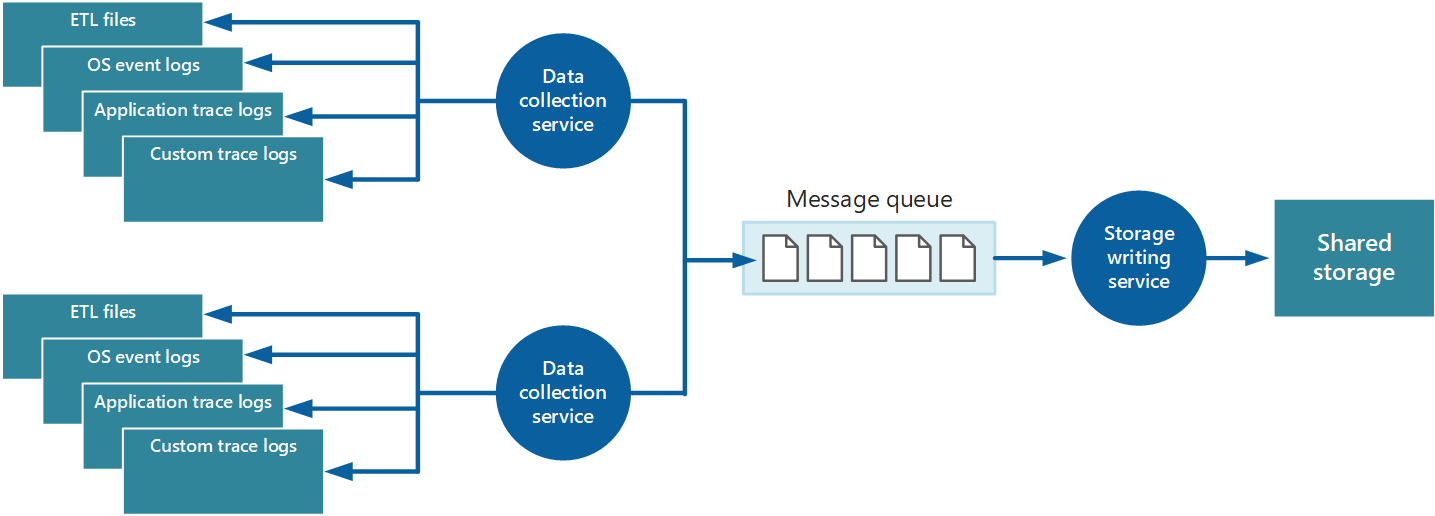
図 4 - キューを使用したインストルメンテーション データのバッファー処理。
ローカル データ コレクション サービスでは、データを受信したらすぐにキューに追加できます。 キューはバッファーとして機能し、ストレージ書き込みサービスは独自のペースでデータの取得や書き込みを行うことができます。 既定では、キューは先入れ先出しベースで機能します。 しかし、より迅速に処理する必要があるデータを含むメッセージに優先順位を付けて、キューでの処理を高速化できます。 詳細については、「Priority Queue パターン」を参照してください。 この方法に代わって、さまざまなチャネル (Service Bus のトピックなど) を使用し、必要な分析処理の形式に応じて、データをさまざまな宛先に送信できます。
拡張性のために、ストレージ書き込みサービスの複数のインスタンスを実行することができます。 大量のイベントがある場合は、イベント ハブを使用して、処理やストレージのためにデータを別のコンピューティング リソースに送信できます。
インストルメンテーション データの統合
アプリケーションの 1 つのインスタンスからデータ コレクション サービスによって取得されるインストルメンテーション データは、そのインスタンスの正常性とパフォーマンスのローカライズされたビューを示します。 システムの全体的な正常性を評価するには、ローカル ビュー内のデータの一部の要素を統合する必要があります。 この操作は、データが格納された後でも実行できますが、データが収集される際に実行できる場合もあります。 インストルメンテーション データは、共有ストレージに直接書き込む以外にも、データを統合してフィルターやクリーンアップ プロセスとして機能する別個のデータ統合サービスに渡すことができます。 たとえば、アクティビティ ID などの同じ相関関係情報が含まれているインストルメンテーション データは統合できます (ユーザーがビジネス オペレーションを 1 つのノードで開始したものの、その後ノード障害が発生した場合や負荷分散の構成方法によって別のノードに転送されることがあります)。また、このプロセスは重複するデータを検出して削除することもできます (製品利用統計情報サービスがメッセージ キューを使用してインストルメンテーション データをストレージから取り出す場合は重複の可能性が常にあります)。 図 5 は、この構造の例を示します。
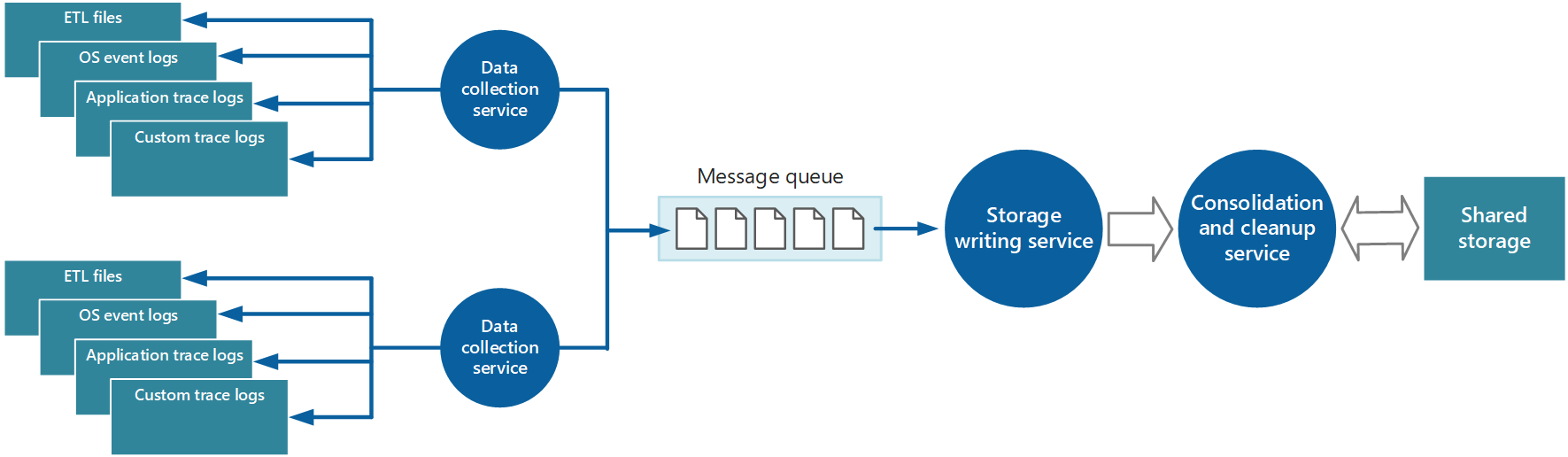
図 5 - 別個のサービスを使用したインストルメンテーション データの統合とクリーンアップ。
インストルメンテーション データの格納
前述の説明では、インストルメンテーション データが格納される方法について簡単に示しました。 実際には、異なる種類の情報の格納に、情報の種類に合わせて最も適切なテクノロジを使うのが理にかなっています。
たとえば、Azure BLOB と Table Storage はアクセス方法が似通っています。 しかし、それらを使って実行できる処理については制限があり、それぞれが保持するデータの粒度はまったく異なります。 より多くの分析処理を実行する必要がある場合や、データにフルテキスト検索機能が必要な場合は、特定の種類のクエリ処理やデータ アクセス用に最適化された機能が用意されているデータ ストレージを使用することが適切なことがあります。 次に例を示します。
- パフォーマンス カウンター データはアドホック分析ができるように、SQL データベースに格納します。
- トレース ログは、Azure Cosmos DB に格納することをお勧めします。
- セキュリティ情報は、HDFS に書き込むことができます。
- フルテキスト検索が必要な情報はエラスティック検索を使って格納できます (リッチ インデックス機能を使って検索を高速化することもできます)。
データを共有ストレージから定期的に取得する追加のサービスを実装し、目的に合わせてデータをパーティション分割またはフィルター処理して、図 6 に示す適切なセットのデータ ストアに書き込むことができます。 別のアプローチでは、統合とクリーンアップ プロセスにこの機能を含め、取得したデータを中間の共有ストレージ領域に保存することなく、これらのストアに直接書き込みます。 各アプローチには、それぞれ長所と短所があります。 別個のパーティション分割サービスを実装すると、統合とクリーンアップ サービスの負荷を軽減し、パーティション分割されたデータの少なくとも一部を必要に応じて再生成できます (共有ストレージに保持されるデータ量によります)。 ただし、追加のリソースが消費されます。 また、インストルメンテーション データを各アプリケーション インスタンスから受信し、このデータを実用的な情報に変換するまでに遅延が発生する可能性があります。
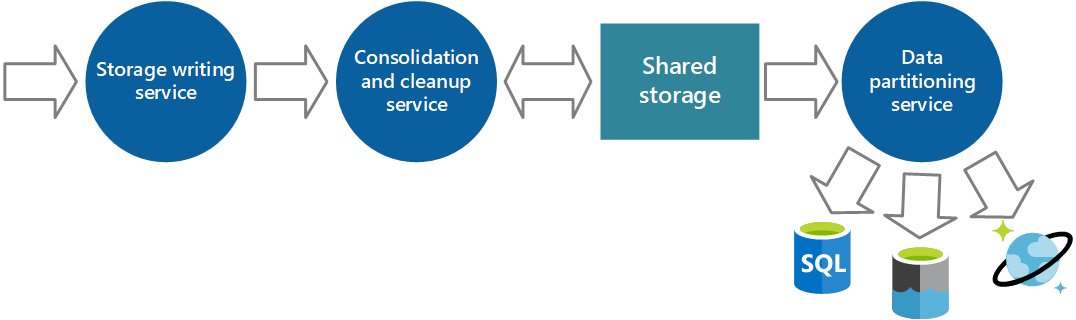
図 6 - 分析要件とストレージ要件に基づくデータのパーティション分割。
同じインストルメンテーション データを 1 つ以上の目的で使う必要がある場合があります。 たとえば、パフォーマンス カウンターは、システム パフォーマンスの推移の履歴を表示するために使用することができます。 他の使用状況データと組み合わせて、顧客の課金情報を生成することもできます。 このような場合は、課金情報を保持する長期的なストアとして機能するドキュメント データベースや、複雑なパフォーマンス分析を処理する多次元ストアなど、同じデータを 1 つ以上の宛先に送信できます。
また、データが必要となる緊急度も検討する必要があります。 アラートを発信する情報を提供するデータにはすばやくアクセスする必要があるため、高速なデータ ストレージに格納し、アラート発信システムが実行するクエリを最適化するためにインデックスを作成して構造化する必要があります。 場合によっては、各ノードのデータを収集する製品利用統計情報サービスでデータを書式設定してローカルに保存し、アラート発信システムのローカル インスタンスがあらゆる問題をすばやく通知できるようにする必要があります。 同じデータを別の目的にも使う場合は、前のダイアグラムに示されているストレージ書き込みサービスにディスパッチして 1 か所に格納できます。
詳細な分析、レポート作成、および履歴の傾向の特定のための情報は、緊急度が低いため、データ マイニングとアドホック クエリをサポートする方法で格納することができます。 詳細については、このドキュメントの後の方のセクション「 ホット、ウォーム、およびコールド分析のサポート 」を参照してください。
ログのローテーションとデータの保持
インストルメンテーションでは、かなりの量のデータが生成されます。 このデータは、未加工のログ ファイル、トレース ファイル、各ノードでキャプチャされたその他の情報を始めとして、共有ストレージに保持される統合、クリーニング、およびパーティション分割されたデータまで、複数の場所に保持されます。 場合によっては、処理および転送されたデータの元の生データは各ノードから削除できます。 未加工の情報を保存する必要がある場合や、保存しておく方が便利な場合もあります。 たとえば、デバッグを目的に生成されたデータは未加工の状態のまま残しておくのが最適ですが、バグがすべて修正された後はすぐに削除して問題ありません。
パフォーマンス データは、パフォーマンスの傾向の特定や容量の計画に使用できるように、多くの場合、長期間必要になります。 このデータの統合ビューは通常、一定の期間はすぐにアクセスできるようにオンラインで保持されます。 その後は、アーカイブまたは破棄することができます。 測定および顧客への課金のために収集されるデータは、無期限に保存する必要がある場合があります。 さらに、法的要件に基づいて、監査とセキュリティの目的で収集された情報はアーカイブして保存する必要がある場合があります。 また、このデータは機密性が高いため、改ざんを防ぐために暗号化またはその他の方法で保護する必要があります。 ユーザーのパスワードなどの不正アクセスにつながる情報は記録しないでください。 このような情報は、格納する前にデータから削除する必要があります。
ダウン サンプリング
長期間の傾向を特定するために、履歴データを格納しておくと便利です。 古いデータをすべて保存するのではなく、データをダウンサンプリングしてデータの密度を下げ、ストレージのコストを節約できる場合があります。 たとえば、パフォーマンス インジケーターを分単位で保存するのではなく、ひと月以上前のデータは統合して時間単位で表示することもできます。
ログ情報を収集および格納するためのベスト プラクティス
次の一覧は、ログ情報をキャプチャおよび格納するためのベスト プラクティスをまとめたものです。
監視エージェントやデータ コレクション サービスはプロセス外のサービスとして実行し、簡単にデプロイできる必要があります。
監視エージェントやデータ コレクション サービスからのすべての出力は、コンピューター、オペレーティング システム、またはネットワーク プロトコルに依存しない、独立した形式にする必要があります。 たとえば、ETL や ETW ではなく、JSON、MessagePack、Protobuf などの自己記述型の形式で情報を出力します。 標準的な形式を使うと、システムが処理パイプラインを構築して、データを特定の形式で読み取り、変換、および送信するコンポーネントを簡単に実装できます。
監視とデータ コレクション処理はフェールセーフで、エラーの連鎖を引き起こさないようにする必要があります。
データ シンクへの情報の送信中に一時的なエラーが発生する場合は、監視エージェントやデータ コレクション サービスで製品利用統計情報データの順序を変更し、最新の情報が最初に送信されるように準備する必要があります (監視エージェントやデータ コレクション サービスは、独自の裁量により、古いデータをドロップしたり、ローカルに保存して後追いで送信したりする場合があります)。
データの分析と問題の診断
監視と診断のプロセスの重要な部分は、収集されたデータを分析してシステムの健康状態の全体像を把握することです。 独自の KPI とパフォーマンス メトリックを定義し、分析の要件を満たすには収集されたデータをどのように構成すればよいかを理解することが重要です。 また、この情報は一連のイベントを追跡し、発生する問題の診断に役立つキーとなるため、別のメトリックとログ ファイルでキャプチャされたデータがどのように関連付けられているかを理解することも重要です。
セクション「 インストルメンテーション データの統合」で説明したように、通常、システムの各部分のデータはローカルでキャプチャされますが、一般的にはそのシステムを構成する他のサイトで生成されたデータと組み合わせる必要があります。 データが正確に組み合わされるように、この情報は慎重に関連付ける必要があります。 たとえば、ある処理の使用状況データの範囲は、ユーザーが接続する Web サイトをホストするノード、この処理の一部としてアクセスされる別個のサービスが実行されているノード、他のノードに保持されているデータ ストレージにまで広がる可能性があります。 この処理で使われるリソースやプロセスの全体像を把握するには、この情報を結び付ける必要があります。 データの事前処理とフィルター処理の一部はデータがキャプチャされるノードで発生する一方で、集計やフォーマットは多くの場合中央ノードで発生します。
ホット分析、ウォーム分析、コールド分析のサポート
視覚化、レポート、およびアラート発信用途のデータの分析と再フォーマットには複雑なプロセスを要し、独自のリソース セットを消費します。 一部の形態の監視はスピードが重視されるため、効果を発揮するにはデータの即時分析が必要です。 これを ホット分析と呼びます。 たとえば、アラートの発信やセキュリティ監視の一部 (システムへの攻撃を検出する場合など) に必要な分析などが挙げられます。 これらの目的に必要なデータは、すぐに使えて、効率的に処理できるように構造化されている必要があります。 場合によっては、データが保持されている個々のノードに分析処理を移動する必要があります。
他の形態の分析は時間の制限が少なく、生データが受信された後にいくつかの計算処理や集計処理が必要になる場合があります。 これを、ウォーム分析と呼びます。 パフォーマンス分析は多くの場合このカテゴリに分類されます。 この場合、分離された 1 つのパフォーマンス イベントは、統計的に有意ではありません (突然の急増または誤作動によって引き起こされた可能性があるため)。一連のイベントからのデータの方が、より信頼性の高い全体像を提供します。
また、ウォーム分析は正常性の問題の診断に役立ちます。 正常性イベントは通常、ホット分析を通じて処理され、アラートがすぐに生成されます。 オペレーターはウォーム パスからのデータを調べることによって、正常性イベントの原因を掘り下げることができる必要があります。 このデータには、正常性イベントの原因となった問題につながるイベントに関する情報が含まれている必要があります。
監視の種類によっては、より長期的なデータが生成されます。 この分析は、定義済みのスケジュールに従って、後の日程で実行できます。 場合によっては、長期間にわたってキャプチャされた大量のデータに対して複雑なフィルター処理を実行する必要があります。 これを、 コールド分析と呼びます。 主な要件は、キャプチャしたデータが安全に格納されることです。 たとえば、使用状況の監視や監査にはある時点におけるシステムの状態についての正確な全体像を必要としますが、この情報は収集した直後に処理できる必要はありません。
また、コールド分析を利用して、正常性の予測分析のためのデータを提供することもできます。 特定の期間にわたって収集された履歴データを現在の正常性データ (ホット パスから取得) と組み合わせて、正常性の問題を引き起こす原因となる傾向を特定できます。 このような場合は、アラートを発信して修正措置を取ることができるようにすることをお勧めします。
データの関連付け
インストルメンテーションによってキャプチャされたデータは、システム状態に関するスナップショットを提供しますが、分析の目的はこのデータを有益なものにすることです。 次に例を示します。
- ある時点においてシステム レベルで大量の I/O 読み込みが発生した原因は何でしょうか。
- 大量のデータベース処理の結果でしょうか。
- これは、同じ時点におけるデータベースの応答時間、1 秒あたりのトランザクション数、およびアプリケーションの応答時間に反映されていますか。
その場合、負荷を軽減する対応策の 1 つは、データをより多くのサーバーに分割することです。 さらに、例外はシステムのあらゆるレベルでの障害の結果として発生する可能性があります。 1 つのレベルで発生した例外は、その上のレベルの障害を引き起こすことがよくあります。
このような理由により、システムやシステム上で実行されているアプリケーションの状態の全体像を把握するには、各レベルのさまざまな種類の監視データを組み合わせる必要があります。 その後、この情報を使ってシステムが期待どおり機能しているかどうか、システムの品質を向上させるために何ができるかを判断します。
セクション「 データを相互に関連付けるための情報」で説明しているように、イベントの関連付けに必要な集計をサポートするための十分なコンテキストやアクティビティ ID 情報が、生のインストルメンテーション データに含まれていることを確認する必要があります。 さらに、このデータはさまざまな形式で保持されている可能性があり、分析の際にはこの情報を解析して標準化された形式に変換する必要がある場合があります。
問題のトラブルシューティングと診断
診断では、根本原因の分析の実行など、エラーや予期しない動作の原因を判断できる必要があります。 一般的に必要な情報は、次のようなものです。
- 指定した期間における、システム全体または指定したサブシステムのイベント ログやトレースからの詳細情報。
- 指定した期間における、システム全体または指定したサブシステムで発生した、指定したあらゆるレベルの例外およびエラーによるスタック トレースすべて。
- 指定した期間における、システム全体または指定したサブシステムの失敗したプロセスのクラッシュ ダンプ。
- 指定した期間における、すべてのユーザーまたは選択したユーザーによって実行された操作を記録したアクティビティ ログ。
多くの場合、トラブルシューティングのためのデータを分析するには、システムのアーキテクチャと、ソリューションを構成するさまざまなコンポーネントの技術的な詳細に関する理解が必要です。 そのため、データの解釈、問題の原因の確定、および適切な対処の推奨に、大幅な手動による介入が必要になることがよくあります。 この情報のコピーを元の形式で格納し、専門家によるコールド分析に使用できるようにするだけで適切な場合があります。
データの視覚化とアラートの生成
すべての監視システムにとって重要な機能は、オペレーターが傾向や問題をすばやく特定できる形でデータを表示する機能です。 また、対処が必要となる重大なイベントが発生した際にオペレーターにすばやく通知する機能も重要です。
データを表示する方法は、ダッシュボードによる視覚化、アラートの生成、レポートなど、さまざまな形態を取ります。
ダッシュボードによる視覚化
データを視覚化するには、一連のチャート、グラフ、およびその他の図を使って情報を表示できるダッシュボードを使う方法が最も一般的です。 これらの表示項目をパラメーター化して、アナリストが特定の状況で重要なパラメーター (期間など) を選択できるようにする必要があります。
ダッシュボードは、階層的に整理することができます。 最上位のダッシュボードではシステムの全体像をあらゆる側面から確認できますが、オペレーターが詳細にドリルダウンできる機能も備えています。 たとえば、システムの全体的なディスク I/O を示すダッシュボードでは、アナリストが個々のディスクの I/O 率を表示して、1 つ以上の特定のデバイス アカウントで過度のトラフィックが発生していないかどうかを確認できるようにする必要があります。 また、理想的には、この I/O を発生させている各要求のソース (ユーザーまたはアクティビティ) などの関連情報もダッシュボードに表示される必要があります。 その後、この情報に基づいて、デバイス間に負荷を均等に分散した方がよいか (およびその方法)、デバイスを追加した方がシステムのパフォーマンスが向上するかどうかを判断します。
また、ダッシュボードはカラー コーディングやその他の視覚的な合図を使って、異常を示す値や想定の範囲外にある値を示します。 前の例を使うと、次のようになります。
- I/O 率が長期間にわたって最大容量に迫っている状況のディスク (ホット ディスク) は赤色で強調表示されます。
- I/O 率が定期的に短期間にわたって最大容量で実行されるディスク (ウォーム ディスク) は黄色で強調表示されます。
- 通常の使用状況を示すディスクは緑色で表示されます。
ダッシュボード システムが効果的に動作するには、動作対象となる生データが必要です。 独自のダッシュボード システムを構築している場合、または別の組織が開発したダッシュボードを活用する場合は、収集するインストルメンテーション データ、その粒度、ダッシュボードで使うためのフォーマットなどを把握する必要があります。
優れたダッシュボードは情報を表示するだけではなく、アナリストがその情報について掘り下げることができる手段を提供します。 一部のシステムにはオペレーターがこれらのタスクを実行し、基になるデータを探索できる管理ツールが用意されています。 他にもこの情報を保持するために使われるリポジトリによっては、このデータで直接クエリを実行し、また Microsoft Excel などのツールにインポートしてさらに詳しい分析やレポート作成を行うことができる場合があります。
注意
この情報は商業的に機密性が高い可能性があるため、ダッシュボードへのアクセスは承認されているユーザーに制限することをお勧めします。 また、ダッシュボードの基データはユーザーが変更できないように保護してください。
アラートの発信
アラートとは、インストルメンテーション データを監視、分析して、重大なイベントが検出された際に通知を生成するプロセスです。
アラートはシステムの正常性、応答性、および安全性を維持するための機能です。 ユーザーにパフォーマンス、可用性、およびプライバシーを保証する重要なシステムの一部で、即時に実行される必要があります。 アラートが発生したイベントは、オペレーターに通知される必要があります。 アラートは自動スケールなどのシステムの機能を呼び出すために使われる場合もあります。
アラートは通常、次のインストルメンテーション データによって変わります。
- セキュリティ イベント。 イベント ログに認証エラーや承認エラーが繰り返し発生していることが示されている場合は、システムが攻撃を受けている可能性があるため、オペレーターに通知する必要があります。
- パフォーマンス メトリック。 特定のパフォーマンス メトリックが指定されたしきい値を超えている場合は、迅速に対応する必要があります。
- 可用性情報。 障害が発生した場合は、1 つ以上のサブシステムをすぐに再起動するか、バックアップ リソースにフェールオーバーする必要があります。 サブシステムで障害が繰り返し発生する場合は、重大な問題が発生している可能性があります。
オペレーターは電子メール、ポケットベル、SMS テキスト メッセージなどの各種配布チャネルを使ってアラートの情報を受け取ります。 また、アラートには状況の重大度を示す情報が含まれていることがあります。 多くのアラート システムはサブスクライバー グループをサポートし、同じグループのメンバーであるすべてのオペレーターが同じアラートを受信します。
アラート システムはカスタマイズ可能で、基になるインストルメンテーション データの適切な値をパラメーターとして指定できます。 このアプローチにより、オペレーターはデータをフィルター処理して、関心のあるしきい値や値の組み合わせに焦点を絞ることができます。 場合によっては、アラート システムには生のインストルメンテーション データを提供できます。 他の状況では、集計したデータを提供する方が適切なこともあります (たとえば、あるノードで 10 分以上にわたって CPU 使用率が 90% を超えた場合にアラートがトリガーされるなど)。 アラート システムに提供される詳細には、適切な概要やコンテキスト情報も含まれている必要があります。 このデータにより、アラートが偽のイベントを誤検知する可能性が減少します。
レポーティング
レポートはシステムの全体像を把握するために使用されます。 現在の情報の他に、履歴データも組み込まれることがあります。 レポート自体の要件は 2 つのカテゴリに分類されます。運用レポートとセキュリティ レポートです。
運用レポートには通常、次の側面があります。
- 指定した期間における、システム全体または指定したサブシステムのリソース使用率を把握するための統計情報を集計します。
- 指定した期間における、システム全体または指定したサブシステムのリソース使用率の傾向を識別します。
- 指定した期間における、システム全体または指定したサブシステムで発生した例外を監視します。
- デプロイされたリソースの観点からアプリケーションの効率性を判断し、不必要にパフォーマンスに影響を与えずにリソースの量 (および関連するコスト) を縮小できるかどうかを判断します。
セキュリティ レポートは、顧客によるシステム利用の追跡に関する内容です。 次のような情報が含まれます。
- ユーザー操作の監査。 これには、各ユーザーが実行した個々の要求とその日時を記録する必要があります。 データは、特定のユーザーが特定の期間に実行した一連の操作を管理者がすぐに再構築できるように構築されている必要があります。
- ユーザーによるリソース使用率の追跡。 これには、ユーザーの各要求が、システムを構成する各種リソースにどのように、どの程度の時間アクセスしたかを記録する必要があります。 管理者はこのデータを使って、主に課金のために、指定した期間におけるユーザーごとの使用率レポートを作成できる必要があります。
多くの場合、レポートは定義されたスケジュールに従ってバッチ処理によって生成されます (待機時間は通常問題になりません)。しかし、必要に応じてアドホック ベースで生成することもできます。 たとえば、データを Azure SQL Database などのリレーショナル データベースに格納している場合、SQL Server Reporting Services などのツールを使ってデータを抽出してフォーマットし、それをレポートのセットとして表示することもできます。
次のステップ
- Azure Monitor の概要
- Microsoft Azure Storage の監視、診断、およびトラブルシューティング
- Microsoft Azure のアラートの概要
- Azure Portal を使用したサービス正常性通知の表示
- Application Insights とは何か?
- Azure 仮想マシンのパフォーマンス診断
- Visual Studio の SQL Server Data Tools (SSDT) をダウンロードし、インストールする
関連リソース
- 自動スケールのガイダンス では、オペレーターがシステムのパフォーマンスを継続的に監視してリソースの追加や削除に関して判断を行う必要性を軽減することで、管理オーバーヘッドを削減する方法について説明しています。
- 「正常性エンドポイントの監視パターン」では、公開されたエンドポイントを通じて外部ツールが定期的にアクセスできる機能チェックをアプリケーションに実装する方法について説明しています。
- 「Priority Queue パターン」では、緊急度の高い要求を緊急度の低いメッセージの前に処理できるように、キューに置かれたメッセージの優先順位を設定する方法を示しています。