SAP HANA データベースは、低い回復ポイントの目標値 (RPO) と長期リテンション期間を必要とする重要なワークロードです。 この記事では、Azure portal を使用して、Azure Backup によって Azure 仮想マシン (VM) で実行されている SAP HANA データベースを Azure Backup Recovery Services コンテナーにバックアップする方法について説明します。 Azure CLI を使用して操作を行うこともできます。
Azure Backup で Azure VM (スタンドアロン) 上の SAP HANA データベースの保護を HSR に切り替えることもできます。 詳細については、こちらを参照してください。
注意
- 現在、HSR + DR のシナリオのサポートは利用できません。VM とコンテナーを同じリージョンに設定することに対して制限があるためです。 別のリージョンにある 3 番目のノードのバックアップ操作を有効にするには、別のコンテナー内のバックアップをスタンドアロン ノードとして構成する必要があります。
- サポートされている構成とシナリオの詳細については、「SAP HANA バックアップのサポート マトリックス」を参照してください。
前提条件
Azure VM 上の SAP HANA システム レプリケーション データベースをバックアップする前に、次のことを確認してください。
- HANA システム レプリケーション (HSR) データベースの 2 つの VM またはノードと同じリージョンおよびサブスクリプション内で Recovery Services コンテナーを特定または作成します。
- Azure との通信のために、各 VM またはノードからインターネットへの接続を許可します。
- HANA システム レプリケーション (HSR) の一部である両方の VM またはノードで、事前登録スクリプトを実行します。 最新の事前登録スクリプトはこちらからダウンロードできます。 [Recovery Services コンテナー]>[バックアップ]>[VM 内のデータベースを検出]>[検出の開始] のリンクからダウンロードすることもできます。
重要
SAP HANA サーバー VM 名とリソース グループ名とを組み合わせた長さが、Azure Resource Manager VM の場合は 84 文字、クラシック VM の場合は 77 文字を超えないようにしてください。 この制限は、一部の文字がサービスによって予約されていることに起因します。
Recovery Services コンテナーを作成する
Recovery Services コンテナーは、時間の経過と共に作成される復旧ポイントを格納する管理エンティティであり、バックアップ関連の操作を実行するためのインターフェイスが用意されています。 たとえば、オンデマンドのバックアップの作成、復元の実行、バックアップ ポリシーの作成などの操作です。
Recovery Services コンテナーを作成するには、次の手順に従います。
Azure portal にサインインします。
ビジネス継続性センターを検索し、ビジネス継続性センター ダッシュボードに移動します。

[コンテナー] ペインで、[+コンテナー] を選択します。
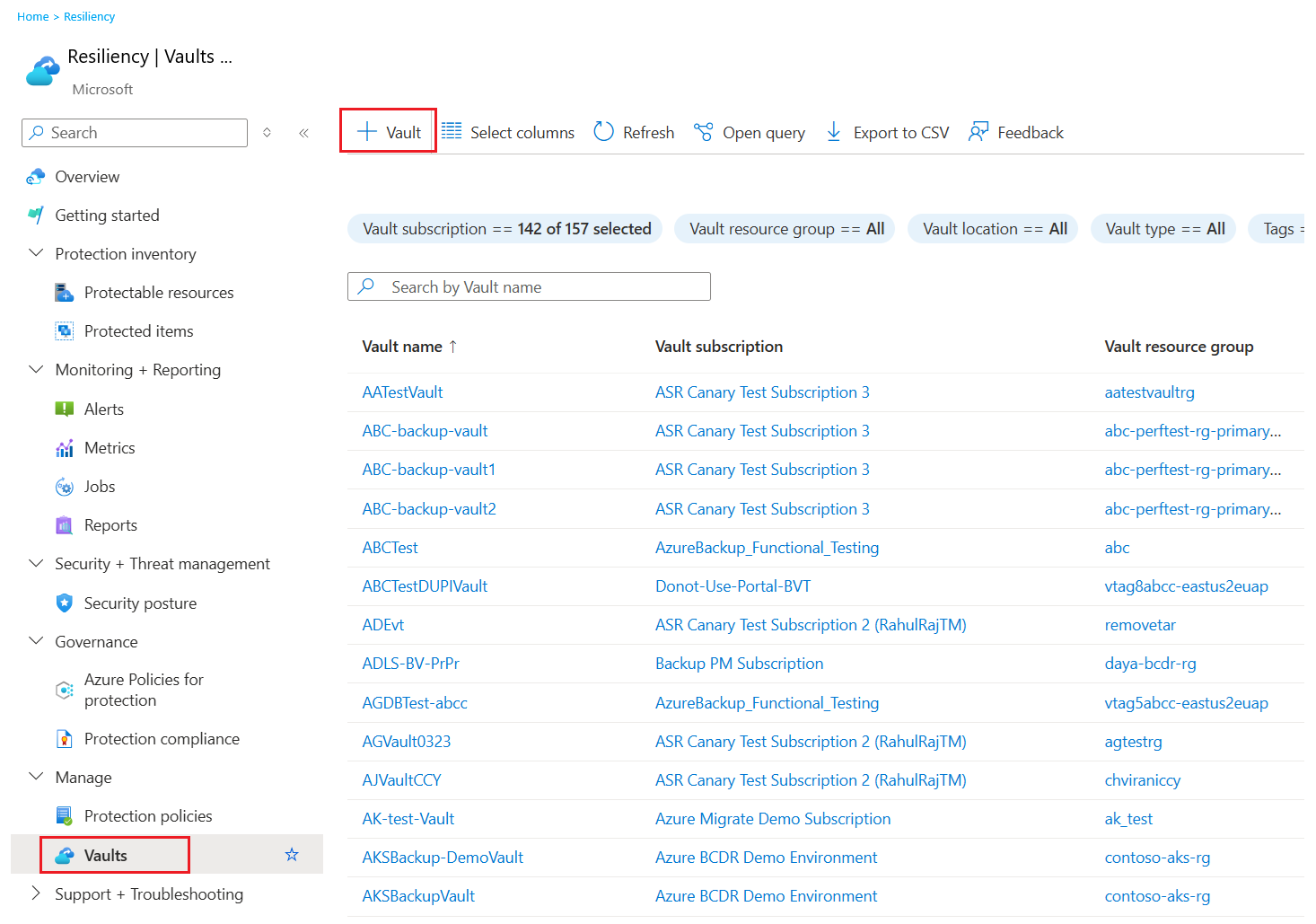
[Recovery Services コンテナー]>[続行] の順に選択します。
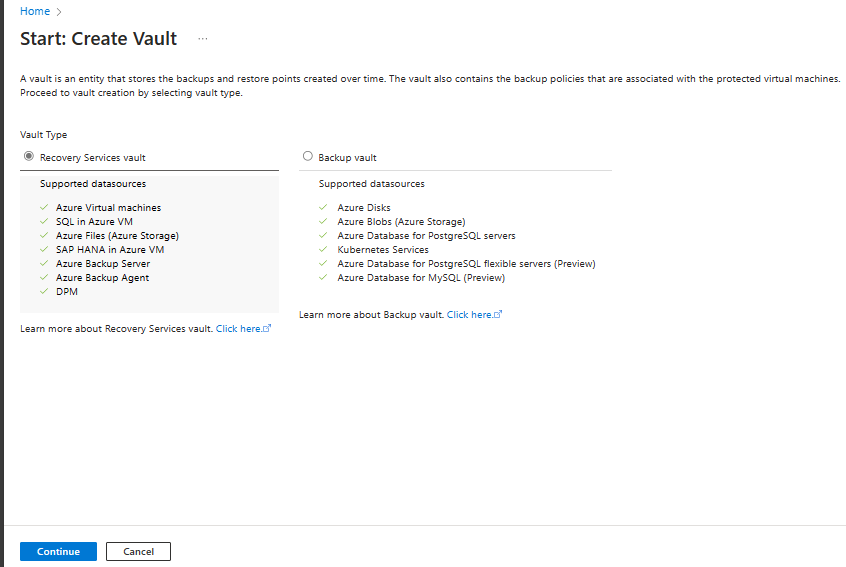
[Recovery Services コンテナー] ペインで、次の値を入力します。
[サブスクリプション] : 使用するサブスクリプションを選択します。 1 つのサブスクリプションのみのメンバーの場合は、その名前が表示されます。 どのサブスクリプションを使用すればよいかがわからない場合は、既定のサブスクリプションを使用してください。 職場または学校アカウントが複数の Azure サブスクリプションに関連付けられている場合に限り、複数の選択肢が存在します。
[リソース グループ] :既存のリソース グループを使用するか、新しいリソース グループを作成します。 サブスクリプションの使用可能なリソース グループの一覧を表示するには、[既存のものを使用] を選択してから、ドロップダウン リストでリソースを選択します。 新しいリソース グループを作成するには、[新規作成] を選択し、名前を入力します。 リソース グループの詳細については、「Azure Resource Manager の概要」を参照してください。
[コンテナー名]: コンテナーを識別するフレンドリ名を入力します。 名前は Azure サブスクリプションに対して一意である必要があります。 2 文字以上で、50 文字以下の名前を指定します。 名前の先頭にはアルファベットを使用する必要があります。また、名前に使用できるのはアルファベット、数字、ハイフンのみです。
[リージョン]: コンテナーの地理的リージョンを選択します。 データ ソースを保護するためのコンテナーを作成するには、コンテナーがデータ ソースと同じリージョン内にある "必要があります"。
重要
データ ソースの場所が不明な場合は、ウィンドウを閉じます。 ポータルの自分のリソースの一覧に移動します。 複数のリージョンにデータ ソースがある場合は、リージョンごとに Recovery Services コンテナーを作成します。 最初の場所にコンテナーを作成してから、別の場所にコンテナーを作成します。 バックアップ データを格納するためにストレージ アカウントを指定する必要はありません。 Recovery Services コンテナーと Azure Backup で自動的に処理されます。
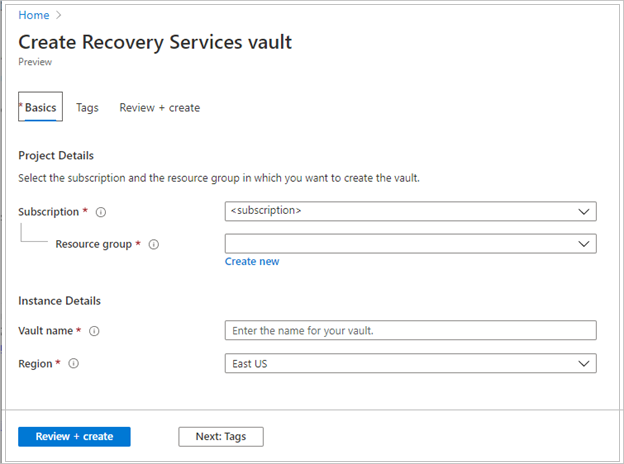
値を指定したら、 [確認と作成] を選択します。
Recovery Services コンテナーの作成を完了するには、[作成] を選択します。
Recovery Services コンテナーの作成に時間がかかることがあります。 右上の [通知] 領域で、状態の通知を監視します。 作成されたコンテナーは、Recovery Services コンテナーのリストに表示されます。 コンテナーが表示されない場合は、[最新の情報に更新] を選択します。


注意
Azure Backup は、作成された復旧ポイントがバックアップ ポリシーに従って、有効期限切れ前に削除されないようにできる不変コンテナーをサポートするようになりました。 また、不変性を元に戻せないようにして、ランサムウェア攻撃や悪意のあるアクターなど、さまざまな脅威からバックアップ データを最大限に保護することができます。 詳細については、こちらを参照してください。
事前登録スクリプトを実行する
フェールオーバーが発生すると、ユーザーは新しいプライマリにレプリケートされますが、hdbuserstore はレプリケートされません。 そのため、HSR セットアップのすべてのノードで同じキーを作成する必要があります。これにより、Azure Backup サービスは手動の介入なしに新しいプライマリ ノードに自動的に接続できます。
次のロールとアクセス許可を持つカスタム バックアップ ユーザーを HANA システムに作成します。
役割 権限 説明 MDC データベース管理者とバックアップ管理者 (HANA 2.0 SPS05 以降) 復元中に新しいデータベースを作成します。 SDC バックアップ管理者 バックアップ カタログを読み取ります。 SAP_INTERNAL_HANA_SUPPORT いくつかのプライベート テーブルにアクセスします。
HANA 2.0 SPS04 Rev 46 より前のバージョンの単一コンテナー データベース (SDC) と複数のコンテナー データベース (MDC) でのみ必要です。 これは、HANA 2.0 SPS04 Rev 46 以降では必要ありません。HANA チームからの修正プログラムの提供後、必要な情報はパブリック テーブルから入手することになるためです。例:
- hdbsql -t -U SYSTEMKEY CREATE USER USRBKP PASSWORD AzureBackup01 NO FORCE_FIRST_PASSWORD_CHANGE - hdbsql -t -U SYSTEMKEY 'ALTER USER USRBKP DISABLE PASSWORD LIFETIME' - hdbsql -t -U SYSTEMKEY 'ALTER USER USRBKP RESET CONNECT ATTEMPTS' - hdbsql -t -U SYSTEMKEY 'ALTER USER USRBKP ACTIVATE USER NOW' - hdbsql -t -U SYSTEMKEY 'GRANT DATABASE ADMIN TO USRBKP' - hdbsql -t -U SYSTEMKEY 'GRANT CATALOG READ TO USRBKP'カスタム バックアップ ユーザーの hdbuserstore にキーを追加します。これにより、HANA バックアップ プラグインですべての操作 (データベース クエリ、復元操作、構成、バックアップの実行) を管理できるようになります。
例:
- hdbuserstore set BKPKEY localhost:39013 USRBKP AzureBackup01このカスタム バックアップ ユーザー キーを、パラメーターとしてスクリプトに渡します。
-bk CUSTOM_BACKUP_KEY_NAME` or `-backup-key CUSTOM_BACKUP_KEY_NAMEこのカスタム バックアップ キーのパスワード有効期限が切れると、バックアップと復元操作は失敗します。
例:
hdbuserstore set SYSTEMKEY localhost:30013@SYSTEMDB <custom-user> '<some-password>' hdbuserstore set SYSTEMKEY <load balancer host/ip>:30013@SYSTEMDB <custom-user> '<some-password>'注意
仮想 IP (VIP) を使用するには、ローカル ホストではなくロード バランサーのホスト/IP を使用してカスタム バックアップ キーを作成してください。
図は、ローカル ホスト/IP を使用してカスタム バックアップ キーを作成する様子を示しています。

図は、仮想 IP (Load Balancer フロントエンド IP/ホスト) を使用してカスタム バックアップ キーを作成する様子を示しています。

両方の VM またはノードに同じ顧客バックアップ ユーザー (同じパスワードを持つ) とキー (hdbuserstore) を作成します。
スクリプトへの入力として一意の HSR ID を指定します。
-hn HSR_UNIQUE_VALUEまたは--hsr-unique-value HSR_Unique_Value。両方の VM またはノードで同じ HSR ID を指定する必要があります。 この ID は、コンテナー内で一意である必要があります。 これは、数字、小文字、大文字をそれぞれ 1 つ以上含む 6 から 35 文字の英数字の値にする必要があります。
例:
- ./script.sh -sk SYSTEMKEY -bk USRBKP -hn HSRlab001 -p 39013セカンダリ ノードで事前登録スクリプトを実行している間に、SDC または MDC ポートを入力として指定する必要があります。 これは、SDC/MDC セットアップを識別する SQL コマンドをセカンダリ ノードで実行できないためです。 次に示すように、パラメーターとしてポート番号を指定する必要があります。
-p PORT_NUMBERまたは–port_number PORT_NUMBER。- MDC の場合は、
3<instancenumber>13という形式を使用します。 - SDC の場合は、
3<instancenumber>15という形式を使用します。
例:
- MDC: ./script.sh -sk SYSTEMKEY -bk USRBKP -hn HSRlab001 -p 39013 - SDC: ./script.sh -sk SYSTEMKEY -bk USRBKP -hn HSRlab001 -p 39015- MDC の場合は、
HANA のセットアップでプライベート エンドポイントが使用されている場合は、
-snまたは--skip-network-checksのパラメーターを指定して事前登録スクリプトを実行します。 事前登録スクリプトが正常に実行されたら、次の手順に進みます。HANA がインストールされている VM で、SAP HANA バックアップ構成スクリプト (事前登録スクリプト) をルート ユーザーとして実行します。 このスクリプトは、HANA システムをバックアップ用に設定します。 スクリプトの挙動の詳細については、「事前登録スクリプトで実行される処理」セクションを参照してください。
HSR のセットアップのために HANA によって生成される一意の ID はありません。 そのため、バックアップ サービスが HSR のすべてのノードを 1 つのデータ ソースとしてグループ化するのに役立つ一意の ID を指定する必要があります。


バックアップ用にデータベースを設定するには、「前提条件」と「事前登録スクリプトで実行される処理」のセクションを参照してください。
データベースを検出する
HSR データベースを検出するには、次の手順に従います。
Azure portal で、[バックアップ センター] に移動し、[+ バックアップ] を選びます。
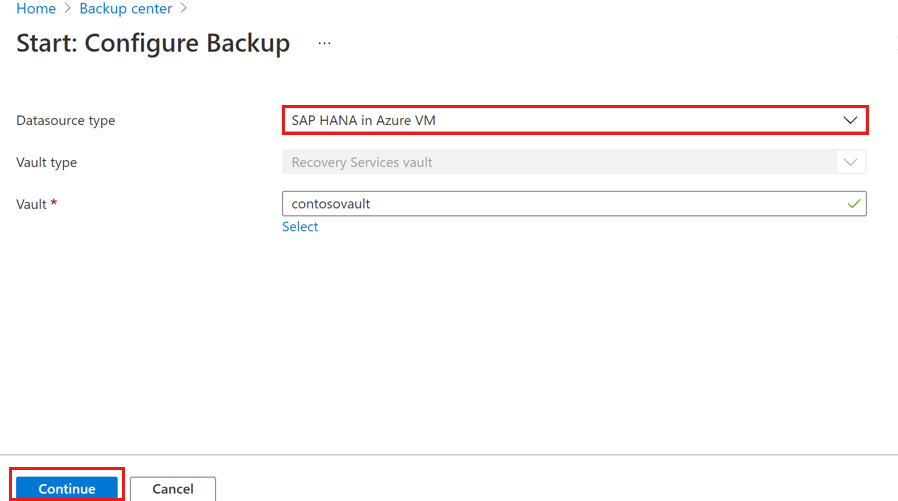
データ ソースの種類として [Azure VM の SAP HANA] を選び、バックアップに使う Recovery Services コンテナーを選んで、[続行] を選択します。
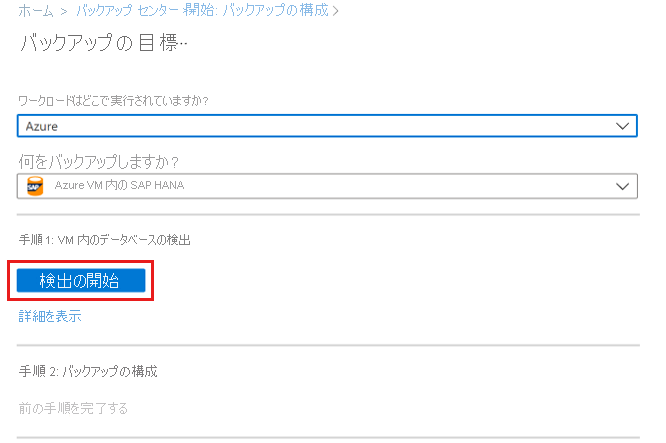
[検出の開始] を選び、コンテナー リージョン内の保護されていない Linux VM の検出を開始します。
- 検出後、保護されていない VM は、ポータルで名前およびリソース グループ別に一覧表示されます。
- VM が予期したとおりに一覧表示されない場合は、それが既にコンテナーにバックアップされているかどうかを確認してください。
- 複数の VM を同じ名前にすることはできますが、異なるリソース グループに含める必要があります。
[仮想マシンの選択] ペインの下部にある [このスクリプトを SAP HANA VM で実行し、Azure Backup サービスにこれらのアクセス許可を提供します] に含まれる "この" リンクを選びます。
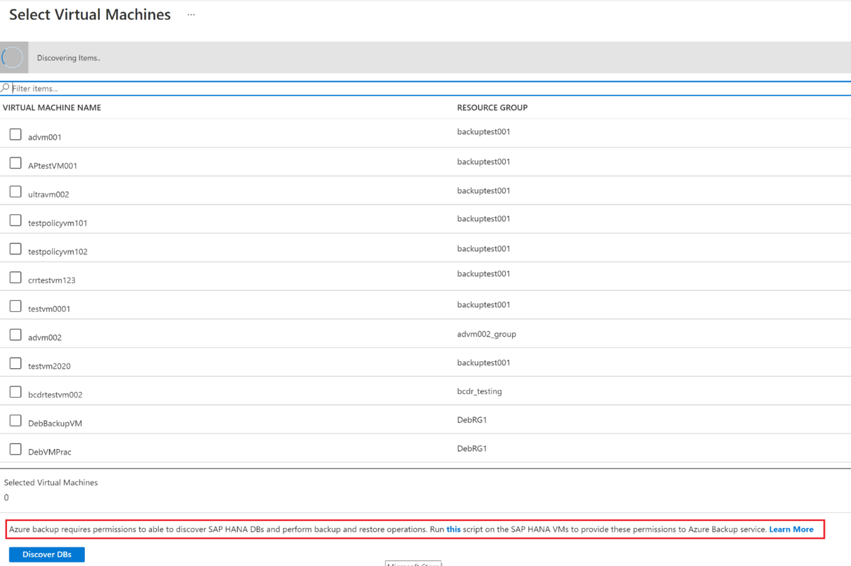
バックアップする SAP HANA データベースをホストしている各 VM でスクリプトを実行します。
[仮想マシンの選択] ペインで、VM に対してスクリプトを実行した後、VM を選んで、[Discover DBs] (DB の検出) を選びます。
Azure Backup によって、VM 上のすべての SAP HANA データベースが検出されます。 検出中に、Azure Backup によって VM がコンテナーに登録され、VM に拡張機能がインストールされます。 データベースにエージェントはインストールされません。
検出された各 VM のすべてのデータベースの詳細を表示するには、[手順 1: VM 内のデータベースを検出] セクションの下の [詳細の表示] を選びます。

注意
セカンダリ ノードでのバックアップの検出または構成中に、HSR のセカンダリ ノードに対して予期される状態であるために、[バックアップの準備] が [Not Ready](準備未完了) と表示される場合は、その状態を無視します。
![さまざまな [バックアップの準備] の状態を示すスクリーンショット。](media/sap-hana-database-with-hana-system-replication-backup/backup-readiness-state.png#lightbox)
バックアップの構成
バックアップを有効にするには、次の手順に従います。
[バックアップの目標] ペインの 手順 2 で、[バックアップの構成] を選びます。
![[バックアップの構成] ボタンを示すスクリーンショット。](media/sap-hana-database-with-hana-system-replication-backup/configure-database-backup.png)
[Select items to back up] (バックアップする項目の選択) ペインで、保護するデータベースをすべて選んで、[OK] を選びます。

[バックアップ ポリシー] ドロップダウン リストで、使用するポリシーを選んで、[追加] を選びます。
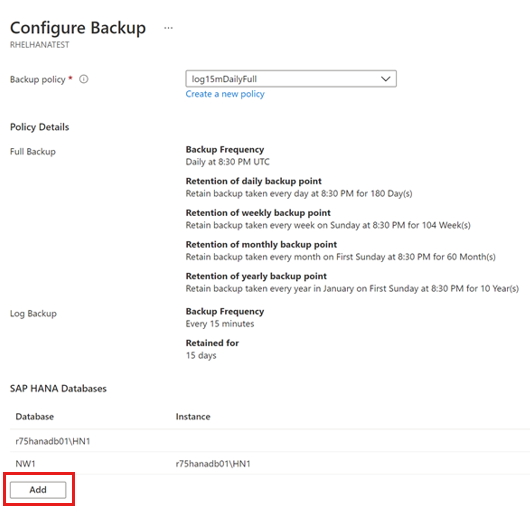
ポリシーを作成した後、[バックアップ] ペインで [バックアップの有効化] を選びます。
![データベースをバックアップするための [バックアップの有効化] ボタンを示すスクリーンショット。](media/sap-hana-database-with-hana-system-replication-backup/enable-backup.png)
バックアップ構成の進行状況を追跡するには、Azure portal の [通知] に移動します。

注意
"システム DB バックアップの構成" ステージでは、プライマリ ノードでこの パラメーターを設定する必要があります。[inifile_checker]/replicate これにより、プライマリからセカンダリ (ノードまたは VM) にパラメーターをレプリケートできます。
バックアップ ポリシーの作成
バックアップ ポリシーは、バックアップ スケジュールとバックアップ保有期間を定義します。
注意
- ポリシーはコンテナー レベルで作成されます。
- 複数のコンテナーでは同じバックアップ ポリシーを使用できますが、各コンテナーにバックアップ ポリシーを適用する必要があります。
- Azure Backup では、Azure VM で実行されている SAP HANA データベースをバックアップしている場合、夏時間変更に合わせた自動調整は行われません。 必要に応じて手動でポリシーを変更してください。
ポリシー設定を構成するには、次の手順に従います。
[バックアップ ポリシー] ペインの [ポリシー名] ボックスに、新しいポリシーの名前を入力します。
![ポリシー名を入力するための [バックアップ ポリシー] ペインを示すスクリーンショット。](media/sap-hana-database-with-hana-system-replication-backup/add-policy-name.png)
[完全バックアップ] の [バックアップの頻度] で、[毎日] または [毎週] を選びます。
[毎日]: バックアップ ジョブを開始しなければならない時刻とタイム ゾーンを選択します。
- 完全バックアップを実行する必要があります。 このオプションをオフにすることはできません。
- [完全バックアップ] を選択し、ポリシーを表示します。
- 日次の完全バックアップを選択する場合は、差分バックアップを作成できません。
[毎週]: バックアップ ジョブを開始しなければならない曜日、時刻、およびタイム ゾーンを選択します。
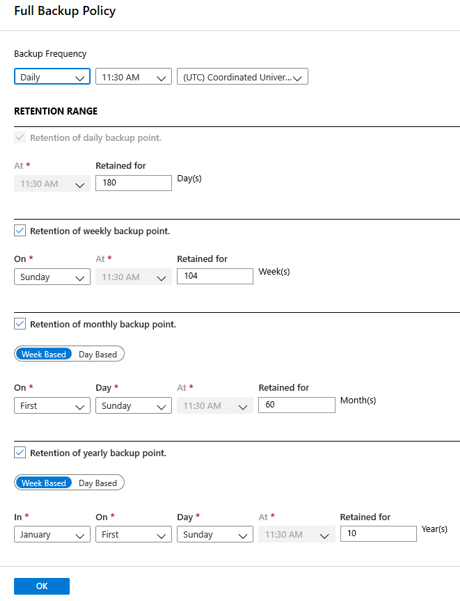
[完全バックアップ ポリシー] ペインの [保持期間] で、完全バックアップの保持設定を構成します。
- 既定では、すべてのオプションが選択されています。 使用しない保持期間の制限をすべてクリアしてから、必要に応じて設定します。
- バックアップのすべての種類 (完全/差分/ログ) の最小保持期間は 7 日間です。
- 復旧ポイントは、そのリテンション期間の範囲に基づいて、リテンション期間に対してタグ付けされます。 たとえば、日次での完全バックアップを選択した場合、日ごとにトリガーされる完全バックアップは 1 回だけです。
- 特定の曜日のバックアップがタグ付けされ、毎週の保持期間と設定に基づいて保持されます。
[OK] を選んで、ポリシー設定を保存します。
** [差分バックアップ]** を選択して、差分ポリシーを追加します。差分バックアップのポリシーで、 [有効] を選択して頻度とリテンション期間の制御を開きます。
- 最大で、1 日に 1 回の差分バックアップをトリガーできます。
- 差分バックアップは最大 180 日間保持できます。 より長い保持期間が必要な場合は、完全バックアップを使用する必要があります。
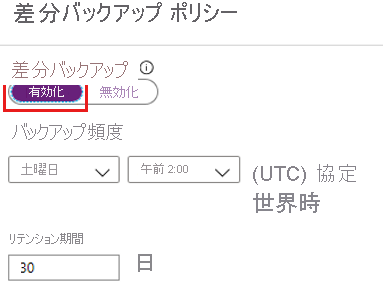
注意
指定された時刻における毎日のバックアップとしては、差分または増分のどちらかのバックアップを選ぶことができます。
[増分バックアップ ポリシー] ペインで、[有効] を選んで、頻度と保有期間の制御を開きます。
- 最大で、1 日に 1 回の増分バックアップをトリガーできます。
- 増分バックアップは最大 180 日間保持できます。 より長い保持期間が必要な場合は、完全バックアップを使用する必要があります。
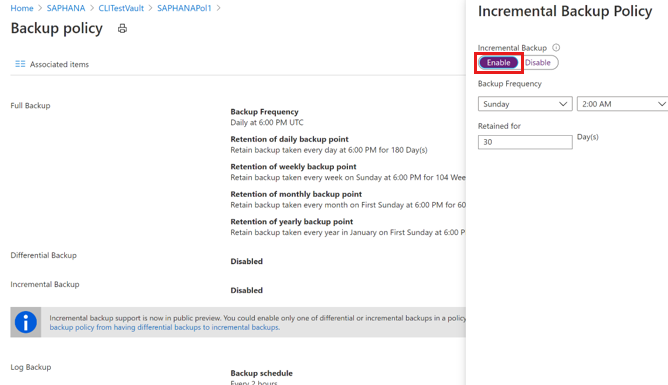
[OK] を選択してポリシーを保存し、 [バックアップ ポリシー] のメイン メニューに戻ります。
[ログ バックアップ] を選択し、トランザクションのログ バックアップ ポリシーを追加します。
** [ログ バックアップ]** で、** [有効化]** を選択します。SAP HANA ではすべてのログ バックアップが管理されるため、このオプションを無効にすることはできません。
頻度とリテンション期間の制御を設定します。
注意
完全バックアップが正常に完了した後にのみ、ログ バックアップのストリーミングが開始されます。
[OK] を選択してポリシーを保存し、 [バックアップ ポリシー] のメイン メニューに戻ります。
バックアップ ポリシーの構成が完了したら、[OK] を選択します。
復旧チェーンを形成するために、すべてのログ バックアップは以前の完全バックアップに関連付けられています。 完全バックアップは、最後のログ バックアップの有効期限が切れるまで保持されます。 このため、完全バックアップの保持期間を追加することで、すべてのログを確実に復旧することができます。
たとえば、完全バックアップを毎週、差分バックアップを毎日、ログ バックアップを "2 時間" ごとに行っているとします。 これらのすべてが "30 日間" 保持されます。 ただし、毎週の完全バックアップは、次の完全バックアップが利用可能になった後 (すなわち "30 + 7 日" 後) にのみ削除されます。
毎週の完全バックアップが 11 月 16 日に行われた場合は、保持ポリシーに従って 12 月 16 日 まで保持される必要があります。 この完全バックアップに対する最後のログ バックアップは、"11 月 22 日" に予定されている次の完全バックアップの前に行われます。 このログが 12 月 22 日 に利用可能になるまで、11 月 16 日の完全バックアップは削除されません。 そのため、"11 月" 16 日の完全バックアップは "12 月 22 日" まで保持されます。
オンデマンド バックアップを実行する
バックアップは、ポリシー スケジュールに従って実行されます。 オンデマンド バックアップを実行する方法を確認してください。
注意
計画されたフェールオーバーの実行前に、両方の VM またはノードがコンテナーに登録されていること (物理登録と論理登録) を確認します。 詳細については、こちらを参照してください。
Azure Backup のデータベースで SAP HANA ネイティブ クライアント バックアップを実行する
SAP HANA ネイティブ クライアントを使用して、Backint ではなくローカル ファイル システムへのオンデマンド バックアップを実行できます。 SAP ネイティブ クライアントを使用して操作を管理する方法をご覧ください。
Azure Backup で HSR ノードを保護するシナリオ
Azure Backup で Azure VM (スタンドアロン) 上の SAP HANA データベースの保護を HSR に切り替えられるようになりました。 HSR を既に構成し、Azure Backup を使用してプライマリ ノードのみを保護している場合は、プライマリ ノードとセカンダリ ノードの両方を保護するように構成を変更できます。
2 つのスタンドアロン/HSR ノードが Azure VM 上の SAP HANA Database バックアップを使用して保護されていない
(必須) プライマリ VM ノードとセカンダリ VM ノードの両方で最新の事前登録スクリプトを実行します。
注意
HSR ベースの属性は、最新の事前登録スクリプトに追加されます。
HSR を手動で構成するか、pacemaker などのクラスタリング ツールを使用して構成します。
HSR 構成が既に完了している場合は、次の手順に進みます。
これらの VM のバックアップを検出して構成します。
注意
HSR デプロイの場合、保護されたインスタンスのコストは HSR 論理コンテナー (プライマリとセカンダリの 2 つのノード) に請求され、1 つの HSR 論理コンテナーが形成されます。
計画フェールオーバーの実行前に、両方の VM またはノードがコンテナーに登録されていること (物理登録と論理登録) を確認します。
2 つのスタンドアロン VM/1 つのスタンドアロン VM が Azure VM 上の SAP HANA Database バックアップを使用して既に保護されている
バックアップを停止してデータを保持するには、Azure VM の [コンテナー]>[バックアップ項目]>[SAP HANA] に移動し、[詳細を表示]>[バックアップの停止]>[バックアップ データの保持]>[バックアップの停止] の順に選択します。
(必須) プライマリ VM ノードとセカンダリ VM ノードの両方で最新の事前登録スクリプトを実行します。
注意
HSR ベースの属性は、最新の事前登録スクリプトに追加されます。
HSR を手動で構成するか、pacemaker などのクラスタリング ツールを使用して構成します。
VM を検出し、HSR 論理インスタンスでバックアップを構成します。
注意
HSR デプロイの場合、保護されたインスタンスのコストは HSR 論理コンテナー (プライマリとセカンダリの 2 つのノード) に請求され、1 つの HSR 論理コンテナーが形成されます。
計画フェールオーバーの実行前に、両方の VM またはノードがコンテナーに登録されていること (物理登録と論理登録) を確認します。