Microsoft のお客様にとって、高パフォーマンスの Exadata グレード データベースをクラウドに移行することがますます必要になっています。 サプライ チェーンのソフトウェア スイートでは、単一のコンピューティング ノードが駆動する読み取りと書き込みの混在ワークロードによってストレージ I/O に求められる要求が大きくなるため、高い条件が設定されています。 Azure インフラストラクチャは、Azure NetApp Files との組み合わせで、この要求の厳しいワークロードのニーズを満たすことができます。 この記事では、お客様の一例を取り上げて、このお客様に対してこの要求が満たされた方法と、Azure が重要な Oracle ワークロードの要求を満たす方法を示します。
エンタープライズ規模の Oracle パフォーマンス
パフォーマンスの上限を探索するときは、結果を誤って歪める可能性のある制約を認識し減らすことが重要です。 たとえば、ストレージ システムのパフォーマンス性能を証明することを意図する場合は、ストレージのパフォーマンス上限に達する前に CPU が足を引っ張る要因にならないようにクライアントを構成することが理想的です。 そのため、テストはインスタンスの種類が E104ids_v5 で始まっています。この VM には、100 Gbps のネットワーク インターフェイスだけでなく、エグレス制限も同じように 100 Gbps と大きく設定されているためです。
テストは次の 2 つのフェーズで実施しました。
- 最初のフェーズでは、今や業界標準となった Kevin Closson の SLOB2 (Silly Little Oracle Benchmark) ツール (バージョン 2.5.4) を使用したテストに焦点を絞りました。 目標は、1 つの仮想マシン (VM) からできる限り多くの Oracle I/O を使って複数の Azure NetApp Files ボリュームを駆動し、その後にさらに多くのデータベースを使用するようにスケールアウトして線形スケーリングが可能であることを示すことです。
- スケーリングの限度をテストした後は、テストの方向を転換し、コストは低くなりますがほぼ同等の機能がある E96ds_v5 で、実際のサプライ チェーン アプリケーションのワークロードと実際のデータを使用して顧客フェーズのテストに入ります。
SLOB2 のスケールアップ パフォーマンス
以下に示すグラフは、8 つのストレージ エンドポイントを持つ 8 つの Azure NetApp Files ボリュームに対して単一の Oracle 19c データベースを実行する、 1 つの E104ids_v5 Azure VM のパフォーマンス プロファイルを示したものです。 ボリュームは、データ、ログ、アーカイブという 3 つの ASM ディスク グループに分散されています。 データ ディスク グループには 5 つのボリューム、ログ ディスク グループには 2 つのボリューム、アーカイブ ディスク グループには 1 つのボリュームが割り当てられています。 この記事全体で示した結果はすべて、実稼働している Azure リージョンと実稼働しているアクティブな Azure サービスを使用して収集されています。
複数のストレージ エンドポイントで複数の Azure NetApp Files ボリュームを使用して Azure 仮想マシンに Oracle をデプロイするには、Oracle のアプリケーション ボリューム グループを使用します。
単一ホスト アーキテクチャ
次の図は、テストが実施されたアーキテクチャを示しています。Oracle データベースが複数の Azure NetApp Files ボリュームとエンドポイントに分散されていることに注意してください。

単一ホスト ストレージ IO
次の図は、100% ランダムに選択されたワークロードで、データベース バッファー ヒット率が約 8% のものを示しています。 SLOB2 は、DB ファイルのシーケンシャル読み取りイベント待機時間をサブミリ秒に維持したまま、1 秒あたり約 850,000 の I/O 要求を駆動できました。 データベース ブロック サイズが 8K の場合、約 6,800 MiB/秒のストレージ スループットに相当します。

単一ホストのスループット
次の図は、フル テーブル スキャンや RMAN アクティビティなど、帯域幅を集中的に使用するシーケンシャル IO ワークロードの場合に、Azure NetApp Files は E104ids_v5 VM 自体が持つすべての帯域幅の能力を発揮できることを示しています。

注
コンピューティング インスタンスは帯域幅の理論上の最大値にあるため、アプリケーションのコンカレンシーを追加しても、クライアント側の待機時間が長くなるだけです。 その結果、SLOB2 のワークロードが目標の実行期間を超えるため、スレッド数は 6 を上限としています。
SLOB2 のスケールアウト パフォーマンス
以下のグラフでは、3 つの E104ids_v5 Azure VM がそれぞれ 1 つの Oracle 19c データベースを実行し、それぞれが「スケールアップ パフォーマンス」のセクションで説明されているのと同じ Azure NetApp Files ボリュームセットと ASM ディスク グループのレイアウトで構成した場合のパフォーマンス プロファイルを示しています。 グラフは、Azure NetApp Files のマルチボリューム/マルチエンドポイントを使用すると、一貫性と予測可能性のある方法でパフォーマンスを簡単にスケールアウトできることを示しています。
マルチホスト アーキテクチャ
次の図は、テストを実行するアーキテクチャを示しています。3 つの Oracle データベースが、複数の Azure NetApp Files ボリュームとエンドポイントに分散されていることに注意してください。 エンドポイントは、Oracle VM 1 に示すように 1 つのホスト専用にすることも、Oracle VM2 と Oracle VM 3 で示しているようにホスト間で共有することもできます。

マルチホスト ストレージ IO
次の図は、100% ランダムに選択されたワークロードで、データベース バッファー ヒット率が約 8% のものを示しています。 SLOB2 は、3 つのホストすべてに対し、それぞれ 1 秒あたり約 850,000 件の I/O 要求を駆動できました。 SLOB2 は、1 秒あたり合計約 2,500,000 件の I/O 要求を並行して実行しながらこれを実現できました。各ホストでは、DB ファイルのシーケンシャル読み取りイベント待機時間がサブミリ秒に維持されています。 データベース ブロック サイズが 8K の場合、3 つのホスト間で約 20,000 MiB/秒がやり取りされたことになります。

マルチホスト スループット
次の図は、シーケンシャル ワークロードの場合に、Azure NetApp Files をスケールアウトしても E104ids_v5 VM 自体が持つすべての帯域幅の能力を発揮できることを示しています。 SLOB2 は、並行処理中に、3 つのホスト全体で合計 30,000 MiB/秒以上の I/O を駆動することができました。

実際のパフォーマンス
SLOB2 でスケーリングの限度をテストした後、Azure NetApp ファイル上の Oracle に対して実際のサプライ チェーンのアプリケーション スイートを使用してテストを実施したところ、すばらしい結果が出ました。 Oracle 自動ワークロード リポジトリ (AWR) のレポートから得た次のデータは、特定の 1 つの重要なジョブがどのように実行されているかに注目しています。
このデータベースでは、フラッシュバックが有効になっており、データベース ブロック サイズが 16k であるため、アプリケーション ワークロードに加えて、相当な数の追加 IO 処理が行われています。 AWR レポートの IO プロファイル セクションから、読み取りと比べて書き込みの比率が高いことがわかります。
| - | 1 秒あたりの読み取りと書き込み | 1 秒あたりの読み取り | 1 秒あたりの書き込み |
|---|---|---|---|
| 合計 (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
DB ファイルのシーケンシャル読み取り待機イベントでは、待機時間が SLOB2 テストよりも長い 2.2 ミリ秒であるにもかかわらず、Exadata 上の RAC データベースから Azure 上の単一インスタンスのデータベースへのジョブ実行時間が 15 分間短縮されています。
Azure リソースの制約
どのようなシステムも最終的にはリソース上の制約に直面します。これは昔からチョークポイントと呼ばれています。 データベース ワークロード、特にサプライ チェーンのアプリケーション スイートなどの要求が厳しいワークロードでは、リソースが集中的に使用されます。 デプロイを成功させるには、こうしたリソース上の制約を見つけて対応することが欠かせません。 このセクションでは、このような環境で発生する可能性があるさまざまな制約と対処方法について説明します。 各サブセクションでは、ベスト プラクティスとその背景にある論理的根拠の両方について学べます。
仮想マシン
このセクションでは、最適なパフォーマンスを得るために、テスト用の VM を選択する際に考慮すべき条件と、その選択の背景にある論理的根拠について詳しく説明します。 Azure NetApp Files はネットワーク接続ストレージ (NAS) サービスであるため、最適なパフォーマンスを得るには適切なネットワーク帯域幅の大きさを設定することが重要になります。
チップセット
最初のトピックはチップセットの選択です。 一貫性を保つため、どのような VM SKU を選ぶにしても、1 つのチップセット上に構築されているものにしてください。 E_v5 VM の Intel バリアントは、第 3 世代の Intel Xeon Platinum 8370C (Ice Lake) 構成で実行されます。 このファミリの VM はすべて、単一の 100 Gbps ネットワーク インターフェイスを搭載しています。 これに対し、例として挙げる E_v3 シリーズは、さまざまな物理ネットワーク帯域幅を備えた 4 つの別々のチップセット上に構築されています。 E_v3ファミリ (Broadwell、Skylake、Cascade Lake、Haswell) に使用されている 4 つのチップセットは、それぞれプロセッサ速度が異なり、マシンのパフォーマンス特性に影響します。
チップセットの選択肢に注目しながら、Azure Compute のドキュメントを読んでください。 また、「Azure NetApp Files 用の Azure 仮想マシン SKU のベスト プラクティス」も参照してください。 一貫性を保つには、1 つのチップセットの VM を選択することをお勧めします。
使用可能なネットワーク帯域幅
VM ネットワーク インターフェイスが利用可能な帯域幅と、同インターフェイスに適用される従量課金制の帯域幅との違いを理解することが重要です。 Azure Compute のドキュメントでネットワーク帯域幅の制限が言及されている場合、この制限はエグレス (書き込み) にのみ適用されます。 イングレス (読み取り) トラフィックは従量課金制ではないため、ネットワーク インターフェイス カード (NIC) 自体の物理的な帯域幅による制限しか受けません。 ほとんどの VM のネットワーク帯域幅は、マシンに適用されるエグレスの制限を超えています。
Azure NetApp Files のボリュームはネットワークに接続されているため、エグレス制限は書き込みに対して適用されると理解できる一方で、イングレスは読み取りおよび読み取りに似たワークロードとして定義されます。 ほとんどのマシンのエグレス制限値は NIC のネットワーク帯域幅を超えていますが、この記事のテストで使用されている E104_v5 については当てはまりません。 E104_v5 には 100 Gbps の NIC があり、エグレス制限も 100 Gbps に設定されています。 これに対して E96_v5 では、NIC が 100 Gbps であってもエグレス制限は 35 Gbps で、イングレスは事実上無制限の 100 Gbps です。 VM のサイズが小さくなるとエグレス制限は低くなりますが、イングレスは論理的に課された上限では制限されません。
エグレス制限は VM 全体に対するもので、すべてのネットワーク ベースのワークロードに適用されます。 Oracle Data Guard を使用する場合、ログのアーカイブのために書き込みがすべて 2 倍になるため、エグレス制限について検討する際に考慮に入れる必要があります。 これは、複数の宛先と RMAN を使用する場合のアーカイブ ログにも当てはまります。 VM を選定するときは、Azure ではネットワーク インターフェイスの構成が文書化されていないため、NIC の構成を調べる ethtool のようなコマンド ライン ツールに慣れておいてください。
ネットワーク コンカレンシー
Azure VM と Azure NetApp Files ボリュームには、一定の帯域幅が与えられています。 先述のように、VM の CPU に十分な余裕がある限り、ワークロードは理論上、ネットワーク カードとエグレスの上限の範囲内で利用可能な帯域幅を使用できます。 ただし、実際には、達成可能なスループットはネットワーク上のワークロードのコンカレンシー (ネットワーク フローとネットワーク エンドポイントの数) に依存します。
詳細については、 VM ネットワークの帯域幅に関する ドキュメントのネットワーク フローの制限に関するセクションを参照してください。 ここで覚えておくべきことは、クライアントをストレージに接続するネットワーク フローが多ければ多いほど、潜在的なパフォーマンスが向上するという点にあります。
Oracle では、カーネル NFS と Direct NFS (dNFS)という 2 つの NFS クライアントがサポートされています。 カーネル NFS は、最近まで 2 つのエンドポイント (コンピューティング - ストレージ) 間の単一のネットワーク フローのみをサポートしていました。 この 2 つのうちでパフォーマンスが高い方の Direct NFS では、さまざまな数のネットワーク フローに対応しています。テストでは、エンドポイントごとに数百のユニークな接続が確認されており、負荷に応じて増加または減少します。 2 つのエンドポイント間のネットワーク フローのスケーリングができるため、Direct NFS はカーネル NFS よりもはるかに優れており、推奨される構成です。 Azure NetApp Files 製品グループでは、Oracle ワークロードでカーネル NFS を使用することはお勧めしていません。 詳細については、「Oracle Database での Azure NetApp Files 利用のメリット」を参照してください。
実行のコンカレンシー
Direct NFS を利用し、1 つのチップセットで一貫性を確保し、ネットワーク帯域幅に関する制限を理解したとしても、それだけでは不十分です。 最終的には、アプリケーションがパフォーマンスを決定付けます。 SLOB2 を使用した概念実証と、現実世界のサプライ チェーン アプリケーション スイートと実際の顧客データを使用した概念実証で大きなスループットを実現できた理由は、アプリケーションを高いコンカレンシーで実行したためです。前者ではスキーマごとに相当な数のスレッドを使用し、後者では複数のアプリケーション サーバーからの複数の接続を使用しています。 つまり、コンカレンシーがワークロードを駆動するのです。同じインフラストラクチャを使用している限り、コンカレンシーが低いとスループットも低くなり、コンカレンシーが高いとスループットも高くなるということになります。
Accelerated Networking
高速ネットワークによって、VM との間でシングル ルート I/O 仮想化 (SR-IOV) が可能になり、ネットワークのパフォーマンスが大幅に向上します。 この高パフォーマンスのパスによってデータ パスからホストがバイパスされ、サポートされている VM の種類において最も要求の厳しいネットワーク ワークロードで、待ち時間、ジッター、CPU 使用率が低下します。 terraform やコマンド ラインの構成管理ユーティリティを使用して VM をデプロイする際は、高速ネットワークが既定では有効になっていないことに注意してください。 最適なパフォーマンスを実現するために、高速ネットワークを有効にしてください。 高速ネットワークはネットワーク インターフェイスごとに有効または無効にすることにも注意してください。 高速ネットワーク機能は、動的に有効または無効にできます。
注
この記事には、Microsoft が使用しなくなった SLAVE という用語が使われています。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
NIC で高速ネットワークが有効になっていることを確認するための王道のアプローチは、Linux ターミナルを使う方法です。 NIC の高速ネットワークを有効にすると、2 つ目の仮想 NIC が最初の NIC に関連付けられます。 この 2 つ目の NIC はシステムによって構成され、SLAVE フラグが有効になります。
SLAVE フラグが設定された NIC がない場合、そのインターフェイスでは高速ネットワークは有効になっていません。
複数の NIC を構成するシナリオでは、NFS ボリュームのマウントに使用する NIC にどの SLAVE インターフェイスが関連付けられているかを確認する必要があります。 VM にネットワーク インターフェイス カードを追加しても、パフォーマンスには影響しません。
構成されたネットワーク インターフェイスとそれに関連付けられている仮想インターフェイスの間のマッピングを見分けるには、次のプロセスを使用します。 このプロセスでは、Linux マシン上の特定の NIC に対して高速ネットワークが有効になっていることを確認し、NIC が実現できる物理的なイングレス速度を表示します。
-
ip aコマンドを実行します。
- 確認対象の NIC ID (例では
/sys/class/net/) のeth0ディレクトリを一覧表示し、単語「lower」をgrepします。ls /sys/class/net/eth0 | grep lower lower_eth1 - 前の手順で下位デバイスであることがわかったイーサネット デバイスに対して
ethtoolコマンドを実行します。
Azure VM: ネットワークとディスクの帯域幅の制限
Azure VM のパフォーマンス制限に関するドキュメントを読むには、一定レベルの専門知識が必要です。 注意事項:
- 一時ストレージのスループットと IOPS の数値は、VM に直接接続されている一時的なオンボックス ストレージのパフォーマンス性能を指します。
- キャッシュされていないディスクのスループットと I/O 番号は Azure Disk (Premium、Premium v2、Ultra) に関するもので、Azure NetApp Files などのネットワーク接続ストレージとは関係がありません。
- VM に追加の NIC を接続しても、VM のパフォーマンス制限やパフォーマンス性能には何の影響もありません (文書化およびテスト済み)。
- 最大ネットワーク帯域幅とは、VM のネットワーク帯域幅に対して適用されるエグレス制限 (つまり、Azure NetApp Files の場合は書き込み) を指します。 イングレス制限 (つまり、Azure NetApp Files の場合は読み取り) は適用されません。 十分な CPU、十分なネットワーク コンカレンシー、十分に豊富な数のエンドポイントがあると仮定すると、理論的には VM はイングレス トラフィックを NIC の限界まで処理することができます。 「使用可能なネットワーク帯域幅 」のセクションで言及したように、
ethtoolなどのツールを使って NIC の帯域幅を確認してください。
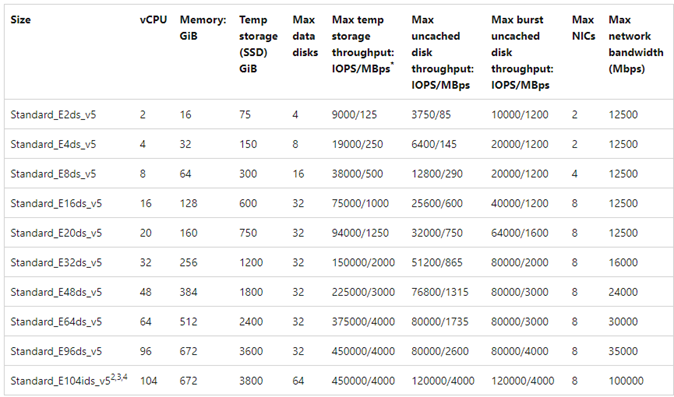
参考のためにサンプルの表を示します。
Azure NetApp Files
Azure のファースト パーティ ストレージ サービスである Azure NetApp Files は、先ほど紹介したような要求の厳しい Oracle ワークロードに対応できる、可用性の高いフル マネージド ストレージ ソリューションです。
Oracle データベースのストレージ パフォーマンスのスケールアップの限界はよく理解されているので、この記事では意識的にストレージ性能のスケールアウトに焦点を絞って説明します。 ストレージ パフォーマンスをスケールアウトするということは、単一の Oracle インスタンスに数多くの Azure NetApp Files ボリュームへのアクセス権を付与することを意味します。このボリュームは、複数のストレージ エンドポイントに分散されます。
このような方法で複数のボリューム間でデータベースのワークロードをスケーリングすることで、データベースのパフォーマンスはボリュームとエンドポイントの両方の制限から解放されます。 ストレージはパフォーマンス上の制限ではなくなったので、VM のアーキテクチャ (CPU、NIC、VM エグレスの制限) が対処すべきボトルネックとなります。 VM セクションで説明したように、E104ids_v5 と E96ds_v5 のインスタンスを選択したのは、この点を念頭に置いていたためです。
データベースを 1 つの大容量ボリュームに配置しても、複数の小さなボリュームに分散しても、コストの合計額は同じです。 1 つのボリュームとエンドポイントではなく、複数のボリュームとエンドポイントに I/O を分散する利点は、帯域幅の制限を回避することができることです。つまり、支払った分の帯域幅をすべて使用できるのです。
重要
multiple volume:multiple endpoint 構成で Azure NetApp Files を使用してデプロイする場合は、Azure NetApp Files スペシャリストまたはクラウド ソリューション アーキテクトにお問い合わせください。
データベース
Oracle のデータベース バージョン 19c は、現在 Oracle で長く利用されているリリースバージョンであり、この記事で解説しているすべてのテスト結果は、このバージョンを使用して作成されたものです。
最高のパフォーマンスのために、データベース ボリュームはすべて Direct NFS を使ってマウントされています。カーネル NFS はパフォーマンス上の制約があるため推奨されません。 2 つのクライアントのパフォーマンスの比較については、「Azure NetApp Files の複数ボリュームでの Oracle データベースのパフォーマンス」を参照してください。 ここでは、関連するすべての dNFS パッチ (Oracle サポート ID 1495104) が適用され、Azure NetApp Files を使用した Microsoft Azure 上の Oracle データベースに関するレポートで説明されているベスト プラクティスも同様に適用されています。
Oracle と Azure NetApp Files では NFSv3 と NFSv4.1 の両方がサポートされていますが、NFSv3 はより成熟したプロトコルであるため、一般に最も安定性が高いと見なされています。サービスの中断に特に神経を使う環境では信頼性の高いオプションです。 この記事で説明しているテストはすべて NFSv3 で実施しています。
重要
サポート ID 1495104の Oracle ドキュメントで推奨されているパッチのいくつかは、dNFS を使用する際にデータの整合性を保つために特に重要です。 運用環境では、このようなパッチの適用を強くお勧めします。
NFS ボリュームでは、自動ストレージ管理 (ASM) がサポートされています。 通常、ASM は、論理ボリューム管理 (LVM) とファイルシステムの両方を ASM で置き換えるブロックベースのストレージに関連付けて考えられますが、複数ボリューム NFS のシナリオでも重要な役割を果たしますので、十分な検討に値します。 そのような ASM の利点の 1 つである、新しく追加された NFS ボリュームとエンドポイントを動的にオンラインで追加し、全体で再調整する機能により、管理が単純になり、パフォーマンスと容量の両方を拡張することができます。 ASM 自体ではデータベースのパフォーマンスは向上しませんが、ASM を使用することで、ホット ファイルを回避し、ファイルの分散を手動で維持する必要がなくなることは、わかりやすい利点です。
この記事で論じるテスト結果は、すべて ASM over dNFS 構成を使用して作成されています。 次の図は、Azure NetApp Files ボリューム内の ASM ファイル レイアウトと、ASM ディスク グループへのファイルの割り当てを示しています。

ストレージ スナップショットに関しては、Azure NetApp Files の NFS マウント ボリュームで ASM を使用する上でいくつかの制限がありますが、アーキテクチャで一定の配慮をすれば克服できます。 この配慮が必要な点に関する詳細なレビューについては、Azure NetApp Files スペシャリストまたはクラウド ソリューション アーキテクトにお問い合わせください。
総合テスト ツールとチューニング
このセクションでは、テスト アーキテクチャ、チューニング、構成の詳細について具体的に説明します。 前のセクションでは、なぜこのような構成にするのかに重点を置きましたが、このセクションでは構成に関して "どのような" 決定をするのかに重点を置きます。
自動化されたデプロイ
- データベース VM は、GitHub で入手できる bash スクリプトを使用してデプロイします。
- 複数の Azure NetApp Files ボリュームとエンドポイントのレイアウトと割り当ては手動で行います。 作業は Azure NetApp Files スペシャリストまたはクラウド ソリューション アーキテクトのサポートを受けて行う必要があります。
- 各マシンでのグリッドのインストール、ASM 構成、データベースの作成と構成、および SLOB2 環境は、一貫性のために Ansible を使用して構成します。
- 複数のホスト間での並列 SLOB2 テストの実行も、一貫性と同時実行のために Ansible を使用して行います。
VM の構成
| 構成 | 値 |
|---|---|
| Azure リージョン | 西ヨーロッパ |
| VM の SKU | E104ids_v5 |
| NIC 数 | 1 注: vNIC を追加しても、システム数には影響しません |
| 最大エグレス ネットワーク帯域幅 (Mbps) | 100,000 |
| 一時ストレージ (SSD) GiB | 3,800 |
システム構成
バージョン 19c で Oracle が必要と定めるすべてのシステム構成の設定は、Oracle のドキュメントに従って実施されました。
Linux システム ファイルの /etc/sysctl.conf に次のパラメーターが追加されました。
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
すべての Azure NetApp Files ボリュームは、次の NFS マウント オプションを使用してマウントされました。
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
データベース パラメーター
| パラメーター | 値 |
|---|---|
db_cache_size |
2グラム |
large_pool_size |
2グラム |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25g |
shared_io_pool_size |
500m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
SLOB2 の構成
すべてのテスト用ワークロードの生成は、SLOB2 ツール バージョン 2.5.4 を使用して行われました。
14 の SLOB2 スキーマが標準の Oracle テーブルスペースに読み込まれ、Slob 構成ファイルの設定と組み合わせて実行されて、SLOB2 データ セットが 7 TiB に設定されます。 以下の設定には、SLOB2 のランダムな読み取り実行を反映しています。 構成パラメーター SCAN_PCT=0 は、シーケンシャル テスト時には SCAN_PCT=100 に変更されました。
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
ランダム読み取りテストでは、SLOB2 が 9 回実行されました。 スレッド数は 6 ずつ増やし、各テストのイテレーションを 1 から開始しました。
シーケンシャル テストでは、SLOB2 が 7 回実行されました。 スレッド数は 2 ずつ増やし、各テストのイテレーションを 1 から開始しました。 ネットワーク帯域幅の上限に達するため、スレッド数は 6 に制限されています。
AWR メトリック
すべてのパフォーマンス メトリックは、Oracle 自動ワークロード リポジトリ (AWR) で報告されています。 結果に表示されるメトリックを次に示します。
- スループット: AWR Load Profile セクションからの平均読み取りスループットと書き込みスループットの合計
- AWR Load Profile セクションからの平均読み取り IO 要求数
- AWR Foreground Wait Events セクションからの db ファイルシーケンシャル読み取り待機イベントの平均待機時間
専用設計のシステムからクラウドへの移行
Oracle Exadata は、ハードウェアとソフトウェアの組み合わせてエンジニアリングされたシステムで、Oracle ワークロードを実行するために最も最適化されたソリューションと考えられています。 クラウドには技術的な世界の全体的なスキームの中で大きな利点がありますが、このような専用システムは、Oracle が特定のワークロードを中心に構築した最適化について読み、その目で見た人にとって、非常に魅力的に映ります。
Exadata で Oracle を実行することに関して、Exadata が選択される一般的な理由がいくつかあります。
- Exadata 機能を使用するのに最適な 1 つから 2 つの高い IO ワークロードがある場合です。このようなワークロードには、Exadata の設計に組み込まれている重要な機能が必要であり、それと並行して実行されている残りのデータベースは Exadata に統合します。
- RAC をスケーリングする必要があり、Oracle の最適化に関する深い知識がないと独自のハードウェアを使用して設計するのが難しい、または技術的負債を最適化できない可能性がある複雑または困難な OLTP ワークロードの場合。
- 使用率が低い既存の Exadata でさまざまなワークロードが実行されている場合。 これは、以前の移行や、以前の Exadata の有効期間が終了した、または社内で Exadata の作業/テストを実施したい場合に存在します。
Exadata システムからの移行は、ワークロードの観点から理解し、移行がどの程度単純なのか複雑なのかを理解することが不可欠です。 2 つ目の必要性は、Exadata を購入した理由を状況の観点から理解することです。 Exadata と RAC のスキルは需要が高く、技術的な利害関係者から購入を推奨されたのかもしれません。
重要
どのようなシナリオであれ、Exadata にどのようなデータベース ワークロードがあるにしても、Exadata 独自の機能を使用していればいるほど、移行と計画が複雑になるということを理解しておく必要があります。 Exadata 独自の機能を本格的に利用していない環境では、移行と計画のプロセスを簡単にできる可能性があります。
こうしたワークロードの状況を評価するために使用できるツールがいくつかあります。
- AWR (自動ワークロード リポジトリ):
- すべての Exadata データベースには、AWR レポート、関連するパフォーマンス機能、診断機能を使用するライセンスが付与されています。
- 常に有効になっており、過去のワークロード情報を表示し、利用状況を評価するために使用できるデータを収集します。 ピーク値でシステムの使用率が高くなっているかを評価できます。
- 大きなウィンドウの AWR レポートでは、ワークロード全体を評価できます。そのため、機能の利用状況と、ワークロードを Exadata 以外に効果的に移行する方法に関して貴重な分析情報を入手できます。 これに対して、ピーク AWR レポートは、パフォーマンスの最適化とトラブルシューティングに最適です。
- Exadata のグローバル (RAC 対応) AWR レポートには、Exadata 固有のセクションも含まれています。Exadata 固有のセクションでは、特定の Exadata 機能の使用状況にドリルダウンし、フラッシュ キャッシュ、フラッシュ ログ、IO、およびその他の機能の使用状況をデータベースとセル ノードごとに提供するので、貴重な分析情報となります。
Exadata からの切り離し
クラウドに移行する Oracle Exadata ワークロードを見極める際には、次の質問とデータ ポイントを考慮してください。
- ワークロードは、ハードウェア上の利点のほかに、Exadata の機能を複数使用していますか?
- スマート スキャン
- ストレージ インデックス
- フラッシュ キャッシュ
- フラッシュ ログ
- ハイブリッド列圧縮
- ワークロードは Exadata のオフロードを効率的に使用していますか? 上位の時間を占めているフォアグラウンド イベントの中で、以下を使用するワークロードの比率 (DB 時間の 10% 以上) はどれくらいですか?
- セル スマート テーブル スキャン (最適)
- セルマルチブロックの物理的な読み取り (最適ではない)
- セル単一ブロックの物理読み取り (最も最適ではない)
- ハイブリッド列圧縮 (HCC/EHCC): 圧縮と非圧縮の比率はどれくらいですか?
- データベースは、データの圧縮と展開にデータベースの時間の 10% 以上を費やしていますか?
- クエリに圧縮を使用することで述語のパフォーマンスが向上しているかを調べます。得られた値は、圧縮で節約できたデータ量と比較して価値があるものですか?
- セルの物理 IO: 以下によってどれだけ節約できたかを調べます。
- CPU のバランスを取るために DB ノードに送られた量。
- スマート スキャンによって返されたバイト数の特定。 この値は、Exadata から移行した後は、セルの単一ブロックの物理的な読み取りの割合の分だけ IO で差し引くことができます。
- キャッシュからの論理読み取りの回数に注意してください。 ワークロードのクラウド IaaS ソリューションで、フラッシュ キャッシュが必要かどうかを判断します。
- 物理的な読み取りと書き込みの合計バイト数を、キャッシュで実行された合計数と比較します。 物理的な読み取り要件をなくすためにメモリを増やすことができますか (一部のメモリでは、Exadata のオフロードを強制するために SGA を縮小するのが一般的)?
- システム統計で、どのオブジェクトがどの統計の影響を受けているかを特定します。 SQL をチューニングする場合、インデックス作成、パーティション分割、その他の物理チューニングを行うと、ワークロードが大幅に最適化される可能性があります。
- 初期化パラメーターを調べて、アンダースコア (_) や非推奨のパラメーターがないか確認します。これらはデータベース レベルで」影響があり、パフォーマンスに影響を与える場合があるためです。
Exadata サーバーの構成
Oracle バージョン 12.2 以降では、Exadata 固有の情報が AWR グローバル レポートに追加されています。 このレポートには、Exadata からの移行を考える場合に特に価値がある情報を提供するセクションがあります。
Exadata のバージョンとシステムの詳細
セル ノード アラートの詳細
Exadata 非オンライン ディスク
Exadata OS 統計の外れ値データ
黄色/ピンク:懸念事項。 Exadata が最適に実行されていません。
赤色: Exadata のパフォーマンスが大幅に影響を受けます。
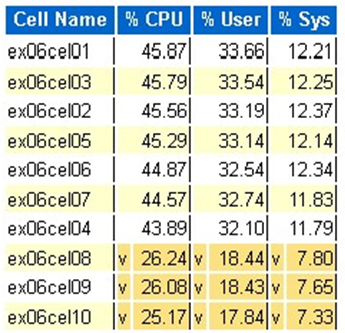
Exadata OS CPU 統計: 上位セル
- これらの統計は OS がセルに対して収集するので、このデータベースまたはインスタンスに限定されません
-
vと濃い黄色の背景は、範囲の下限を下回る外れ値を示しています -
^と明るい黄色の背景は、範囲を上限を超える外れ値を示しています - CPU 使用率で上位のセルが、CPU 使用率の降順に表示されます
- 平均: CPU 39.34%、ユーザー 28.57%、システム 10.77%
単一セルの物理ブロックの読み取り
フラッシュ キャッシュの使用
一時 IO
列キャッシュの効率性
IO スループットの上位データベース
サイズ設定に関する評価は実施できますが、平均値とシミュレートされたピーク値に関して問うべき質問がいくつかあります。大きなワークロードでは、こうした値に必ず付きまとう質問です。 AWR レポートの最後にあるこのセクションでは、Exadata 上の上位 10 個のデータベースの平均フラッシュとディスク使用量の両方が示されているため、非常に価値があります。 多くのユーザーは、クラウドのピーク時のパフォーマンスに合わせてデータベースのサイズを設定する必要があると考えているかもしれませんが、ほとんどのデプロイでは合理的ではありません (95% 以上が平均範囲内にあり、シミュレートされたピークを計算に入れた場合、平均範囲は 98% を超えます)。 Oracle のワークロードの中で最も要求が高いワークロードであったとしても、必要な分だけの料金を支払うことが大切です。IO スループットの上位データベースを調べると、データベースが必要としているリソースを理解する上で貴重な情報が得られます。
Exadata の AWR を使用して Oracle のサイズを適切に設定する
オンプレミス システムの容量計画を実施する場合、ハードウェアに大きなオーバーヘッドを組み込むのは当然のことです。 過剰にプロビジョニングされたハードウェアは、データの増加、コードの変更、アップグレードによるワークロードの追加に影響されることなく、何年間にもわたって Oracle のワークロードに対応する必要があります。
クラウドの利点の 1 つは、需要の増加に応じて VM ホスト内のリソースとストレージをスケーリングできることです。 これにより、(Oracle 関連の) プロセッサの使用に関連するクラウド コストとライセンス コストを節約できます。
適切なサイズ設定では、従来のリフト アンド シフト移行からハードウェアを除外し、Oracle の自動ワークロード リポジトリ (AWR) で提供されるワークロード情報を活用して、お客様が選択したクラウドでワークロードをサポートするように特別に設計されたコンピューティングとストレージにワークロードをリフト アンド シフトすることも考慮に入れる必要があります。 適切なサイズ設定のプロセスを実施することで、今後のアーキテクチャでは、インフラストラクチャの技術的負債や、オンプレミス システムの重複がクラウドに持ち越された場合に発生するアーキテクチャの冗長性を確実に取り除き、可能な限りクラウド サービスを利用できるようになります。
Microsoft の Oracle 領域専門家は、Oracle データベースの 80% 以上が過剰にプロビジョニングされており、クラウドに移行する前に時間を取って Oracle データベースのワークロードを適切なサイズに設定することで、クラウドに移行しても同じだけのコストか、それよりも節約になると推定しています。 この評価を行うには、チームのデータベース スペシャリストがこれまで実施していた容量計画の方法に関する考え方を変える必要がありますが、利害関係者のクラウドへの投資と事業のクラウド戦略のことを考えると実施する価値はあります。
次のステップ
- パフォーマンスやスケーラビリティを犠牲にすることなく、Azure で最も要求の厳しい Oracle ワークロードを実行する
- Azure NetApp Files を使用したソリューション アーキテクチャ - Oracle
- Azure での Oracle データベースの設計と実装
- Oracle ワークロードを Azure IaaS VM に合わせてサイズ変更するための見積もりツール
- Azure 上の Oracle Database Enterprise Edition 用リファレンス アーキテクチャ
- SAP HANA の Azure NetApp Files アプリケーション ボリューム グループについて