Azure データ プラットフォームの DR - 推奨事項
得られた教訓
関係するすべての関係者が、高可用性 (HA) とディザスター リカバリー (DR) の違いを理解していることを確認します。 これらの概念を混同すると、ソリューションが一致しない可能性があります。
復旧ポイント目標 (RPO) と目標復旧時間 (RTO) を定義するには、次の要因に関するビジネス利害関係者の期待について話し合います。
許容できるダウンタイムの量。 通常、より高速な復旧ではコストが高くなる点に注意してください。
利害関係者が保護を必要とするインシデントの種類と、発生する可能性。 たとえば、サーバーの障害は、リージョン内のすべてのデータセンターに影響を与える自然災害よりも発生する可能性が高くなります。
システムの使用不能がビジネスに及ぼす影響。
長期的なソリューションの運用費 (OPEX) 予算。
エンド ユーザーが受け入れることができる低下したサービス オプションを検討します。 次のようなオプションがあります。
データが -date up-toでない場合でも、視覚化ダッシュボードにアクセスできます。 このシナリオでは、インジェスト パイプラインが失敗した場合でも、エンド ユーザーは自分のデータを表示できます。
書き込み機能のない読み取りアクセス。
ターゲットの RTO メトリックと RPO メトリックによって、実装する DR 戦略が決まります。 これらの戦略には、アクティブ/アクティブ、アクティブ/パッシブ、および障害発生時のアクティブ/再デプロイが含まれます。 許容可能なダウンタイムを考慮に入れます。独自の 複合サービス レベル 目標を検討してください。
次のような、システムの可用性に影響を与える可能性があるすべてのコンポーネントを理解していることを確認します。
ID 管理。
ネットワーク トポロジ。
シークレット管理とキー管理。
データ ソース:
自動化とジョブのスケジュール設定。
GitHub や Azure DevOps などのソース リポジトリとデプロイ パイプライン。
停止の早期検出も、RTO と RPO の値を大幅に減少させる方法です。 次の主な要因を含めます。
Microsoft に従って、停止とは何か、および停止の定義にどのようにマップされるかを定義します。 Microsoft の定義は、製品またはサービス レベルの Azure サービス レベル アグリーメント (SLA) ページで確認できます。
目標をサポートするためにメトリックとアラートを迅速に確認する説明責任のあるチームを使用して、効率的な監視およびアラート システムを実装します。
サブスクリプションの設計では、DR 用の追加のインフラストラクチャを元のサブスクリプションに格納できます。 通常、Azure Data Lake Storage や Azure Data Factory などのサービスとしてのプラットフォーム サービスには、ネイティブ フェールオーバー機能が含まれます。 これらの機能を使用すると、元のサブスクリプション内に残っている間に、他のリージョンのセカンダリ インスタンスを使用できます。 コストを最適化するために、一部の組織では、DR 関連のリソース専用のリソース グループを割り当てることを選択する場合があります。
サブスクリプションの制限により、 このアプローチに制約が生じる可能性があります。
その他の制約には、DR リソース グループが通常どおりのビジネス ワークフローに使用されないようにするための設計の複雑さと管理の制御が含まれる場合があります。
ソリューションの重要度と依存関係に基づいて DR ワークフローを設計します。 たとえば、データ ウェアハウスが動作する前に Azure Analysis Services インスタンスを再構築しないでください。エラーがトリガーされるためです。 開発ラボはプロセスの後半に残し、最初にコア エンタープライズ ソリューションを復旧します。
ソリューション間で並列化できる復旧タスクを特定します。 この方法では、RTO の合計が減少します。
ソリューションで Azure Data Factory が使用されている場合は、セルフホステッド統合ランタイムをスコープに含めるのを忘れないでください。 Azure Site Recovery は、これらのマシンに最適です。
手動操作を可能な限り自動化して、人為的ミスを防ぎます(特に負荷がかかっているとき)。 推奨事項は次のとおりです。
Bicep、Azure Resource Manager テンプレート、または PowerShell スクリプトを使用してリソース プロビジョニングを採用します。
ソース コードとリソース構成のバージョン管理を採用する。
select-ops ではなく、継続的インテグレーションと継続的デリバリー リリース パイプラインを使用します。
フェールオーバーの計画があるため、プライマリ インスタンスにフォールバックする手順を検討する必要があります。
明確なインジケーターとメトリックを定義して、フェールオーバーが成功し、ソリューションが動作していることを検証します。 パフォーマンスが正常に戻っていることを確認します( プライマリ機能とも呼ばれます)。
フェールオーバー後に SLA を変更しないか、サービス品質の一時的な低下を許可するかを決定します。 この決定は、サポートされているビジネス サービス プロセスによって大きく異なります。 たとえば、部屋予約システムのフェールオーバーは、コア運用システムとは大きく異なります。
インフラストラクチャ レベルではなく、特定のユーザー シナリオに基づいて RTO または RPO 定義を作成します。 この方法では、障害または障害発生時に復旧に優先順位を付ける必要があるプロセスとコンポーネントを決定する方法の細分性が向上します。
フェールオーバーを続行する前に、ターゲット リージョンで容量チェックを実行してください。 大規模な災害では、多くのお客様が同じペアリージョンに同時にフェールオーバーを試みる場合があります。 このシナリオでは、リソースプロビジョニングの遅延または競合が発生する可能性があります。 これらのリスクが許容できない場合は、アクティブ/アクティブまたはアクティブ/パッシブの DR 戦略を検討してください。
復旧プロセスとアクション所有者を文書化するには、DR 計画を作成して管理する必要があります。 一部のチーム メンバーが休暇中である可能性があることに注意し、セカンダリ連絡先が含まれていることを確認します。
定期的な DR 訓練を実行して DR 計画ワークフローを検証し、必要な RTO と RPO の要件を満たしていることを確認し、責任あるチームをトレーニングします。 データと構成のバックアップを定期的にテストして、目的に 合っていることを確認します。つまり、意図した用途に適しており、効果的です。 このプロセスにより、復旧アクティビティをサポートできるようになります。
ネットワーク、ID、およびリソースのプロビジョニングを担当するチームとの早期コラボレーションにより、次の方法に対する最適なソリューションに関する合意が容易になります。
プライマリ サイトからセカンダリ サイトにユーザーとトラフィックをリダイレクトします。 ドメイン ネーム システムのリダイレクトや 、Azure Traffic Manager などの特定のツールの使用などの概念を評価できます。
セカンダリ サイトへのアクセス権と権限を、タイムリーかつ安全な方法で提供します。
災害発生時には、関係する多くの当事者間の効果的なコミュニケーションが、計画を効率的かつ迅速に実施するための鍵となります。 Teams には次のものが含まれる場合があります。
- 意思決定者。
- インシデント対応チーム。
- 影響を受ける内部ユーザーとチーム。
- 外部チーム。
適切なタイミングでさまざまなリソースをオーケストレーションすることで、DR 計画の実装の効率が確保されます。
考慮事項
アンチパターン
この記事シリーズをコピー/貼り付けする
この記事シリーズでは、Azure 固有の DR プロセスをより深く理解しようとしているお客様向けのガイダンスを提供します。 これは、単一の顧客固有の Azure 実装ではなく、一般的な Microsoft の知的財産と参照アーキテクチャに基づいています。
このコンテンツは、強力な基礎理解を提供します。 しかし、お客様は、目的に合った DR 戦略とプロセスを開発するために、独自のコンテキスト、実装、要件を考慮してアプローチを調整する必要があります。
DR を技術のみのプロセスとして扱う
ビジネス利害関係者は、DR の要件を定義し、サービスの復旧を確認するために必要なビジネス検証手順を完了する上で重要です。
ビジネス利害関係者がすべての DR アクティビティに関与していることを確認することで、目的に合った、ビジネス価値を表し、実装可能な DR プロセスが提供されます。
DR プランの "設定と忘れ"
個々の顧客がさまざまなコンポーネントやサービスを使用する方法と同様に、Azure は絶えず進化しています。 目的に合った DR プロセスは、そのプロセスと共に進化する必要があります。
お客様は、ソフトウェア開発ライフサイクルまたは定期的なレビューを通じて、DR 計画を定期的に再評価する必要があります。 この戦略は、サービス復旧計画を有効に保ち、コンポーネント、サービス、またはソリューション全体の変更に適切に対処します。
紙ベースの評価
DR イベントのエンドツーエンドのシミュレーションは、最新のデータ エコシステム全体で実行することは困難です。 ただし、影響を受けるコンポーネント間で完全なシミュレーションを可能な限り近づけるように努力する必要があります。
定期的にスケジュールされた訓練は、組織が自信を持って DR 計画を実装する本能的能力を開発するのに役立ちます。
Microsoft に頼ってすべてを実行する
Microsoft Azure サービス内には、使用されるクラウド サービス レベルに固定された明確な 責任部門があります。
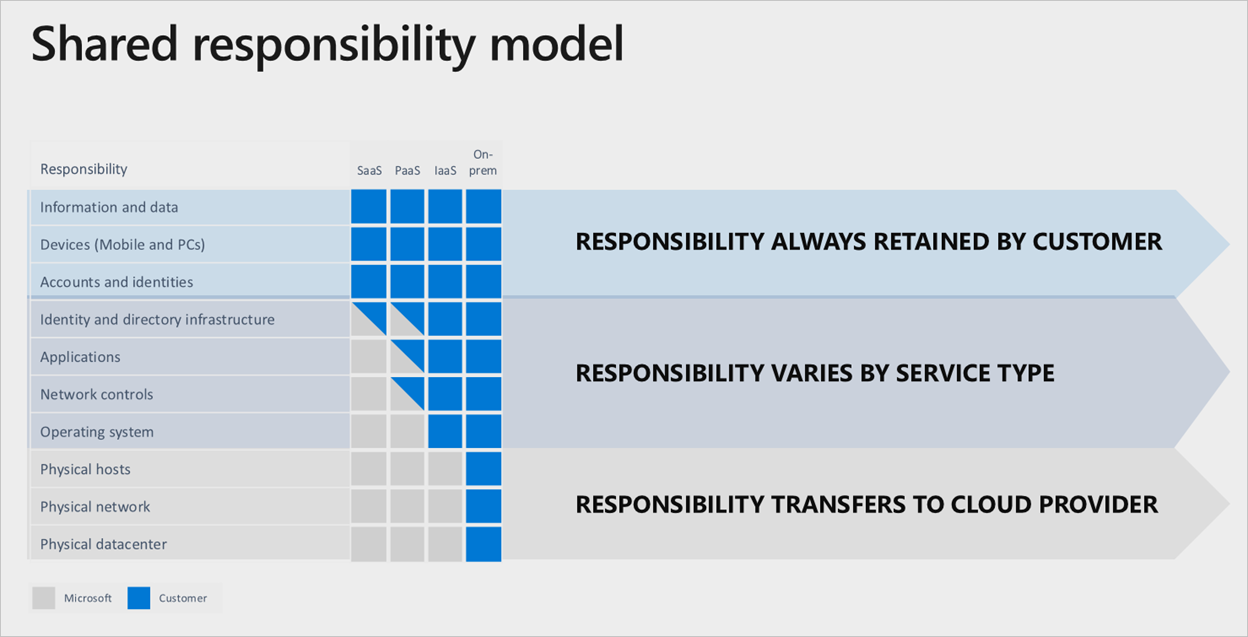
完全なサービスとしてのソフトウェア スタックが使用されている場合でも、お客様は、アカウント、ID、データが正しく、up-to日付であることを確認する責任と、Azure サービスとの対話に使用されるデバイスを保持します。
イベントの範囲と方法
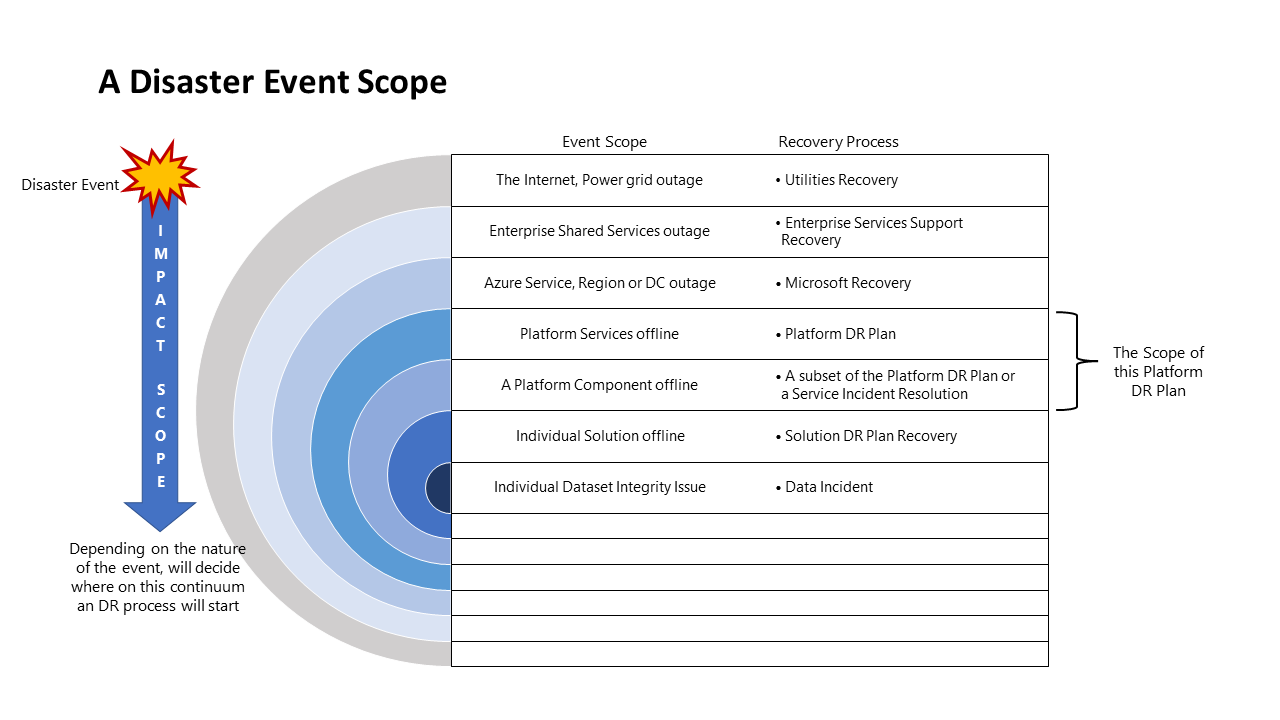
災害イベントの範囲
異なるイベントには、異なる応答を必要とする影響の範囲が異なります。 次の図は、災害イベントの影響と対応の範囲を示しています。
災害への対処方法のオプション
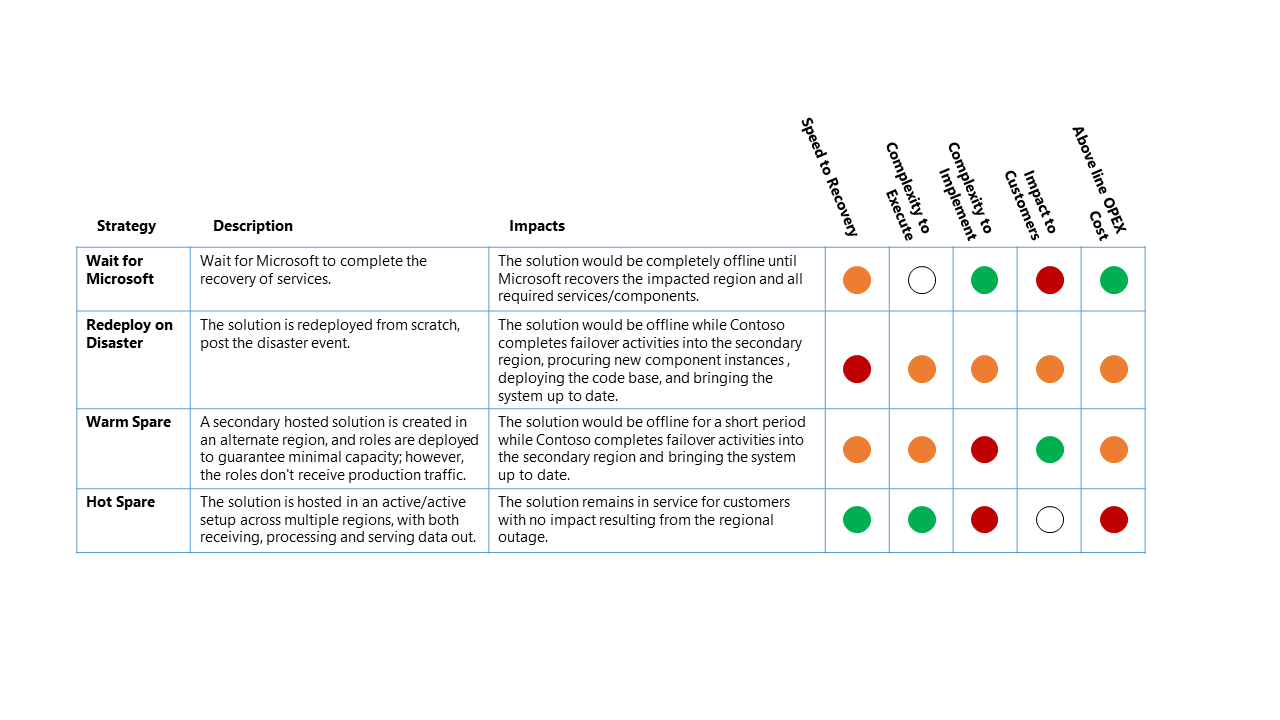
DR 戦略には、次の 4 つの大まかなオプションがあります。
Microsoft を待つ
名前が示すように、影響を受けるリージョンのサービスが Microsoft によって完全に復旧されるまで、ソリューションはオフラインになります。 復旧後、顧客はソリューションを検証し、サービスの復旧を確実にするために更新されます。
障害発生時の再デプロイ
このソリューションは、障害イベントの後、利用可能なリージョンに新しいデプロイとして手動で再デプロイされます。
ウォーム スペア (アクティブ/パッシブ)
セカンダリ ホステッド ソリューションは代替リージョンに作成され、最小限の容量を保証するためにコンポーネントがデプロイされます。 ただし、コンポーネントは運用トラフィックを受信しません。
代替リージョンのセカンダリ サービスが オフになっているか、DR イベントが発生するまで低いパフォーマンス レベルで実行される場合があります。
ホット スペア (アクティブ/アクティブ)
ソリューションは、複数のリージョンにわたるアクティブ/アクティブセットアップでホストされます。 セカンダリ ホステッド ソリューションは、大規模なシステムの一部としてデータを受信、処理、および処理します。
DR 戦略の効果
サービスの回復性の高いレベルに起因する運用コストは、DR 戦略の 主要な設計決定 において大きな役割を果たすことがよくありますが、他の重要な要因も考慮する必要があります。
注
コストの最適化 は、 Azure Well-Architected Framework におけるアーキテクチャの卓越性の 5 つの柱の 1 つです。 その目標は、不要な費用を削減し、運用効率を向上することです。
この作業例の DR シナリオは、Contoso Data Platform をホストするプライマリ リージョンに直接影響する完全な Azure リージョンの停止です。
次の表に、オプションの比較を示します。 緑色のインジケーターを持つ戦略は、オレンジ色または赤のインジケーターを持つ戦略よりも、その分類に適しています。
分類キー
この停止シナリオでは、4 つの高レベル DR 戦略に対する相対的な影響は、次の要因に基づいています。
RTO: ディザスター イベントからプラットフォーム サービスの復旧までの予想経過時間。
実行の複雑さ: 組織が復旧アクティビティを実行するための複雑さ。
実装の複雑さ: DR 戦略を実装する組織の複雑さ。
お客様への影響: DR 戦略からのデータ プラットフォーム サービスのお客様への直接的な影響。
上記の OPEX コスト: この戦略の実装によって予想される追加コスト (追加のコンポーネントやサポートに必要な追加リソースに対する Azure の毎月の課金の増加など)。