Azure
リリース サイクルの短縮は、マイクロサービス アーキテクチャの主な利点の 1 つです。 ただし、適切な CI/CD プロセスがないと、マイクロサービスが約束する機敏性は実現しません。 この記事では、課題について説明し、問題に対するいくつかのアプローチを推奨します。
CI/CD とは
CI/CD について話すときは、継続的インテグレーション、継続的デリバリー、継続的デプロイなど、いくつかの関連プロセスについて実際に説明しています。
継続的インテグレーション コードの変更は、多くの場合、メイン ブランチにマージされます。 ビルドとテストのプロセスを自動化することで、メイン ブランチのコードが常に運用環境の品質であることを確認します。
継続的デリバリー。 CI プロセスを渡すコード変更は、運用環境に似た環境に自動的に発行されます。 ライブ運用環境へのデプロイには手動による承認が必要になる場合がありますが、それ以外の場合は自動化されます。 目標は、コードが常に運用環境にデプロイ 準備ができている必要があるということです。
継続的デプロイメント。 前の 2 つの手順に合格したコード変更は、運用環境のに
自動的にデプロイされます。
マイクロサービス アーキテクチャの堅牢な CI/CD プロセスの目標を次に示します。
各チームは、他のチームに影響を与えたり中断したりすることなく、独自に所有するサービスを構築してデプロイできます。
サービスの新しいバージョンが運用環境にデプロイされる前に、検証のために開発/テスト/QA 環境にデプロイされます。 品質ゲートは各段階で適用されます。
サービスの新しいバージョンは、以前のバージョンと並行してデプロイできます。
十分なアクセス制御ポリシーが用意されています。
コンテナー化されたワークロードの場合は、運用環境にデプロイされているコンテナー イメージを信頼できます。
堅牢な CI/CD パイプラインが重要な理由
従来のモノリシック アプリケーションでは、出力がアプリケーション実行可能ファイルである 1 つのビルド パイプラインがあります。 開発作業はすべて、このパイプラインにフィードされます。 優先度の高いバグが見つかった場合は、修正プログラムを統合、テスト、公開する必要があり、新機能のリリースが遅れる可能性があります。 これらの問題を軽減するには、モジュールを十分に考慮し、機能ブランチを使用してコード変更の影響を最小限に抑えます。 しかし、アプリケーションがより複雑になり、より多くの機能が追加されると、モノリスのリリース プロセスはより脆弱になり、中断する可能性が高くなります。
マイクロサービスの理念に従って、すべてのチームが列に並ぶ必要がある長いリリース トレーニングは決してありません。 サービス "A" を構築するチームは、サービス "B" の変更がマージ、テスト、デプロイされるのを待たずに、選択した時点で更新プログラムをリリースできます。
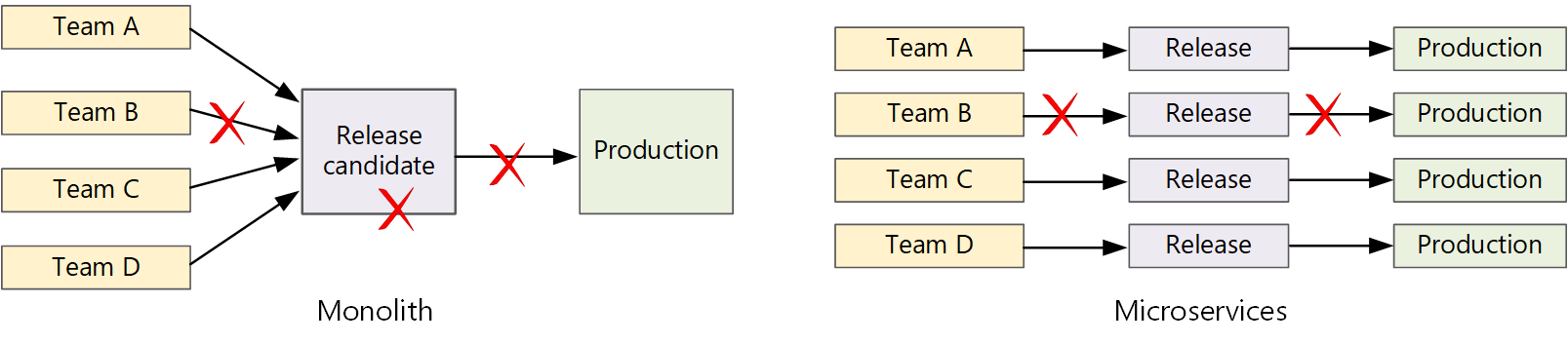 の図
の図
高いリリース速度を実現するには、リスクを最小限に抑えるために、リリース パイプラインを自動化し、信頼性を高める必要があります。 運用環境に 1 日に 1 回以上リリースする場合、回帰やサービスの中断はまれである必要があります。 同時に、不適切な更新プログラムがデプロイされる場合は、以前のバージョンのサービスにすばやくロールバックまたはロールフォワードするための信頼性の高い方法が必要です。
課題
多くの小さな独立したコード ベース。 各チームは、独自のビルド パイプラインを使用して独自のサービスを構築する責任があります。 組織によっては、チームが個別のコード リポジトリを使用する場合があります。 個別のリポジトリを使用すると、システムの構築方法に関する知識がチーム間で分散され、組織内の誰もアプリケーション全体をデプロイする方法を知らない状況につながる可能性があります。 たとえば、新しいクラスターに迅速にデプロイする必要がある場合、ディザスター リカバリー シナリオはどうなりますか。
軽減策: サービスを構築してデプロイするための統合された自動化されたパイプラインを用意し、この知識が各チーム内で "非表示" にされないようにします。
複数の言語とフレームワーク。 各チームが独自のテクノロジを組み合わせて使用する場合、組織全体で動作する 1 つのビルド プロセスを作成することは困難な場合があります。 ビルド プロセスは、すべてのチームが言語またはフレームワークの選択に合わせて調整できる十分な柔軟性を備えている必要があります。
軽減策の: 各サービスのビルド プロセスをコンテナー化します。 そうすることで、ビルド システムはコンテナーを実行できるだけで済みます。
統合とロード テストの。 チームが自分のペースで更新プログラムをリリースする場合、特にサービスが他のサービスに依存している場合に、堅牢なエンドツーエンドテストを設計することは困難な場合があります。 さらに、完全な運用クラスターを実行するとコストがかかる可能性があるため、テストのためだけに、すべてのチームが運用スケールで独自の完全なクラスターを実行する可能性は低くなります。
リリース管理。 すべてのチームは、運用環境に更新プログラムをデプロイできる必要があります。 これは、すべてのチーム メンバーにアクセス許可があることを意味するわけではありません。 ただし、リリース マネージャーの役割を一元化すると、デプロイの速度が低下する可能性があります。
軽減策の: CI/CD プロセスが自動化され、信頼性が高いほど、中央機関の必要性は低くなります。 しかし、主要な機能更新プログラムをリリースするためのポリシーと、軽微なバグ修正が異なる場合があります。 分散型であることは、ガバナンスがゼロであることを意味するわけではありません。
サービスの更新プログラム。 サービスを新しいバージョンに更新する場合、サービスに依存する他のサービスを中断しないでください。
軽減策: ブルーグリーンやカナリア リリースなどのデプロイ手法を使用して、破壊的な変更を避けます。 API の破壊的変更については、新しいバージョンを以前のバージョンと並行してデプロイします。 そうすることで、前の API を使用するサービスを更新し、新しい API についてテストできます。 詳細については、この記事の「 サービスの更新 」セクションを参照してください。
Monorepo 対 マルチリポ
CI/CD ワークフローを作成する前に、コード ベースの構造と管理方法を把握しておく必要があります。
- チームは個別のリポジトリまたは monorepo (単一リポジトリ) で作業しますか?
- 分岐戦略は何ですか?
- 運用環境にコードをデプロイできる人 リリース マネージャーロールはありますか?
モノレポアプローチは好意を得ていますが、両方に長所と短所があります。
| モノレポ | 複数のリポジトリ | |
|---|---|---|
| の利点 | コード共有 コードとツールの標準化が容易 コードのリファクタリングが容易 検出可能性 - コードの単一ビュー |
チームごとの明確な所有権 マージの競合が少なくなる可能性がある マイクロサービスの分離を強制するのに役立ちます |
| 課題 | 共有コードに対する変更は、複数のマイクロサービスに影響する可能性があります マージ競合の可能性が高い ツールは大規模なコード ベースにスケーリングする必要がある アクセス制御 より複雑なデプロイ プロセス |
コードを共有するのが難しい コーディング標準の適用が困難 依存関係の管理 拡散コード ベース、検出可能性が低い 共有インフラストラクチャの不足 |
サービスの更新
既に運用環境にあるサービスを更新するためのさまざまな戦略があります。 ここでは、ローリング アップデート、ブルーグリーン デプロイ、カナリア リリースの 3 つの一般的なオプションについて説明します。
ローリングアップデート
ローリング アップデートでは、サービスの新しいインスタンスをデプロイすると、新しいインスタンスがすぐに要求の受信を開始します。 新しいインスタンスが起動すると、前のインスタンスが削除されます。
例。 Kubernetes では、デプロイのポッド スペックを更新する場合、ローリング 更新が既定の動作です。 デプロイ コントローラーは、更新されたポッドの新しい ReplicaSet を作成します。 次に、必要なレプリカ数を維持するために、古いものをスケールダウンしながら新しい ReplicaSet をスケールアップします。 新しいポッドの準備ができるまで、古いポッドは削除されません。 Kubernetes は更新プログラムの履歴を保持するため、必要に応じて更新プログラムをロールバックできます。
例。 Azure Container Apps では リビジョン を使用してローリングアップデートを管理します。 新しいリビジョンをデプロイすると、Container Apps はトラフィック分割ルールを使用して、古いリビジョンから新しいリビジョンにトラフィックを徐々にシフトできます。 新しいリビジョンで問題が発生した場合は、トラフィックを以前のリビジョンにリダイレクトすることでロールバックできます。 複数のアクティブなリビジョンを同時に構成し、各リビジョンが受信するトラフィックの割合を制御できます。
ローリング アップデートの課題の 1 つは、更新プロセス中に、古いバージョンと新しいバージョンが混在して実行され、トラフィックを受信していることです。 この期間中、要求は 2 つのバージョンのいずれかにルーティングされる可能性があります。
API の破壊的変更については、前のバージョンのすべてのクライアントが更新されるまで、両方のバージョンを並行してサポートすることをお勧めします。 API のバージョニングを参照してください。
ブルーグリーンデプロイメントとは、環境Aと環境Bを交互に使用して新しいソフトウェアをリリースする手法です。
青緑色のデプロイでは、以前のバージョンと共に新しいバージョンをデプロイします。 新しいバージョンを検証したら、すべてのトラフィックを以前のバージョンから新しいバージョンに一度に切り替えます。 スイッチの後、アプリケーションで問題が発生した場合は監視します。 問題が発生した場合は、古いバージョンに戻すことができます。 問題がないと仮定すると、古いバージョンを削除できます。
従来のモノリシックまたは N 層アプリケーションでは、ブルーグリーンデプロイは通常、2 つの同じ環境をプロビジョニングすることを意味していました。 新しいバージョンをステージング環境にデプロイし、VIP アドレスをスワップするなどして、クライアント トラフィックをステージング環境にリダイレクトします。 マイクロサービス アーキテクチャでは、更新はマイクロサービス レベルで行われるので、通常は同じ環境に更新プログラムをデプロイし、サービス検出メカニズムを使用してスワップします。
例。 Kubernetes では、ブルーグリーンデプロイを行うために別のクラスターをプロビジョニングする必要はありません。 代わりに、セレクターを利用できます。 新しいポッド スペックと別のラベル セットを使用して、新しい Deployment リソースを作成します。 以前のデプロイを削除したり、それを指すサービスを変更したりせずに、このデプロイを作成します。 新しいポッドが実行されたら、新しいデプロイに合わせてサービスのセレクターを更新できます。
ブルーグリーンデプロイの欠点の 1 つは、更新中に、サービスのポッドの 2 倍の数 (現在と次のポッド) を実行することです。 ポッドに大量の CPU またはメモリ リソースが必要な場合は、リソースの消費を処理するためにクラスターを一時的にスケールアウトすることが必要になる場合があります。
カナリアリリース
カナリア リリースでは、最初に更新されたバージョンをクライアントの小さなサブセットに展開します。 その後、すべてのクライアントにロールアウトする前に、新しいサービスの動作を監視します。 このアプローチを使用すると、制御された方法で徐々にロールアウトし、実際のデータを監視し、問題がすべての顧客に影響を与える前に特定することができます。
カナリア リリースは、異なるバージョンのサービスに要求を動的にルーティングする必要があるため、ブルーグリーンまたはローリング 更新プログラムよりも管理が複雑です。
例。 Kubernetes では、2 つのレプリカ セット (バージョンごとに 1 つ) にまたがる サービス を構成し、レプリカ数を手動で調整できます。 ただし、Kubernetes がポッド間で負荷分散を行う方法のため、この手法は粗めです。 たとえば、合計 10 個のレプリカがある場合は、10% 増分でのみトラフィックをシフトできます。 サービス メッシュを使用している場合は、サービス メッシュ ルーティング規則を使用して、より高度なカナリア リリース戦略を実装できます。
次の手順
- ラーニング パス: 継続的インテグレーション を定義して実装する
- トレーニング: 継続的デリバリーの導入
- マイクロサービス アーキテクチャ
- マイクロサービス アプローチを使用してアプリケーションを構築する理由
関連リソース
- KubernetesでのマイクロサービスのCI/CD
- マイクロサービス アーキテクチャ を設計する
- ドメイン分析を使用してマイクロサービス をモデル化する