Azure Front Door
Azure API Management
Azure Kubernetes Service (AKS)
Azure Application Gateway
Dynamics 365
クラウド ソリューションの成功は、そのソリューションの信頼性にかかっています。 信頼性は “特定の期間に特定の環境条件でシステムが正常に機能する確率” と広く定義されます。 サイト リライアビリティ エンジニアリング (SRE) は、スケーラブルで信頼性の高いソフトウェア システムを作成するための、原則および手法の集まりです。 信頼性を高めるために、デジタル サービスの設計で SRE を利用することが増えています。
SRE 戦略の詳しい情報は「AZ-400:サイト リライアビリティ エンジニアリング (SRE) 戦略の構築」をご覧ください。
考えられるユース ケース
この記事の内容は、次のものが対象です。
- API ベースのクラウド サービス。
- 一般公開する Web アプリケーション。
- IoT ベースまたはイベント ベースのワークロード。
アーキテクチャ

このアーキテクチャの PowerPoint ファイルをダウンロードする。
ここでは、スケーラブルな API プラットフォームのアーキテクチャを説明します。 このソリューションは、Dynamics 365 や Microsoft 365 などのサービスとしてのソフトウェア (SaaS) ソリューションなど、さまざまなデータベースとストレージ サービスを使用する複数のマイクロサービスで構成されます。
この記事では、図に示すブロックを示すために、高レベルのマーケットプレースと e コマースのユース ケースを処理するソリューションについて説明します。 ユースケースは次のとおりです。
- 製品の閲覧。
- 登録とログイン。
- ニュース記事などのコンテンツの閲覧。
- 注文とサブスクリプションの管理。
Web アプリ、モバイル アプリ、さらにはサービス アプリケーションなどのクライアント アプリケーションでは、共通のアクセス パス https://api.contoso.com を使って、API プラットフォーム サービスを使用します。
コンポーネント
- Azure Front Door では、ソリューションに対するすべての要求に使用できる、保護された共通のエントリー ポイントを提供します。 詳しくは「ルーティング アーキテクチャの概要」をご覧ください。
- Azure API Management では、すべての公開 API 上にガバナンス層を追加します。 Azure API Management ポリシーを使って、制約付きアクセス、キャッシュ、データ変換などの機能を API 層に追加します。 API Management では、Standard および Premium サービス レベルで自動スケーリングをサポートしています。
- Azure Kubernetes Service (AKS) はオープンソースの Kubernetes クラスターの Azure での実装です。 Azure で Kubernetes サービスをホストして、正常性の監視や維持などの重要なタスクを処理します。 Azure は Kubernetes API サーバーを管理するため、エージェント ノードの管理と保守のみを行います。 このアーキテクチャでは、すべてのマイクロサービスを AKS にデプロイします。
- Azure Application Gateway は、アプリケーション配信コントローラー サービスです。 これは、第 7 層のアプリケーション層で機能し、さまざまな負荷分散機能を備えています。 Application Gateway Ingress Controller (AGIC) は、Azure Kubernetes Service (AKS) で、Azure のネイティブの Application Gateway L7 ロードバランサーを使って、クラウド ソフトウェアをインターネットに公開できるようにする、Kubernetes アプリケーションです。 自動スケーリングとゾーン冗長性は v2 SKU でサポートしています。
- Azure Storage、Azure Data Lake Storage、Azure Cosmos DB、Azure SQL では、構造化コンテンツと非構造化コンテンツの両方を保存できます。 Azure Cosmos DB のコンテナーとデータベースは、自動スケーリング スループットで作成できます。
- Microsoft Dynamics 365 は、Microsoft のサービスとしてのソフトウェア (SaaS) オファリングであり、カスタマー サービス、販売、マーケティング、財務に複数のビジネス アプリケーションを提供します。 このアーキテクチャでは、Dynamics 365 は主に製品カタログの管理とカスタマー サービス管理に使用されます。 Dynamics 365 アプリケーションでは、スケール ユニットによ回復性を確保しています。
- Microsoft 365 (旧称 Office 365) は、Microsoft 365 の Microsoft 365 SharePoint を基礎に開発されたサービスであり、ここでは業務用コンテンツ管理システムとして使用します。 メディア資産やドキュメントなどのコンテンツを作成、管理、公開するのに使用します。
代替
このソリューションでは、スケーラビリティの高いマイクロサービスベースのアーキテクチャを使用するため、コンピューティング プレーンをこれらのもので代替することを検討してください。
- Azure Functions: サーバーレス API サービス使用
- Azure Spring Apps: Java ベースのマイクロサービスに
適切な水準の信頼性
各ソリューションに求められる信頼性の水準は、ビジネスの条件により異なります。 1 日に 14 時間営業し、その時間内にシステム使用量のピークがある小売店と、24 時間営業のオンライン ビジネスとでは、要件が異なります。 SRE の手法は、必要な信頼性のレベルに合わせてカスタマイズできます。
信頼性は、サービスの信頼性の目標レベルを定めているサービスレベル評価基準 (サービスレベル評価基準 (SLO)) によって設定し、計測します。 目標レベルを達成することで、コンシューマーの満足を確実にできます。 SLO はビジネスの要件により変化します。 ですが、サービスの持ち主は、SLO を基準にして継続的に信頼性を計測することで、問題を見つけて修正する必要があります。 SLO は通常、一定期間における達成率 (%) で設定します。
もう 1 つの重要な用語はサービスレベル指標 (サービスレベル指標 (SLI)) です。SLI は SLO の計算に使用するメトリックです。 SLI は、顧客がサービスを使用するときに取得するデータから得られる分析情報に基づく指標です。 SLI は常に顧客視点で計測します。
SLO と SLI は密接に関連しており、通常、反復的に調整します。 SLO は主要事業目標に基づき、SLI はサービス実施中に計測できる値に基づきます。
次の図は、監視対象メトリック、SLI、SLO の関係を示しています。
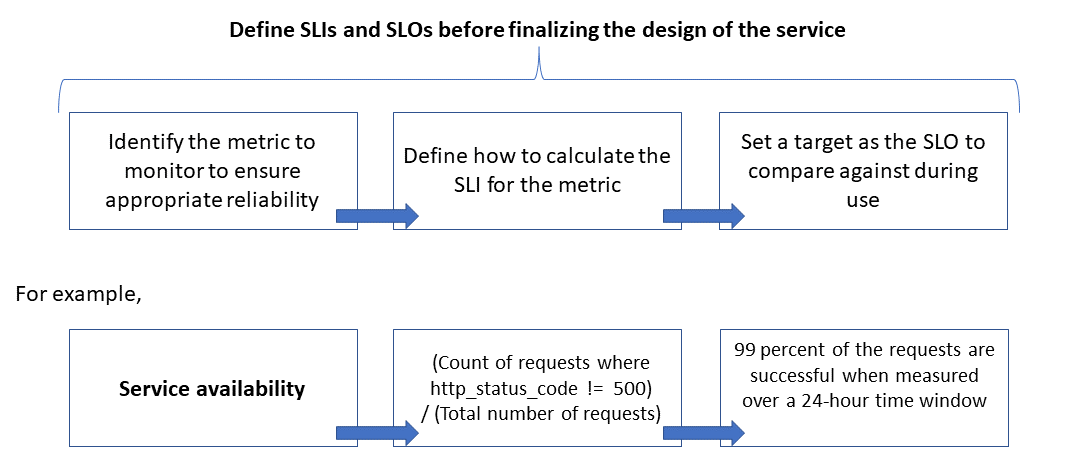
このプロセスの詳細については、「 SLI メトリックを定義して SLO を計算する」を参照してください。
スケールとパフォーマンスをモデル化して予測する
ソフトウェア システムでは、パフォーマンスとは通常、システムでアクションを実行するときの、特定期間における全体的な応答性を指します。スケーラビリティは、パフォーマンスを損なわずにユーザー負荷の増加を処理するシステムの能力を指します。
負荷の増大に対応するために、処理を実行するリソースを動的に動員できる場合、そのシステムはスケーラブルであると言います。 クラウド アプリケーションはスケールできるよう設計する必要があります。また、トラフィックの量は予測が難しい場合があります。 特に複数のテナントに対する要求をサービスで処理している場合は、季節的なトラフィックの急増によって、大きなスケールが必要になることがあります。
負荷に対処できるよう自動的にクラウド リソースをスケールアップ/スケールダウンするようにアプリケーションを設計することをお勧めします。 システムでは基本的に、需要の増加量に合わせてリソースのプロビジョニングまたは割り当てを段階的に行うことによって、ワークロードの増加に対応します。 スケーラビリティは、コンピューティング インスタンスだけでなく、データ保存やメッセージング インフラストラクチャなどの他の要素とも関係しています。
この記事では、ワークロード シナリオのスケールとパフォーマンスをモデル化し、その結果に基づいてモニター、SLI、SLO を設定することにより、クラウド アプリケーションに必要な信頼性を確保する方法を説明します。
考慮事項
信頼性の高いスケーラブルなアプリケーションを構築する際のガイダンスとして、Azure Well Architected Framework の柱である信頼性とパフォーマンス効率の説明を参考にしてください。
この記事では、スケーラビリティとパフォーマンスのモデル化により、ソリューション アーキテクチャと設計を細かく調整する方法を説明します。 これらの手法によって、最高のユーザー エクスペリエンスを実現するために、トランザクションのフローのどこを変更するべきかを把握します。 機能以外のものに関するソリューションの要件に基づいて、技術的な事項を決定してください。 手順です。
- スケーラビリティの要件を把握します。
- 負荷をモデル化して予測します。
- ユーザー シナリオの SLI と SLO を設定します。
注意
Azure Monitor の一部である Azure Application Insights は、アプリケーションと簡単に統合してテレメトリを送信し、アプリケーションごとにメトリクスを分析できる、優れたアプリケーション パフォーマンス管理 (APM) ツールです。 すぐに使えるダッシュボードと、データを分析してビジネス ニーズを調べることができるメトリクス エクスプローラも備えています。
スケーラビリティの要件を把握する
ピーク時の負荷として、これらのメトリクスを想定します。
- API プラットフォームを使用するコンシューマーの人数: 150 万人
- 1 時間あたりのアクティブ コンシューマー数 (150 万人の 30%): 45 万人
- 各アクティビティによる負荷の割合:
- 製品の閲覧: 75%
- 登録 (プロファイルの作成を含む) とログイン: 10%
- 注文とサブスクリプションの管理: 10%
- コンテンツの表示: 5%
この負荷から、プラットフォームでホストしている API の、通常のピーク時負荷におけるスケール要件が、次のように決まります。
- 製品のマイクロサービス: 1 秒あたりの要求数 (RPS) が約 500 RPS
- プロファイルのマイクロサービス: 約 100 RPS
- 注文と支払いのマイクロサービス: 約 100 RPS
- コンテンツのマイクロサービス: 約 50 RPS
これらのスケール要件では、ピーク時負荷の季節的変動およびランダムの変動、販売促進イベントなどの特別なイベントにおけるピーク時負荷の変動を考慮していません。 一部のユーザー アクティビティでは、ピーク時負荷が通常の 10 倍まで変動し、それに伴ってスケール要件も変動します。 マイクロサービスの設計を決めるときは、これらの制約と見込みを考慮してください。
SLI メトリクスを設定して SLO を計算する
SLI メトリクスは、サービスに対する満足度の目安となるもので、全イベントの数に対する良好なイベントの数の比で表します。
API サービスにおいて、イベントとは、プロセス実行時にテレメトリまたは処理済みデータの形で収集する、アプリケーションごとのメトリクスを指します。 例として、次の SLI メトリクスがあります。
| メトリック | 説明 |
|---|---|
| 可用性 | API で要求が処理されたかどうか |
| 遅延 | API で要求を処理して応答するのにかかる時間 |
| スループット | API で処理した要求の数 |
| 成功率 | API で処理に成功した要求の数 |
| エラー率 | API で処理した要求に発生したエラーの数 |
| 鮮度 | API による読み取り操作でユーザーが最新のデータを受け取った回数。データ ストアの書き込み待機時間を上書きした場合も同様にカウントする。 |
注意
ソリューションに追加するべき重要な SLI を必ず把握してください。
SLA の例をここに挙げます。
- 1,000 ミリ秒未満で処理を完了した要求の数 / 要求数
- 3 秒以内に出力された検索結果のうち、カタログで公開している製品を表すものの数 / 検索数
SLI を設定したら、それを計測するために収集するイベントとテレメトリを決めます。 たとえば、可用性を計測するには、API サービスで要求を正しく処理できたかどうかを示すイベントを収集します。 HTTP ベースのサービスでは、HTTP 状態コードで成否が示されます。 API の設計と実装は、適切なコードを出力するように行う必要があります。 一般に、SLI メトリクスは API 実装のための重要なデータとなります。
クラウドベースのシステムでは、リソースの診断と監視をサポートする機能を使って、一部のメトリクスを取得できます。 Azure Monitor は、クラウド サービスのテレメトリを収集、分析し、その結果を運用に反映させるための、総合的なソリューションです。 SLI によっては、メトリクスを算出するために、通常より多くの監視データを収集する必要があります。
パーセンタイルを使用する
パーセンタイルを使用して計算する SLI もあります。 この方法だと、平均値や中央値などの他の指標では偏りが出てしまう外れ値がある場合も、比較的良好な結果が得られます。
たとえば、API 要求の待機時間をメトリックに使用していて、最適なパフォーマンスの上限は 3 秒だと考えてください。 1 時間に受け取った API 要求に対する反応時間を長さ順に並べたところ、ほとんどの要求には、3 秒の制限時間内に応答できていたことが分かったとします。 これは、システムが予期したとおりに動作していることを表します。
パーセンタイルは、不定期に発生する問題に起因する外れ値を排除するために使用します。 たとえば、90 または 95 パーセンタイル値が、サービスの適切な応答時間の範囲にある場合、SLO を達成できていると言えます。
適切な測定期間を選択する
SLO では、指標の測定期間がとても重要です。 ユーザー エクスペリエンスの向上に役立つ結果を得るためには、操作が行われない時間帯ではなく、アクティビティが存在する時間帯にデータを収集する必要があります。 SLI メトリックの監視方法、計算方法に応じて、この時間帯は、5 分から 24 時間の長さに設定できます。
パフォーマンス ガバナンス プロセスを整備する
API のパフォーマンスは、開発の一番最初の段階から、非推奨化または廃止に至るまで、管理する必要があります。 ビジネスに影響を与える大規模な停止を引き起こす前に、パフォーマンスの問題が早期に検出され、修正されるように、堅牢なガバナンス プロセスを実施する必要があります。
パフォーマンス ガバナンスの要素をここに挙げます。
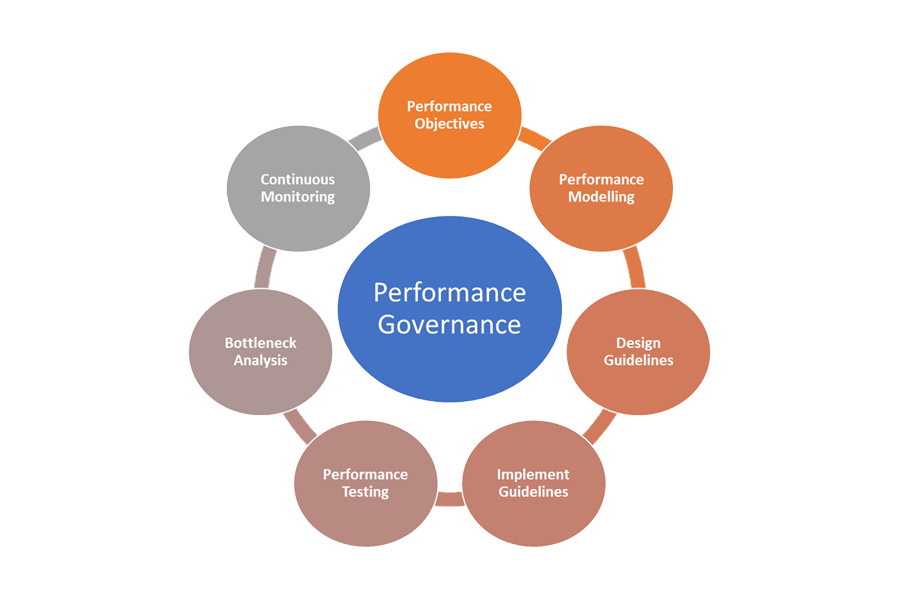
- パフォーマンス目標: ビジネス シナリオのパフォーマンス SLO を設定します。
- パフォーマンスのモデル化: 業務上重要なワークフローとトランザクションを把握し、モデル化を行ってパフォーマンスへの影響を理解します。 正確な予測を行うには、この情報をより細かく収集します。
- 設計ガイドライン: パフォーマンス設計ガイドラインを用意し、これに基づいてビジネスのワークフローに必要な変更を推奨します。 チームが、このガイドラインを理解している必要があります。
- 実行ガイドライン: メトリクスを収集するためのインストルメンテーションなど、ソリューションのコンポーネントに対して、パフォーマンス設計ガイドラインの内容を実行します。 パフォーマンス設計の見直しを行います。 アーキテクチャー バックログ項目を利用し、各チームについて、これらすべてを追跡することが重要です。
- パフォーマンスのテスト: 負荷プロファイルの分布に基づいて負荷テストとストレス テストを行い、プラットフォームの正常性に関連するメトリクスを収集します。 対象とする負荷を限定してこれらのテストを実施し、ソリューションのインフラストラクチャの要件に関するベンチマーキングを行うこともできます。
- ボトルネック分析: コードの検査と見直しを行って、さまざまなコンポーネントのパフォーマンスのボトルネックを特定、分析、除去します。 トラフィック ピーク時の負荷に対応するために、水平/垂直スケーリングに関して強化が必要な点を調べます。
- 継続的監視: DevOps プロセスの一環として、継続的監視と警告を行うインフラストラクチャを構築します。 応答時間がベンチマークと比較して大幅に遅くなったときに、関係するチームに通知が届くようにします。
- パフォーマンス ガバナンス: パフォーマンス SLO を達成するため、適切なプロセスとチームで構成したパフォーマンス ガバナンス体制を構築します。 毎リリース後にコンプライアンスの状態を追跡し、ビルドのアップグレードに起因するシステムの問題を防止します。 定期的に見直しを行って負荷の増大がないかどうか調べ、それが見つかった場合は、ソリューションのどのアップグレードが原因かを特定します。
段階的詳細化プロセスの一環として、ソリューションの全開発工程でこのステップを繰り返します。
バックログで、パフォーマンスの目標、予測に関する情報を追跡する
パフォーマンス目標に関する情報を追跡して目標達成に役立てます。 ユーザーの振る舞いの詳細な情報を収集します。これは、開発チームがパフォーマンス ガバナンス アクティビティに優先的に取り組むのに役立ちます。
対象ソリューションの SLO を設定する
API プラットフォーム ソリューションの SLO のサンプルをここに挙げます。
- 1 日に受け取る READ 要求の 95% 以上に対して 1 秒以内に応答する。
- 1 日に受け取る CREATE および UPDATE 要求の 95% 以上に対して 3 秒以内に応答する。
- 1 日に受け取る要求の 99% 以上に対して、5 秒以内にエラーを出さずに応答する。
- 1 日に受け取る要求の 99.9% 以上に対して、5 分以内にエラーを出さずに応答する。
- トラフィックのピークに当たる 1 時間に受け取る要求のうち、エラーにより終了する要求の割合を 1% 未満にする。
SLO は、アプリケーションの特定の要求に合わせて設定できます。 ただし、信頼性を確保するのに十分な具体性のある目標を設定する必要があります。
ログのデータに基づいて初期 SLO を測定する
API サービスを使用すれば、監視ログを自動で作成できます。 1 週間のデータに次の結果が表示されるとします。
- 要求: 123,456 件
- 成功した要求: 123,204 件
- 待機時間の 90 パーセンタイル値: 497 ミリ秒
- 待機時間の 95 パーセンタイル値: 870 ミリ秒
- 待機時間の 99 パーセンタイル値: 1,024 ミリ秒
このデータから、次の初期 SLI が得られます。
- 可用性 = 123,204 / 123,456 = 99.8%
- 待機時間 = 要求の 90% 以上を 500 ミリ秒以内に処理しました
- 待機時間 = 要求の約 98% を 1,000 ミリ秒以内に処理しました
1 週間に受け取る要求の 90% 以上を、99% 以上の成功率で、500 ミリ秒以内に処理することを、計画段階で、待機時間の SLO に設定していると考えてください。 ログのデータを見れば、この SLO を達成できたかどうかは簡単に分かります。 数週間こうした分析を行えば、SLO の達成状況に関する傾向が見えてきます。
技術的リスク軽減のガイダンス
次に掲載する推奨事項のチェックリストを使用して、スケーラビリティとパフォーマンスのリスクを軽減します。
- スケールとパフォーマンスを考慮して設計する。
- 季節的変動とトラフィックのピークを含めて、すべてのユーザー シナリオとワークロードに関するスケール要件を把握する。
- パフォーマンスをモデル化して、システムの制約とボトルネックを把握する
- 技術的負債を管理する。
- パフォーマンスのメトリクスを広範に追跡する。
- 一定範囲のユーザー負荷 (たとえば 50 - 100 RPS) を受ける開発ステージング環境で、スクリプトにより K6.io、Karate、JMeter などのツールを使用することを検討する。 そうすれば、設計上、実装上の問題を検出するための情報のログを取ることができます。
- ビルドの失敗を検出するため、継続的配置 (CD) プロセスに自動テスト スクリプトを導入する。
- 常に本番を想定する。
- 正常性の統計情報に基づいて自動スケーリングのしきい値を調整する。
- できる限り、垂直スケーリングではなく水平スケーリングを行う。
- 季節的変動を処理するための予防的なスケーリングを行う。
- できる限りリングベースでデプロイする。
- エラー バジェットを使用して実験を行う。
価格
信頼性、パフォーマンス、コストの最適化は密接に関連しています。 Azure サービスでは自動スケーリングによってユーザー負荷の変動に対応できるため、アーキテクチャに Azure サービスを使用すればコスト削減に役立ちます。
AKS では、最初は標準サイズの VM をノード プールに使用します。 その後、開発または運用環境でそれを使用しながらリソース要件を把握し、それに合わせて調整します。
コストの最適化は Microsoft Azure Well-Architected Framework の重要な役割の 1 つです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。 Azure 製品の構成とコストの見積もりには料金計算ツールを使用してください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Subhajit Chatterjee |プリンシパル ソフトウェア エンジニア
次のステップ
- Azure ドキュメント
- Microsoft Azure Well-Architected フレームワーク
- マイクロサービス アーキテクチャ スタイル
- スケールアウトのための設計
- アプリケーションの Azure コンピューティング サービスを選択する
- Azure Kubernetes Service 上のマイクロサービス アーキテクチャ
- Azure Front Door とは
- API Management について
- Application Gateway イングレス コントローラーとは
- Azure Kubernetes サービス
- 自動スケーリングとゾーン冗長 Application Gateway v2
- Azure Kubernetes Service (AKS) でのアプリケーションの需要を満たすようにクラスターを自動的にスケーリング
- 自動スケーリングのスループットを使用して Azure Cosmos DB コンテナーとデータベースを作成する
- Microsoft Dynamics 365 のドキュメント
- Microsoft 365 ドキュメント
- サイト信頼性エンジニアリングのドキュメント
- AZ-400:サイト リライアビリティ エンジニアリング (SRE) 戦略の構築
- ゾーン冗長性を備えたベースライン Web アプリケーション