Azure SQL トリガーでは SQL 変更の追跡機能を使用して SQL テーブルの変更を監視し、行の作成、更新、または削除時に関数をトリガーします。 Azure SQL トリガーで使用する変更追跡の構成について詳しくは、「変更の追跡を設定する」を参照してください。 Azure Functions 用 Azure SQL 拡張機能のセットアップについて詳しくは、SQL バインディングの概要に関するページを参照してください。
従量課金プランと Premium プランの Azure SQL トリガースケーリングの決定は、ターゲット ベースのスケーリングによって行われます。 詳細については、「 ターゲットベースのスケーリング 」を参照し、 Azure Functions ホスティング オプションを確認してください。
注
従量課金プランのサポートには、Azure Functions 用の Azure SQL バインドのリリース v3.1.284 以降が必要です。
機能の概要
Azure SQL トリガー バインドは、ポーリング ループを使用して変更を確認し、変更が検出されたときにユーザー関数をトリガーします。 ループは、おおまかには次のようなものです。
while (true) {
1. Get list of changes on table - up to a maximum number controlled by the Sql_Trigger_MaxBatchSize setting
2. Trigger function with list of changes
3. Wait for delay controlled by Sql_Trigger_PollingIntervalMs setting
}
変更は、変更が行われた順序で処理され、最も古い変更が最初に処理されます。 変更処理に関するいくつかの注意事項:
- 複数の行に対する変更が一度に行われる場合、関数に送信される正確な順序は、CHANGETABLE 関数によって返される順序に基づいています
- 変更は、行ごとにまとめて "バッチ処理" されます。 ループの各反復の間に複数の変更が行われた場合、その行に対して 1 つの、最後に処理された状態と現在の状態との違いを示す変更エントリのみが作成されます
- 一連の行に変更が加えられた後で、同じそれらの行の半分に別の一連の変更が加えられた場合、2 回めに変更されなかった半分の行が先に処理されます。 この処理ロジックは、変更が一括処理されるという上記の注意事項によるものです。トリガーは、加えられた "最後の" 変更のみを認識し、処理する順序についてそれを使用します
注
Azure SQLの変更追跡は、Always EncryptedやTransparent Data Encryption(TDE)などの暗号化技術を用いたテーブルの行レベルの変更を検出できます。 しかし、Azure SQLトリガーは変更ペイロード内の暗号化された列値を復号または公開しません。 トリガーは変更があったことを検出できますが、その列の復号データにはアクセスできません。
変更の追跡と、Azure SQL トリガーなどのアプリケーションでのその使用方法の詳細については、「変更の追跡のしくみ」を参照してください。
重要
最適なセキュリティを実現するために、Functions と Azure SQL Database の間の接続には、マネージド ID と共に Microsoft Entra ID を使用する必要があります。 マネージド ID は、接続文字列の資格情報、サーバー名、使用されているポートなど、アプリケーションのデプロイからシークレットを排除することで、アプリの安全性を高めます。 マネージド ID の使用方法については、このチュートリアルの「 マネージド ID と SQL バインドを使用して関数アプリを Azure SQL に接続する。
使用例
Azure SQL トリガーのその他のサンプルは、GitHub リポジトリで入手できます。
次の例は、ToDoItem クラスとそれに対応するデータベース テーブルを示しています。
namespace AzureSQL.ToDo
{
public class ToDoItem
{
public Guid Id { get; set; }
public int? order { get; set; }
public string title { get; set; }
public string url { get; set; }
public bool? completed { get; set; }
}
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
変更の追跡は、データベースとテーブルで有効になります。
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
SQL トリガーは、それぞれ 2 つのプロパティを持つ IReadOnlyList<SqlChange<T>> オブジェクトの一覧である SqlChange にバインドされます。
-
項目: 変更された項目。 項目の型は、
ToDoItemクラスに示されているようにテーブル スキーマに従う必要があります。 -
操作:
SqlChangeOperation列挙型からの値。 設定可能な値はInsert、Update、Deleteです。
次の例は、 テーブルに変更がある場合に呼び出される ToDoを示しています。
using System;
using System.Collections.Generic;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Extensions.Sql;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
namespace AzureSQL.ToDo
{
public static class ToDoTrigger
{
[Function("ToDoTrigger")]
public static void Run(
[SqlTrigger("[dbo].[ToDo]", "SqlConnectionString")]
IReadOnlyList<SqlChange<ToDoItem>> changes,
FunctionContext context)
{
var logger = context.GetLogger("ToDoTrigger");
foreach (SqlChange<ToDoItem> change in changes)
{
ToDoItem toDoItem = change.Item;
logger.LogInformation($"Change operation: {change.Operation}");
logger.LogInformation($"Id: {toDoItem.Id}, Title: {toDoItem.title}, Url: {toDoItem.url}, Completed: {toDoItem.completed}");
}
}
}
}
使用例
Azure SQL トリガーのその他のサンプルは、GitHub リポジトリで入手できます。
次の例では、ToDoItem クラス、SqlChangeToDoItem クラス、SqlChangeOperation 列挙型と、それに対応するデータベース テーブルを参照します。
別個のファイル ToDoItem.java で、次のように指定します。
package com.function;
import java.util.UUID;
public class ToDoItem {
public UUID Id;
public int order;
public String title;
public String url;
public boolean completed;
public ToDoItem() {
}
public ToDoItem(UUID Id, int order, String title, String url, boolean completed) {
this.Id = Id;
this.order = order;
this.title = title;
this.url = url;
this.completed = completed;
}
}
別個のファイル SqlChangeToDoItem.java で、次のように指定します。
package com.function;
public class SqlChangeToDoItem {
public ToDoItem item;
public SqlChangeOperation operation;
public SqlChangeToDoItem() {
}
public SqlChangeToDoItem(ToDoItem Item, SqlChangeOperation Operation) {
this.Item = Item;
this.Operation = Operation;
}
}
別個のファイル SqlChangeOperation.java で、次のように指定します。
package com.function;
import com.google.gson.annotations.SerializedName;
public enum SqlChangeOperation {
@SerializedName("0")
Insert,
@SerializedName("1")
Update,
@SerializedName("2")
Delete;
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
変更の追跡は、データベースとテーブルで有効になります。
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
SQL トリガーは、それぞれ 2 つのプロパティを持つ SqlChangeToDoItem[] オブジェクトの配列である SqlChangeToDoItem にバインドされます。
-
項目: 変更された項目。 項目の型は、
ToDoItemクラスに示されているようにテーブル スキーマに従う必要があります。 -
操作:
SqlChangeOperation列挙型からの値。 設定可能な値はInsert、Update、Deleteです。
次の例は、ToDo テーブルに変更がある場合に呼び出される Java 関数を示しています。
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.sql.annotation.SQLTrigger;
import com.function.Common.SqlChangeToDoItem;
import com.google.gson.Gson;
import java.util.logging.Level;
public class ProductsTrigger {
@FunctionName("ToDoTrigger")
public void run(
@SQLTrigger(
name = "todoItems",
tableName = "[dbo].[ToDo]",
connectionStringSetting = "SqlConnectionString")
SqlChangeToDoItem[] todoItems,
ExecutionContext context) {
context.getLogger().log(Level.INFO, "SQL Changes: " + new Gson().toJson(changes));
}
}
使用例
Azure SQL トリガーのその他のサンプルは、GitHub リポジトリで入手できます。
この例では、ToDoItem データベース テーブルを参照します。
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
変更の追跡は、データベースとテーブルで有効になります。
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
SQL トリガーは、それぞれ 2 つのプロパティを持つオブジェクトの一覧である todoChanges にバインドされます。
- 項目: 変更された項目。 項目の構造は、テーブル スキーマに従います。
-
操作: 使用可能な値は、
Insert、Update、およびDeleteです。
次の例は、ToDo テーブルに変更がある場合に呼び出される PowerShell 関数を示しています。
function.json ファイルのバインド データを次に示します。
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
これらのプロパティについては、「構成」セクションを参照してください。
run.ps1 ファイル内の関数の PowerShell コードの例を次に示します。
using namespace System.Net
param($todoChanges)
# The output is used to inspect the trigger binding parameter in test methods.
# Use -Compress to remove new lines and spaces for testing purposes.
$changesJson = $todoChanges | ConvertTo-Json -Compress
Write-Host "SQL Changes: $changesJson"
使用例
Azure SQL トリガーのその他のサンプルは、GitHub リポジトリで入手できます。
この例では、ToDoItem データベース テーブルを参照します。
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
変更の追跡は、データベースとテーブルで有効になります。
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
SQL トリガーは、それぞれ 2 つのプロパティを持つオブジェクトの配列である todoChanges をバインドします。
- 項目: 変更された項目。 項目の構造は、テーブル スキーマに従います。
-
操作: 使用可能な値は、
Insert、Update、およびDeleteです。
次の例は、ToDo テーブルに変更がある場合に呼び出される JavaScript 関数を示しています。
function.json ファイルのバインド データを次に示します。
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
これらのプロパティについては、「構成」セクションを参照してください。
index.js ファイル内の関数の JavaScript コードの例を次に示します。
module.exports = async function (context, todoChanges) {
context.log(`SQL Changes: ${JSON.stringify(todoChanges)}`)
}
使用例
Azure SQL トリガーのその他のサンプルは、GitHub リポジトリで入手できます。
この例では、ToDoItem データベース テーブルを参照します。
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
変更の追跡は、データベースとテーブルで有効になります。
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
SQL トリガーは、それぞれ 2 つのプロパティを持つオブジェクトの一覧である変数 todoChanges にバインドされます。
- 項目: 変更された項目。 項目の構造は、テーブル スキーマに従います。
-
操作: 使用可能な値は、
Insert、Update、およびDeleteです。
次の例は、ToDo テーブルに変更がある場合に呼び出される Python 関数を示しています。
function_app.py ファイルの Python コードの例を次に示します。
import json
import logging
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="ToDoTrigger")
@app.sql_trigger(arg_name="todo",
table_name="ToDo",
connection_string_setting="SqlConnectionString")
def todo_trigger(todo: str) -> None:
logging.info("SQL Changes: %s", json.loads(todo))
属性
C# ライブラリでは SqlTrigger 属性を使用して、次のプロパティを持つ関数で SQL トリガーを宣言します。
| 属性のプロパティ | 説明 |
|---|---|
| テーブル名 | 必須。 トリガーによって監視されるテーブルの名前。 |
| ConnectionStringSetting | 必須。 変更が監視されるテーブルを含むデータベースの接続文字列を含むアプリ設定の名前。 接続文字列設定名は、Azure SQL または SQL Server インスタンスへの接続のlocal.settings.jsonが含まれるアプリケーション設定 (ローカル開発の場合は の) に合致します。 |
| LeasesTableName | 省略可能。 リースの保存のために使用するテーブルの名前。 指定しない場合、リース テーブル名は Leases_{FunctionId}_{TableId} になります。 この生成方法の詳細については、 こちら を参照してください。 |
注釈
Java 関数ランタイム ライブラリで、その値が Azure SQL に由来するパラメーター上で @SQLTrigger 注釈 (com.microsoft.azure.functions.sql.annotation.SQLTrigger) を使用します。 この注釈は、次の要素をサポートします。
| 要素 | 説明 |
|---|---|
| 名前 | 必須。 トリガーのバインド先パラメーターの名前。 |
| tableName | 必須。 トリガーによって監視されるテーブルの名前。 |
| connectionStringSetting | 必須。 変更が監視されるテーブルを含むデータベースの接続文字列を含むアプリ設定の名前。 接続文字列設定名は、Azure SQL または SQL Server インスタンスへの接続のlocal.settings.jsonが含まれるアプリケーション設定 (ローカル開発の場合は の) に合致します。 |
| LeasesTableName | 省略可能。 リースの保存のために使用するテーブルの名前。 指定しない場合、リース テーブル名は Leases_{FunctionId}_{TableId} になります。 この生成方法の詳細については、 こちら を参照してください。 |
構成
次の表は、function.json ファイルで設定したバインド構成のプロパティを説明しています。
| function.json のプロパティ | 説明 |
|---|---|
| 名前 | 必須。 トリガーのバインド先パラメーターの名前。 |
| タイプ | 必須。
sqlTrigger に設定する必要があります。 |
| 方向 | 必須。
in に設定する必要があります。 |
| tableName | 必須。 トリガーによって監視されるテーブルの名前。 |
| connectionStringSetting | 必須。 変更が監視されるテーブルを含むデータベースの接続文字列を含むアプリ設定の名前。 接続文字列設定名は、Azure SQL または SQL Server インスタンスへの接続のlocal.settings.jsonが含まれるアプリケーション設定 (ローカル開発の場合は の) に合致します。 |
| LeasesTableName | 省略可能。 リースの保存のために使用するテーブルの名前。 指定しない場合、リース テーブル名は Leases_{FunctionId}_{TableId} になります。 この生成方法の詳細については、 こちら を参照してください。 |
オプションの構成
ローカル開発またはクラウド デプロイ用の SQL トリガーに対して、次のオプションの設定を構成できます。
host.json
このセクションでは、バージョン 2.x 以降でこのバインドに使用できる構成設定について説明します。 host.json ファイルの設定は、関数アプリ インスタンスのすべての関数に適用されます。 関数アプリの構成設定の詳細については、 Azure Functions のhost.json リファレンスを参照してください。
| 設定 | 既定値 | 説明 |
|---|---|---|
| MaxBatchSize | 100 | トリガーされた関数に送信される前に、トリガー ループの各イテレーションで処理される変更の最大数。 |
| PollingIntervalMs | 1000 | 変更の各バッチを処理するまでの遅延 (ミリ秒単位)。 (1000 ミリ秒は 1 秒) |
| MaxChangesPerWorker | 1000 | アプリケーション ワーカーごとに許可されるユーザー テーブル内の保留中の変更の数の上限。 変更の数がこの制限を超えると、スケールアウトが発生する可能性があります。この設定は、ランタイム駆動型スケーリングが有効な Azure 関数アプリにのみ適用されます。 |
host.json ファイルの例
省略可能な設定を含むhost.json ファイルの例を次に示します。
{
"version": "2.0",
"extensions": {
"Sql": {
"MaxBatchSize": 300,
"PollingIntervalMs": 1000,
"MaxChangesPerWorker": 100
}
},
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
},
"logLevel": {
"default": "Trace"
}
}
}
local.setting.json
local.settings.json ファイルには、アプリの設定、およびローカルの開発ツールによって使用される設定が格納されます。 local.settings.json ファイル内の設定は、プロジェクトをローカルで実行している場合にのみ使用されます。 プロジェクトを Azure に発行するときは、関数アプリのアプリ設定にも必要な設定を必ず追加してください。
重要
local.settings.json には接続文字列などのシークレットが含まれている場合があるため、リモート リポジトリには絶対に格納しないようにしてください。 Functions をサポートするツールを使用すると、local.settings.json ファイル内の設定を、プロジェクトをデプロイしている関数アプリのアプリ設定と同期できます。
| 設定 | 既定値 | 説明 |
|---|---|---|
| Sql_Trigger_BatchSize | 100 | トリガーされた関数に送信される前に、トリガー ループの各イテレーションで処理される変更の最大数。 |
| Sql_Trigger_PollingIntervalMs | 1000 | 変更の各バッチを処理するまでの遅延 (ミリ秒単位)。 (1000 ミリ秒は 1 秒) |
| Sql_Trigger_MaxChangesPerWorker | 1000 | アプリケーション ワーカーごとに許可されるユーザー テーブル内の保留中の変更の数の上限。 変更の数がこの制限を超えると、スケールアウトが発生する可能性があります。この設定は、ランタイム駆動型スケーリングが有効な Azure 関数アプリにのみ適用されます。 |
local.settings.json ファイルの例
省略可能な設定を含むlocal.settings.json ファイルの例を次に示します。
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"SqlConnectionString": "",
"Sql_Trigger_MaxBatchSize": 300,
"Sql_Trigger_PollingIntervalMs": 1000,
"Sql_Trigger_MaxChangesPerWorker": 100
}
}
変更の追跡を設定する (必須)
Azure SQL トリガーで使用する変更の追跡を設定するには、2 つの手順が必要です。 これらの手順は、 Visual Studio Code や SQL Server Management Studio など、クエリの実行をサポートする任意の SQL ツールから実行できます。
SQL データベースで変更の追跡を有効にします。
your database nameは、監視対象のテーブルがあるデータベースの名前に置き換えます。ALTER DATABASE [your database name] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);CHANGE_RETENTIONオプションでは、変更の追跡情報 (変更履歴) を保持する期間を指定します。 SQL データベースによる変更履歴の保持は、トリガー機能に影響する可能性があります。 たとえば、Azure 関数が数日間オフになってから再開された場合、データベースには、上記の設定例を使用して過去 2 日間に発生した変更が含まれます。AUTO_CLEANUPオプションは、古い変更の追跡情報を削除するクリーンアップ タスクを有効または無効にするために使用されます。 トリガーの実行を妨げる一時的な問題の場合は、自動クリーンアップをオフにすると、問題が解決されるまで保有期間より前の情報の削除を一時停止するのに役立つことがあります。変更の追跡オプションについて詳しくは、SQL ドキュメントを参照してください。
テーブルの変更追跡を有効にします。
your table nameは監視対象のテーブルの名前に置き換えます (必要に応じて、スキーマを変更します)。ALTER TABLE [dbo].[your table name] ENABLE CHANGE_TRACKING;トリガーには、変更の監視対象のテーブルと変更の追跡システム テーブルに対する読み取りアクセス権が必要です。 各関数トリガーには、スキーマ
az_func内の変更の追跡テーブルとリース テーブルが関連付けられています。 これらのテーブルは、まだ存在しない場合、トリガーによって作成されます。 これらのデータ構造の詳細については、Azure SQL バインド ライブラリのドキュメントを参照してください。
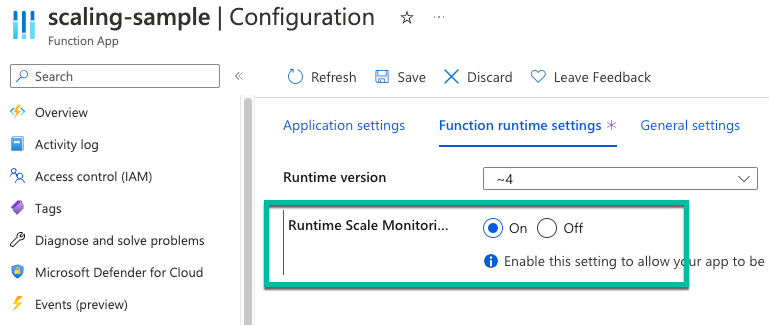
ランタイム駆動型スケーリングを有効にする
必要に応じて、関数は、ユーザー テーブルで処理される保留中の変更の数に基づいて自動的にスケーリングできます。 SQL トリガーを使用するときに関数が Premium プランで適切にスケーリングできるようにするには、ランタイム スケールの監視を有効にする必要があります。
Azure portal の関数アプリで、[ 構成] を選択します。
[ 関数ランタイム設定 ] タブの [ ランタイム スケール監視] で、[オン] を選択します。
再試行のサポート
SQL トリガーの再試行のサポートとリース テーブルの詳細については、GitHub リポジトリを参照してください。
スタートアップの再試行
スタートアップ時に例外が発生した場合、ホスト ランタイムでは、エクスポネンシャル バックオフ戦略を使用してトリガー リスナーの再起動を自動的に試みます。 これらの再試行は、リスナーが正常に開始されるか、スタートアップが取り消されるまで続行します。
切断した接続の再試行
関数が正常に起動したが、その後エラーが発生して接続が切断された場合 (サーバーがオフラインになるなど)、関数が停止するか、接続が成功するまで、関数は接続の再開を試行し続けます。 接続が正常に再確立されると、中断した場所で処理の変更が取得されます。
これらの再試行は、ConnectRetryCountオプションとConnectRetryInterval接続文字列 オプションを使用して構成できる SqlClient が持つ組み込みのアイドル接続再試行ロジックの外部にあることに注意してください。 組み込みのアイドル接続の再試行が最初に試行され、再接続に失敗した場合、トリガー バインドにより接続自体の再確立が試行されます。
関数の例外の再試行
変更の処理中にユーザー関数で例外が発生した場合、現時点で処理されている行のバッチが 60 秒後に再試行されます。 その他の変更は、この期間中は通常どおり処理されますが、例外の原因となったバッチ内の行は、タイムアウト期間が経過するまで無視されます。
特定の行に対して関数の実行が行あたり 5 回失敗した場合、その行は今後のすべての変更で完全に無視されます。 バッチ内の行は決定論的ではないので、失敗したバッチ内の行は、後続の呼び出しで異なるバッチになる可能性があります。 これは、失敗したバッチ内のすべての行が必ずしも無視されるわけではないことを意味します。 バッチ内の他の行が例外の原因であった場合、"問題のない" 行が、今後の呼び出しで失敗しない別のバッチに入る可能性があります。