Azure Blob Storage
分散アプリケーションで共同作業を行うインスタンスのコレクションによって実行されるアクションを調整するには、1 つのインスタンスを他のインスタンスを管理する責任を負うリーダーとして選択します。 これは、インスタンスが互いに競合しないようにしたり、共有リソースの競合を引き起こしたり、他のインスタンスが実行している作業に誤って干渉したりするのに役立ちます。
コンテキストと問題
一般的なクラウド アプリケーションには、調整された方法で動作する多くのタスクがあります。 これらのタスクはすべて、同じコードを実行し、同じリソースへのアクセスを必要とするインスタンスであるか、複雑な計算の個々の部分を実行するために並行して動作している可能性があります。
タスク インスタンスは、多くの場合、個別に実行される場合がありますが、各インスタンスのアクションを調整して、それらが競合しないようにしたり、共有リソースの競合を引き起こしたり、他のタスク インスタンスが実行している作業に誤って干渉したりする必要がある場合もあります。
例えば次が挙げられます。
- 水平スケーリングを実装するクラウドベースのシステムでは、同じタスクの複数のインスタンスが、異なるユーザーにサービスを提供する各インスタンスと同時に実行される可能性があります。 これらのインスタンスが共有リソースに書き込む場合は、各インスタンスが他のインスタンスによって行われた変更を上書きしないようにアクションを調整する必要があります。
- タスクが複雑な計算の個々の要素を並列で実行している場合は、すべてが完了したときに結果を集計する必要があります。
タスク インスタンスはすべてピアであるため、コーディネーターまたはアグリゲーターとして機能できる自然なリーダーはありません。
解決策
リーダーとして機能するように 1 つのタスク インスタンスを選択する必要があります。このインスタンスは、他の下位タスク インスタンスのアクションを調整する必要があります。 すべてのタスク インスタンスが同じコードを実行している場合、それらはそれぞれリーダーとして機能できます。 したがって、2 つ以上のインスタンスが同時にリーダーの位置を引き継ぐのを防ぐために、選択プロセスを慎重に管理する必要があります。
システムは、リーダーを選択するための堅牢なメカニズムを提供する必要があります。 この方法では、ネットワークの停止やプロセスエラーなどのイベントに対処する必要があります。 多くのソリューションでは、下位タスク インスタンスは、何らかの種類のハートビート メソッドまたはポーリングによってリーダーを監視します。 指定されたリーダーが予期せず終了した場合、またはネットワーク障害によって下位タスク インスタンスでリーダーが使用できなくなった場合は、新しいリーダーを選択する必要があります。
分散環境の一連のタスクの中でリーダーを選ぶには、次のような複数の戦略があります。
- 共有の分散ミューテックスを獲得しようと急いでいる。 ミューテックスを取得する最初のタスク インスタンスがリーダーです。 ただし、システムは、リーダーが終了するか、システムの残りの部分から切断された場合、ミューテックスが解放され、別のタスク インスタンスがリーダーになるようにする必要があります。 この方法を次の例で示します。
- Bully アルゴリズム、ラフト コンセンサス アルゴリズム、チャンとロバーツ アルゴリズムなど、一般的なリーダー選定アルゴリズムの 1 つを実装します。 これらのアルゴリズムは、選挙の各候補者が一意の ID を持ち、他の候補者と確実に通信できることを前提としています。
問題と考慮事項
このパターンを実装する方法を決定するときは、次の点を考慮してください。
- リーダーを選ぶプロセスは、一時的で永続的な障害に対する回復性を備える必要があります。
- リーダーがいつ失敗したか、または使用できなくなった場合 (通信エラーなど) を検出できる必要があります。 検出が必要な速さは、システムによって異なります。 一部のシステムでは、リーダーなしで短時間機能でき、その間に一時的な障害が修正される可能性があります。 それ以外の場合は、リーダーの失敗をすぐに検出し、新しい選択をトリガーすることが必要な場合があります。
- 水平自動スケールを実装するシステムでは、システムがスケール バックしてコンピューティング リソースの一部をシャットダウンすると、リーダーを終了できます。
- 共有の分散ミューテックスを使用すると、ミューテックスを提供する外部サービスへの依存関係が導入されます。 サービスは単一障害点を構成します。 何らかの理由で使用できなくなった場合、システムはリーダーを選択できなくなります。
- 1 つの専用プロセスをリーダーとして使用することは、簡単なアプローチです。 ただし、プロセスが失敗した場合は、再起動中に大幅な遅延が発生する可能性があります。 結果として生じる待機時間は、リーダーが操作を調整するのを待機している場合、他のプロセスのパフォーマンスと応答時間に影響を与える可能性があります。
- リーダー選択アルゴリズムの 1 つを手動で実装すると、コードをチューニングおよび最適化するための最大の柔軟性が提供されます。
- リーダーをシステムのボトルネックにしないでください。 リーダーの目的は、下位タスクの作業を調整することであり、必ずしもこの作業自体に参加する必要はありません。ただし、タスクがリーダーとして選択されていない場合は、この作業に参加できる必要があります。
このパターンを使用する場合
このパターンは、クラウドでホストされるソリューションなどの分散アプリケーションのタスクに慎重な調整が必要であり、自然なリーダーがいない場合に使用します。
このパターンは、次の場合には役に立たない場合があります。
- 常にリーダーとして機能できる自然なリーダーまたは専用のプロセスがあります。 たとえば、タスク インスタンスを調整するシングルトン プロセスを実装できる場合があります。 このプロセスが失敗した場合、または異常になった場合、システムはそれをシャットダウンして再起動できます。
- タスク間の調整は、より軽量な方法を使用して実現できます。 たとえば、複数のタスク インスタンスが単に共有リソースへの調整されたアクセスを必要とする場合は、オプティミスティック ロックまたはペシミスティック ロックを使用してアクセスを制御することをお勧めします。
- Apache Zookeeper などのサードパーティソリューションは、より効率的なソリューションである可能性があります。
ワークロード設計
アーキテクトは、ワークロードの設計でリーダー選定パターンを使用して、 Azure Well-Architected Framework の柱で説明されている目標と原則に対処する方法を評価する必要があります。 例えば次が挙げられます。
| 柱 | このパターンが柱の目標をサポートする方法 |
|---|---|
| 信頼性設計の決定により、ワークロードが誤動作に対して復元力を持ち、障害発生後も完全に機能する状態に回復することができます。 | このパターンは、作業を確実にリダイレクトすることで、ノードの誤動作の影響を軽減します。 また、リーダーが誤動作したときにコンセンサス アルゴリズムを使用してフェールオーバーを実装します。 - RE: 05冗長性 - RE:07 自己修復 |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
例
GitHub の Leader Election サンプルでは、Azure Storage BLOB のリースを使用して、共有の分散ミューテックスを実装するためのメカニズムを提供する方法を示します。 このミューテックスを使用して、使用可能なワーカー インスタンスのグループ間でリーダーを選択できます。 リースを取得する最初のインスタンスはリーダーに選択され、リースを解放するか、リースを更新できないまでリーダーのままです。 リーダーが使用できなくなった場合でも、他の worker インスタンスは引き続き BLOB リースを監視できます。
BLOB リースは、BLOB に対する専用の書き込みロックです。 1 つの BLOB は、任意の時点で 1 つのリースのみの対象にすることができます。 ワーカー インスタンスは、指定された BLOB に対してリースを要求できます。同じ BLOB に対してリースを保持しているワーカー インスタンスが他に存在しない場合は、リースが付与されます。 それ以外の場合、リクエストは例外を投げます。
障害が発生したリーダー インスタンスがリースを無期限に保持しないようにするには、リースの有効期間を指定します。 この有効期限が切れると、リースが使用可能になります。 ただし、インスタンスがリースを保持している間は、リースの更新を要求でき、さらに一定期間リースが付与されます。 リーダー インスタンスは、リースを保持する場合に、このプロセスを継続的に繰り返すことができます。 BLOB をリースする方法の詳細については、「リース BLOB (REST API)」を参照してください。
次の C# の例の BlobDistributedMutex クラスには、ワーカー インスタンスが指定した BLOB 経由でリースを取得できるようにする RunTaskWhenMutexAcquired メソッドが含まれています。 blob の詳細 (名前、コンテナー、ストレージ アカウント) は、BlobSettings オブジェクトの作成時にBlobDistributedMutex オブジェクトのコンストラクターに渡されます (このオブジェクトはサンプル コードに含まれる単純な構造体です)。 コンストラクターは、BLOB のリースを正常に取得しリーダーとして選出された場合に、ワーカー インスタンスが実行すべきコードを参照するTaskも受け入れます。 リース取得の低レベルの詳細を処理するコードは、 BlobLeaseManagerという名前の別のヘルパー クラスに実装されます。
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
前のコード サンプルの RunTaskWhenMutexAcquired メソッドは、次のコード サンプルに示す RunTaskWhenBlobLeaseAcquired メソッドを呼び出して、実際にリースを取得します。
RunTaskWhenBlobLeaseAcquired メソッドは非同期的に実行されます。 リースが正常に取得された場合、ワーカーインスタンスがリーダーとして選出されます。
taskToRunWhenLeaseAcquiredデリゲートの目的は、他の worker インスタンスを調整する作業を実行することです。 リースが取得されていない場合、別のワーカー インスタンスがリーダーとして選択され、現在のワーカー インスタンスは下位のままになります。
TryAcquireLeaseOrWait メソッドは、BlobLeaseManager オブジェクトを使用してリースを取得するヘルパー メソッドであることに注意してください。
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
リーダーによって開始されたタスクも非同期的に実行されます。 このタスクの実行中、次のコード サンプルに示す RunTaskWhenBlobLeaseAcquired メソッドは定期的にリースの更新を試みます。 これにより、ワーカー インスタンスがリーダーのままになります。 サンプル ソリューションでは、別のワーカー インスタンスがリーダーに選択されないようにするために、更新要求間の遅延がリース期間中に指定された時間よりも短くなります。 何らかの理由で更新が失敗した場合、リーダー固有のタスクは取り消されます。
リースの更新に失敗した場合、またはタスクが取り消された場合 (ワーカー インスタンスがシャットダウンした結果として発生する可能性があります)、リースは解放されます。 この時点で、このワーカー インスタンスまたは別のワーカー インスタンスをリーダーとして選択できます。 次のコード抽出は、プロセスのこの部分を示しています。
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
KeepRenewingLease メソッドは、BlobLeaseManager オブジェクトを使用してリースを更新する別のヘルパー メソッドです。
CancelAllWhenAnyCompletes メソッドは、最初の 2 つのパラメーターとして指定されたタスクを取り消します。 次の図は、 BlobDistributedMutex クラスを使用してリーダーを選択し、操作を調整するタスクを実行する方法を示しています。
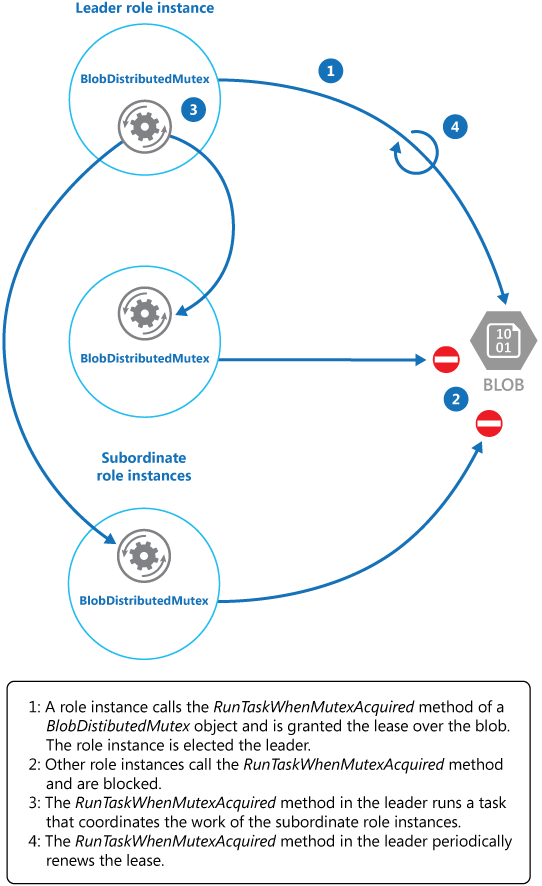
次のコード例は、ワーカー インスタンス内で BlobDistributedMutex クラスを使用する方法を示しています。 このコードは、リースのコンテナー Azure Blob Storage の MyLeaderCoordinatorTask という名前の BLOB に対するリースを取得し、ワーカー インスタンスがリーダーに選択された場合に、 MyLeaderCoordinatorTask メソッドで定義されたコードを実行することを指定します。
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
サンプル ソリューションに関する次の点に注意してください。
- BLOBは単一障害点となる可能性があります。 BLOB サービスが使用できなくなった場合、またはアクセスできない場合、リーダーはリースを更新できず、他の worker インスタンスはリースを取得できません。 この場合、リーダーとして機能できるワーカー インスタンスはありません。 ただし、BLOB サービスは回復性を備えるように設計されているため、BLOB サービスの完全な障害は非常に可能性が低いと見なされます。
- リーダーが実行しているタスクが停止した場合、リーダーが継続的にリースを更新し、他のワーカーインスタンスがリースを取得してタスクを調整するためにリーダーの位置を引き継ぐことができないようにします。 現実の世界では、リーダーの正常性を頻繁にチェックする必要があります。
- 選挙プロセスは非決定的です。 どのワーカー インスタンスが BLOB リースを取得してリーダーになるかを想定することはできません。
- BLOB リースのターゲットとして使用される BLOB は、他の目的には使用しないでください。 ワーカー インスタンスがこの BLOB にデータを格納しようとすると、ワーカー インスタンスがリーダーであり、BLOB リースを保持していない限り、このデータにアクセスできません。
次のステップ
このパターンを実装する場合は、次のガイダンスも関連する場合があります。
- このパターンには、ダウンロード可能な サンプル アプリケーションがあります。
- 自動スケール ガイダンス。 アプリケーションの負荷が異なるため、タスク ホストのインスタンスを開始および停止できます。 自動スケールは、ピーク時の処理時にスループットとパフォーマンスを維持するのに役立ちます。
- タスク ベースの非同期パターン。
- Apache Curator は、Apache ZooKeeper 用のクライアントライブラリです。
- リース BLOB (REST API)に関するMSDNの記事。