この記事はシリーズの一部です。 概要から始めます。
前の手順で実行したクラスターのチェックが明確な場合は、Azure Kubernetes Service (AKS) ワーカー ノードの正常性を確認します。 この記事の 6 つの手順に従って、ノードの正常性を確認し、異常なノードの理由を特定し、問題を解決します。
手順 1: ワーカー ノードの正常性を確認する
さまざまな要因が、AKS クラスター内の異常なノードに影響を与える可能性があります。 一般的な理由の1つは、コントロールプレーンとノード間の通信が断絶することです。 この間違った通信は、多くの場合、ルーティングとファイアウォール規則の構成ミスが原因で発生します。
ユーザー定義ルーティング用に AKS クラスターを構成する場合は、ネットワーク仮想アプライアンス (NVA) またはファイアウォール (Azure ファイアウォールなど) を介してエグレス パスを構成する必要があります。 構成ミスの問題に対処するには、 AKS エグレス トラフィックのガイダンスに従って、必要なポートと完全修飾ドメイン名 (FQDN) を許可するようにファイアウォールを構成することをお勧めします。
異常なノードのもう 1 つの理由は、kubelet の負荷を生み出すコンピューティング、メモリ、またはストレージ リソースが不十分である可能性があります。 このような場合、リソースをスケールアップすると、問題を効果的に解決できます。
プライベート AKS クラスターでは、ドメイン ネーム システム (DNS) の解決の問題により、コントロール プレーンとノード間の通信の問題が発生する可能性があります。 Kubernetes API サーバーの DNS 名が API サーバーのプライベート IP アドレスに解決されることを確認する必要があります。 カスタム DNS サーバーの正しくない構成は、DNS 解決エラーの一般的な原因です。 カスタム DNS サーバーを使用する場合は、ノードがプロビジョニングされている仮想ネットワーク上の DNS サーバーとして正しく指定してください。 また、カスタム DNS サーバーを介して AKS プライベート API サーバーを解決できることを確認します。
コントロール プレーンの通信と DNS 解決に関連するこれらの潜在的な問題に対処したら、AKS クラスター内のノードの正常性の問題に効果的に取り組んで解決できます。
次のいずれかの方法を使用して、ノードの正常性を評価できます。
Azure Monitor コンテナー正常性ビュー
AKS クラスター内のノード、ユーザー ポッド、およびシステム ポッドの正常性を表示するには、次の手順に従います。
- Azure portal で Azure Monitor に移動します。
- ナビゲーション ウィンドウの [ Insights ] セクションで、[コンテナー] を選択 します。
- 監視対象の AKS クラスターの一覧については、[監視対象クラスター] を選択します。
- 一覧から AKS クラスターを選択して、ノード、ユーザー ポッド、およびシステム ポッドの正常性を表示します。
![[コンテナーの状態監視ビュー] を示すスクリーンショット。](images/azure-monitor-containers-health.png#lightbox)
AKS ノード ビュー
AKS クラスター内のすべてのノードが準備完了状態であることを確認するには、次の手順に従います。
- Azure portal で、AKS クラスターに移動します。
- ナビゲーション ウィンドウの [設定] セクションで、[ ノード プール] を選択します。
- [ノード] を選択します。
- すべてのノードが準備完了状態であることを確認します。

Prometheus と Grafana を使用したクラスター内監視
AKS クラスターに Prometheus と Grafana をデプロイした場合は、 K8 クラスター詳細ダッシュボード を使用して分析情報を取得できます。 このダッシュボードには、Prometheus クラスターメトリックが表示され、CPU 使用率、メモリ使用量、ネットワーク アクティビティ、ファイル システムの使用状況などの重要な情報が表示されます。 また、個々のポッド、コンテナー、 および systemd サービスの詳細な統計情報も表示されます。
ダッシュボードで [ ノードの条件 ] を選択して、クラスターの正常性とパフォーマンスに関するメトリックを表示します。 スケジュールの問題、ネットワーク、ディスクの負荷、メモリ負荷、比例積分派生 (PID) の負荷、ディスク領域など、問題が発生する可能性があるノードを追跡できます。 これらのメトリックを監視して、AKS クラスターの可用性とパフォーマンスに影響を与える可能性のある問題を事前に特定して対処できるようにします。

Prometheus と Azure Managed Grafana のマネージド サービスを監視する
事前構築済みのダッシュボードを使用して、Prometheus メトリックを視覚化および分析できます。 これを行うには、Prometheus の Monitor マネージド サービスで Prometheus メトリックを収集し、 Monitor ワークスペース を Azure Managed Grafana ワークスペースに接続するように AKS クラスターを設定する必要があります。 これらのダッシュボードは、 Kubernetes クラスターのパフォーマンスと正常性の包括的なビューを提供します。
ダッシュボードは、 Managed Prometheus フォルダー内の指定された Azure Managed Grafana インスタンスにプロビジョニングされます。 一部のダッシュボードには、次のものが含まれます。
- Kubernetes / コンピューティング リソース / クラスター
- Kubernetes / コンピューティング リソース / 名前空間 (ポッド)
- Kubernetes / コンピューティング リソース / ノード (ポッド)
- Kubernetes / コンピューティング リソース / ポッド
- Kubernetes / コンピューティング リソース / 名前空間 (ワークロード)
- Kubernetes / コンピューティング リソース / ワークロード
- Kubernetes/Kubelet
- Node Exporter / USE メソッド / Node
- ノード エクスポーター/ノード
- Kubernetes / コンピューティング リソース / クラスター (Windows)
- Kubernetes / コンピューティング リソース / 名前空間 (Windows)
- Kubernetes / コンピューティング リソース / ポッド (Windows)
- Kubernetes / USE メソッド / クラスター (Windows)
- Kubernetes / USE メソッド / Node (Windows)
これらの組み込みダッシュボードは、Prometheus と Grafana を使用して Kubernetes クラスターを監視するために、オープンソース コミュニティで広く使用されています。 これらのダッシュボードを使用して、リソースの使用状況、ポッドの正常性、ネットワーク アクティビティなどのメトリックを表示します。 監視のニーズに合わせてカスタマイズされたカスタム ダッシュボードを作成することもできます。 ダッシュボードを使用すると、AKS クラスター内の Prometheus メトリックを効果的に監視および分析できます。これにより、パフォーマンスの最適化、問題のトラブルシューティング、および Kubernetes ワークロードの円滑な運用を実現できます。
Kubernetes/コンピューティング リソース/ノード (ポッド) ダッシュボードを使用して、Linux エージェント ノードのメトリックを表示できます。 各ポッドの CPU 使用率、CPU クォータ、メモリ使用量、メモリ クォータを視覚化できます。

クラスターに Windows エージェント ノードが含まれている場合は、 Kubernetes/USE メソッド/ノード (Windows) ダッシュボードを使用して、これらのノードから収集された Prometheus メトリックを視覚化できます。 このダッシュボードでは、クラスター内の Windows ノードのリソース消費とパフォーマンスの包括的なビューが提供されます。
これらの専用ダッシュボードを利用して、Linux および Windows エージェント ノードの両方の CPU、メモリ、およびその他のリソースに関連する重要なメトリックを簡単に監視および分析できます。 この可視性により、潜在的なボトルネックを特定し、リソースの割り当てを最適化し、AKS クラスター全体で効率的な操作を確保できます。
手順 2: コントロール プレーンとワーカー ノードの接続を確認する
ワーカー ノードが正常な場合は、マネージド AKS コントロール プレーンとクラスター ワーカー ノードの間の接続を確認する必要があります。 AKS を使用すると、セキュリティで保護されたトンネル通信方法を使用して、 Kubernetes API サーバー と個々のノード kubelets 間の通信が可能になります。 これらのコンポーネントは、異なる仮想ネットワーク上にある場合でも通信できます。 トンネルは、相互トランスポート層セキュリティ (mTLS) 暗号化で保護されています。 AKS で使用されるプライマリ トンネルは Konnectivity (旧称 apiserver-network-proxy) と呼ばれます。 すべてのネットワーク規則と FQDN が、必要な Azure ネットワーク規則に準拠していることを確認します。
マネージド AKS コントロール プレーンと AKS クラスターのクラスター ワーカー ノードの間の接続を確認するには、 kubectl コマンド ライン ツールを使用できます。
Konnectivity エージェント ポッドが正常に動作することを確認するには、次のコマンドを実行します。
kubectl get deploy konnectivity-agent -n kube-system
ポッドが準備完了状態であることを確認します。
コントロール プレーンとワーカー ノード間の接続に問題がある場合は、必要な AKS エグレス トラフィック ルールが許可されていることを確認した後、接続を確立します。
次のコマンドを実行して、 konnectivity-agent ポッドを再起動します。
kubectl rollout restart deploy konnectivity-agent -n kube-system
ポッドを再起動しても接続が修正されない場合は、ログで異常がないか確認します。 次のコマンドを実行して、 konnectivity-agent ポッドのログを表示します。
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
ログには、次の出力が表示されます。
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
注
API サーバー仮想ネットワーク統合と、動的ポッド IP 割り当てがある Azure コンテナー ネットワーク インターフェイス (CNI) または Azure CNI を使用して AKS クラスターを設定する場合、Konnectivity エージェントをデプロイする必要はありません。 統合 API サーバー ポッドは、プライベート ネットワークを介してクラスター ワーカー ノードとの直接通信を確立できます。
ただし、AZURE CNI オーバーレイと API サーバーの仮想ネットワーク統合を使用する場合や、独自の CNI (BYOCNI) を使用する場合は、API サーバーとポッド IP 間の通信を容易にするために Konnectivity がデプロイされます。 API サーバーとワーカー ノード間の通信は引き続き直接行われます。
ログと監視サービスのコンテナー ログを検索して、ログを取得することもできます。 aks-link 接続エラーを検索する例については、コンテナー分析情報からのログのクエリを参照してください。
次のクエリを実行してログを取得します。
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
次のクエリを実行して、特定の名前空間で失敗したポッドのコンテナー ログを検索します。
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
クエリまたは kubectl ツールを使用してログを取得できない場合は、 Secure Shell (SSH) 認証を使用します。 この例では、SSH 経由でノードに接続した後に トンネルフロント ポッドを検索します。
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
手順 3: エグレスを制限するときに DNS 解決を検証する
DNS 解決は、AKS クラスターの重要な側面です。 DNS 解決が正しく機能しない場合は、コントロール プレーン エラーまたはコンテナー イメージのプルエラーが発生する可能性があります。 Kubernetes API サーバーへの DNS 解決が正しく機能していることを確認するには、次の手順に従います。
kubectl exec コマンドを実行して、ポッドで実行されているコンテナーでコマンド シェルを開きます。
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashどちらのツールもポッドにインストールされていない場合は、次のコマンドを実行して、同じ名前空間にユーティリティ ポッドを作成します。
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shAZURE portal で AKS クラスターの概要ページから API サーバー アドレスを取得することも、次のコマンドを実行することもできます。
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsv次のコマンドを実行して、AKS API サーバーの解決を試みます。 詳細については、 ポッド内からの DNS 解決エラーのトラブルシューティングを参照してください。ワーカー ノードからのトラブルシューティングは行いません。
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioポッドからのアップストリーム DNS サーバーを調べて、DNS 解決が正しく機能しているかどうかを確認します。 たとえば、Azure DNS の場合は、
nslookupコマンドを実行します。nslookup microsoft.com 168.63.129.16前の手順で分析情報が得られない場合は、 いずれかのワーカー ノードに接続し、ノードから DNS 解決を試みます。 この手順は、問題が AKS とネットワーク構成のどちらに関連しているかを特定するのに役立ちます。
ノードから DNS 解決が成功したが、ポッドからは解決されない場合、問題は Kubernetes DNS に関連している可能性があります。 ポッドから DNS 解決をデバッグする手順については、「 DNS 解決エラーのトラブルシューティング」を参照してください。
ノードから DNS 解決が失敗した場合は、ネットワークのセットアップを確認して、DNS 解決を容易にするために適切なルーティング パスとポートが開かれていることを確認します。
手順 4: kubelet エラーを確認する
各ワーカー ノードで実行される kubelet プロセスの条件を確認し、負荷がかからないようにします。 潜在的な負荷は、CPU、メモリ、またはストレージに関連している可能性があります。 個々のノード の kubelets の状態を確認するには、次のいずれかの方法を使用できます。
AKS kubelet ワークブック
エージェント ノードの kubelets が正しく動作することを確認するには、次の手順に従います。
Azure portal で、AKS クラスターに移動します。
ナビゲーション ウィンドウの監視セクションで、ワークブックを選択します。
Kubelet ブックを選択します。
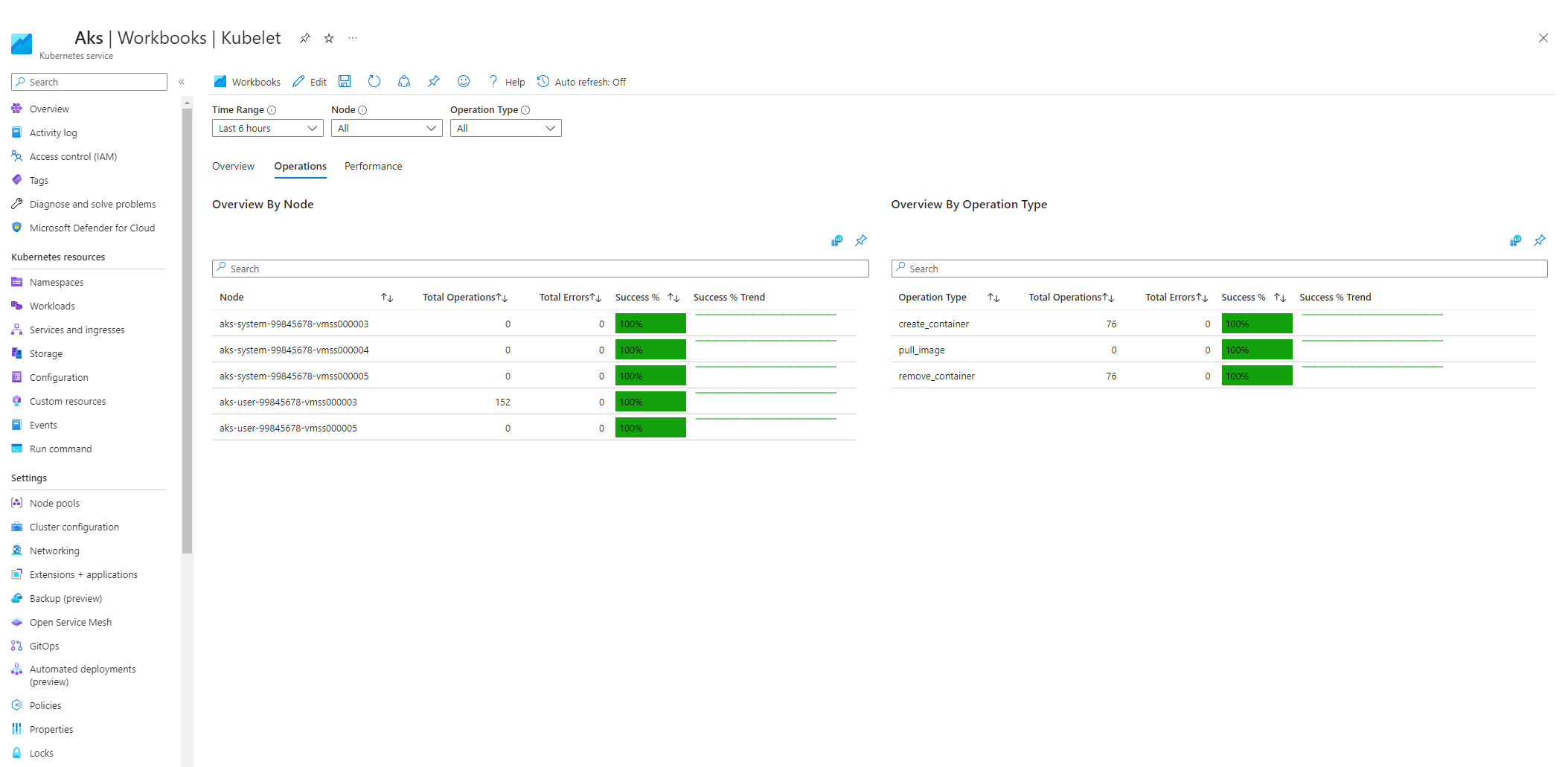
[ 操作] を選択し、すべてのワーカー ノードの操作が完了していることを確認します。


Prometheus と Grafana を使用したクラスター内監視
AKS クラスターに Prometheus と Grafana をデプロイした場合は、 Kubernetes/Kubelet ダッシュボードを使用して、個々のノード kubelets の正常性とパフォーマンスに関する分析情報を取得できます。

Prometheus と Azure Managed Grafana のマネージド サービスを監視する
Kubernetes/Kubelet 事前構築済みダッシュボードを使用して、ワーカー ノード kubelets の Prometheus メトリックを視覚化および分析できます。 これを行うには、Prometheus の Monitor マネージド サービスで Prometheus メトリックを収集し、 Monitor ワークスペース を Azure Managed Grafana ワークスペースに接続するように AKS クラスターを設定する必要があります。

Kubelet が再起動すると圧力が高くなり、散発的で予測できない動作が発生します。 エラー数が継続的に増加しないことを確認します。 場合によってはエラーが発生してもかまいませんが、一定の増加は、調査して解決する必要がある根本的な問題を示しています。
手順 5: ノード問題検出 (NPD) ツールを使用してノードの正常性を確認する
NPD は、ノード関連の問題を特定して報告するために使用できる Kubernetes ツールです。 これは、クラスター内のすべてのノードで systemd サービスとして動作します。 CPU 使用率、ディスク使用率、ネットワーク接続状態などのメトリックとシステム情報を収集します。 問題が検出されると、NPD ツールによってイベントとノードの条件に関するレポートが生成されます。 AKS では、NPD ツールを使用して、Azure クラウドでホストされている Kubernetes クラスター内のノードを監視および管理します。 詳細については、 AKS ノードの NPD を参照してください。
手順 6: 1 秒あたりのディスク I/O 操作 (IOPS) の調整を確認する
IOPS が調整されず、AKS クラスター内のサービスとワークロードに影響を与えないように、次のいずれかの方法を使用できます。
AKS ノード ディスク I/O ワークブック
AKS クラスター内のワーカー ノードのディスク I/O 関連メトリックを監視するには、 ノード ディスク I/O ブックを使用できます。 ブックにアクセスするには、次の手順に従います。
Azure portal で、AKS クラスターに移動します。
ナビゲーション ウィンドウの監視セクションで、ワークブックを選択します。
ノード ディスク IO ワークブックを選択します。
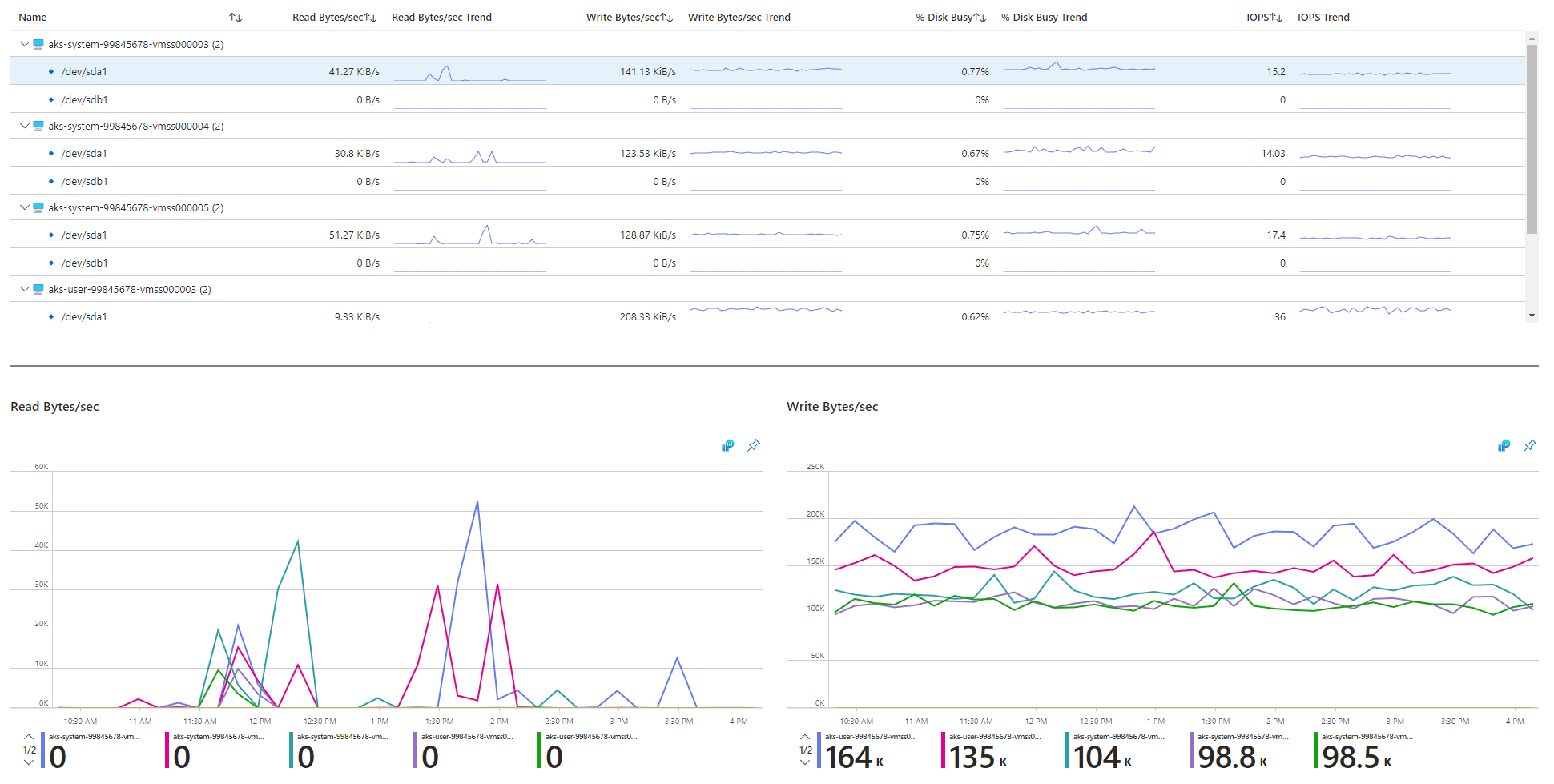
I/O 関連のメトリックを確認します。


Prometheus と Grafana を使用したクラスター内監視
AKS クラスターに Prometheus と Grafana をデプロイした場合は、 USE メソッド/ノード ダッシュボードを使用して、クラスター ワーカー ノードのディスク I/O に関する分析情報を取得できます。

Prometheus と Azure Managed Grafana のマネージド サービスを監視する
ノード エクスポーター/ノード事前構築済みダッシュボードを使用して、ワーカー ノードからディスク I/O 関連のメトリックを視覚化および分析できます。 これを行うには、Prometheus の Monitor マネージド サービスで Prometheus メトリックを収集し、 Monitor ワークスペース を Azure Managed Grafana ワークスペースに接続するように AKS クラスターを設定する必要があります。

IOPS と Azure ディスク
物理ストレージ デバイスには、帯域幅と、処理できるファイル操作の最大数に固有の制限があります。 Azure ディスクは、AKS ノードで実行されるオペレーティング システムを格納するために使用されます。 ディスクには、オペレーティング システムと同じ物理ストレージ制約が適用されます。
スループットの概念を考えてみましょう。 平均 I/O サイズに IOPS を乗算して、1 秒あたりのスループット (MBps) を MB 単位で決定できます。 I/O サイズを大きくすると、ディスクの固定スループットが原因で IOPS が低下します。
ワークロードが Azure ディスクに割り当てられている最大 IOPS サービス制限を超えると、クラスターが応答しなくなり、I/O 待機状態になる可能性があります。 Linux ベースのシステムでは、ネットワーク ソケット、CNI、Docker、ネットワーク I/O に依存するその他のサービスなど、多くのコンポーネントがファイルとして扱われます。 そのため、ディスクを読み取ることができない場合、エラーはこれらすべてのファイルに拡張されます。
次のようないくつかのイベントとシナリオで IOPS 調整をトリガーできます。
Docker I/O はオペレーティング システム ディスクを共有するため、ノードで実行されるコンテナーの数が多い。
セキュリティ、監視、およびログ記録に使用されるカスタムまたはサード パーティ製のツール。オペレーティング システム ディスクに追加の I/O 操作が生成される可能性があります。
ワークロードを強化したりポッドの数をスケーリングしたりするノード フェールオーバー イベントと定期的なジョブ。 この負荷が増加すると制限が発生する可能性が高まり、I/O 操作が終了するまで、すべてのノードが 準備ができていない状態 に移行する可能性があります。
貢献者
この記事は Microsoft によって管理されています。 当初の寄稿者は以下のとおりです。
主要な著者:
- パオロ サルヴァトリ |プリンシパル カスタマー エンジニア
- フランシスコ・シミー・ナハレス |シニア テクニカル スペシャリスト
非公開の LinkedIn プロファイルを表示するには、LinkedIn にサインインします。