新しい vFXT クラスターを作成した後、最初のタスクとしてデータを Azure の新しいストレージ ボリュームに移動する場合があります。 ただし、通常のデータ移動方法が 1 つのクライアントからシンプルなコピー コマンドを発行する方法である場合は、コピーのパフォーマンスが低下する可能性があります。 シングル スレッドのコピー処理は、Avere vFXT クラスターのバックエンド ストレージにデータをコピーするために適したオプションではありません。
Avere vFXT for Azure クラスターはスケーラブルなマルチクライアント キャッシュであるため、それにデータをコピーする最速かつ最も効率的な方法は、複数のクライアントを使用することです。 この方法では、ファイルとオブジェクトの取り込みが並列化されます。
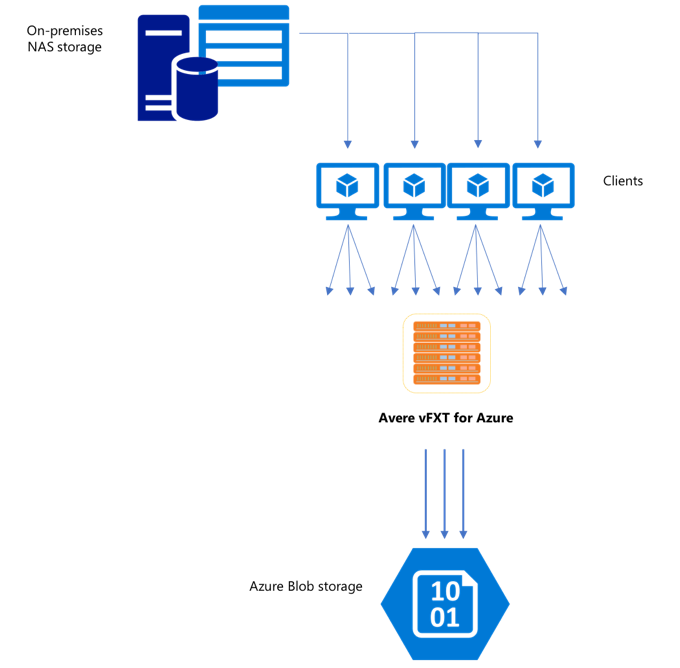
1 つのストレージ システムから別のストレージ システムにデータを転送するためによく使われる cp または copy コマンドは、一度に 1 つのファイルだけをコピーするシングルスレッドのプロセスです。 つまり、一度に 1 つのファイルしかファイル サーバーに取り込まれません。これでは、クラスターのリソースを浪費してしまいます。
この記事では、Avere vFXT クラスターにデータを移動するための、マルチクライアント、マルチスレッドのファイル コピー システムを作成する方法について説明します。 複数のクライアントとシンプルなコピー コマンドを使ってデータを効率よくコピーするために使用できる、ファイル転送の概念と決定点について説明します。
便利なユーティリティについても説明します。 msrsync ユーティリティを使用すると、データセットを複数のバケットに分割したうえで rsync コマンドを使用するというプロセスを部分的に自動化できます。 もう 1 つ、parallelcp スクリプトというユーティリティがあります。これはソース ディレクトリを読み取り、自動的にコピー コマンドを発行するユーティリティです。 また、rsync ツールを 2 フェーズで使用して、データの一貫性を維持しながら、より迅速なコピーを提供することができます。
リンクをクリックすると、そのセクションに移動します。
- 手動コピーの例 - コピー コマンドの使用に関する詳しい説明
- 2 フェーズでの rsync の例
- 部分的な自動化 (msrsync) の例
- 並列コピーの例
データ インジェスター VM のテンプレート
この記事で説明する並列データ取り込みツールを使用して VM を自動的に作成する Resource Manager テンプレートを、GitHub で入手できます。
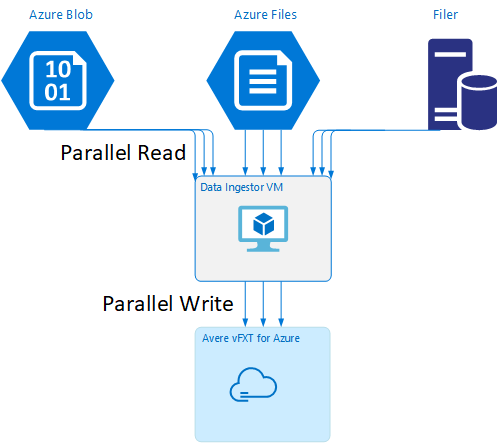
データ インジェスター VM はチュートリアルの一部になっています。そのチュートリアルでは、新しく作成した VM を Avere vFXT クラスターにマウントし、データ インジェスター VM のブートストラップ スクリプトをクラスターからダウンロードします。 詳細については、「Bootstrap a data ingestor VM」 (データ インジェスター VM のブートストラップ) を参照してください。
戦略的計画
データを並列コピーするための戦略を設計するときは、ファイルのサイズ、ファイルの数、ディレクトリの深さにおけるトレードオフを理解する必要があります。
- ファイルが小さいとき、注目すべきメトリックは 1 秒あたりのファイル数です。
- ファイルが大きい場合 (10 MiBi 以上)、注目すべきメトリックは 1 秒あたりのバイト数です。
コピー プロセスごとにスループット率とファイル転送された率が示されます。これらは、コピー コマンドの長さのタイミングを計り、ファイル サイズとファイル数を考慮することによって、測定できます。 それらの測定方法についての説明は、このドキュメントの範囲外ですが、小さいファイルを処理するのか、大きいファイルを処理するのかを把握することが重要です。
手動コピーの例
クライアント上で、マルチスレッドのコピーを手動で作成できます。そのためには、定義済みのファイル セットまたはパスのセットに対して、一度に複数のコピー コマンドをバックグラウンドで実行します。
Linux または UNIX の cp コマンドには、所有権と mtime メタデータを保持するための引数 -p があります。 この引数の以下のコマンドへの追加はオプションです。 (引数を追加すると、メタデータを変更するためにクライアントからコピー先ファイルシステムに送信されるファイルシステム呼び出し数が増えます。)
このシンプルな例では、2 つのファイルを並列コピーします。
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
このコマンドの発行後、jobs コマンドによって、2 つのスレッドが実行されていることが表示されます。
ファイル名の構造が予測可能な場合
ファイル名が予測可能な場合は、式を使用して並列コピー スレッドを作成できます。
たとえば、ディレクトリに 1,000 個のファイルが含まれていて、それらのファイルに 0001 から 1000 まで順番に番号が付いている場合は、次の式を使用して、それぞれが 100 個のファイルをコピーする並列スレッドを 10 個作成できます。
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
ファイル名の構造が不明な場合
ファイルの命名構造が予測可能でない場合は、ファイルをディレクトリ名別にグループ化できます。
この例では、各ディレクトリ全体を収集し、バックグラウンド タスクとして実行される cp コマンドに送ります。
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
ファイルを収集した後、並列コピー コマンドを実行して、サブディレクトリと各サブディレクトリの内容をすべて再帰的にコピーします。
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
マウント ポイントを追加するタイミング
1 つのコピー先ファイル システム マウント ポイントに対して十分な数の並列スレッドを作成した後、ある時点から、それ以上スレッドを追加してもスループットが上がらなくなります。 (スループットは、データの種類に応じて、1 秒あたりのファイル数または 1 秒あたりのバイト数の単位で測定されます。) または、さらに悪いことに、スレッド数が過剰になると、スループットが低下する場合もあります。
この場合、同じリモート ファイルシステム マウント パスを使用して、クライアント側のマウント ポイントを他の vFXT クラスター IP アドレスに追加できます。
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
クライアント側のマウント ポイントを追加することで、追加のコピー コマンドを追加の /mnt/destination[1-3] マウント ポイントにフォークすることができるため、さらに高い並列度を実現できます。
たとえば、ファイルが非常に大きい場合は、個別のコピー先パスを使用するようにコピー コマンドを定義して、コピーを実行するクライアントから、より多くのコマンドを同時に送信します。
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
上記の例では、3 つのコピー先マウント ポイントすべてが、クライアントのファイル コピー プロセスのターゲットになっています。
クライアントを追加するタイミング
最後に、クライアントの機能の上限に達した場合、コピー スレッドまたはマウント ポイントをそれ以上追加しても、1 秒あたりのファイル数または 1 秒あたりのバイト数がさらに増加することはありません。 そのような状況では、同じマウント ポイント セットを持つ別のクライアントをデプロイして、そのクライアント独自のファイル コピー プロセスのセットを実行できます。
例:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
ファイル マニフェストの作成
上記のアプローチ (コピー先あたり複数のコピー スレッド、クライアントあたり複数のコピー先、ネットワーク アクセス可能なソース ファイルシステムあたり複数のクライアント) を理解したら、この推奨事項を検討してください。つまり、ファイル マニフェストを作成し、作成したマニフェストを複数のクライアント全体でコピー コマンドと一緒に使用します。
このシナリオでは UNIX の find コマンドを使用して、ファイルまたはディレクトリのマニフェストを作成します。
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
この結果を次のようにしてファイルにリダイレクトします: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
その後は、マニフェストを通して反復処理ができます。BASH コマンドを使用してファイルを数え、サブディレクトリのサイズを決定します。
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
最後に、クライアントへの実際のファイル コピー コマンドを作成する必要があります。
4 つのクライアントがある場合は、このコマンドを使用します。
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
5 つのクライアントがある場合は、次のようにします。
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
6 つの場合は...必要に応じて推定してください。
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
結果として N 個のファイルを取得できます (find コマンドの出力の一部として取得したレベル 4 のディレクトリへのパス名を持つ、N 個のクライアントごとに 1 つずつ)。
各ファイルを使用してコピー コマンドを作成します。
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
上記のようにして N 個のファイルを取得できます。各ファイルには 1 行あたり 1 個のコピー コマンドが含まれ、それらをクライアント上で BASH スクリプトとして実行できます。
目標は、これらのスクリプトのスレッドを複数のクライアント上で、クライアントごとに並行して複数同時に実行することです。
2 フェーズでの rsync プロセスを使用する
標準の rsync ユーティリティでは、データの整合性を保証するために多数のファイル作成および名前変更操作が生成されるため、これは Avere vFXT for Azure システムを通じたクラウド ストレージの設定には適切に機能しません。 ただし、その後にファイルの整合性をチェックする 2 回目の実行を行う場合は、rsync と共に --inplace オプションを安全に使用して、より慎重なコピー手順は省略できます。
標準の rsync のコピー操作では、一時ファイルを作成して、そこにデータを格納します。 データ転送が正常に完了すると、一時ファイルの名前が元のファイル名に変更されます。 この方法では、コピー中にファイルにアクセスする場合であっても、整合性が保証されます。 ただし、この方法では、より多くの書き込み操作が生成されるため、キャッシュ内でのファイルの移動速度が低下します。
オプション --inplace を指定すると、新しいファイルが最終的な場所に直接書き込まれます。 転送中のファイルの整合性は保証されませんが、後から使用するためにストレージ システムを準備しているのであれば、そのことは重要ではありません。
2番目の rsync 操作は、最初の操作での整合性チェックとして機能します。 ファイルは既にコピーされているため、2 番目のフェーズはクイック スキャンであり、コピー先のファイルが元のファイルと一致することを確認します。 ファイルが一致しない場合は、再コピーが行われます。
次の 1 つのコマンドで、両方のフェーズを同時に発行できます。
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
この方法は、内部ディレクトリ マネージャーによって処理可能なファイル数までのデータセットに対しては、単純かつ時間効率の高い方法です (これは通常、3 ノード クラスターに対しては 2 億ファイル、6 ノード クラスタに対しては 5 億ファイルなどとなります)。
msrsync ユーティリティを使用する
msrsync ツールも、Avere クラスターのバックエンド コア ファイラーへのデータ移動に使用できます。 このツールは、複数の rsync プロセスを並列実行して帯域幅の使用を最適化することを目的に設計されています。 GitHub (https://github.com/jbd/msrsync) で入手できます。
msrsync では、ソース ディレクトリを別々の "バケット" に分割したうえで、個々の rsync プロセスを各バケットに対して実行します。
4 コアの VM を使用した予備テストでは、64 個のプロセスを使用したときに最適な効率が示されました。 msrsync の -p オプションを使用して、プロセスの数を 64 に設定します。
また、msrsync コマンドと共に --inplace 引数を使用することもできます。 このオプションを使用する場合は、での 2 番目のコマンド (前述の rsyncと同様に) を実行してデータの整合性を保証することを考慮してください。
msrsync では、ローカル ボリュームにおける書き込みと書き出しのみが可能です。 ソースとコピー先は、クラスターの仮想ネットワーク内のローカル マウントとしてアクセス可能である必要があります。
msrsync を使用して Avere クラスターに Azure クラウド ボリュームを設定するには、次の手順に従います。
msrsyncとその前提条件 (rsync および Python 2.6 以降) をインストールします。コピーするファイルおよびディレクトリの合計数を確認します。
たとえば、引数
prime.py --directory /path/to/some/directoryを指定した Avere ユーティリティprime.pyを使用します (https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py の URL から、ダウンロードして入手できます)。prime.pyを使用しない場合は、次のように GNU のfindツールを使用して項目数を計算できます。find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)項目の数を 64 で除算してプロセスごとの項目数を決定します。 この数字を
-fオプションに指定して、コマンドを実行するときのバケットのサイズを設定します。msrsyncコマンドを発行してファイルをコピーします。msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>--inplaceを使用する場合は、データが正しくコピーされていることをチェックするオプションを指定せずに、2 番目の実行を追加します。msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>たとえば、このコマンドは /test/source-repository から /mnt/vfxt/repository に 64 プロセスで 11,000 ファイルを移動するように指定されています。
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
並列コピー スクリプトの使用
parallelcp スクリプトは、vFXT クラスターのバックエンド ストレージにデータを移動するのにも便利です。
次のスクリプトでは、実行可能な parallelcp を追加します。 (このスクリプトは Ubuntu 用に作成されています。別のディストリビューションを使用する場合は、parallel を別途インストールする必要があります。)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
並列コピーの例
この例では、並列コピー スクリプトを使用して glibc をコンパイルします。Avere クラスターにあるソース ファイルを使用しています。
ソース ファイルは Avere クラスターのマウント ポイントに格納され、オブジェクト ファイルはローカル ハード ドライブに格納されます。
このスクリプトでは、上記の並列コピー スクリプトを使用しています。 -j オプションを parallelcp と make で使用して、並列処理を行います。
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j