この記事では、Azure Monitor Application Insights for Java を構成する方法について説明します。
詳細については、サンプル アプリケーションを含む「OpenTelemetry の概要」を参照してください。
接続文字列とロール名
接続文字列とロール名は、作業を開始するために必要な最も一般的な設定です。
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
}
}
接続文字列は必須です。 ロール名は、異なるアプリケーションから同じ Application Insights リソースにデータを送信する場合に常に重要です。
詳細と構成オプションについては、以降のセクションをご覧ください。
JSON 構成のセットアップ
既定の構成
デフォルトでは、Application Insights Java 3 は、構成ファイルが applicationinsights.json という名前で、applicationinsights-agent-3.7.1.jar と同じディレクトリに配置されることを期待しています。
代替構成
カスタム構成ファイル
カスタム設定ファイルを指定できます。
- APPLICATIONINSIGHTS_CONFIGURATION_FILE 環境変数、または
- applicationinsights.configuration.file システム プロパティ
相対パスを指定すると、applicationinsights-agent-3.7.1.jarが配置されているディレクトリを基準にして解決されます。
JSON 構成
構成ファイルを使用する代わりに、JSON 構成全体を次のものを使用して設定できます:
- APPLICATIONINSIGHTS_CONFIGURATION_CONTENT 環境変数、または
- applicationinsights.configuration.content システム プロパティ
接続文字列
接続文字列は必須です。 接続文字列は、Application Insights リソースで確認できます。
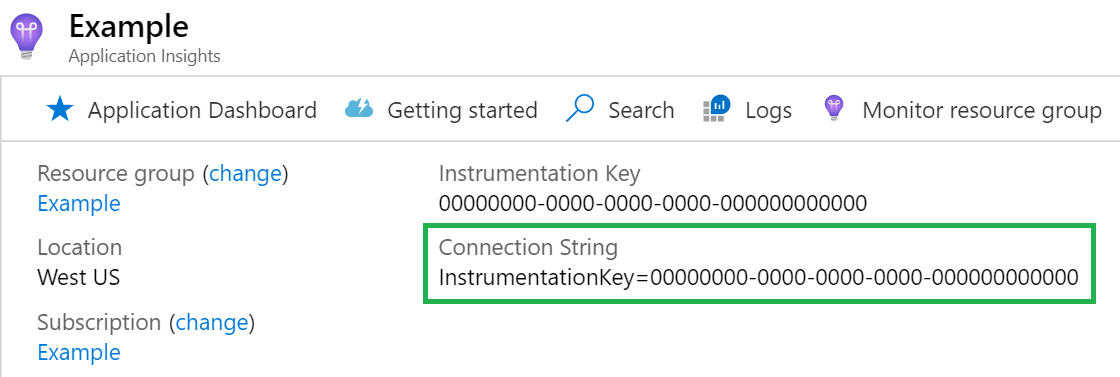
{
"connectionString": "..."
}
環境変数 APPLICATIONINSIGHTS_CONNECTION_STRING を使用して、接続文字列を設定することもできます。 その場合、JSON 構成で指定された接続文字列より優先されます。
または、Java システム プロパティ applicationinsights.connection.string を使用して接続文字列を設定することもできます。 また、これは JSON 構成で指定された接続文字列より優先されます。
接続文字列を読み込むファイルを指定して、接続文字列を設定することもできます。
相対パスを指定すると、applicationinsights-agent-3.7.1.jar があるディレクトリを基準にしてパスが解決されます。
{
"connectionString": "${file:connection-string-file.txt}"
}
ファイルには接続文字列のみが含まれている必要があります。
接続文字列を設定しないと、Java エージェントが無効になります。
同じ Java 仮想マシン (JVM) に複数のアプリケーションがデプロイされており、それらがテレメトリを異なる接続文字列に送信するようにする場合は、「接続文字列のオーバーライド (プレビュー)」を参照してください。
クラウド ロール名
クラウド ロール名は、アプリケーション マップのコンポーネントにラベルを付けるために使用します。
クラウド ロール名を設定する場合:
{
"role": {
"name": "my cloud role name"
}
}
クラウド ロール名が設定されていない場合は、アプリケーション マップのコンポーネントにラベルを付けるために、Application Insights リソースの名前が使用されます。
環境変数 APPLICATIONINSIGHTS_ROLE_NAME を使用して、クラウド ロール名を設定することもできます。 その場合、JSON 構成で指定されたクラウド ロール名より優先されます。
または、Java システム プロパティ applicationinsights.role.name を使用してクラウド ロール名を設定することもできます。 その場合も、JSON 構成で指定されたクラウド ロール名より優先されます。
同じ JVM に複数のアプリケーションがデプロイされていて、テレメトリを別のクラウド ロール名に送信させる場合は、「クラウド ロール名のオーバーライド (プレビュー)」を参照してください。
クラウド ロール インスタンス
クラウド ロール インスタンスの既定値は、コンピューター名です。
クラウド ロール インスタンスをコンピューター名以外のものに設定する場合は、次のように設定します。
{
"role": {
"name": "my cloud role name",
"instance": "my cloud role instance"
}
}
環境変数 APPLICATIONINSIGHTS_ROLE_INSTANCE を使用して、クラウド ロール インスタンスを設定することもできます。 その場合、JSON 構成で指定されたクラウド ロール インスタンスより優先されます。
または、Java システム プロパティ applicationinsights.role.instance を使用してクラウド ロール インスタンスを設定することもできます。
その場合も、JSON 構成で指定されたクラウド ロール インスタンスより優先されます。
サンプリング
メモ
サンプリングは、Application Insights のコストを削減する場合にお勧めの方法です。 ユース ケースに合わせてサンプリング構成を適切に設定してください。
サンプリングは要求に基づきます。つまり、要求がキャプチャ (サンプリング) される場合は、その依存関係、ログ、例外もキャプチャされます。
サンプリングはトレース ID にも基づくため、異なるサービス間で一貫したサンプリングの判断を下すことができます。
サンプリングは、要求内のログにのみ適用されます。 要求内にないログ (スタートアップ ログなど) は常に既定で収集されます。 これらのログをサンプリングする場合は、サンプリング オーバーライドを使用できます。
レート制限付きサンプリング
3.4.0 以降、レート制限付きサンプリングを使用できるようになり、現在は既定値になりました。
サンプリングを構成していない場合、デフォルトのレート制限付きサンプリングでは、毎秒最大で (およそ) 5 つの要求と、それら要求のすべての依存関係およびログのキャプチャが構成されるようになりました。
この構成は、すべての要求をキャプチャするという以前の既定値に置き換わるものです。 今後もすべての要求をキャプチャする必要がある場合は、固定率のサンプリングを使い、サンプリング率を 100 に設定してください。
メモ
レート制限付きサンプリングは概算値です。これは、各テレメトリ レコードで正確な項目カウントを出力するために、内部的に「固定の」サンプリング率を調整する必要があるためです。 レート制限付きサンプリングは、新しいアプリケーションの読み込みにすばやく (0.1 秒) 適合するように内部的に調整されます。 このため、構成されたレートを大幅に超えたり、長時間にわたってそうなることをあまり見かけることはないはずです。
この例では、1 秒間に最大で (およそ) 1 要求をキャプチャするようにサンプリングを設定する方法を示します。
{
"sampling": {
"requestsPerSecond": 1.0
}
}
requestsPerSecond は小数の場合もあります。そのため、必要であれば、1 秒間に 1 未満の要求をキャプチャするように構成することができます。 たとえば、0.5 の値は、2 秒間に最大で 1 つの要求をキャプチャすることを意味します。
環境変数 APPLICATIONINSIGHTS_SAMPLING_REQUESTS_PER_SECOND を使用してサンプリング率を設定することもできます。 その場合、JSON 構成で指定されたレート制限より優先されます。
固定率のサンプリング
この例では、すべての要求の約 3 分の 1 をキャプチャするようにサンプリングを設定する方法を示します。
{
"sampling": {
"percentage": 33.333
}
}
環境変数 APPLICATIONINSIGHTS_SAMPLING_PERCENTAGE を使用してサンプリング率を設定することもできます。 その場合、JSON 構成で指定されたサンプリング率より優先されます。
メモ
サンプリング率には、N を整数として 100/N に近い割合を選択します。 サンプリングでは現在、その他の値はサポートされていません。
サンプリングのオーバーライド
サンプリング オーバーライドを使用すると、既定のサンプリング率をオーバーライドできます。 たとえば、次のように操作できます。
- ノイズの多い正常性チェックでは、サンプリング率を 0 (または小さい値) に設定します。
- ノイズの多い依存関係呼び出しでは、サンプリング率を 0 (または小さい値) に設定します。
- 重要な要求の種類では、サンプリング率を 100 に設定します。 たとえば、既定のサンプリングが低い値に構成されている場合でも、
/loginを使用できます。
詳細については、サンプリング オーバーライドに関するドキュメントを参照してください。
Java Management Extensions のメトリック
他の Java Management Extensions (JMX) メトリックを収集する場合は、次のようにします。
{
"jmxMetrics": [
{
"name": "JVM uptime (millis)",
"objectName": "java.lang:type=Runtime",
"attribute": "Uptime"
},
{
"name": "MetaSpace Used",
"objectName": "java.lang:type=MemoryPool,name=Metaspace",
"attribute": "Usage.used"
}
]
}
上記の構成例では、次のようになっています。
nameは、この JMX メトリックに割り当てられるメトリック名です (何でもかまいません)。objectNameは、収集する のJMX MBeanです。 ワイルドカード文字のアスタリスク (*) がサポートされています。attributeは、収集するJMX MBean内の属性名です。
数値とブール型の JMX メトリック値がサポートされています。 ブール型の JMX メトリックは、false の場合は 0 に、true の場合は 1 にマップされます。
詳細については、JMX メトリックのドキュメントを参照してください。
カスタム ディメンション
すべてのテレメトリにカスタム ディメンションを追加する場合は、次のようにします。
{
"customDimensions": {
"mytag": "my value",
"anothertag": "${ANOTHER_VALUE}"
}
}
${...} を使用すると、起動時に指定した環境変数から値を読み取ることができます。
メモ
バージョン 3.0.2 以降では、service.version という名前のカスタム ディメンションを追加した場合、値はカスタム ディメンションとしてではなく、Application Insights ログ テーブルの application_Version 列に格納されます。
継承された属性 (プレビュー)
バージョン 3.2.0 以降では、要求テレメトリにカスタム ディメンションをプログラムで設定できます。 依存関係とログ テレメトリにより確実に継承されます。 すべてがその要求のコンテキストでキャプチャされます。
{
"preview": {
"inheritedAttributes": [
{
"key": "mycustomer",
"type": "string"
}
]
}
}
次に、各リクエストの開始時に、以下を呼び出します。
Span.current().setAttribute("mycustomer", "xyz");
「スパンにカスタム プロパティを追加する」も参照してください。
接続文字列の上書き設定 (プレビュー)
3.4.0 以降、この機能はプレビュー段階にあります。
接続文字列のオーバーライドを使うと、既定の接続文字列をオーバーライドできます。 たとえば、次のように操作できます。
- 1 つの HTTP パス プレフィックス
/myapp1に対して 1 つの接続文字列を設定します。 - もう 1 つの HTTP パス プレフィックス
/myapp2/に対しては別の接続文字列を設定します。
{
"preview": {
"connectionStringOverrides": [
{
"httpPathPrefix": "/myapp1",
"connectionString": "..."
},
{
"httpPathPrefix": "/myapp2",
"connectionString": "..."
}
]
}
}
クラウド ロール名のオーバーライド (プレビュー)
3.3.0 以降、この機能はプレビュー段階にあります。
クラウド ロール名のオーバーライドを使用すると、既定のクラウド ロール名をオーバーライドできます。 たとえば、次のように操作できます。
- 1 つの HTTP パス プレフィックス
/myapp1に対して 1 つのクラウド ロール名を設定します。 - もう 1 つの HTTP パス プレフィックス
/myapp2/に対しては別のクラウド ロール名を設定します。
{
"preview": {
"roleNameOverrides": [
{
"httpPathPrefix": "/myapp1",
"roleName": "Role A"
},
{
"httpPathPrefix": "/myapp2",
"roleName": "Role B"
}
]
}
}
実行時に構成される接続文字列
バージョン 3.4.8 以降では、実行時に接続文字列を構成する機能が必要な場合は、以下のプロパティを json 設定に追加してください。
{
"connectionStringConfiguredAtRuntime": true
}
アプリケーションに applicationinsights-core を追加します:
<dependency>
<groupId>com.microsoft.azure</groupId>
<artifactId>applicationinsights-core</artifactId>
<version>3.7.1</version>
</dependency>
クラス configure(String) で静的 com.microsoft.applicationinsights.connectionstring.ConnectionString メソッドを使います。
メモ
接続文字列を構成する前にキャプチャされたテレメトリはすべて削除されるため、アプリケーションの起動時にできるだけ早く構成することをお勧めします。
InProc 依存関係の自動収集 (プレビュー)
バージョン 3.2.0 以降で、コントローラーの "InProc" の依存関係をキャプチャする場合は、次の構成を使用してください。
{
"preview": {
"captureControllerSpans": true
}
}
ブラウザー SDK ローダー (プレビュー)
この機能は、ブラウザー SDK ローダーをアプリケーションの HTML ページに自動的に挿入し、適切な接続文字列の構成も含みます。
たとえば、Java アプリケーションが次のような応答を返す場合です。
<!DOCTYPE html>
<html lang="en">
<head>
<title>Title</title>
</head>
<body>
</body>
</html>
次を返すように自動的に変更されます。
<!DOCTYPE html>
<html lang="en">
<head>
<script type="text/javascript">
!function(v,y,T){var S=v.location,k="script"
<!-- Removed for brevity -->
connectionString: "YOUR_CONNECTION_STRING"
<!-- Removed for brevity --> }});
</script>
<title>Title</title>
</head>
<body>
</body>
</html>
このスクリプトは、お客様が Web ユーザー データを追跡し、収集されたサーバー側テレメトリをユーザーの Azure portal に送り返すのを支援することを目的としています。 詳細については、「ApplicationInsights-JS」を参照してください。
この機能を有効にしたい場合は、次の構成オプションを追加します。
{
"preview": {
"browserSdkLoader": {
"enabled": true
}
}
}
テレメトリ プロセッサ (プレビュー)
テレメトリ プロセッサを使用して、要求、依存関係、トレース テレメトリに適用されるルールを構成できます。 たとえば、次のように操作できます。
- 機密データをマスクする。
- 条件付きでカスタム ディメンションを追加する。
- スパン名を更新する。これは、Azure portal で同様のテレメトリを集計するために使用されます。
- インジェスト コストを制御するために特定のスパン属性を削除する。
詳細については、テレメトリ プロセッサに関するドキュメントを参照してください。
メモ
インジェスト コストを制御するために特定の (全体の) スパンを削除する必要がある場合は、「サンプリング オーバーライド」を参照してください。
カスタム インストルメンテーション (プレビュー)
バージョン 3.3.1 以降では、アプリケーション内のメソッドのスパンをキャプチャできます。
{
"preview": {
"customInstrumentation": [
{
"className": "my.package.MyClass",
"methodName": "myMethod"
}
]
}
}
インジェスト サンプリングをローカルで無効にする (プレビュー)
既定では、Java エージェントの有効なサンプリング率が 100% で、インジェスト サンプリングが Application Insights リソースに対して構成されている場合、インジェスト サンプリングの割合が適用されます。
この動作は、100% の固定レート サンプリングと、要求レートがレート制限を超えない場合のレート制限付きサンプリングの両方に適用されることに注意してください (継続的なスライディング時間枠中に実質的に 100% をキャプチャします)。
3.5.3 以降では、この動作を無効にすることができます (また、Application Insights リソースでインジェスト サンプリングが構成されている場合でも、このような場合はテレメトリの 100% を保持できます)。
{
"preview": {
"sampling": {
"ingestionSamplingEnabled": false
}
}
}
自動収集されるログ
Log4j、Logback、JBoss Logging、java.util.logging は自動でインストルメント化されます。 これらのログ記録フレームワークを介して実行されるログは、自動収集されます。
ログは、次の場合にのみキャプチャされます。
- ログ記録フレームワークに対する構成済みレベルを満たしている。
- Application Insights に対して構成されているレベルも満たしている。
たとえば、ログ記録フレームワークがパッケージ WARN から com.example をログするように構成されていて (かつ、ユーザーがそれを前に説明したように構成していて)、Application Insights が INFO をキャプチャするように構成されている (かつ、ユーザーが説明したように構成している) 場合、Application Insights はパッケージ WARN から com.example (以上の重大度) のみをキャプチャします。
Application Insights に構成されている既定のレベルは INFO です。 このレベルを変更する場合:
{
"instrumentation": {
"logging": {
"level": "WARN"
}
}
}
環境変数 APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVEL を使用してレベルを設定することもできます。 その場合、JSON 構成で指定されたレベルより優先されます。
これらの有効な level 値を使用して、applicationinsights.json ファイルで指定できます。 この表では、さまざまなログ記録フレームワークのログ レベルにどのように対応するかを示しています。
| レベル | Log4j | Logback | JBoss | 7 月 |
|---|---|---|---|---|
| オフ | オフ | オフ | オフ | オフ |
| 致死 | 致死 | エラー | 致死 | 重度 |
| エラー(または重大) | エラー | エラー | エラー | 重度 |
| WARN (または WARNING) | WARN | WARN | WARN | 警告: |
| 情報 | 情報 | 情報 | 情報 | 情報 |
| CONFIG | デバッグ | デバッグ | デバッグ | CONFIG |
| DEBUG (または FINE) | デバッグ | デバッグ | デバッグ | FINE |
| FINER | デバッグ | デバッグ | デバッグ | FINER |
| TRACE (または FINEST) | TRACE | TRACE | TRACE | FINEST |
| 全て | 全て | 全て | 全て | 全て |
メモ
ロガーに例外オブジェクトが渡されると、Azure portal 内で exceptions テーブルではなく traces テーブルの下にログ メッセージ (例外オブジェクトの詳細を含む) が表示されます。 traces と exceptions の両方のテーブルでログ メッセージを表示する場合は、Logs (Kusto) クエリを作成して、それらを結合できます。 次に例を示します。
union traces, (exceptions | extend message = outerMessage)
| project timestamp, message, itemType
ログ マーカー (プレビュー)
3.4.2 以降、Logback と Log4j 2 のログ マーカーをキャプチャできます。
{
"preview": {
"captureLogbackMarker": true,
"captureLog4jMarker": true
}
}
Logback のその他ログ属性 (プレビュー)
3.4.3 以降、Logback の FileName、ClassName、MethodName、LineNumber をキャプチャできます。
{
"preview": {
"captureLogbackCodeAttributes": true
}
}
警告
コード属性をキャプチャすると、パフォーマンスのオーバーヘッドが増加する可能性があります。
カスタム ディメンションとしてのログ レベル
バージョン 3.3.0 以降は、既定では、LoggingLevel はトレースのカスタム ディメンションの一部としてキャプチャされません。このデータは既に SeverityLevel フィールドでキャプチャされているためです。
必要に応じて、一時的に前の動作を再び有効にすることができます。
{
"preview": {
"captureLoggingLevelAsCustomDimension": true
}
}
自動収集される Micrometer メトリック (Spring Boot Actuator メトリックを含む)
アプリケーションで Micrometer が使用されている場合、Micrometer のグローバル レジストリに送信されたメトリックは自動収集されます。
また、アプリケーションで Spring Boot Actuator が使用されている場合、Spring Boot Actuator によって構成されたメトリックも自動収集されます。
micrometer を使ってカスタム メトリックを送信するには
次の例に示すように、Micrometer をアプリケーションに追加します。
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-core</artifactId> <version>1.6.1</version> </dependency>次の例に示すように、Micrometer グローバル レジストリを使ってメーターを作成します。
static final Counter counter = Metrics.counter("test.counter");次のコマンドにより、カウンターを使ってメトリックを記録します。
counter.increment();メトリックは customMetrics テーブルに取り込まれ、タグは
customDimensions列にキャプチャされます。 メトリックは、 メトリック名前空間のLog-based metricsで表示することもできます。メモ
Application Insights Java は、Micrometer メトリック名内のすべての英数字以外の文字 (ダッシュを除く) をアンダースコアに置き換えます。 その結果、上記
test.counterのメトリックはtest_counterとして表示されます。
Micrometer メトリックと Spring Boot Actuator メトリックの自動収集を無効にするには、次のようにします。
メモ
カスタム メトリックの料金は別途請求されるため、追加のコストが発生する可能性があります。 必ず価格情報を確認してください。 Micrometer と Spring Boot Actuator のメトリックを無効にするには、以下の構成を構成ファイルに追加します。
{
"instrumentation": {
"micrometer": {
"enabled": false
}
}
}
Java Database Connectivity のクエリ マスク
Java Database Connectivity (JDBC) クエリのリテラル値は、機密データを誤って取り込むことを避けるために、既定でマスクされます。
3.4.0 以降では、この動作を無効にできます。 次に例を示します。
{
"instrumentation": {
"jdbc": {
"masking": {
"enabled": false
}
}
}
}
Mongo のクエリ マスク
Mongo クエリ内のリテラル値は、機密データが誤ってキャプチャされないように、既定でマスクされています。
3.4.0 以降では、この動作を無効にできます。 次に例を示します。
{
"instrumentation": {
"mongo": {
"masking": {
"enabled": false
}
}
}
}
HTTP ヘッダー
バージョン 3.3.0 以降、サーバー (要求) テレメトリで要求および応答ヘッダーをキャプチャできます。
{
"preview": {
"captureHttpServerHeaders": {
"requestHeaders": [
"My-Header-A"
],
"responseHeaders": [
"My-Header-B"
]
}
}
}
ヘッダー名は大文字と小文字が区別されません。
上記の例は、プロパティ名 http.request.header.my_header_a と http.response.header.my_header_b でキャプチャされます。
同様に、クライアント (依存関係) テレメトリで要求および応答ヘッダーをキャプチャできます。
{
"preview": {
"captureHttpClientHeaders": {
"requestHeaders": [
"My-Header-C"
],
"responseHeaders": [
"My-Header-D"
]
}
}
}
この場合も、ヘッダー名は大文字と小文字が区別されません。 上記の例は、プロパティ名 http.request.header.my_header_c と http.response.header.my_header_d でキャプチャされます。
HTTP サーバー 4xx 応答コード
既定で、4xx 応答コードを生成する HTTP サーバー要求はエラーとしてキャプチャされます。
バージョン 3.3.0 以降では、それらを成功としてキャプチャするように、この動作を変更できます。
{
"preview": {
"captureHttpServer4xxAsError": false
}
}
特定の自動収集テレメトリを抑制する
Version 3.0.3 以降では、これらの構成オプションを使用して、特定の自動収集テレメトリを抑制できます。
{
"instrumentation": {
"azureSdk": {
"enabled": false
},
"cassandra": {
"enabled": false
},
"jdbc": {
"enabled": false
},
"jms": {
"enabled": false
},
"kafka": {
"enabled": false
},
"logging": {
"enabled": false
},
"micrometer": {
"enabled": false
},
"mongo": {
"enabled": false
},
"quartz": {
"enabled": false
},
"rabbitmq": {
"enabled": false
},
"redis": {
"enabled": false
},
"springScheduling": {
"enabled": false
}
}
}
これらの環境変数を false に設定することで、これらのインストルメンテーションを抑制することもできます。
APPLICATIONINSIGHTS_INSTRUMENTATION_AZURE_SDK_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_CASSANDRA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JDBC_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JMS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_KAFKA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MICROMETER_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MONGO_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_RABBITMQ_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_REDIS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_SPRING_SCHEDULING_ENABLED
これらの変数は、JSON 構成で指定された有効な変数より優先されます。
メモ
より細かい制御を検討している (たとえば、すべての Redis 呼び出しではなく、一部の Redis 呼び出しを抑制する) 場合は、サンプリング オーバーライドを参照してください。
プレビュー インストルメンテーション
バージョン 3.2.0 以降では、次のプレビュー インストルメンテーションを有効にすることができます。
{
"preview": {
"instrumentation": {
"akka": {
"enabled": true
},
"apacheCamel": {
"enabled": true
},
"grizzly": {
"enabled": true
},
"ktor": {
"enabled": true
},
"play": {
"enabled": true
},
"r2dbc": {
"enabled": true
},
"springIntegration": {
"enabled": true
},
"vertx": {
"enabled": true
}
}
}
}
メモ
Akka インストルメンテーションはバージョン 3.2.2 から使用できます。 Vertx HTTP ライブラリのインストルメンテーションはバージョン 3.3.0 から使用できます。
メトリックの間隔
既定では、メトリックは 60 秒ごとにキャプチャされます。
バージョン 3.0.3 以降では、この間隔を変更できます。
{
"metricIntervalSeconds": 300
}
3.4.9 GA 以降では、環境変数 metricIntervalSeconds を使用して APPLICATIONINSIGHTS_METRIC_INTERVAL_SECONDS を設定することもできます。 その場合は、JSON 構成で指定された metricIntervalSeconds よりも優先されます。
この設定は、次のメトリックに適用されます。
- 既定のパフォーマンス カウンター: CPU やメモリなど
- 既定のカスタム メトリック: ガベージ コレクションのタイミングなど
- 構成済みの JMX メトリック: JMX メトリックに関するセクションを参照
- Micrometer メトリック: 自動収集された Micrometer メトリックに関するセクションを参照
ハートビート
Application Insights Java 3.x は、既定では 15 分ごとにハートビート メトリックを送信します。 ハートビート メトリックを使用してアラートをトリガーする場合は、このハートビートの頻度を増やすことができます。
{
"heartbeat": {
"intervalSeconds": 60
}
}
メモ
ハートビート データは Application Insights の使用状況の追跡にも使用されるため、間隔を 15 分より長くすることはできません。
認証
メモ
認証機能は、バージョン 3.4.17 から GA になっています。
認証を使用して、Microsoft Entra 認証に必要なトークン資格情報を生成するエージェントを設定できます。 詳細については、認証に関するドキュメントを参照してください。
HTTP プロキシ
アプリケーションがファイアウォールの内側にあり、Application Insights に直接接続できない場合は、 Azure Monitor エンドポイントのアクセスとファイアウォールの構成を参照してください。
このイシューを回避するには、HTTP プロキシを使用するように Application Insights Java 3.x を構成します。
{
"proxy": {
"host": "myproxy",
"port": 8080
}
}
環境変数 APPLICATIONINSIGHTS_PROXY (https://<host>:<port> という形式) を使って、http プロキシを 設定することもできます。 その場合、JSON 構成で指定されたプロキシより優先されます。
APPLICATIONINSIGHTS_PROXY 環境変数を使用して、プロキシのユーザーとパスワードを指定できます。https://<user>:<password>@<host>:<port>
Application Insights Java 3.x では、グローバル システム プロパティの https.proxyHost と https.proxyPort (および必要に応じて http.nonProxyHosts) が設定されている場合、それらも考慮されます。
インジェストの失敗から復旧する
Application Insights サービスへのテレメトリの送信が失敗した場合、Application Insights Java 3.x はテレメトリをディスクに格納し、ディスクからの再試行を続行します。
ディスク永続化の既定の制限は 50 Mb です。 テレメトリ ボリュームが大きい場合、またはネットワークまたはインジェスト サービスの長い停止から復旧できるようにしておく必要がある場合、バージョン 3.3.0 以降ではこの制限を引き上げることができます。
{
"preview": {
"diskPersistenceMaxSizeMb": 50
}
}
自己診断
"自己診断" では、Application Insights Java 3.x からの内部ログを参照します。 この機能は、Application Insights 自体の問題を発見して診断する場合に役立ちます。
Application Insights Java 3.x は、既定では INFO ファイルとコンソールの両方に applicationinsights.log レベルでログを記録します。これらは次の構成に対応します。
{
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}
上記の構成例では、次のようになっています。
levelには、OFF、ERROR、WARN、INFO、DEBUG、TRACEのいずれかを指定できます。pathには、絶対パスまたは相対パスを指定できます。 相対パスは、applicationinsights-agent-3.7.1.jarがあるディレクトリを基準にして解決されます。
バージョン 3.0.2 以降では、環境変数 level を使用して自己診断 APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVEL を設定することもできます。 これは、JSON 構成で指定されている自己診断レベルより優先されます。
バージョン 3.0.3 以降では、環境変数 APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_FILE_PATH を使用して自己診断ファイルの場所を設定することもできます。 これは、JSON 構成で指定されている自己診断ファイル パスより優先されます。
テレメトリの関連付け
テレメトリの関連付けは既定で有効になっていますが、構成内で無効にすることができます。
{
"preview": {
"disablePropagation": true
}
}
例
この例では、複数のコンポーネントを含む構成ファイルがどのように表示されるかを示します。 各自のニーズに基づいて特定のオプションを構成してください。
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
},
"sampling": {
"percentage": 100
},
"jmxMetrics": [
],
"customDimensions": {
},
"instrumentation": {
"logging": {
"level": "INFO"
},
"micrometer": {
"enabled": true
}
},
"proxy": {
},
"preview": {
"processors": [
]
},
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}