この記事では、Azure Kubernetes Service (AKS) で実行されるマイクロサービス アプリケーションを監視するためのベスト プラクティスについて説明します。 具体的なトピックとして、テレメトリ収集、クラスターの状態の監視、メトリック、ログ記録、構造化ログ、分散トレースなどが含まれます。 後者を次の図に示します。

このアーキテクチャの Visio ファイルをダウンロードします。
テレメトリの収集
複雑なアプリケーションは、どこかの時点で何かがうまくいかなくなります。 マイクロサービス アプリケーションでは、数十から数百のサービス全体で何が起こっているのかを追跡する必要があります。 何が起きているのかを把握するには、アプリケーションからテレメトリを収集する必要があります。 テレメトリは "ログ"、"トーレス"、"メトリック" に分けることができます。
ログは、アプリケーションの実行中に発生するイベントに関するテキストベースの記録です。 これには、アプリケーション ログ (トレース ステートメント) や Web サーバー ログなどが含まれます。 ログは、主に科学捜査と根本原因の解析に役立ちます。
トレース ("操作" とも呼ばれる) は、マイクロサービス内およびマイクロサービス間の複数の呼び出し間で 1 つの要求のステップを接続します。 これは、システム コンポーネントの相互作用に関する構造化された監視を実現します。 トレースは、アプリケーションの UI 内など、要求プロセスの早い段階で開始できます。また、要求を処理するマイクロサービスのネットワーク全体を、ネットワーク サービスを介して伝達できます。
- スパンは、トレース内の作業単位です。 各スパンは 1 つのトレースに関連付けられ、他のスパンと入れ子にすることができます。 多くの場合、サービス間操作における個々の "要求" に対応しますが、サービス内の個々のコンポーネントの作業を定義することもできます。 また、スパンは、あるサービスから別のサービスへの送信呼び出しを追跡します。 (スパンは依存関係レコードと呼ばれる場合があります)。
メトリックは、解析できる数値です。 メトリックを使用すると、リアルタイムで (またはほぼリアルタイムで) システムを観察したり、パフォーマンスの傾向を時系列で解析したりすることができます。 システムを包括的に理解するには、次のような、物理インフラストラクチャからアプリケーションまでの、アーキテクチャのさまざまなレベルで、メトリックを収集する必要があります。
ノードレベル メトリック。CPU、メモリ、ネットワーク、ディスク、ファイル システムの使用状況などです。 システム メトリックは、クラスター内の各ノードのリソース割り当てを把握し、外れ値の問題解決を行うのに役立ちます。
コンテナー メトリック。 コンテナー化されたアプリケーションでは、VM レベルだけでなく、コンテナー レベルでメトリックを収集する必要があります。
アプリケーション メトリック。 これらのメトリックは、サービスの動作の把握に関連します。 たとえば、キューに追加された受信 HTTP 要求の数、要求の待機時間、メッセージキューの長さなどがあります。 アプリケーションでは、1 分あたりに処理されたビジネス トランザクションの数など、ドメインに固有のカスタム メトリックを使用することもできます。
依存サービス メトリック。 サービスからは、マネージド PaaS や SaaS サービスなど、外部サービスまたはエンドポイントが呼び出されることがあります。 サードパーティのサービスでは、メトリックが提供されない場合があります。 提供されない場合、待機時間とエラー率の統計を追跡するには、独自のアプリケーション メトリックに頼る必要があります。
クラスターの状態の監視
クラスターの正常性を監視するには、Azure Monitor を使います。 次のスクリーンショットでは、ユーザーがデプロイしたポッドに重大なエラーがあるクラスターが示されています。

ここから、さらにドリルダウンして問題を発見できます。 たとえば、ポッドの状態が ImagePullBackoff である場合、Kubernetes はレジストリからコンテナー イメージをプルできませんでした。 この問題は、レジストリからプルする際の、無効なコンテナー タグまたは認証エラーによって発生する可能性があります。
コンテナーがクラッシュした場合、コンテナー State は Waiting になり、Reason は CrashLoopBackOff になります。 ポッドがレプリカ セットの一部であり、再試行ポリシーが Always である一般的なシナリオでは、この問題はクラスターの状態においてエラーとしては表示されません。 ただし、この状態に対しては、クエリを実行したり、アラートを設定したりすることができます。 詳細については、Azure Monitor Container insights を使用した AKS クラスターのパフォーマンスの把握に関する記事を参照してください。
AKS リソースのブック ペインには、使用可能なコンテナー固有のブックが複数あります。 これらのブックを、簡単な概要、トラブルシューティング、管理、分析情報に使用できます。 次のスクリーンショットは、AKS ワークロードで既定で使用できるブックの一覧を示しています。

メトリック
AKS クラスターおよび他の依存 Azure サービスのメトリックを収集して表示するには、Azure Monitor を使うことをお勧めします。
クラスターとコンテナーのメトリックの場合は、Azure Monitor Container insights を有効にします。 この機能を有効にすると、Monitor により、Kubernetes Metrics API を介して、コントローラー、ノード、コンテナーから、メモリやプロセッサのメトリックが収集されます。 Container insights から使用できるメトリックの詳細については、Azure Monitor Container insights を使用した AKS クラスターのパフォーマンスの把握に関する記事を参照してください。
アプリケーションのメトリックを収集するには、Application Insights を使います。 Application Insights は、拡張可能なアプリケーション パフォーマンス管理 (APM) サービスです。 それを使うには、アプリケーションにインストルメンテーション パッケージをインストールします。 このパッケージは、アプリケーションを監視し、テレメトリ データを Application Insights に送信します。 また、テレメトリ データをホスト環境からプルすることもできます。 データはその後、Monitor に送信されます。 Application Insights には、相関関係と依存関係の追跡機能も組み込まれています。 (この記事の後半の「分散トレース」を参照してください)。
Application Insights では、1 秒あたりのイベント数で最大スループットが測定され、データ レートが制限を超えた場合はテレメトリが調整されます。 詳しくは、Application Insights の制限に関する記事をご覧ください。 クォータについて開発/テスト環境が運用環境のテレメトリと競合しないように、環境ごとに異なる Application Insights インスタンスを作成します。
1 回の操作で多数のテレメトリ イベントが生成されることがあります。そのため、アプリケーションで大量のトラフィックが発生すると、そのテレメトリのキャプチャが抑えられる可能性があります。 この問題を軽減するために、サンプリングを実行してテレメトリ トラフィックを減らすことができます。 そのトレードオフとして、メトリックの精度が低くなります。ただし、インストルメンテーションで事前集計がサポートされている場合を除きます。 その場合、トラブルシューティング用のトレース サンプルは少なくなりますが、メトリックの正確性は維持されます。 詳細については、「Application Insights におけるサンプリング」を参照してください。 メトリックを事前に集計することで、データ量を減らすこともできます。 つまり、平均や標準偏差などの統計値を計算し、未加工のテレメトリの代わりにそれらの値を送信できます。 このブログ投稿「大規模な Azure の監視と解析」では、Application Insights を大規模に使用するアプローチについて説明しています。
調整がトリガーされるほどにデータ レートが高く、サンプリングまたは集計が許容されない場合は、クラスターで実行されている Azure Data Explorer、Prometheus、InfluxDB などの時系列データベースにメトリックをエクスポートすることを検討してください。
Azure Data Explorer は、ログと利用統計情報のための拡張性に優れた Azure ネイティブのデータ探索サービスです。 複数のデータ形式のサポート、豊富なクエリ言語、Jupyter Notebook や Grafana のような一般的なツールでデータを使用するための接続を特徴としています。 Azure Data Explorer には、Azure Event Hubs を介してログとメトリック データを取り込む、組み込みのコネクタが用意されています。 詳細については、Azure Data Explorer での監視データの取り込みとクエリの実行に関するページを参照してください。
InfluxDB はプッシュベースのシステムです。 エージェントはメトリックをプッシュする必要があります。 TICK スタックを使用して Kubernetes の監視を設定できます。 次に、Telegraf (メトリックの収集とレポートのためのエージェント) を使用して InfluxDB にメトリックをプッシュできます。 InfluxDB は、不定期的なイベントや文字列データ型に使用できます。
Prometheus はプルベースのシステムです。 設定された場所から定期的にメトリックを収集します。 Prometheus は、Azure Monitor または kube-state-metrics によって生成されたメトリクスを取得することができます。 kube-state-metrics は、Kubernetes API サーバーからメトリックを収集し、Prometheus (または Prometheus クライアント エンドポイントと互換性のある取得ツール) で使用できるようにするサービスです。 システム メトリックについては、ノード エクスポーターを使用します。これは、システム メトリックの Prometheus 用エクスポート ツールです。 Prometheus は浮動小数点データをサポートしますが、文字列データはサポートしないため、システム メトリックには適していますが、ログには適していません。 Kubernetes Metrics Server は、クラスター全体のリソース使用状況データのアグリゲーターです。
ログ記録
マイクロサービス アプリケーションでのログ記録の一般的な課題を次に示します。
- 1 つの要求を処理するために複数のサービスが呼び出されることがある、クライアント要求のエンドツーエンド処理の理解。
- 複数のサービスから 1 つの集約ビューへのログの統合。
- それぞれが独自のログ スキーマを使っている、または特定のスキーマがない、複数のソースから取得したログの解析。 ログは、自分では制御できないサードパーティのコンポーネントによって生成される場合があります。
- トランザクション内のサービス、ネットワーク呼び出し、ステップが増えているため、マイクロサービス アーキテクチャでは、従来のモノリスより大量のログが生成されることがよくあります。 つまり、ログ自体が、アプリケーションに対するパフォーマンスまたはリソースのボトルネックになる可能性があります。
Kubernetes ベースのアーキテクチャでは、さらにいくつかの課題があります。
- コンテナーが移動されたり再スケジュールされたりする場合があります。
- Kubernetes には、仮想 IP アドレスとポート マッピングを使うネットワーク抽象化があります。
Kubernetes でのログ記録の標準的なアプローチは、コンテナーで stdout および stderr にログを書き込むことです。 コンテナー エンジンでは、これらのストリームがログ ドライバーにリダイレクトされます。 クエリの実行を容易にし、ノードが応答を停止した場合にログ データが消失する可能性を防ぐための通常の方法は、各ノードからログを収集し、中央の保存場所に送信することです。
Azure Monitor は AKS と統合して、このアプローチをサポートします。 Monitor では、コンテナー ログが収集されて、Log Analytics ワークスペースに送信されます。 そこから、Kusto 照会言語を使って、集約されたログに対するクエリを記述できます。 たとえば、指定したポッドのコンテナー ログを表示する Kusto クエリを次に示します。
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
Azure Monitor はマネージド サービスであり、CLI または Azure Resource Manager テンプレートの簡単な構成変更で、Monitor を使うように AKS クラスターを構成できます。 (詳細については、Azure Monitor Container insights を有効にする方法に関する記事を参照してください。) Azure Monitor を使うもう 1 つの利点は、AKS ログと他の Azure プラットフォームのログが統合されて、統合監視エクスペリエンスが提供されることです。
Azure Monitor では、サービスに取り込まれたデータがギガバイト (GB) 単位で請求されます。 (「Azure Monitor の価格」を参照してください。) 量が多いと、コストが考慮事項になる可能性があります。 Kubernetes エコシステムでは、代わりに使用できるオープンソースが多くあります。 たとえば、多くの組織では Fluentd と Elasticsearch が使われています。 Fluentd はオープンソースのデータ コレクターで、Elasticsearch は検索に使用されるドキュメント データベースです。 これらのオプションの課題は、クラスターに関して追加の構成と管理が必要になることです。 運用ワークロードの場合は、構成設定の実験が必要になる可能性があります。 また、ログ記録インフラストラクチャのパフォーマンスを監視する必要があります。
OpenTelemetry
OpenTelemetry は、アプリケーション、ライブラリ、テレメトリ、データ コレクター間のインターフェイスを標準化することによってトレースを改善するための、業界をまたいだ取り組みです。 OpenTelemetry でインストルメント化されたライブラリとフレームワークを使用する場合、従来のシステム操作であるトレース操作のほとんどの作業は、基になるライブラリによって処理されます。これには、次の一般的なシナリオが含まれます。
- 開始時刻、終了時刻、期間などの基本的な要求操作のログ記録
- スローされた例外
- コンテキストの伝達 (HTTP 呼び出しの境界を越えた相関 ID の送信など)
代わりに、これらの操作を処理する基本ライブラリとフレームワークによって、詳細な相互に関連するスパンおよびトレース データ構造が作成され、コンテキスト間で伝達されます。 OpenTelemetry 以前は、これらは通常、特別なログメッセージとして、または監視ツールを構築したベンダーに固有の独自のデータ構造として挿入されていました。 また、OpenTelemetry は、従来のログ優先アプローチよりも高度なインストルメンテーション データ モデルを推奨しています。ログ メッセージはその生成元のトレースとスパンにリンクされるため、ログはより有用になります。 これにより、特定の操作または要求に関連付けられているログを簡単に見つけることができます。
Azure SDK の多くは、既に OpenTelemetry でインストルメント化されているか、または実装中です。
アプリケーション開発者は、OpenTelemetry SDK を使用して手動のインストルメンテーションを追加し、次の操作を行うことができます。
- 基になるライブラリで提供されていない場合にインストルメンテーションを追加する。
- アプリケーション固有の作業単位を公開するためにスパンを追加することでトレース コンテキストをエンリッチする (各注文明細の処理のためにスパンを作成する注文ループなど)。
- トレースを容易にするためにエンティティ キーを使用して既存のスパンをエンリッチする。 (たとえば、注文を処理する要求に OrderID キー/値を追加するなど。) これらのキーは、クエリ、フィルター処理、集計のための構造化された値として監視ツールで表示されます (ログを優先する方法では一般的だった、ログ メッセージ文字列を解析したり、ログ メッセージ シーケンスの組み合わせを検索したりすることはありません)。
- 要求とスパンを作成するために、トレースとスパンの属性へのアクセス、応答とペイロードへの traceId の挿入、および/または受信メッセージからの traceId の読み取りにより、トレース コンテキストを伝達する。
インストルメンテーションと OpenTelemetry SDK の詳細については、OpenTelemetry のドキュメントを参照してください。
Application Insights
Application Insights は OpenTelemetry とそのインストルメンテーション ライブラリから豊富なデータを収集し、それを効率的なデータ ストアにキャプチャすることで、豊富な視覚化とクエリのサポートを提供します。 .NET、Java、Node.js、Python などの言語用の Application Insights の OpenTelemetry ベースのインストルメンテーション ライブラリを使用すると、テレメトリ データを Application Insights に簡単に送信できます。
.NET Core を使っている場合は、Application Insights for Kubernetes ライブラリも検討することをお勧めします。 このライブラリは、コンテナー、ノード、ポッド、ラベル、レプリカ セットなどの情報で Application Insights トレースをエンリッチします。
Application Insights では、OpenTelemetry のコンテキストが内部データ モデルにマップされます。
- トレース-> 操作
- トレース ID -> 操作 ID
- スパン -> 要求または依存関係
次の点を考慮してください。
- データ レートが上限を超えた場合、Application Insights ではテレメトリが調整されます。 詳しくは、Application Insights の制限に関する記事をご覧ください。 1 回の操作で複数のテレメトリ イベントが生成されることがあります。そのため、アプリケーションで大量のトラフィックが発生すると、それが抑えられる可能性があります。
- Application Insights ではデータがバッチ処理されるため、ハンドルされない例外によってプロセスが失敗した場合、バッチが失われる可能性があります。
- Application Insights の請求は、データ量に基づいて行われます。 詳細については、「Application Insights での価格とデータ ボリュームの管理」を参照してください。
構造化ログ
ログを解析しやすくするには、可能であれば、構造化ログ記録を使います。 構造化ログ記録を使用すると、構造化されていないテキスト文字列の出力ではなく、JSON などの構造化された形式のログが、アプリケーションによって書き込まれます。 多くの構造化ログ記録ライブラリを使用できます。 たとえば、.NET Core 用の Serilog ライブラリを使うログ記録ステートメントを次に示します。
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
ここでは、LogInformation の呼び出しに、Id パラメーターと DeliveryInfo パラメーターが含まれています。 構造化ログ記録を使用する場合、これらの値はメッセージ文字列に挿入されません。 代わりに、ログ出力は次のようになります。
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
これは JSON 文字列であり、@t フィールドはタイムスタンプ、@mt はメッセージ文字列、残りのキーと値のペアはパラメーターです。 JSON 形式で出力すると、データのクエリを構造化された方法で簡単に実行できます。 たとえば、Kusto クエリ言語で記述された次の Log Analytics クエリでは、fabrikam-delivery という名前のすべてのコンテナーから、この特定のメッセージのインスタンスが検索されます。
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Azure portal で結果を表示すると、DeliveryInfo は DeliveryInfo モデルのシリアル化された表現を含む構造化されたレコードであることを確認できます。

この例の JSON を次に示します。
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
多くのログ メッセージは、作業単位の開始または終了をマークします。または、ビジネス エンティティを、追跡のために一連のメッセージと操作に関連付けます。 多くの場合、操作の開始と終了をログに記録するだけよりも、OpenTelemetry のスパンと要求オブジェクトをエンリッチするほうが優れています。 そうすることで、接続されているすべてのトレースと子操作にそのコンテキストが追加され、その情報が完全な操作のスコープ内に配置されます。 さまざまな言語用の OpenTelemetry SDK は、スパンの作成やスパンに対するカスタム属性の追加をサポートしています。 たとえば、次のコードでは、Application Insights でサポートされているJava OpenTelemetry SDK を使用しています。 ここに示すように、既存の親スパン (たとえば、REST コントローラー呼び出しに関連付けられ、使用されている Web フレームワークによって作成された要求スパン) は、関連付けられているエンティティ ID を使用してエンリッチできます。
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
このコードによって、現在のスパンに対してキーまたは値が設定されます。これは、そのスパンで発生する操作とログ メッセージに接続されます。 この値は、ここに示すように、Application Insights の要求オブジェクトに現れます。
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
この手法は、ここに示すように、ログ、フィルター処理、およびスパン コンテキストを使用したログ トレースの注釈付けで使用すると、より強力になります。
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
OpenTelemetry で既にインストルメント化されているライブラリまたはフレームワークを使用すると、スパンと要求の作成が処理されますが、アプリケーション コードで作業単位を作成することもできます。 たとえば、エンティティの配列をループ処理して、各項目の処理を実行するするメソッドは、処理ループの反復ごとにスパンを作成する場合があります。 アプリケーションとライブラリのコードにインストルメンテーションを追加する方法については、OpenTelemery インストルメンテーションのドキュメントを参照してください。
分散トレース
マイクロサービスを使用する際の課題の 1 つは、サービス間のイベントのフローを把握することです。 1 つのトランザクションに、複数のサービスの呼び出しが含まれる場合があります。
分散トレースの例
この例では、一連のマイクロサービスを介した分散トランザクションのパスを説明します。 この例は、ドローン配送アプリケーションに基づいています。
このシナリオでは、分散トランザクションにこれらの手順が含まれます。
- Ingestion サービスは、Azure Service Bus キューにメッセージを入れます。
- Workflow サービスは、キューからメッセージを取得します。
- Workflow サービスは、3 つのバックエンド サービス (Drone Scheduler、Package、Delivery) を呼び出して要求を処理します。
次のスクリーンショットでは、ドローン配送アプリケーションのアプリケーション マップを示します。 このマップでは、5 つのマイクロサービスを含むワークフローになるパブリック API エンドポイントの呼び出しが示されています。
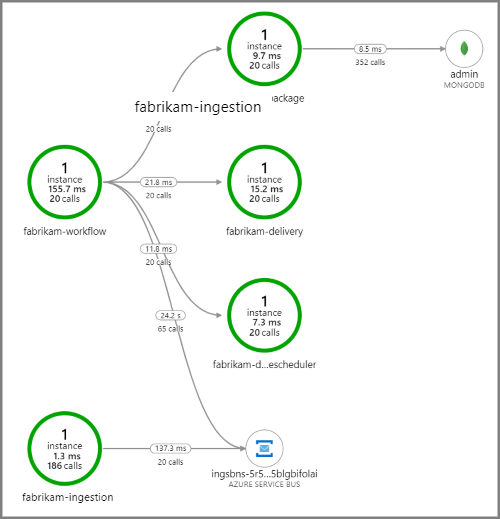
fabrikam-workflow と fabrikam-ingestion から Service Bus キューへの矢印は、メッセージが送信される場所と受信される場所を示します。 どのサービスがメッセージを送信し、どのサービスが受信しているか、図からは判断できません。 矢印は、両方のサービスが Service Bus を呼び出していることを示しています。 ただし、送信しているサービスと受信しているサービスに関する情報は、次の詳細で確認できます。
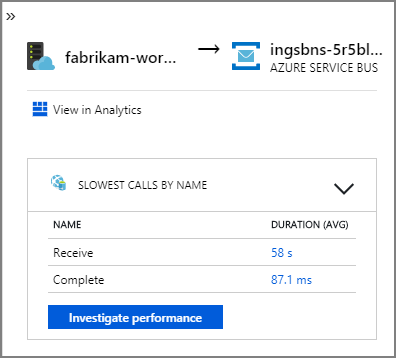
すべての呼び出しには操作 ID が含まれているため、タイミング情報や各ステップでの HTTP 呼び出しなど、単一のトランザクションのエンドツーエンドのステップも見ることができます。 そのようなトランザクションを視覚化したものを次に示します。

この視覚化では、Ingestion サービスからキュー、キューから Workflow サービス、Workflow サービスから他のバックエンド サービスへのステップが示されています。 最後のステップは、Service Bus メッセージを完了としてマークする Workflow サービスです。
この例では、失敗しているバックエンド サービスの呼び出しが示されています。
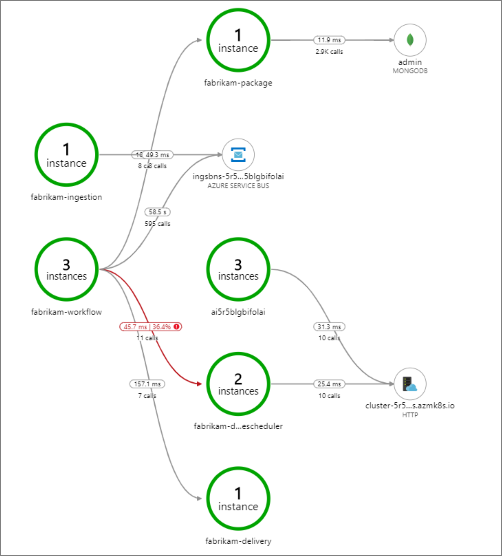
このマップでは、クエリの期間中に Drone Scheduler サービスの呼び出しの大部分 (36%) が失敗したことが示されています。 エンドツーエンドのトランザクション ビューでは、サービスに HTTP PUT 要求が送信されたときに例外が発生していることがわかります。

さらにドリルインすると、この例外がソケット例外 "このようなデバイスまたはアドレスはありません" であることがわかります。
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
この例外は、バックエンド サービスに到達不能であることを示しています。 この時点で、kubectl を使ってデプロイの構成を表示します。 この例では、Kubernetes 構成ファイルのエラーが原因で、サービス ホスト名は解決されません。 Kubernetes のドキュメントの記事「サービスをデバッグする」には、この種類のエラーの診断に関するヒントがあります。
以下では、エラーのよくある原因をいくつか示します。
- コードのバグ。 これらのバグは次のように表示される場合があります。
- 例外。 Application Insights のログを見て、例外の詳細を確認します。
- プロセスが失敗しました。 コンテナーとポッドの状態を見て、コンテナーのログまたは Application Insights のトレースを確認します。
- HTTP 5xx エラー。
- リソースの枯渇:
- 調整 (HTTP 429) または要求タイムアウトを探します。
- CPU、メモリ、ディスクのコンテナー メトリックを調べます。
- コンテナーとポッドのリソース制限の構成を確認します。
- サービス検出。 Kubernetes Service の構成とポートのマッピングを調べます。
- API の不一致。 HTTP 400 エラーを探します。 API がバージョン管理されている場合、呼び出されているバージョンを確認します。
- コンテナー イメージのプルでエラーが発生しました。 ポッドの仕様を確認します。 また、コンテナー レジストリからのプルをクラスターが許可されていることを確認します。
- RBAC の問題。
次のステップ
AKS 上のアプリケーションの監視をサポートする Azure Monitor の機能についてさらに学習します。