Azure
一時的な障害をアプリケーションが処理できるようにします。アプリケーションがサービスまたはネットワーク リソースに接続しようとしたときに失敗した操作を透過的に再試行します。 これにより、アプリケーションの安定性を向上させることができます。
コンテキストと問題
クラウドで実行されている要素と通信するアプリケーションは、この環境で発生する一時的な障害に敏感である必要があります。 障害とは、たとえば、コンポーネントやサービスとのネットワーク接続が一瞬失われたり、サービスを一時的に利用できなくなったり、サービスがビジー状態となってタイムアウトしたりすることが該当します。
通常、これらの障害は自動修正され、障害のトリガーとなったアクションを適切な待ち時間の経過後に再試行すると、高い確率で正常に実行されます。 たとえば、多数の同時要求を処理しているデータベース サービスは、ワークロードが緩和されるまで一時的に新たな要求を拒否する調整ストラテジを実装することができます。 データベースにアクセスしようとしているアプリケーションが接続に失敗した場合は、時間をおいてから接続を再試行すれば成功する可能性があります。
解決策
クラウドでは一時的な障害が予想されるため、アプリケーションはそれらを適切かつ透過的に処理するように設計する必要があります。 そうすることで、アプリケーションが実行しているビジネス タスクに障害が及ぼす影響を最小限に抑えることができます。 対処する最も一般的な設計パターンは、再試行メカニズムを導入することです。
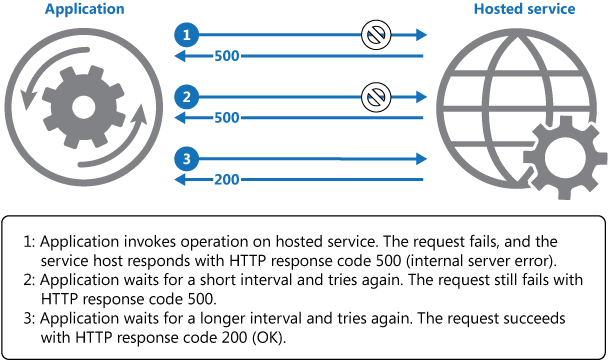
上の図は、再試行メカニズムを使用してホストされるサービスで操作を呼び出す方法を示しています。 あらかじめ定義された試行回数で要求が成功しない場合、アプリケーションは、障害を例外として適切に処理する必要があります。
注
一時的な障害はよくあることなので、多くのクライアント ライブラリやクラウド サービスでは、最大再試行回数、再試行間の遅延、その他のパラメータをある程度構成できる組み込みの再試行メカニズムが利用できるようになりました。 たとえば、Entity Framework Core は、失敗したデータベース操作を再試行する機能を提供します。
再試行戦略
アプリケーションがリモート サービスに要求を送信しようとしたときに障害が検出された場合は、次の方法を使用して障害を処理できます。
キャンセルする。 障害が一時的でないか、操作を繰り返しても成功する可能性が低い場合、アプリケーションは、操作をキャンセルして例外を報告する必要があります。
すぐに再試行。 報告された特定の障害が、送信中にネットワーク パケットが破損するなどの異常またはまれな場合は、要求を直ちに再試行することをお勧めします。
時間をおいて再試行する。 障害の原因が一般的な接続の問題やビジー状態である場合、接続問題が解決するか、作業のバックログがクリアされるまでにネットワークやサービスが短時間必要になる可能性があります。そのため、再試行をプログラム的に遅らせることは有効な戦略です。 多くの場合、アプリケーションの複数インスタンスからの要求ができるだけ均等に分散されるように再試行の間隔を選択することで、負荷の大きいサービスで過負荷状態が継続する可能性を縮小する必要があります。
要求が失敗する場合、アプリケーションは待機してから再試行できます。 必要であれば、要求の最大最高回数に達するまで、再試行の待ち時間を長くしてこのプロセスを繰り返すことができます。 待ち時間は、障害の種類とその時間中に修正される確率に応じて、増分的または指数関数的に長くすることができます。
アプリケーションは、リモート サービスにアクセスするすべての試みを、前述の方法のいずれかに一致する再試行ポリシーを実装するコード内にラップする必要があります。 異なるサービスに送信される要求は、異なるポリシーの対象にすることができます。
アプリケーションは、障害と失敗した操作の詳細をログに記録する必要があります。 この情報はオペレーターにとって有益です。 ただし、再試行して成功した操作に関する警告でオペレーターが手一杯になることを回避するために、初期の失敗を情報エントリとしてログに記録し、最後の再試行で失敗した場合のみ実際のエラーとしてログに記録することをお勧めします。 このログ モデルではどのようになるかの例を次に示します。
サービスが頻繁に使用できなくなるかビジー状態になる場合、その原因の多くは、サービスのリソースが使い果たされていることです。 サービスをスケール アウトすることで、このような障害の頻度を軽減できます。 たとえば、データベース サービスが継続的に過負荷になる場合は、データベースをパーティション分割し、複数のサーバーに負荷を分散すると効果的である可能性があります。
問題と注意事項
このパターンの実装方法を決めるときは、以下の点を考慮してください。
パフォーマンスへの影響
再試行ポリシーは、アプリケーションのビジネス要件と障害の性質と一致するように調整する必要があります。 一部の重要でない操作では、複数回再試行してアプリケーションのスループットに影響を与えるのではなく、高速で失敗することをお勧めします。 たとえば、リモート サービスにアクセスする対話型の Web アプリケーションでは、数回の再試行を短い待ち時間で実行した後、適切なメッセージ (たとえば、"後でもう一度お試しください") をユーザーに表示することをお勧めします。 バッチ アプリケーションの場合は、再試行の待ち時間を指数関数的に長くしながら何度も再試行するほうが適切である可能性があります。
最短の待ち時間で何回も再試行を行う攻撃的な再試行ポリシーは、フル稼働しているかその状態に近いビジー状態のサービスをさらに低下させる可能性があります。 この再試行ポリシーは、障害が発生した操作を継続的に再試行しようとした場合、アプリケーションの応答性にも影響を与える可能性があります。
大量の再試行の後も要求が失敗する場合は、アプリケーションが同じリソースに要求を送信するのを防ぎ、すぐにエラーを報告することをお勧めします。 一定時間が経過した後で、アプリケーションは、試しに 1 つまたは複数の要求を送信して、それらが正常に実行されるかどうかを確認できます。 この戦略の詳細については、「 サーキット ブレーカー パターン」を参照してください。
冪等性
操作がべき等であるかどうかを判断します。 その場合、再試行は本質的に安全です。 それ以外の場合、再試行によって操作を複数回実行すると、意図しない副作用が発生する可能性があります。 たとえば、サービスは要求を受信して要求を正常に処理したが、応答の送信に失敗したとします。 その時点で、再試行ロジックは、最初の要求が受信されなかったと仮定して、要求を再送信する可能性があります。
例外の種類
サービスへの要求は、エラーの性質に応じて異なる例外を発生させるさまざまな理由で失敗する可能性があります。 一部の例外はすぐに解決できる障害を示し、一部の例外は継続時間が長い障害を示します。 再試行ポリシーでは、再試行間隔を例外の種類に基づいて調整すると便利です。
トランザクションの一貫性
トランザクションの一部である操作の再試行がトランザクションの全体的な一貫性に与える影響を検討します。 成功の確率を最大化し、トランザクションのすべてのステップを元に戻す必要性を軽減するように、トランザクション操作の再試行ポリシーを微調整します。
一般的なガイダンス
すべての再試行コードが、さまざまなエラー状態に対して完全にテストされていることを確認します。 アプリケーションのパフォーマンスや信頼性に重大な影響を与えたり、サービスやリソースに過剰な負荷がかかったり、競合状態やボトルネックが発生したりしていないことを確認します。
再試行ロジックは、失敗した操作の完全なコンテキストを理解できる場所のみに実装します。 たとえば、再試行ポリシーを含むタスクが、同じように再試行ポリシーを含む別のタスクを呼び出すと、再試行の追加によって、処理の待ち時間がさらに長くなる可能性があります。 下位レベルのタスクはフェイル ファストするように構成し、呼び出し元のタスクに失敗の理由を報告するほうが適している場合があります。 上位レベルのタスクは、独自のポリシーに基づいて障害を処理できます。
再試行の原因となるすべての接続障害をログに記録し、アプリケーション、サービス、またはリソースの根本的な問題を特定できるようにします。
サービスまたはリソースで最も発生する可能性がある障害を調べて、それらの障害が長く続くか末期的になる可能性があるかどうかを判断します。 該当する場合は、障害を例外として処理することをお勧めします。 アプリケーションは、例外を報告するかログに記録した後、別のサービスを呼び出す (使用可能なものがある場合) か、機能を低下させることで、続行することを試行できます。 長く続く障害を検出して処理する方法の詳細については、「サーキット ブレーカー パターン」を参照してください。
このパターンを使用する状況
このパターンは、アプリケーションがリモート サービスと対話するかリモート リソースにアクセスするときに、一時的な障害が発生する可能性がある場合に使用します。 このような障害は長く続かないことが予想されるため、失敗した要求を繰り返し試行すれば成功する可能性があります。
以下の場合は、このパターンの使用は適していません。
- 障害が長く続きそうな場合。これは、アプリケーションの応答性に影響する可能性があるためです。 失敗する可能性が高い要求を繰り返し試行すると、アプリケーションが時間とリソースを無駄に費やすことになる可能性があります。
- 一時的な障害が原因ではない障害 (アプリケーションのビジネス ロジックのエラーが原因で発生する内部例外など) を処理するため。
- システムのスケーラビリティの問題に対応するための代替方法として。 アプリケーションでビジーフォールトが頻繁に発生する場合、多くの場合、アクセス対象のサービスまたはリソースをスケールアップする必要があることを示す兆候です。
ワークロード設計
設計者は、Azure Well-Architected Framework の柱で説明されている目標と原則に対処するために、ワークロードの設計でどのように再試行パターンを使用できるかを評価する必要があります。 次に例を示します。
| 柱 | このパターンが柱の目標をサポートする方法 |
|---|---|
| 信頼性 設計の決定により、ワークロードが 誤動作 に対して復元力を持ち、障害発生後も完全に機能する状態に 回復 することができます。 | 分散システムの一時的な障害を軽減することが、ワークロードの回復性を高めるための中核的な手法となります。 - RE:07 自己保護 - RE:07 一時的な障害 |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
例
再試行メカニズムのサポートが組み込まれた Azure SDK を使用した詳細な例については、「.NET を使用した再試行ポリシーの実装」ガイドを参照してください。
次のステップ
カスタム再試行ロジックを記述する前に、Polly (.NET の場合)、Resilience4j (Java の場合) などの一般的なフレームワークを使用することを検討してください。
ビジネス データを変更するコマンドを処理する場合は、再試行によってアクションが 2 回実行される可能性があることに注意してください。そのアクションが顧客のクレジットカードへの請求のようなものである場合に問題が発生する可能性があります。 このブログ投稿に記載されている冪等性パターンを使用すると、このような状況に対処できます。
関連リソース
信頼性の高い Web アプリ パターンでは、クラウドに収束する Web アプリケーションに再試行パターンを適用する方法を示します。
Azure サービスのほとんどについて、クライアント SDK に組み込みの再試行ロジックが含まれています。
サーキットブレーカーパターン。 障害が長く続くことが予想される場合は、サーキット ブレーカー パターンを実装するほうが適切である可能があります。 再試行パターンとサーキット ブレーカー パターンを組み合わせることで、障害を処理するための包括的なアプローチが提供されます。