データのランディング ゾーン
データ ランディング ゾーンは、仮想ネットワーク (VNet) ピアリングによってデータ管理ランディング ゾーンに接続されます。 各データ ランディング ゾーンは、Azure ランディング ゾーン アーキテクチャに関連するランディング ゾーンと見なされます。
重要
データ ランディング ゾーンをプロビジョニングする前に、DevOps と CI/CD 運用モデルを設定し、データ管理ランディング ゾーンをデプロイしておいてください。
各データ ランディング ゾーンには、それに含まれるサービス データ統合とデータ製品の機敏性を可能にする複数のレイヤーがあります。 標準のサービス セットを使用して新しいデータ ランディング ゾーンをデプロイし、データ ランディング ゾーンでデータのインジェストと分析を開始させることができます。
データ ランディング ゾーンに関連付けられる Azure サブスクリプションは次の構造になります。
| レイヤー | 必須 | リソース グループ |
|---|---|---|
| コア サービス | はい | |
| データ アプリケーション | 省略可能 |
|
| 視覚化 | オプション |
Note
データ アプリケーションによって、1 つ以上のデータ製品が生成されます。
データ ランディング ゾーンのアーキテクチャ
データ ランディング ゾーンのアーキテクチャには、レイヤー、それらのリソース グループ、各リソース グループに含まれるサービスが示されています。 さらに、このアーキテクチャにはデータ ランディング ゾーンに関連付けられているすべてのグループとロールの概要と、コントロールおよびデータ プレーンへのそれらのアクセスの範囲も示されています。

ヒント
データ ランディング ゾーンのデプロイを開始する前に、まず、デプロイする初期データ ランディング ゾーンの数を検討してください。
このアーキテクチャを開始点として使用します。 データ ランディング ゾーンの実装を計画する際は、Visio ファイルをダウンロードし、特定のビジネス要件や技術要件に合わせて変更してください。
コア サービス レイヤー
コア サービス レイヤーには、クラウド規模の分析のコンテキスト内でデータ ランディング ゾーンを有効にするために必要なすべてのサービスが含まれています。 次の表に、デプロイするすべてのデータ ランディング ゾーンで使用可能なサービスの標準スイートを提供するリソース グループを示します。
| リソース グループ | 必須 | 説明 |
|---|---|---|
| network-rg | はい | ネットワーク |
| databricks-monitoring-rg | 省略可能 | Azure Databricks ワークスペースの監視 |
| hive-rg | 省略可能 | Azure Databricks の Hive メタストア |
| storage-rg | はい | データ レイク サービス |
| external-data-rg | はい | アップロード インジェスト ストレージ |
| runtimes-rg | はい | 共有統合ランタイム |
| mgmt-rg | はい | CI/CD エージェント |
| metadata-ingestion-rg | 省略可能 | データに依存しないインジェスト |
| databricks-monitoring-rg | 省略可能 | ランディング ゾーン内の databricks ワークスペースの Log Analytics ワークスペース |
| shared-synapse-rg | 省略可能 | 共有 Azure Synapse |
| shared-databricks-rg | 省略可能 | 共有 Azure Databricks ワークスペース |
ネットワーク
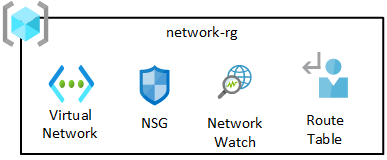
ネットワーク リソース グループには、Azure Network Watcher、ネットワーク セキュリティ グループ (NSG)、仮想ネットワークなどのコア コンポーネントが含まれています。 これらのサービスはすべて 1 つのリソース グループにデプロイされます。
データ ランディング ゾーンの仮想ネットワークは、データ管理ランディング ゾーンの VNet および接続サブスクリプションの VNet と自動的にピアリングされます。
Azure Databricks ワークスペースの監視
このリソース グループは省略可能であり、Azure Databricks でのみデプロイします。
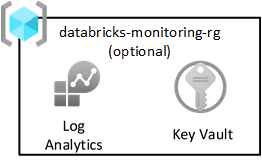
Azure ランディング ゾーン パターンでは、すべてのログを中央の Log Analytics ワークスペースに送信することが推奨されます。 ただし、各データ ランディング ゾーンには、Databricks から Spark ログをキャプチャするための監視リソース グループも含まれています。 各リソース グループには、共有 Log Analytics ワークスペースと、Log Analytics キーを格納するための Azure Key Vault が含まれています。
重要
Databricks 監視リソース グループの Log Analytics ワークスペースは、Databricks Spark ログのキャプチャのためにのみ使用します。
詳細については、「Azure Databricks の監視」を参照してください。
Azure Databricks の Hive メタストア
このリソース グループは省略可能であり、Azure Databricks でのみデプロイする必要があります。
Azure Databricks の Hive メタストアでは、Azure Database for MySQL データベースとキー コンテナーがプロビジョニングされます。 データ ランディング ゾーン内のすべての Azure Databricks ワークスペースによって、このメタストアが外部の Apache Hive メタストアとして使用されます。
詳細については、「外部 Apache Hive メタストア」を参照してください。
データ レイク サービス
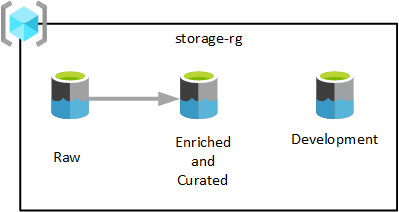
前の図に示すように、1 つのデータ レイク サービス リソース グループに 3 つの Azure Data Lake Storage Gen2 アカウントがプロビジョニングされます。 さまざまなステージで変換されたデータが、データ ランディング ゾーンのいずれかのデータ レイクに保存されます。 データは、分析、データ サイエンス、視覚化チームが使用できるようになります。
データ レイク レイヤーでは、テクノロジとベンダーによって異なる用語が使用されます。 次の表は、クラウド規模の分析に用語を適用する方法に関するガイダンスを示しています。
| クラウド規模の分析 | Delta Lake | その他の用語 | 説明 |
|---|---|---|---|
| Raw | ブロンズ | ランディングと適合性 | インジェスト テーブル |
| 強化 | シルバー | 標準化ゾーン | 改善されたテーブル。 レコードのシステムから完全なエンティティの消費対応レコードセットが格納されます。 |
| Curated | ゴールド | 製品ゾーン | 機能テーブルまたは集計テーブル。 アプリケーション、チーム、ユーザーがデータ製品を使用するためのプライマリ ゾーン。 |
| 開発 | -- | 開発ゾーン | 分析サンドボックスと製品開発ゾーンの両方で構成されるデータ エンジニアとデータ サイエンティスト用の場所。 |
Note
前の図では、各データランディング ゾーンに 3 つのデータ レイクがあります。 ただし、要件によっては、生、エンリッチ、キュレーション レイヤーを 1 つのストレージ アカウントに統合し、データ コンシューマーが他の有用なデータ製品を取り込むために、"開発" と呼ばれる別のストレージ アカウントを維持することが必要になる場合があります。
詳細については、次を参照してください。
- クラウド規模の分析での Azure Data Lake Storage の概要
- データの標準化
- データ ランディング ゾーンごとに Azure Data Lake Storage Gen2 アカウントをプロビジョニングする
- Azure Data Lake Storage に関する主な考慮事項
- Azure Data Lake Storage でのアクセス制御とデータ レイクの構成
アップロード インジェスト ストレージ
サードパーティのデータ発行元は、データ アプリケーション チームがそれぞれのデータ レイクにデータをプルできるように、データをプラットフォームに配置する必要があります。 次の図に示されているように、アップロード インジェスト ストレージ リソース グループにより、サードパーティ用の BLOB ストアをプロビジョニングできます。
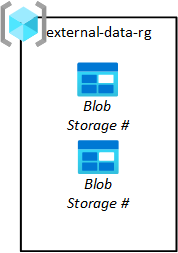
データ アプリケーション チームは、これらのストレージ BLOB を要求します。 その要求は、データランディング ゾーン運用チームによって承認されます。 データがストレージ BLOB から生にプルされたら、それをソース ストレージ BLOB から削除する必要があります。
重要
Azure Storage Blob は "必要に応じて" プロビジョニングされるため、最初に、各データ ランディング ゾーンに空のストレージ サービス リソース グループをデプロイする必要があります。
共有統合ランタイム
仮想マシンを、セルフホステッド統合ランタイムと共にデータ ランディング ゾーンにデプロイします。 それを共有統合リソース グループでホストします。 このデプロイにより、データ製品をデータ ランディング ゾーンに迅速にオンボードできます。
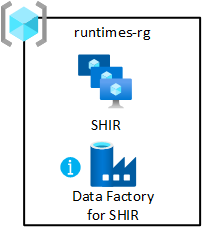
リソース グループを有効にするには:
- データ ランディング ゾーンの共有統合リソース グループに、少なくとも 1 つの Azure Data Factory を作成します。 それは、データ パイプライン用ではなく共有セルフホステッド統合ランタイムをリンクするためだけに使用します。
- 仮想マシンにセルフホステッド統合ランタイムを作成して構成します。
- セルフホステッド統合ランタイムを、データ ランディング ゾーン内の Azure Data Factory に関連付けます。
- セルフ ホステッド統合ランタイムを定期的に更新するように Azure Automation を設定します。
Note
上記のデプロイでは、セルフホステッド統合ランタイムを使用した単一の仮想マシンのデプロイが提供されます。 セルフホステッド統合ランタイムを複数のオンプレミス マシンまたは Azure の仮想マシンに関連付けることができます。 これらのコンピューターは、ノードと呼ばれます。 セルフホステッド統合ランタイムには最大で 4 つのノードを関連付けることができます。 論理ゲートウェイ用にゲートウェイがインストールされているオンプレミス コンピューターに複数のノードを配置すると、次のような利点があります。
- セルフホステッド統合ランタイムの可用性の向上によって、ビッグ データ ソリューションまたはクラウド データ統合における単一障害点がなくなります。 この可用性により、最大 4 つのノードを使用する場合に継続性が確保されます。
- オンプレミスとクラウド データ ストアとの間のデータ移動は、パフォーマンスとスループットが向上しました。 詳しくはパフォーマンス比較を参照してください。
セルフホステッド統合ランタイム ソフトウェアをダウンロード センターからインストールして、複数のノードを関連付けることができます。 その後、チュートリアルの説明に従って、New-AzDataFactoryV2IntegrationRuntimeKey コマンドレットから取得した認証キーのいずれかを使用して、登録します。
詳細については、Azure Datafactory の高可用性とスケーラビリティに関するページを参照してください。
重要
共有統合ランタイムは可能な限りデータ ソースの近くにデプロイします。 それらのデプロイによって、データ ランディング ゾーン内、またはサードパーティのクラウドへの統合ランタイムのデプロイが制限されることはありません。 代わりに、クラウド ネイティブのリージョン内データ ソースにフォールバックが提供されます。
CI/CD エージェント
CI/CD エージェントは、データランディング ゾーンへのデータ アプリケーションと変更をデプロイするのに役立ちます。
詳細については、「Azure Pipeline エージェント」を参照してください。
データに依存しないインジェスト
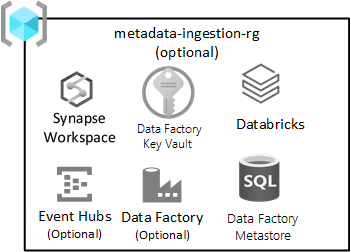
このリソース グループは省略可能であり、ランディング ゾーンのデプロイを禁止するものではありません。
このリソース グループは、登録するメタデータ (接続文字列、データのコピー元とコピー先のパス、インジェスト スケジュールなど) に基づいてデータを自動的に取り込むためのデータに依存しないインジェスト エンジンがある (または開発している) 場合に適用されます。 インジェストおよび処理リソース グループには、この種類のフレームワークの主要なサービスがあります。
Azure Data Factory によって使用されるメタデータを保持する Azure SQL Database インスタンスをデプロイします。 自動インジェスト サービスに関連するシークレットを格納するための Azure Key Vault をプロビジョニングします。 これらのシークレットには、次のものが含まれる可能性があります。
- Azure Data Factory メタストアの資格情報
- 自動インジェスト プロセス用のサービス プリンシパルの資格情報
詳細については、自動インジェスト フレームワークで Azure のクラウド規模の分析をサポートする方法に関するページを参照してください。
このリソース グループに含まれるサービスには次のものがあります。
| サービス | 必須 | ガイドライン |
|---|---|---|
| Azure Data Factory | はい | Azure Data Factory は、データに依存しないインジェストのためのオーケストレーション エンジンです。 |
| Azure SQL DB | はい | Azure SQL DB は、Azure Data Factory のメタストアです。 |
| Event Hubs または IoT Hub | オプション | Event Hubs または IoT Hub では、Event Hubs へのリアルタイム ストリーミングと、Databricks エンジニアリング ワークスペースを介したバッチとストリーミングの処理を行うことができます。 |
| Azure Databricks | 省略可能 | Azure Databricks または Azure Synapse Spark をデプロイして、データに依存しないインジェスト エンジンで使用できます。 |
| Azure Synapse | 省略可能 | Azure Databricks または Azure Synapse Spark をデプロイして、データに依存しないインジェスト エンジンで使用できます。 |
共有 Databricks
このリソース グループは省略可能であり、Azure Databricks でのみデプロイします。 データ ランディング ゾーンのすべてのユーザーが Databricks ワークスペースを使用できます。
Azure Databricks は、Azure Data Lake Storage サービスの主要なコンシューマーです。 アトミック ファイル操作は、Spark 分析エンジン用に最適化されています。 この最適化により、Azure Databricks サービスによって発行された Spark ジョブの完了が高速化されます。
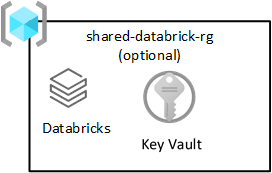
重要
共有製品リソース グループに示されているように、Azure Databricks (分析) ワークスペースを呼び出した Azure Databricks ワークスペースがデータ サイエンティストと DataOps 向けに、プロビジョニングされます。
このワークスペースは、Microsoft Entra パススルーまたはテーブル アクセス制御を使用して Azure Data Lake に接続するように構成できます。 ユース ケースに応じて、別のセキュリティ対策として条件付きアクセスを構成できます。
クラウド規模の分析のベスト プラクティスに従って、Azure Databricks を統合します。
Azure ランディング ゾーン パターンでは、すべてのログを中央の Log Analytics ワークスペースに送信することが推奨されます。 ただし、各データ ランディング ゾーンには、Databricks から Spark ログをキャプチャするための監視リソース グループも含まれています。
共有 Azure Synapse Analytics
このリソース グループは省略可能です。
データ ランディング ゾーンの初期セットアップ時に、1 つの Azure Synapse Analytics ワークスペースがデプロイされ、共有製品リソース グループ内のすべてのデータ アナリストおよびデータ サイエンティストが使用できます。
コスト管理と再チャージが必要な場合は、データ製品用に追加の Synapse ワークスペースを設定できます。 データ アプリケーション チームは、視覚化レイヤーで使用される読み取りデータ ストアとして専用の Azure SQL Database プールを作成するために、専用の Azure Synapse Analytics ワークスペースを使用する場合があります。
重要
ワークスペースをロックダウンして SQL オンデマンド クエリのみを許可することで、データ製品の作成に共有 Azure Synapse ワークスペースを使用できないようにします。 これは開発目的でのみ存在します。
データ アプリケーション
各データ ランディング ゾーンには複数のデータ製品を含めることができます。 ソースからデータを取り込むことで、これらのデータ製品を作成できます。 また、同じデータ ランディング ゾーン内または他のデータランディング ゾーンのデータ製品からデータ製品を作成することもできます。 データ製品のデータ製品作成は、データ スチュワードによる承認の対象です。
データ製品リソース グループ
データ製品リソース グループ製品には、そのデータ製品を作成するために必要なすべてのサービスが含まれています。 たとえば、MySQL には Azure Database が必要であり、それは視覚化ツールによって使用されます。 データはその MySQL データベースに配置する前に、取り込んで変換する必要があります。 この場合、Azure Database for MySQL と Azure Data Factory をデータ製品リソース グループにデプロイすることができます。
ヒント
運用ソースから 1 回取り込むためにデータに依存しないエンジンを実装しない場合、またはデータに依存しないエンジンでは複雑な接続の助けにならない場合は、ソースアラインのデータ アプリケーションを作成します。 詳細については、「データ アプリケーション (ソースアライン)」を参照してください
データ製品をオンボードする方法の詳細については、「Azure でのクラウド規模の分析データ製品」を参照してください。
グラフ
データ ランディング ゾーンごとに、空の視覚化リソース グループが作成されます。 このリソース グループに、視覚化ソリューションを実装するために必要なサービスを含めます。 既存の VNet を使用して、自分のソリューションからデータ製品に接続させます。
このリソース グループでサードパーティの視覚化サービス用の仮想マシンをホストできます。
ヒント
ライセンス コストのため、サードパーティの視覚化製品をデータ管理のランディング ゾーンにデプロイし、それらの製品でデータ ランディング ゾーンにまたがって接続してデータをプルする方が経済的な場合があります。