TDSP は、予測分析ソリューションと AI アプリケーションを効率的に実現するために使用できるアジャイルで反復的なデータ サイエンス手法です。 TDSP は、チームの役割を連携させる最適な方法を推奨して、チームのコラボレーションと学習を強化します。 TDSP には、Microsoft やその他の業界リーダーのベスト プラクティスとフレームワークが組み込まれており、チームがデータ サイエンス イニシアチブを効果的に実装できるよう支援します。 TDSP を使用すると、分析プログラムのベネフィットを十分に得ることができます。
この記事では、TDSP とその主なコンポーネントの概要について説明します。 Microsoftのツールとインフラストラクチャを使用してTDSPを実装する方法に関するガイダンスを提供します。 この記事全体で、より詳細なリソースを見つけることができます。
TDSP の主な構成要素
TDSPには、次の主要コンポーネントがあります。
- データ サイエンス ライフサイクルの定義
- 標準プロジェクト構造
- データ サイエンス プロジェクトに最適なインフラストラクチャとリソース
- 責任ある AI: 倫理原則に基づいた AI の発展への取り組み
データ サイエンス ライフサイクル
TDSPは、データサイエンスプロジェクトの開発の構造化に使用できるライフサイクルを提供します。 ライフサイクルには、正常なプロジェクトが従う完全な手順の概要が示されます。
タスクベースのTDSPは、データマイニングの業界間標準プロセス (CRISP-DM) 、データベースでのナレッジ検出 (KDD) プロセス、または別のカスタムプロセスなど、他のデータサイエンスライフサイクルと組み合わせることができます。 大局的に見ると、これらの各種の手法には多くの共通点があります。
インテリジェント アプリケーションの一部であるデータ サイエンス プロジェクトがある場合は、このライフサイクルを使用します。 インテリジェントアプリケーションでは、予測分析のために機械学習またはAIモデルをデプロイします。 このプロセスは、探索的なデータサイエンスプロジェクトや即席の分析プロジェクトにも使用できます。
TDSP ライフサイクルは、チームが反復的に実行する 5 つの主要なステージで構成されています。 次の段階があります。
TDSPライフサイクルの視覚的な表現を次に示します。
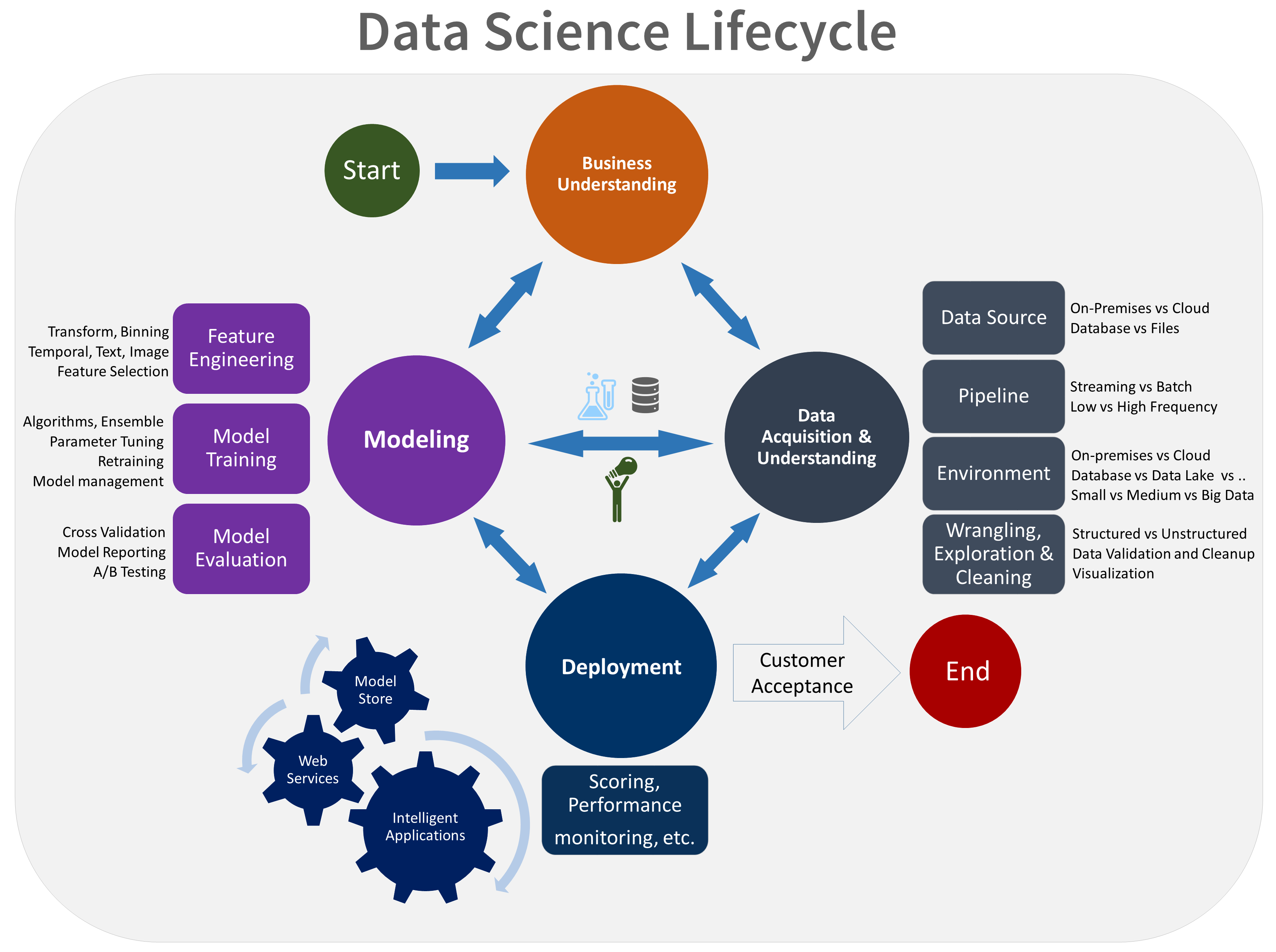
各ステージの目標、タスク、およびドキュメント成果物の詳細については、「TDSP ライフサイクル」を参照してください。
これらのタスクと成果物は、次のようなプロジェクトの各種役割と一致します。
- ソリューション アーキテクト
- プロジェクト マネージャー
- データ エンジニア
- データ サイエンティスト
- アプリケーション開発者
- プロジェクト リード
次の図は、横軸に示されているライフサイクルの各ステージに対応するタスク (青色) と成果物 (緑色) が、縦軸に示されている役割ごとに示されています。

標準プロジェクト構造
チームは、Azureインフラストラクチャを使用してデータサイエンス資産を整理できます。
Azure Machine Learningでは、オープンソースのMLflowがサポートされています。 データ サイエンスと AI プロジェクト管理には MLflow を使用することをお勧めします。 MLflowは、機械学習のライフサイクル全体を管理するように設計されています。 さまざまなプラットフォームでモデルをトレーニングして提供するため、実験を実行する場所に関係なく、一貫したツール セットを使用できます。 MLflow は、コンピューター、リモート コンピューティング先、仮想マシン、または機械学習のコンピューティング インスタンスでローカルに使用できます。
MLflowは、いくつかの主要な機能で構成されています。
実験の追跡: MLflow を使用して、パラメーター、コード バージョン、メトリック、出力ファイルなどの実験を追跡できます。 この機能を使用すると、さまざまな実行を比較し、実験プロセスを効率的に管理できます。
パッケージ コード: 依存関係と構成を含む機械学習コードをパッケージ化するための標準化された形式を提供します。 このパッケージ化により、実行を再現し、他のユーザーとコードを共有することが容易になります。
モデルの管理: MLflow には、モデルの管理とバージョン管理を行う機能が用意されています。 さまざまな機械学習フレームワークをサポートしているため、モデルの保存、バージョン管理、提供ができます。
モデルの提供とデプロイ: MLflow では、モデルの提供とデプロイのための機能が統合されており、さまざまな環境でモデルを簡単にデプロイできます。
モデルの登録: バージョン管理、ステージ遷移、注釈など、モデルのライフサイクルを管理できます。 MLflow を使用すると、コラボレーション環境で一元化されたモデル ストアを維持できます。
APIとUIの使用: Azure内では、MLflowはMachine Learning APIバージョン2にバンドルされているため、プログラムでシステムと対話できます。 Azure portalを使用してUIと対話できます。
MLflow は、実験からデプロイまでの機械学習開発プロセスを簡素化し、標準化します。
Machine Learning は Git リポジトリと統合されるため、Git 互換サービス (GitHub、GitLab、Bitbucket、Azure DevOps、その他の Git 互換サービスなど) を使用できます。 チームは、Machine Learning で既に追跡されている資産に加えて、次のような他のプロジェクト データを格納するために Git 互換サービス内で独自の分類法を開発できます。
- ドキュメント
- プロジェクト データ: 最終的なプロジェクト レポートなど
- データ レポート: データ辞書やデータ品質レポートなど
- モデル: モデル レポートなど
- コード
- データ準備
- モデルの開発
- 運用化 (セキュリティとコンプライアンスを含む)
インフラストラクチャとリソース
TDSP では、次のカテゴリで分析とストレージの共有インフラストラクチャを管理する方法について、推奨事項が提供されます。
データセットを格納するためのクラウド ファイル システム
クラウド ファイル システムは、いくつかの理由から TDSP にとって重要です。
一元化されたデータ ストレージ: クラウド ファイル システムには、データ サイエンス チームのメンバー間のコラボレーションに不可欠なデータセットを格納するための一元化された場所が用意されています。 一元化により、すべてのチーム メンバーが最新のデータにアクセスでき、古くなったデータセットや一貫性のないデータセットで作業するリスクが軽減されます。
スケーラビリティ: クラウド ファイル システムは、データ サイエンス プロジェクトではありがちな大量のデータを処理できます。 ファイル システムは、プロジェクトのニーズに合わせて拡張できるスケーラブルなストレージ ソリューションを提供します。 それにより、チームは、ハードウェアの制限を気にすることなく、大量のデータセットを格納して処理できます。
アクセシビリティ: クラウド ファイル システムを使用すると、インターネット接続を使用してどこからでもデータにアクセスできます。 このアクセスは、分散チームにとって、またはチーム メンバーがリモートで作業する必要がある場合に重要です。 クラウド ファイル システムはシームレスなコラボレーションを促進し、データに常にアクセスできるようにします。
セキュリティとコンプライアンス: クラウド プロバイダーは多くの場合、暗号化、アクセス制御、業界標準や規制への準拠など、強力なセキュリティ対策を実装します。 強力なセキュリティ対策は機密データを保護でき、チームが法的要件と規制要件を満たすのに役立ちます。
バージョン管理: クラウド ファイル システムには、多くの場合、バージョン管理機能が搭載されており、チームはデータセットの変更を経時的に追跡する際にそれを使用できます。 バージョン管理は、データの整合性を維持し、データ サイエンス プロジェクトの結果を再現するうえで重要です。 また、発生した問題の監査とトラブルシューティングにも役立ちます。
ツールとの統合: クラウド ファイル システムは、さまざまなデータ サイエンス ツールやプラットフォームとシームレスに統合できます。 ツールの統合により、データ インジェスト、データ処理、データ分析が簡単になります。 たとえば、Azure Storage は、Machine Learning や Azure Databricks などのデータ サイエンス ツールとうまく統合されます。
コラボレーションと共有: クラウド ファイル システムを使用すると、データセットを他のチーム メンバーや関係者と簡単に共有できます。 これらのシステムでは、共有フォルダーやアクセス許可管理などのコラボレーション機能がサポートされています。 コラボレーション機能はチームワークを促進し、適切なユーザーが必要なデータにアクセスできるようになります。
コスト効率: クラウド ファイル システムは、オンプレミスのストレージ ソリューションを維持する場合よりもコスト効率が高くなります。 クラウド プロバイダーには、従量課金オプションを含む柔軟な価格モデルがあり、データ サイエンス プロジェクトの実際の使用状況とストレージ要件に基づいてコストを管理するのに役立ちます。
ディザスター リカバリー: クラウド ファイル システムには、通常、データのバックアップとディザスター リカバリーの機能が含まれています。 これらの機能は、ハードウェア障害、誤削除、その他のディザスターからデータを保護するのに役立ちます。 安心感を与え、データ サイエンス操作の継続性をサポートします。
自動化とワークフローの統合: クラウド ストレージ システムは自動化されたワークフローに統合できるため、データ サイエンス プロセスの異なるステージ間でシームレスなデータ転送が可能です。 自動化は効率を向上させ、データを管理するために必要な手作業を減らすことができます。
クラウド ファイル システムに推奨される Azure リソース
- Azure Blob Storage - Azure Blob Storage に関する包括的なドキュメント。これは、非構造化データのスケーラブルなオブジェクト ストレージ サービスです。
- Azure Data Lake Storage - ビッグ データの分析用に設計され、大規模なデータセットをサポートする Azure Data Lake Storage Gen2 に関する情報。
- Azure Files - クラウドでフル マネージド ファイル共有を提供する Azure Files の詳細。
要約すると、クラウド ファイル システムは、データ ライフサイクル全体をサポートする、スケーラブルで安全かつアクセス可能なストレージ ソリューションを提供するため、TDSP にとって非常に重要です。 クラウド ファイル システムを使用すると、さまざまなソースからのシームレスなデータ統合が可能になり、包括的なデータ取得と理解がサポートされます。 データ科学者は、クラウド ファイル システムを使用して、大規模なデータセットを効率的に格納、管理し、そうしたデータセットにアクセスできます。 この機能は、機械学習モデルのトレーニングとデプロイに不可欠です。 これらのシステムでは、統合された環境でチーム メンバーが同時にデータを共有して作業することができるため、コラボレーションも強化されます。 クラウド ファイル システムは、データを保護し、規制要件に準拠させるのに役立つ強力なセキュリティ機能を備えています。これは、データの整合性と信頼性を維持するために不可欠なことです。
クラウド データベース
クラウド データベースは、いくつかの理由で TDSP で重要な役割を果たします。
スケーラビリティ: クラウド データベースは、プロジェクトのデータ ニーズの増加に合わせて簡単に拡張できるスケーラブルなソリューションを提供します。 スケーラビリティは、大規模で複雑なデータセットを頻繁に処理するデータ サイエンス プロジェクトにとって非常に重要です。 クラウド データベースは、手動による介入やハードウェアのアップグレードを必要とせずに、さまざまなワークロードを処理できます。
パフォーマンスの最適化: 開発者は、自動インデックス作成、クエリ最適化、負荷分散などの機能を使用して、クラウド データベースのパフォーマンスを最適化します。 これらの機能によって、高速で効率的なデータ取得とデータ処理が確保されます。これは、リアルタイムまたはほぼリアルタイムのデータ アクセスを必要とするデータ サイエンス タスクにとって非常に重要です。
アクセシビリティとコラボレーション: Teams は、クラウド データベースに格納されているデータに任意の場所からアクセスできます。 このアクセシビリティにより、地理的に分散している可能性のあるチーム メンバー間のコラボレーションが促進されます。 アクセシビリティとコラボレーションは、分散チームやリモートで作業するユーザーにとって重要です。 クラウド データベースでは、同時アクセスとコラボレーションを可能にするマルチユーザー環境がサポートされています。
データ サイエンス ツールとの統合: クラウド データベースは、さまざまなデータ サイエンス ツールやプラットフォームとシームレスに統合されます。 たとえば、Azure クラウド データベースは、Machine Learning や Power BI などのデータ分析ツールとうまく統合されます。 この統合により、インジェストやストレージから分析や視覚化まで、データ パイプラインが合理化されます。
セキュリティとコンプライアンス: クラウド プロバイダーは、データ暗号化、アクセス制御、業界標準や規制への準拠などを含む、強力なセキュリティ対策を実装します。 セキュリティ対策は機密データを保護でき、チームが法的要件と規制要件を満たすのに役立ちます。 セキュリティ機能は、データの整合性とプライバシーを維持するために不可欠です。
コスト効率: クラウド データベースは、多くの場合、従量課金制モデルで動作します。これは、オンプレミスのデータベース システムを維持するよりもコスト効率が高い場合があります。 この価格の柔軟性により、組織は予算を効果的に管理し、使用したストレージおよびコンピューティング リソースに対してのみ料金を支払うことができます。
自動バックアップとディザスター リカバリー: クラウド データベースには、自動バックアップとディザスター リカバリー ソリューションが備わっています。 これらのソリューションにより、ハードウェア障害、誤削除、またはその他のディザスターが発生した場合でも、データ損失を防ぐことができます。 信頼性は、データ サイエンス プロジェクトでデータの継続性と整合性を維持するために重要です。
リアルタイム データ処理: 多くのクラウド データベースでは、リアルタイムのデータ処理と分析がサポートされています。これは、最新の情報を必要とするデータ サイエンス タスクに不可欠です。 この機能により、データ科学者は最新の利用可能なデータに基づいてタイムリーな意思決定を行えます。
データ統合: クラウド データベースは、他のデータ ソース、データベース、データ レイク、外部データ フィードと簡単に統合できます。 統合は、データ科学者が複数のソースからのデータを結合し、包括的なビューとより高度な分析を提供するのに役立ちます。
柔軟性と多様性: クラウド データベースには、リレーショナル データベース、NoSQL データベース、データ ウェアハウスなど、さまざまな形式があります。 この多様性により、データ サイエンス チームは、構造化データ ストレージ、非構造化データ処理、大規模データ分析など、チームの固有のニーズに最適な種類のデータベースを選べます。
高度な分析のサポート: クラウド データベースには、多くの場合、高度な分析と機械学習のサポートが組み込まれています。 たとえば、Azure SQL Database には組み込みの機械学習サービスが用意されています。 これらのサービスを使用すると、データ科学者はデータベース環境内で高度な分析を直接実行できます。
クラウド データベースに推奨される Azure リソース
- Azure SQL Database - フル マネージド リレーショナル データベース サービスであるAzure SQL Databaseに関するドキュメント。
- Azure Cosmos DB - グローバルに分散されたマルチモデル データベース サービスである Azure Cosmos DB に関する情報。
- Azure Database for PostgreSQL - アプリの開発とデプロイのためのマネージド データベース サービスである Azure Database for PostgreSQL に関するガイド。
- Azure Database for MySQL - MySQL データベースのマネージド サービスである Azure Database for MySQL の詳細。
要約すると、クラウド データベースは、データドリブン プロジェクトをサポートするスケーラブルで信頼性の高い、効率的なデータ ストレージおよび管理ソリューションを提供するため、TDSP にとって非常に重要です。 シームレスなデータ統合が容易になるため、データ科学者はさまざまなソースから大規模なデータセットを取り込み、前処理して分析することができます。 クラウド データベースは、機械学習モデルの開発、テスト、デプロイに不可欠な迅速なクエリとデータ処理を可能にします。 また、クラウド データベースは、チーム メンバーがデータに同時にアクセスして操作するための一元化されたプラットフォームを提供して、コラボレーションを強化します。 最後に、クラウド データベースは高度なセキュリティ機能とコンプライアンス サポートを提供して、データを常に保護し、規制標準に準拠した状態を維持します。これは、データの整合性と信頼を維持するうえで重要です。
SQL または Spark を使用するビッグ データ クラスター
SQL または Spark を使用するビッグ データ クラスターは、いくつかの理由から TDSP の基礎となります。
大量データの処理: ビッグ データ クラスターは、大量データを効率的に処理できるように設計されています。 データ サイエンス プロジェクトには、従来のデータベースの容量を超える大規模なデータセットが含まれることがよくあります。 SQL ベースのビッグ データ クラスターと Spark は、このデータを大規模に管理および処理できます。
分散コンピューティング: ビッグ データ クラスターでは、分散コンピューティングを使用して、データと計算タスクを複数のノードに分散します。 並列処理機能により、データ処理および分析タスクが大幅に高速化されます。これは、データ サイエンス プロジェクトでタイムリーな洞察を得るうえで不可欠です。
スケーラビリティ: ビッグ データ クラスターは、ノードを追加することで水平方向に高いスケーラビリティを提供し、既存のノードの能力を高めることによって垂直方向に高いスケーラビリティを提供します。 スケーラビリティにより、データのサイズと複雑さの増大に対応し、プロジェクトのニーズに合わせてデータ インフラストラクチャを拡張できるようになります。
データ サイエンス ツールとの統合: ビッグ データ クラスターは、さまざまなデータ サイエンス ツールやプラットフォームとうまく統合されます。 たとえば、Spark は Hadoop とシームレスに統合され、SQL クラスターはさまざまなデータ分析ツールと連携します。 統合により、データ インジェストから分析や視覚化までのスムーズなワークフローが促進されます。
高度な分析: ビッグ データ クラスターでは、高度な分析と機械学習がサポートされます。 たとえば、Spark には次の組み込みライブラリが用意されています。
- 機械学習、MLlib
- グラフ処理、GraphX
- ストリーム処理、Spark Streaming
これらの機能を使用すると、データ科学者はクラスター内で複雑な分析を直接実行できます。
リアルタイム データ処理: ビッグ データ クラスター (特に Spark を使用するクラスター) では、リアルタイムデータ処理がサポートされます。 この機能は、最新のデータ分析と意思決定を必要とするプロジェクトにとって非常に重要です。 リアルタイム処理は、不正行為の検出、リアルタイムの推奨事項、動的価格設定などのシナリオで役立ちます。
データ変換と抽出、変換、読み込み (ETL): ビッグ データ クラスターは、データ変換と ETL プロセスに最適です。 複雑なデータ変換、クリーニング、集計タスクを効率的に処理できます。これは、データを分析する前に必要になることがよくあります。
コスト効率: ビッグ データ クラスターは、特に Azure Databricks などのクラウド サービスのようなクラウドベース ソリューションを使用する場合、コスト効率が高くなります。 これらのサービスでは、従量課金制を含む柔軟な価格モデルを提供しており、オンプレミスのビッグデータ インフラストラクチャを維持する場合よりも経済的です。
フォールト トレランス: ビッグ データ クラスターはフォールト トレランスを念頭に置いて設計されています。 ノード間でデータをレプリケートすることで、一部のノードに障害が発生した場合でもシステムが稼働し続けられるようにします。 この信頼性は、データ サイエンス プロジェクトでデータの整合性と可用性を維持するために重要です。
データ レイクの統合: ビッグデータ クラスターは、多くの場合、データ レイクとシームレスに統合されます。これにより、データ科学者はさまざまなデータ ソースに統一された方法でアクセスして分析できるようになります。 統合により、構造化データと非構造化データの組み合わせがサポートされ、より包括的な分析が可能になります。
SQL ベースの処理: SQL を理解しているデータ科学者の場合、Spark SQL や SQL on Hadoop などの SQL クエリを処理するビッグ データ クラスターには、ビッグ データのクエリを実行したり、ビッグ データを分析したりするための使い慣れたインターフェイスが用意されています。 この使いやすさにより、分析プロセスがさらに加速され、より幅広いユーザーがアクセスしやすくなります。
コラボレーションと共有: ビッグ データ クラスターでは、複数のデータ科学者とアナリストが同じデータセットで共同作業できるコラボレーション環境がサポートされています。 チームワークと知識共有を促進するコード、ノートブック、結果を共有する機能が用意されています。
セキュリティとコンプライアンス: ビッグ データ クラスターは、データ暗号化、アクセス制御、業界標準への準拠などの堅牢なセキュリティ機能を提供します。 セキュリティ機能は機密データを保護し、チームが規制要件を満たすのに役立ちます。
ビッグ データ クラスターに推奨される Azure リソース
- Machine Learning の Apache Spark: Machine Learning と Azure Synapse Analytics の統合により、Apache Spark フレームワークを介して分散計算リソースに簡単にアクセスできます。
- Azure Synapse Analytics: ビッグ データとデータ ウェアハウスを統合する Azure Synapse Analytics の包括的なドキュメント。
要約すると、SQL であろうと Spark であろうと、ビッグ データ クラスターは、膨大な量のデータを効率的に処理するために必要な計算能力とスケーラビリティを提供するため、TDSP にとって非常に重要です。 ビッグ データ クラスターを使用すると、データ科学者は大規模なデータセットに対して複雑なクエリと高度な分析を実行できるようになり、深い分析情報と正確なモデル開発が可能になります。 分散コンピューティングを使用すると、これらのクラスターによって迅速なデータ処理と分析が可能になり、それによってデータ サイエンスのワークフロー全体が加速されます。 ビッグ データ クラスターでは、さまざまなデータ ソースやツールとのシームレスな統合もサポートされており、複数の環境からデータを取り込み、処理し、分析する機能が強化されます。 ビッグ データ クラスターは、チームがリソース、ワークフロー、結果を効果的に共有できる統合プラットフォームを提供して、コラボレーションと再現性も促進します。
AI と機械学習のサービス
AI サービスと機械学習 (ML) サービスは、いくつかの理由で TDSP に不可欠です。
高度な分析: AI サービスと ML サービスにより、高度な分析が可能になります。 データ科学者は、高度な分析を使用して、複雑なパターンを発見し、予測を行い、従来の分析方法では不可能な分析情報を導き出すことができます。 これらの高度な機能は、影響力の大きいデータ サイエンス ソリューションを作成するために不可欠です。
反復的なタスクの自動化: AI サービスと ML サービスを使用すると、データ クリーニング、特徴エンジニアリング、モデルのトレーニングなどの反復的なタスクを自動化できます。 自動化により時間を節約でき、データ科学者はプロジェクトのより戦略的な側面に集中できるようになり、それによって全体的な生産性が向上します。
精度とパフォーマンスの向上: ML モデルは、データから学習して、予測と分析の精度とパフォーマンスを向上させることができます。 これらのモデルは、さらに多くのデータにさらされながら継続的に改善され、より適切な意思決定とより信頼性の高い結果をもたらします。
スケーラビリティ: Machine Learning などのクラウド プラットフォームによって提供される AI サービスと ML サービスは、非常にスケーラブルです。 大量のデータと複雑な計算を処理できるため、データ サイエンス チームは基になるインフラストラクチャの制限を気にすることなく、増大する需要に合わせてソリューションを拡張できます。
他のツールとの統合:AI サービスと ML サービスは、Azure Data Lake、Azure Databricks、Power BI など、Microsoft エコシステム内の他のツールやサービスとシームレスに統合されます。 統合では、データ インジェストと処理からモデルのデプロイと視覚化まで、合理化されたワークフローがサポートされます。
モデルのデプロイと管理: AI サービスと ML サービスは、運用環境で機械学習モデルをデプロイおよび管理するための堅牢なツールを提供します。 バージョン管理、監視、自動再トレーニングなどの機能は、モデルが長期にわたって正確で効果的な状態が保たれるようにするのに役立ちます。 このアプローチにより、ML ソリューションのメンテナンスが簡略化されます。
リアルタイム処理: AI サービスと ML サービスでは、リアルタイムのデータ処理と意思決定がサポートされます。 リアルタイム処理は、不正検出、動的価格設定、推奨システムなど、即時の分析情報とアクションを必要とするアプリケーションにとって不可欠です。
カスタマイズ性と柔軟性: AI サービスと ML サービスは、事前構築済みモデルと API から、カスタム モデルをゼロから構築するためのフレームワークまで、さまざまなカスタマイズ可能なオプションを提供します。 この柔軟性により、データ サイエンス チームは固有のビジネス ニーズやユース ケースに合わせてソリューションをカスタマイズできます。
最先端のアルゴリズムへのアクセス: AI サービスと ML サービスにより、データ科学者は、一流の研究者によって開発された最先端のアルゴリズムとテクノロジへのアクセスを得られます。 アクセスは、チームがプロジェクトで AI と ML の最新の進歩を確実に活用できるようにします。
コラボレーションと共有: AI プラットフォームと ML プラットフォームでは、複数のチーム メンバーが同じプロジェクトで共同作業を行い、コードを共有し、実験を再現できるコラボレーション開発環境がサポートされます。 コラボレーションはチームワークを強化し、モデル開発の一貫性を確保するのに役立ちます。
コスト効率: クラウド上の AI サービスと ML サービスは、オンプレミス ソリューションの構築と保守よりもコスト効率が高くなります。 クラウド プロバイダーには、従量課金制オプションを含む柔軟な価格モデルがあるため、コストを削減し、リソースの使用量を最適化できます。
セキュリティとコンプライアンスの強化: AI サービスと ML サービスは、データ暗号化、セキュリティで保護されたアクセス制御、業界標準と規制への準拠など、堅牢なセキュリティ機能を備えています。 これらの機能は、データとモデルを保護し、法的要件と規制要件を満たすのに役立ちます。
事前構築済みのモデルと API: 多くの AI サービスと ML サービスには、自然言語処理、画像認識、異常検出などの一般的なタスク用に事前構築されたモデルと API が用意されています。 事前構築済みのソリューションを使用すると、開発とデプロイが加速され、チームは AI 機能をアプリケーションに迅速に統合できるようになります。
実験とプロトタイプ作成: AI プラットフォームと ML プラットフォームでは、迅速な実験とプロトタイプ作成のための環境が利用できます。 データ科学者は、さまざまなアルゴリズム、パラメーター、データセットを迅速にテストして、最適なソリューションを見つけることができます。 実験とプロトタイプ作成では、モデル開発に対する反復的なアプローチがサポートされます。
AI サービスと ML サービスに推奨される Azure リソース
Machine Learning は、データ サイエンス アプリケーションと TDSP に推奨される主要なリソースです。 また、Azure には、特定のアプリケーションにすぐに使用できる AI モデルを備えた AI サービスが用意されています。
- Machine Learning: セットアップ、モデル トレーニング、デプロイなどを取り上げた、Machine Learning のメイン ドキュメント ページ。
- Azure AI サービス: ビジョン、音声、言語、意思決定タスク用に事前構築済みの AI モデルを提供する AI サービスに関する情報。
要約すると、AI サービスと ML サービスは、機械学習モデルの開発、トレーニング、デプロイを効率化する強力なツールとフレームワークを提供するため、TDSP にとって非常に重要です。 これらのサービスにより、アルゴリズムの選択やハイパーパラメーターのチューニングなどの複雑なタスクが自動化され、モデル開発プロセスが大幅に高速化されます。 これらのサービスは、データ科学者が大規模なデータセットや計算負荷の高いタスクを効率的に処理するのに役立つスケーラブルなインフラストラクチャも提供します。 AI ツールと ML ツールは、他の Azure サービスとシームレスに統合され、データ インジェスト、前処理、モデル デプロイを強化します。 統合は、円滑なエンド ツー エンドのワークフローの確保に役立ちます。 また、これらのサービスは、コラボレーションと再現性を促進します。 Teams は、高度なセキュリティとコンプライアンスを維持しながら、分析情報を共有し、結果とモデルを効果的に試すことができます。
責任ある AI
AI ソリューションまたは ML ソリューションを使用して、Microsoft は AI ソリューションと ML ソリューション内で責任ある AI ツールを促進します。 これらのツールでは、Microsoft の責任ある AI の基準がサポートされます。 それでもワークロードで、AI 関連の損害に個別に対処する必要があります。
ピアレビューされた引用文献
TDSP は、Microsoft の取り組み全体でチームが使用する確立された方法論です。 TDSP は、ピアレビューされた文献で文書化および研究されています。 引用により、TDSP の機能とアプリケーションを調査する機会が生まれます。 引用の詳細と一覧については、「 TDSP ライフサイクル」を参照してください。