Intelligent Insights でパフォーマンスの問題をトラブルシューティングする - Azure SQL データベース と Azure SQL Managed Instance
適用対象:![]() Azure SQL データベース
Azure SQL データベース![]() Azure SQL Managed Instance
Azure SQL Managed Instance
このページでは、Intelligent Insights のリソース ログによって検出された、Azure SQL データベース と Azure SQL Managed Instance のパフォーマンスに関する問題点について説明します。 Azure Monitor ログ、Azure Event Hubs、Azure Storage、または DevOps のカスタム アラートおよびレポート機能を提供するサード パーティ製ソリューションに、メトリックとリソース ログをストリーミングできます。
Note
Intelligent Insights を使ったパフォーマンスのトラブルシューティングに関するクイック ガイドについては、このドキュメントの「推奨されるトラブルシューティングのフロー」のフローチャートを参照してください。
Intelligent Insights はプレビュー機能であり、次のリージョンでは利用できません。西ヨーロッパ、北ヨーロッパ、米国西部 1、米国東部 1。
データベースの検出可能なパフォーマンス パターン
Intelligent Insights は、クエリ実行の待機時間、エラー、またはタイムアウトに基づいて、パフォーマンスの問題を自動的に検出します。 Intelligent Insights では、検出されたパフォーマンス パターンがリソース ログに出力されます。 検出可能なパフォーマンス パターンの概要を次の表に示します。
| 検出可能なパフォーマンス パターン | Azure SQL データベース | Azure SQL Managed Instance |
|---|---|---|
| リソースの上限に到達 | 監視対象サブスクリプションで使用可能なリソース (DTU)、データベース ワーカー スレッド、またはデータベース ログイン セッションの消費量がそのリソースの制限に達しました。 そのことがパフォーマンスに影響を及ぼしています。 | CPU リソースの消費量がその制限に達しそうです。 これは SQL データベースのパフォーマンスに影響しています。 |
| ワークロードの増加 | データベースでのワークロードの増加またはワークロードの継続的な蓄積が検出されました。 そのことがパフォーマンスに影響を及ぼしています。 | ワークロードの増加が検出されました。 これは SQL データベースのパフォーマンスに影響しています。 |
| メモリ不足 | メモリ許可を要求した worker は、統計的にかなりの時間、メモリの割り当てを待つ必要があります。または、メモリ許可を要求した worker の累積が増加します。 そのことがパフォーマンスに影響を及ぼしています。 | メモリ許可を要求した worker は、統計的にかなりの時間、メモリの割り当てを待つ必要があります。 これは SQL データベースのパフォーマンスに影響しています。 |
| ロック | パフォーマンスに影響を与える、過剰なデータベースのロックが検出されました。 | データベースのパフォーマンスに影響を与える、過剰なデータベースのロックが検出されました。 |
| MAXDOP の増加 | 並列処理の最大限度オプション (MAXDOP) が変更されて、クエリの実行効率に影響を与えています。 そのことがパフォーマンスに影響を及ぼしています。 | 並列処理の最大限度オプション (MAXDOP) が変更されて、クエリの実行効率に影響を与えています。 そのことがパフォーマンスに影響を及ぼしています。 |
| ページラッチの競合 | 複数のスレッドがメモリ内の同じデータ バッファー ページに同時にアクセスしようとしたため、待機時間が延び、ページラッチの競合が発生しています。 そのことがパフォーマンスに影響を及ぼしています。 | 複数のスレッドがメモリ内の同じデータ バッファー ページに同時にアクセスしようとしたため、待機時間が延び、ページラッチの競合が発生しています。 これはデータベースのパフォーマンスに影響しています。 |
| インデックスの不足 | パフォーマンスに影響するインデックスの不足が検出されました。 | データベースのパフォーマンスに影響するインデックスの不足が検出されました。 |
| 新しいクエリ | 全体的なパフォーマンスに影響する新しいクエリが検出されました。 | データベースの全体的なパフォーマンスに影響する新しいクエリが検出されました。 |
| 待機の増加の統計 | パフォーマンスに影響するデータベースの待機時間の増加が検出されました。 | データベースのパフォーマンスに影響するデータベースの待機時間の増加が検出されました。 |
| TempDB の競合 | 複数のスレッドが同じ tempdb リソースにアクセスしようとして、ボトルネックが発生しています。 そのことがパフォーマンスに影響を及ぼしています。 |
複数のスレッドが同じ tempdb リソースにアクセスしようとして、ボトルネックが発生しています。 これは SQL データベースのパフォーマンスに影響しています。 |
| エラスティック プールの DTU の不足 | エラスティック プールで使用できる eDTU が不足し、パフォーマンスに影響を与えています。 | 仮想コア モデルを使用する Azure SQL Managed Instance には使用できません。 |
| プランの回帰 | 新しいプラン、または既存プランのワークロードの変更が検出されました。 そのことがパフォーマンスに影響を及ぼしています。 | 新しいプラン、または既存プランのワークロードの変更が検出されました。 これは SQL データベースのパフォーマンスに影響しています。 |
| データベース スコープの構成値の変更 | データベースのパフォーマンスに影響するデータベースの構成の変更が検出されました。 | データベースのパフォーマンスに影響するデータベースの構成の変更が検出されました。 |
| 処理速度が遅いクライアント | 処理速度が遅いアプリケーション クライアントは、データベースからの出力を適切な速度で処理できません。 そのことがパフォーマンスに影響を及ぼしています。 | 処理速度が遅いアプリケーション クライアントは、データベースからの出力を適切な速度で処理できません。 これは SQL データベースのパフォーマンスに影響しています。 |
| 価格レベルのダウングレード | 価格レベルのダウングレード アクションによって、使用できるリソースが減りました。 そのことがパフォーマンスに影響を及ぼしています。 | 価格レベルのダウングレード アクションによって、使用できるリソースが減りました。 これは SQL データベースのパフォーマンスに影響しています。 |
ヒント
データベースのパフォーマンスを継続的に最適化するには、自動チューニングを有効にします。 この組み込みのインテリジェンス機能は、データベースを継続的に監視し、インデックスを自動的に調整して、クエリ実行プランの修正を適用します。
次のセクションでは、検出可能なパフォーマンス パターンについてさらに詳しく説明します。
リソースの上限に到達
状況
この検出可能なパフォーマンス パターンは、使用可能なリソースの上限、worker の上限、およびセッションの上限への到達に関連するパフォーマンスの問題を組み合わせたものです。 このパフォーマンスの問題が検出されると、診断ログの説明フィールドに、パフォーマンスの問題がリソース、worker、セッションの上限のいずれに関連しているかが示されます。
通常、Azure SQL Database 上のリソースは DTU リソースや仮想コア リソースと呼ばれ、Azure SQL Managed Instance 上のリソースは仮想コア リソースと呼ばれます。 リソースの上限への到達パターンが認識されるのは、検出されたクエリ パフォーマンスの低下が、測定されるリソース上限のいずれかに到達したことによって生じている場合です。
セッション上限のリソースは、データベースに同時にログインできる数を示します。 このパフォーマンス パターンは、データベースに接続しているアプリケーションが、データベースに同時にログインできる数に到達した場合に認識されます。 データベースで利用できる数よりも多くのセッションをアプリケーションが使用しようとすると、クエリのパフォーマンスが影響を受けます。
利用可能な worker は DTU または仮想コアの使用量としてカウントされないため、worker の上限に到達するということは、リソース上限に到達する中でも特殊な場合です。 データベースで worker の上限に到達すると、リソース固有の待機時間が上昇するため、クエリのパフォーマンス低下につながります。
トラブルシューティング
診断ログには、パフォーマンスとリソース使用率に影響を与えたクエリのクエリ ハッシュが出力されます。 データベースのワークロードを最適化するための出発点として、この情報を使うことができます。 具体的には、インデックスを追加して、パフォーマンスの低下に影響するクエリを最適化できます。 または、より均等にワークロードを分散させることで、アプリケーションを最適化できます。 ワークロードの削減や最適化が難しい場合は、データベース サブスクリプションの価格レベルを上げて、使用可能なリソースの量を増やすことを検討します。
使用可能なセッションの上限に到達した場合は、データベースへのログイン数を減らすことで、アプリケーションを最適化できます。 アプリケーションからデータベースへのログイン数を減らすことができない場合は、データベース サブスクリプションの価格レベルを上げることを検討します。 または、データベースを分割して複数のデータベースに移動させ、より均等にワークロードを分散させることができます。
セッションの上限に対応するためのその他の推奨事項については、最大ログイン数の上限に対応する方法に関するページを参照してください。 サーバーおよびサブスクリプション レベルの制限については、サーバー上のリソース制限の概要に関するページを参照してください。
ワークロードの増加
状況
このパフォーマンス パターンは、ワークロードの増加、またはより重大なワークロードの累積によって生じる問題を表します。
いくつかの指標を組み合わせることで検出されます。 測定された基本的な指標によって、過去のワークロード ベースラインとの比較により、ワークロードの増加が検出されます。 その他の形式の検出は、クエリのパフォーマンスに影響を与えるほど大きな、アクティブなワーカー スレッド数の増加の測定に基づいています。
より重大なのは、データベースがワークロードを処理できないことにより、ワークロードが継続的に累積する場合です。 その場合、ワークロードのサイズが増大し続けて、ワークロードの累積状態が発生します。 この状態のため、ワークロードが実行を待機する時間が長くなります。 この状態は、最も重大なデータベース パフォーマンスの問題の 1 つです。 この問題は、中止されたワーカー スレッド数の増加を監視することで検出されます。
トラブルシューティング
診断ログには、実行回数が増加したクエリの数、およびワークロードの増加に最も影響を与えているクエリのクエリ ハッシュが出力されます。 ワークロードを最適化するための出発点として、この情報を使うことができます。 ワークロード増加の最大の原因として特定されたクエリは、出発点として特に有効です。
データベースにワークロードをより均等に配分することを検討できる場合があります。 インデックスを追加して、パフォーマンスに影響するクエリの最適化を検討します。 また、複数のデータベースにワークロードを分散できる可能性もあります。 これらの解決策が不可能な場合は、データベース サブスクリプションの価格レベルを上げて、使用可能なリソースの量を増やすことを検討します。
メモリ不足
状況
このパフォーマンス パターンは、過去 7 日間のパフォーマンス ベースラインとの比較により、メモリ不足によって生じた現在のデータベース パフォーマンスの低下、またはより重大なメモリの停滞状態を表します。
メモリ不足は、メモリ許可を要求するワーカー スレッドの数が非常に多いパフォーマンスの状態を表します。 これにより、メモリ使用率が高い状態が発生し、データベースがメモリを要求するすべてのワーカーに効率的にメモリを割り当てることが困難になります。 この問題の最も一般的な理由の 1 つは、データベースが使用できるメモリの量に関連します。 その一方で、ワークロードが増加すると、ワーカー スレッドが増えてメモリ不足が発生します。
より重大なメモリ不足の形態は、メモリ要求が累積した状態です。 このような状況は、メモリ許可を要求しているワーカー スレッドの数の方が、メモリを解放しているクエリより多いことを示します。 また、データベース エンジンが効率的にメモリを割り当てて要求を満たすことができないため、メモリ許可を要求するワーカー スレッド数が増加し続ける (累積状態になる) こともあります。 メモリ累積状態は、データベースのパフォーマンスに関する最も重大な問題の 1 つです。
トラブルシューティング
診断ログには、メモリ使用量が多くなっている最大の要因としてマーク付けされたクラーク (つまりワーカー スレッド) のメモリ オブジェクトの保存詳細と、関連するタイムスタンプが出力されます。 トラブルシューティングのための基準としてこの情報を使うことができます。
メモリ使用量の多さの要因であるクラークに関連するクエリを、最適化または削除することができます。 また、使う予定のないデータをクエリしていないかどうかを確認できます。 クエリでは常に WHERE 句を使用することをお勧めします。 さらに、データをスキャンするのではなくシークするように、非クラスター化インデックスを作成することをお勧めします。
最適化したり、複数のデータベースに分散させたりすることで、ワークロードを減らすこともできます。 または、ワークロードを複数のデータベースに分散させることができます。 これらの解決策が不可能な場合は、データベースの価格レベルを上げて、データベースで使用可能なメモリ リソースの量を増やすことを検討します。
トラブルシューティングのその他の提案については、Memory grants meditation:The mysterious SQL Server memory consumer with many names」(メモリ許可に関する考察: さまざまな名前を持つ、SQL Server の不可解なメモリ コンシューマー) をご覧ください。 Azure SQL Database のメモリ不足エラーについて詳しくは、「Azure SQL Database によるメモリ不足エラーのトラブルシューティング」を参照してください。
ロック
状況
このパフォーマンス パターンは、過去 7 日間のパフォーマンス ベースラインとの比較により、データベースの過剰なロックが検出された、現在のデータベース パフォーマンスの低下を表します。
最新の RDBMS では、マルチスレッド化されたシステムを実装するために、ロックが不可欠です。そこでは、複数の worker を同時に実行し、可能な場合はデータベースでトランザクションを並列処理して、パフォーマンスが最大化されます。 この場合のロックは、1 つのトランザクションのみが必要かつ他のリソースのトランザクションと競合しない行、ページ、表、ファイルに排他的にアクセスできる、組み込みのアクセス メカニズムを指します。 リソースの使用をロックしたトランザクションでリソースの使用が完了すると、これらのリソースのロックが解除されて、他のトランザクションが必要なリソースにアクセスできるようになります。 ロックについて詳しくは、「データベース エンジンのロック」をご覧ください。
SQL エンジンで実行されたトランザクションが、使用がロックされたリソースにアクセスするために長時間待機している場合は、この待機時間がワークロード実行のパフォーマンス低下の原因になります。
トラブルシューティング
診断ログには、トラブルシューティングのときに基本情報として使うことができる、ロックの詳細が出力されます。 報告されたブロッキング クエリ、つまりロックのパフォーマンス低下を引き起こすクエリを分析して、それらを削除できます。 場合によっては、ブロッキング クエリを最適化できることもあります。
問題を緩和する最も簡単で安全な方法は、トランザクションを常に短くして、最もコストの高いクエリのロック フットプリントを低減させることです。 大きい操作のバッチを小さい操作に分割できます。 クエリをできるだけ効率化して、クエリのロック フットプリントを低減させることをお勧めします。 大規模なスキャンは、デッドロックの可能性を高め、データベースの全体のパフォーマンスに悪影響を及ぼすので、減らします。 ロックの原因として特定されたクエリについては、新しいインデックスを作成したり、既存のインデックスに列を追加したりして、テーブル スキャンを回避できます。
その他の提案については、以下を参照してください。
MAXDOP の増加
状況
この検出可能なパフォーマンス パターンは、選択されたクエリの実行プランが必要以上に並列処理されている状態を表します。 クエリ オプティマイザーは、可能であればクエリを同時実行して処理を高速化し、ワークロードのパフォーマンスを向上させます。 場合によっては、同じクエリを少数の並列 worker で実行する場合と比較しても、さらには 1 つのワーカー スレッドで実行する場合と比較しても、クエリを並列 worker で処理する方が、相互に結果を同期しマージするための待機に多くの時間を費やすことがあります。
エキスパート システムは、ベースラインの期間と比較して現在のデータベースのパフォーマンスを分析し、 クエリ実行プランが必要以上に並列化されたために、クエリの実行が以前より遅くなったかどうかを判断します。
同じクエリの並列実行に使われる CPU コア数の制御には、MAXDOP サーバー構成オプションが使われます。
トラブルシューティング
診断ログには、必要以上に並列処理されているために実行時間が増加しているクエリに関連するクエリ ハッシュが出力されます。 また、CXP 待機時間も出力されます。 この時間は、1 つのオーガナイザーまたはコーディネーター スレッド (thread 0) が、結果をマージして先に進む前に、他のすべてのスレッドが終了するのを待機している時間を表します。 さらに、診断ログには、パフォーマンスの低いクエリが実行で待機していた全体の待機時間も出力されます。 トラブルシューティングのための基準としてこの情報を使うことができます。
最初に、複雑なクエリを最適化または単純化します。 長いバッチ ジョブを細かく分割することをお勧めします。 さらに、クエリをサポートするためのインデックスを作成したことを確認します。 また、パフォーマンスが低いことを示すフラグが設定されたクエリに対しては、最大限の並列化 (MAXDOP) を手動で強制することもできます。 T-SQL を使ってこの操作を構成する方法については、「max degree of parallelism サーバー構成オプションの構成」をご覧ください。
MAXDOP サーバー構成オプションを既定値のゼロ (0) に設定すると、データベースは、使用可能なすべての CPU コアを 1 つのクエリを実行するスレッドの並列処理に使うことができます。 MAXDOP を 1 に設定することは、1 つのクエリ実行に使えるコアが 1 つだけであることを示します。 実際には、これは並列処理がオフであるという意味です。 場合によっては、データベースで使用できるコア数、および診断ログの情報に応じて、MAXDOP オプションを調整し、クエリの並列実行に使用できるコア数をそれぞれのケースで問題を解決できる可能性がある値に設定できます。
ページラッチの競合
状況
このパフォーマンス パターンは、過去 7 日間のワークロード ベースラインとの比較により、ページラッチの競合によって、現在のデータベースのワークロード パフォーマンスが低下していることを表します。
ラッチは、マルチスレッドを有効にするために使われる軽量の同期メカニズムです。 インデックス、データ ページ、その他の内部構造を含むメモリ内構造の一貫性を保証します。
さまざまな種類のラッチが用意されています。 単純化のため、バッファー プールのメモリ内ページの保護にはバッファー ラッチが使われます。 バッファー プールにまだ読み込まれていないページの保護には、IO ラッチが使われます。 バッファー プールのページにデータを書き込んだり、ページからデータを読み取ったりする場合、ワーカー スレッドはまずそのページのバッファー ラッチを取得する必要があります。 メモリ内のバッファー プールにまだないページにワーカー スレッドがアクセスを試みると、記憶域から必要な情報を読み込むための IO 要求が生成されます。 このイベント シーケンスは、より重大なパフォーマンスの低下を示します。
ページ ラッチの競合は、複数のスレッドが同じメモリ内の構造で同時にラッチを取得しようとする場合に発生し、クエリ実行の待機時間が増加します。 記憶域からデータにアクセスする必要があるページラッチの IO の競合では、この待機時間がさらに増加します。 これは、ワークロードのパフォーマンスに大きく影響する可能性があります。 ページ ラッチの競合は、スレッドが互いに待機し、複数の CPU システムのリソースにおいて競合する、最も一般的なシナリオです。
トラブルシューティング
診断ログには、ページラッチの競合の詳細が出力されます。 トラブルシューティングのための基準としてこの情報を使うことができます。
ページラッチは内部制御メカニズムであるため、使用のタイミングは自動的に決定されます。 スキーマ デザインを含むアプリケーションの決定は、ラッチの決定論的なビヘイビアーにより、ページラッチの動作に影響を与えます。
ラッチの競合を処理する方法の 1 つは、連続したインデックス キーを連番でないキーに置き換えて、インデックスの範囲に挿入を均等に分散することです。 通常、インデックスの先頭列がワークロードを比例的に配分します。 検討すべきもうひとつの方法は、テーブル パーティションです。 パーティション テーブルの計算列でハッシュ パーティション分割のスキーマを作成することは、ラッチの過剰な競合を軽減するための一般的な方法です。 ページラッチの IO 競合の場合、インデックスの導入がパフォーマンスの問題の軽減に役立ちます。
詳しくは、「Diagnose and resolve latch contention on SQL Server」(SQL Server でのラッチの競合の診断と対応) (PDF をダウンロード) をご覧ください。
インデックスの不足
状況
このパフォーマンス パターンは、過去 7 日間のベースラインとの比較により、インデックスの不足によって、現在のデータベースのワークロード パフォーマンスが低下していることを表します。
インデックスは、クエリのパフォーマンスを高速化するために使用されます。 アクセスまたはスキャンする必要があるデータセットのページ数を削減して、テーブル データへのすばやいアクセスを提供します。
インデックスの作成がパフォーマンスの向上に役立つと考えられる、パフォーマンス低下の原因となったクエリがこの検出によって特定されます。
トラブルシューティング
診断ログには、ワークロードのパフォーマンスに影響を与えることが認められたクエリのクエリ ハッシュが出力されます。 これらのクエリに対してインデックスを作成できます。 また、クエリを最適化したり、必要ない場合はクエリを削除することもできます。 良好なパフォーマンスのためには、使わないデータはクエリしないことをお勧めします。
ヒント
組み込みのインテリジェンスによって、お使いのデータベースに最適なインデックスが自動的に管理されます。
パフォーマンスを継続的に最適化するには、自動チューニングを有効にすることをお勧めします。 きわめて優れた組み込みのインテリジェンス機能によって、データベースが継続的に監視され、データベースのインデックスが自動的に調整されて作成されます。
[新しいクエリ]
状況
このパフォーマンス パターンは、過去 7 日間のパフォーマンス ベースラインとの比較により、パフォーマンスが低く、ワークロードのパフォーマンスに影響を与える新しいクエリが検出されたことを表します。
優れたパフォーマンスのクエリを作成することは、困難なタスクです。 クエリの作成について詳しくは、クエリの作成に関するページをご覧ください。 既存のクエリのパフォーマンスを最適化する方法については、「クエリのチューニング」をご覧ください。
トラブルシューティング
診断ログには、CPU 使用量が最も高い、最大 2 つの新しいクエリの情報 (クエリ ハッシュを含む) が出力されます。 検出されたクエリはワークロードのパフォーマンスに影響を与えるので、クエリを最適化できます。 使う必要があるデータだけを取得することが、よい方法です。 また、クエリで WHERE 句を使うこともお勧めします。 あるいは、複雑なクエリを単純化し、小さいクエリに分割することもお勧めします。 もう 1 つのよい方法は、大きいバッチ クエリを小さいバッチ クエリに分割することです。 通常、このパフォーマンスの問題を軽減するには、新しいクエリにインデックスを導入することをお勧めします。
Azure SQL Database では、Query Performance Insight の使用を検討してください。
待機の増加の統計
状況
この検出可能なパフォーマンス パターンは、過去 7 日間のワークロード ベースラインと比較してパフォーマンスの低いクエリが検出された場合の、ワークロードのパフォーマンスの低下を表します。
この場合、システムは他の検出可能な標準パフォーマンス カテゴリの低パフォーマンス クエリを分類することはできませんが、回帰の原因である待機の統計を検出しました。 したがって、それらを "待機の増加の統計" のクエリと見なし、回帰の原因である特殊な待機統計も公開されます。
トラブルシューティング
診断ログには、待機時間の増加の詳細と影響を受けたクエリのクエリ ハッシュに関する情報が出力されます。
システムでパフォーマンスの低いクエリの根本原因を特定できなかったため、診断情報が手動でトラブルシューティングを行うための第一歩として役立ちます。 これらのクエリのパフォーマンスを最適化することができます。 使う必要のあるデータだけをフェッチして単純化し、複雑なクエリは細かく分割することをお勧めします。
クエリのパフォーマンスの最適化について詳しくは、「クエリのチューニング」をご覧ください。
TempDB の競合
状況
この検出可能なパフォーマンス パターンは、tempdb リソースへのアクセスを試みるスレッドのボトルネックが存在するデータベース パフォーマンスの状態を示します。 (この状態は IO に関連していません)。このパフォーマンスの問題の一般的なシナリオは、数百の同時実行クエリのすべてが小さい tempdb テーブルを作成して、使用し、ドロップすることです。 システムは、過去 7 日間のパフォーマンス ベースラインとの比較により、同じ tempdb テーブルを使う同時実行クエリ数の増加において十分に統計上有意であることが認められ、データベースのパフォーマンスに影響を与えていることを検出しました。
トラブルシューティング
診断ログには、tempdb の競合の詳細が出力されます。 トラブルシューティングの出発点としてこの情報を使うことができます。 この種の競合を軽減し、ワークロード全体のスループットを増やすためにできることが 2 つあります。まず、一時テーブルの使用をやめることができます。 また、メモリ最適化テーブルを使うこともできます。
詳しくは、「メモリ最適化テーブルの概要」をご覧ください。
エラスティック プールの DTU の不足
状況
この検出可能なパフォーマンス パターンは、過去 7 日間のベースラインとの比較により、現在のデータベースのワークロード パフォーマンスが低下していることを示します。 原因は、サブスクリプションのエラスティック プールで使用可能な DTU の不足です。
Azure エラスティック プールのリソースは、複数のデータベース間でスケーリングのために共有される、使用可能なリソースのプールとして使用されます。 エラスティック プールで使用可能な eDTU リソースが、プール内のすべてのデータベースのサポートには足りない場合、エラスティック プールの DTU の不足というパフォーマンスの問題がシステムで検出されます。
トラブルシューティング
診断ログには、エラスティック プールに関する情報が出力され、DTU を最も多く消費しているデータベースが一覧表示されるとともに、消費量が最も多いデータベースによるプールの DTU 使用率が提供されます。
このパフォーマンスの状態は、エラスティック プール内で同じプールの eDTU を使用する複数のデータベースに関連しているため、トラブルシューティングの手順では、DTU を最も多く消費するデータベースに注目します。 このようなデータベースでの使用量が最も多いクエリの最適化も含めて、消費量が最も多いデータベースのワークロードを削減できます。 また、使わないデータのクエリを行っていないことを確認できます。 そのほかの方法としては、DTU を最も多く消費するデータベースを使用するアプリケーションの最適化と、複数のデータベース間でのワークロードの再分配があります。
DTU を最も多く消費するデータベースで、現在のワークロードを削除したり最適化したりすることが難しい場合は、エラスティック プールの価格レベルを上げることを検討します。 これにより、エラスティック プールで使用可能な DTU を増やすことができます。
プランの回帰
状況
この検出可能なパフォーマンス パターンは、最適化されていないクエリ実行プランをデータベースが利用している状態を示します。 通常、最適化されていないプランはクエリ実行回数の増加の原因となり、現在およびその他のクエリの待機時間の増加につながります。
データベース エンジンでは、クエリ実行コストが最も低いクエリ実行プランが決定されます。 クエリの種類とワークロードが変更されると、既存のプランが効率的ではなくなったり、データベース エンジンで最適な評価が行われなかったりする場合があります。 修正については、クエリの実行プランは手動で適用できます。
この検出可能なパフォーマンス パターンでは、プラン回帰の 3 つの異なるケース (新しいプランへの回帰、前のプランへの回帰、ワークロードが変更された既存のプランへの回帰) が組み合わされています。 発生した具体的なプラン回帰の種類は、診断ログの "詳細" プロパティで提供されます。
新しいプランへの回帰の状態は、前のプランほど効率的ではない、新しいクエリ実行プランの実行がデータベース エンジンで開始されている状態を表します。 前のプランへの回帰の状態は、データベース エンジンで、新しくより効率的なプランから、新しいプランほど効率的ではない前のプランの使用に切り替わった状態を表します。 ワークロードが変更された既存のプランへの回帰は、前のプランと新しいプランが継続的に交互に行われつつ、パフォーマンスの低いプランへの比重が高まっている状態を表します。
プランの回帰について詳しくは、「What is plan regression in SQL Server?」(SQL server のプランの回帰とは) をご覧ください。
トラブルシューティング
診断ログには、クエリ ハッシュ、適切なプランの ID、不適切なプランの ID、およびクエリの ID が出力されます。 トラブルシューティングのための基準としてこの情報を使うことができます。
提供されたクエリ ハッシュを使用して特定できるクエリに対して、どのプランのパフォーマンスが優れているかを分析できます。 クエリに対してパフォーマンスが優れているプランを判断した後、手動で適用できます。
詳しくは、「Learn how SQL Server prevents plan regressions」(SQL Server がプランの回帰を回避するしくみ) をご覧ください。
ヒント
組み込みのインテリジェンス機能によって、お使いのデータベースに最適なクエリ実行プランが自動的に管理されます。
パフォーマンスを継続的に最適化するには、自動チューニングを有効にすることをお勧めします。 この組み込みのインテリジェンス機能は、データベースを継続的に監視し、自動的に調整を行って、そのデータベースで最適なパフォーマンスを発揮するクエリ実行プランを作成します。
データベース スコープの構成値の変更
状況
この検出可能なパフォーマンス パターンは、データベース スコープの構成が変更されたことで、過去 7 日間のワークロードの動作と比較して、パフォーマンスの低下が検出された状態を表します。 このパターンは、データベース スコープの構成に加えられた最近の変更が、データベースのパフォーマンスに有益ではないと考えられることを示します。
データベース スコープの構成の変更は、個々のデータベースごとに設定できます。 この構成は、データベースの個々のパフォーマンスを最適化するために、それぞれのケースに応じて使用します。 個別のデータベースごとに、MAXDOP、LEGACY_CARDINALITY_ESTIMATION、PARAMETER_SNIFFING、QUERY_OPTIMIZER_HOTFIXES、CLEAR PROCEDURE_CACHE のオプションを構成できます。
トラブルシューティング
診断ログには、過去 7 日間のワークロードの動作と比較して、パフォーマンスの低下の原因となった、最近加えられたデータベース スコープの構成の変更が出力されます。 構成の変更を前の値に元に戻すことができます。 目的のパフォーマンス レベルに達するまで、値を 1 つずつチューニングすることもできます。 満足のいくパフォーマンスを達成している同様のデータベースから、データベース スコープの構成値をコピーできます。 パフォーマンスのトラブルシューティングが難しい場合は、既定値に戻して、この基準値から微調整を行います。
データベース スコープの構成の最適化と、構成の変更に使用する T-SQL 構文について詳しくは、「ALTER DATABASE SCOPED CONFIGURATION (Transact-SQL)」をご覧ください。
処理速度が低いクライアント
状況
この検出可能なパフォーマンス パターンは、データベースを使っているクライアントが、データベースが結果を送信するのと同じ速度で、データベースからの出力データを処理できない状態を示します。 データベースは実行されたクエリの結果をバッファーに格納しないため、速度を下げて、送信されたクエリの出力をクライアントが処理するまで待機してから続行します。 この状態は、データベースからの出力データを使用するクライアントに対して、十分な速度でデータを送信できないネットワークに関連する場合もあります。
過去 7 日間のワークロードの動作と比較して、パフォーマンスの低下が検出された場合にのみ、この状態が生成されます。 このパフォーマンスの問題は、過去のパフォーマンスの動作と比較して、統計的に有意なパフォーマンスの低下が発生している場合にのみ検出されます。
トラブルシューティング
この検出可能なパフォーマンス パターンは、クライアント側の状態を示します。 クライアント側のアプリケーションまたはネットワークでのトラブルシューティングが必要です。 診断ログには、過去 2 時間以内にクライアントによる処理を最も長い時間待機したクエリのクエリ ハッシュと待機時間が出力されます。 トラブルシューティングのための基準としてこの情報を使うことができます。
これらのクエリの使用に関して、アプリケーションのパフォーマンスを最適化できます。 発生する可能性のあるネットワーク待機時間の問題について考えることもできます。 パフォーマンス低下の問題は過去 7 日間のパフォーマンス ベースラインの変化に基づくものだったので、最近のアプリケーションやネットワークの状態の変化によりこのパフォーマンス回帰イベントが発生したどうかを調査することができます。
価格レベルのダウングレード
状況
この検出可能なパフォーマンス パターンは、データベース サブスクリプションの価格レベルがダウングレードされたことを示します。 データベースで使用できるリソース (DTU) の減少により、過去 7 日間のベースラインと比較して、現在のデータベースのパフォーマンスが低下していることがシステムで検出されています。
この他に、データベース サブスクリプションの価格レベルがダウングレードされた後、短期間内に上位レベルにアップグレードされた可能性もあります。 この一時的なパフォーマンス低下の検出は、診断ログの詳細セクションには価格レベルのダウングレードとアップグレードとして出力されます。
トラブルシューティング
価格レベルを下げたことにより、使用できる DTU が減少しても、パフォーマンスに満足している場合は、対応の必要はありません。 価格レベルを下げた後でデータベースのパフォーマンスに満足できなくなった場合は、データベースのワークロードを削減するか、価格レベルを上位に引き上げることを検討します。
推奨されるトラブルシューティングのフロー
Intelligent Insights を使ったパフォーマンスのトラブルシューティングのお勧めの方法については、フローチャートに従ってください。
Azure SQL Analytics に移動して、Azure Portal から Intelligent Insights にアクセスします。 受信したパフォーマンス アラートを検索して選びます。 検出ページで現在の状況を確認します。 問題の根本原因の解析、クエリ テキスト、クエリの時間の傾向、およびインシデントの展開に関する情報をよく読みます。 パフォーマンスの問題点の軽減に関する Intelligent Insights の推奨事項を使って、問題の解決を試みます。
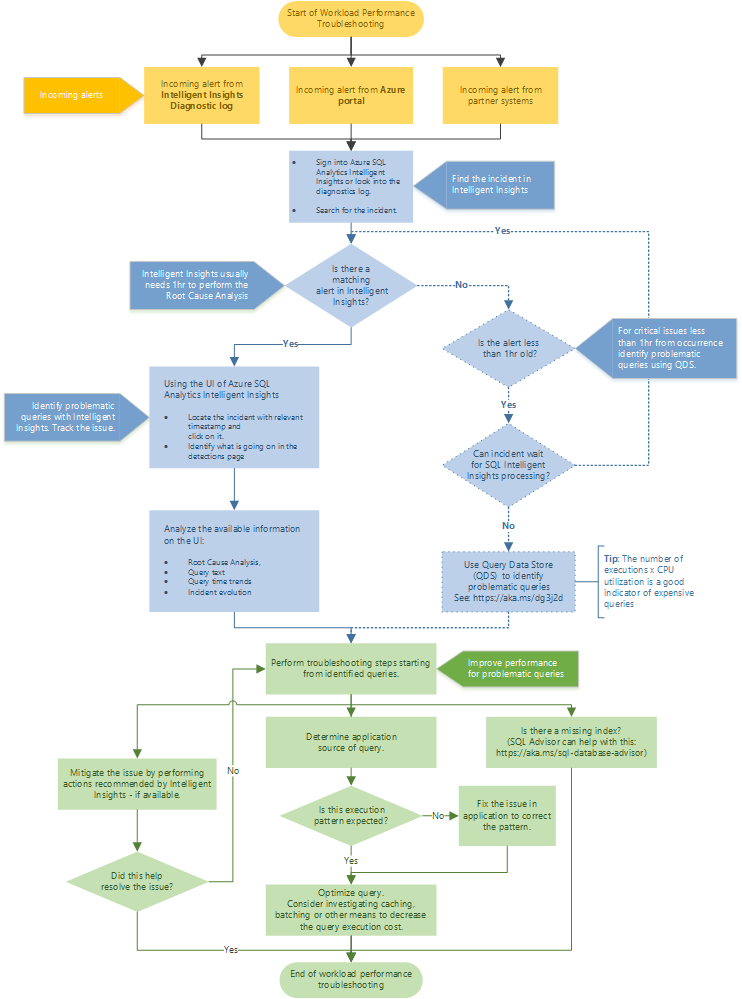
ヒント
PDF バージョンをダウンロードするには、フローチャートを選びます。
Intelligent Insights では、パフォーマンスの問題の根本原因の解析に通常 1 時間かかります。 Intelligent Insights で問題を見つけることができず、問題を見つけることが重要であるときは、クエリ データ ストアを使って、手動でパフォーマンスの問題の根本原因を特定します (通常、これらの問題とは 1 時間以内のものです)。詳しくは、「クエリのストアを使用した、パフォーマンスの監視」をご覧ください。
次のステップ
- Intelligent Insights の概念の習得。
- Intelligent Insights パフォーマンス診断ログの使用。
- Azure SQL Analytics を使用した監視。
- Azure リソースからのログ データの収集と使用の習得。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示