カスタム エンティティ パターン マッチングを使用して意図を認識する方法
Azure AI サービスの Speech SDK は、単純な言語パターン マッチングによる意図認識を提供する組み込み機能です。 意図とは、ウィンドウを閉じる、チェック ボックスをオンにする、テキストを挿入するなど、ユーザーが行いたいと思っている何らかの操作です。
このガイドでは、Speech SDK を使用して、デバイスのマイクを通した発話から意図を抽出するコンソール アプリケーションを開発します。 学習内容は次のとおりです。
- Speech SDK NuGet パッケージを参照する Visual Studio プロジェクトを作成する
- 音声構成を作成して意図認識エンジンを取得する
- Speech SDK API を使用して意図とパターンを追加する
- Speech SDK API を使用してカスタム エンティティを追加する
- 非同期のイベント ドリブンの継続的な認識を使用する
パターン マッチングを使う場合
次の場合にパターン マッチングを使用します。
- ユーザーが言ったことの厳密なマッチングにのみ関心がある。 これらのパターンでは、会話言語理解 (CLU) より積極的にマッチングされます。
- CLU モデルにアクセスできないが、それでも意図が必要である。
詳細については、「パターン マッチングの概要」を参照してください。
前提条件
このガイドを開始する前に、次の項目を用意する必要があります。
- Azure AI サービス リソースまたは Unified Speech リソース
- Visual Studio 2019 (任意のエディション)。
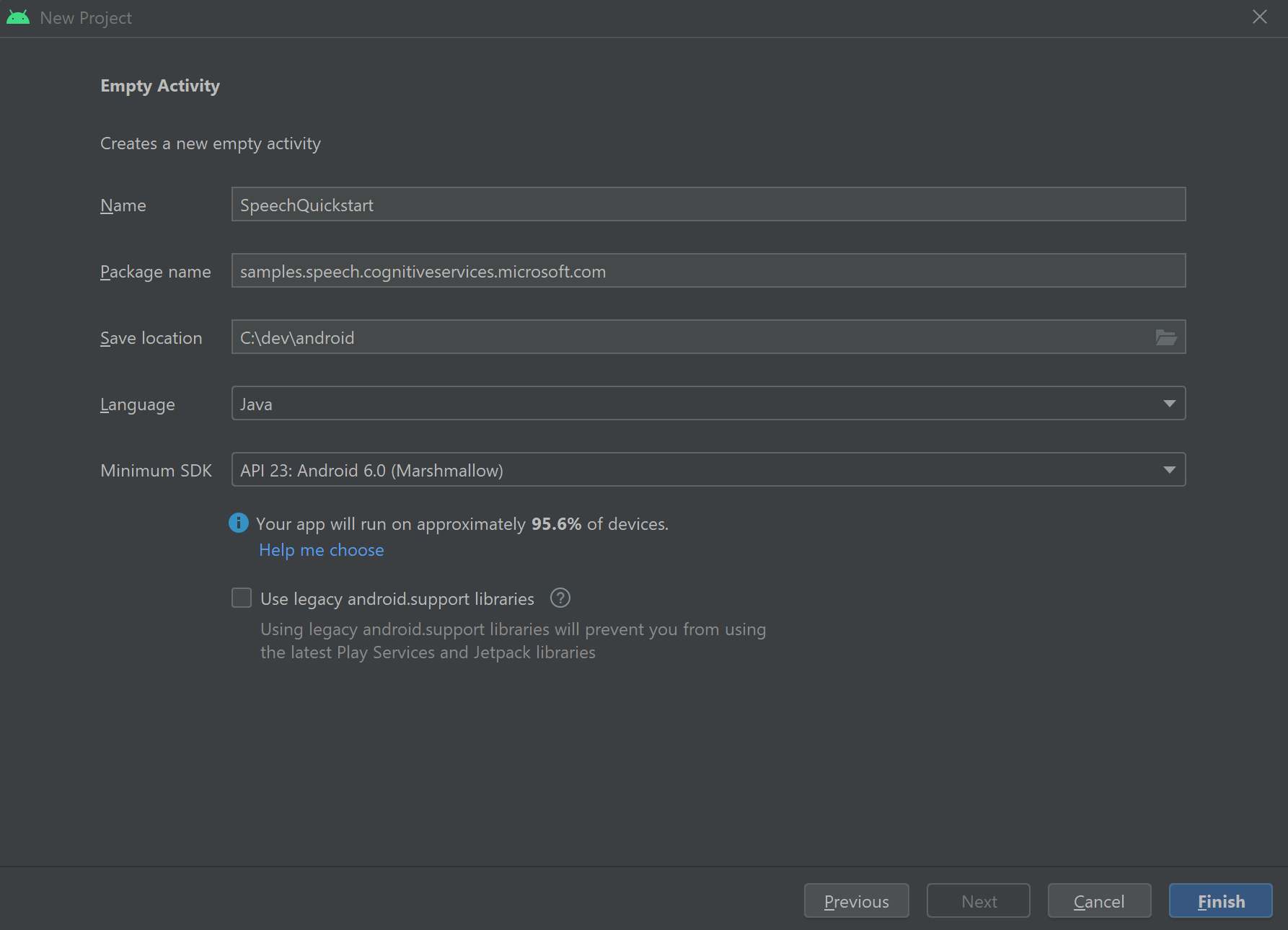
プロジェクトの作成
Visual Studio 2019 で新しい C# コンソール アプリケーション プロジェクトを作成し、Speech SDK をインストールします。
定型コードを使用して開始する
Program.cs を開き、このプロジェクトのスケルトンとして機能するコードを追加しましょう。
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
static void Main(string[] args)
{
IntentPatternMatchingWithMicrophoneAsync().Wait();
}
private static async Task IntentPatternMatchingWithMicrophoneAsync()
{
var config = SpeechConfig.FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
}
}
Speech 構成を作成する
IntentRecognizer オブジェクトを初期化する前に、Azure AI サービス予測リソース用のキーと Azure リージョンを使用する構成を作成する必要があります。
"YOUR_SUBSCRIPTION_KEY"を、Azure AI サービスの実際の予測キーに置き換えます。"YOUR_SUBSCRIPTION_REGION"を Azure AI サービスの実際のリソース リージョンに置き換えます。
このサンプルでは、FromSubscription() メソッドを使用して SpeechConfig をビルドします。 使用可能なメソッドの完全な一覧については、SpeechConfig クラスに関する記事を参照してください。
IntentRecognizer を初期化する
次に、IntentRecognizer を作成します。 Speech 構成のすぐ下にこのコードを挿入します。
using (var recognizer = new IntentRecognizer(config))
{
}
意図を追加する
いくつかのパターンを PatternMatchingModel と関連付け、それを IntentRecognizer に適用する必要があります。
まず PatternMatchingModel を作成し、いくつかの意図を追加します。
注意
PatternMatchingIntent には複数のパターンを追加できます。
このコードを using ブロック内に挿入します。
// Creates a Pattern Matching model and adds specific intents from your model. The
// Id is used to identify this model from others in the collection.
var model = new PatternMatchingModel("YourPatternMatchingModelId");
// Creates a pattern that uses groups of optional words. "[Go | Take me]" will match either "Go", "Take me", or "".
var patternWithOptionalWords = "[Go | Take me] to [floor|level] {floorName}";
// Creates a pattern that uses an optional entity and group that could be used to tie commands together.
var patternWithOptionalEntity = "Go to parking [{parkingLevel}]";
// You can also have multiple entities of the same name in a single pattern by adding appending a unique identifier
// to distinguish between the instances. For example:
var patternWithTwoOfTheSameEntity = "Go to floor {floorName:1} [and then go to floor {floorName:2}]";
// NOTE: Both floorName:1 and floorName:2 are tied to the same list of entries. The identifier can be a string
// and is separated from the entity name by a ':'
// Creates the pattern matching intents and adds them to the model
model.Intents.Add(new PatternMatchingIntent("ChangeFloors", patternWithOptionalWords, patternWithOptionalEntity, patternWithTwoOfTheSameEntity));
model.Intents.Add(new PatternMatchingIntent("DoorControl", "{action} the doors", "{action} doors", "{action} the door", "{action} door"));
いくつかのカスタム エンティティを追加する
パターン マッチャーを最大限に活用するために、エンティティをカスタマイズすることができます。 "floorName" を利用可能なフロアのリストにします。 また、"parkingLevel" を、整数のエンティティにします。
このコードを意図の下に挿入します。
// Creates the "floorName" entity and set it to type list.
// Adds acceptable values. NOTE the default entity type is Any and so we do not need
// to declare the "action" entity.
model.Entities.Add(PatternMatchingEntity.CreateListEntity("floorName", EntityMatchMode.Strict, "ground floor", "lobby", "1st", "first", "one", "1", "2nd", "second", "two", "2"));
// Creates the "parkingLevel" entity as a pre-built integer
model.Entities.Add(PatternMatchingEntity.CreateIntegerEntity("parkingLevel"));
モデルを認識エンジンに適用する
ここで、モデルを IntentRecognizer に適用する必要があります。 複数のモデルを一度に使用して、API がモデルのコレクションを取得するようにすることができます。
このコードをエンティティの下に挿入します。
var modelCollection = new LanguageUnderstandingModelCollection();
modelCollection.Add(model);
recognizer.ApplyLanguageModels(modelCollection);
意図を認識する
IntentRecognizer オブジェクトから、RecognizeOnceAsync() メソッドを呼び出します。 このメソッドは、Speech サービスに対して、1 つのフレーズで音声を認識し、フレーズが識別されたら音声の認識を停止するよう要求します。
言語モデルを適用した後、次のコードを挿入します。
Console.WriteLine("Say something...");
var result = await recognizer.RecognizeOnceAsync();
認識結果 (またはエラー) を表示する
Speech サービスによって認識結果が返されたら、結果を出力します。
次のコードを var result = await recognizer.RecognizeOnceAsync(); の下に挿入します。
if (result.Reason == ResultReason.RecognizedIntent)
{
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id={result.IntentId}.");
var entities = result.Entities;
switch (result.IntentId)
{
case "ChangeFloors":
if (entities.TryGetValue("floorName", out string floorName))
{
Console.WriteLine($" FloorName={floorName}");
}
if (entities.TryGetValue("floorName:1", out floorName))
{
Console.WriteLine($" FloorName:1={floorName}");
}
if (entities.TryGetValue("floorName:2", out floorName))
{
Console.WriteLine($" FloorName:2={floorName}");
}
if (entities.TryGetValue("parkingLevel", out string parkingLevel))
{
Console.WriteLine($" ParkingLevel={parkingLevel}");
}
break;
case "DoorControl":
if (entities.TryGetValue("action", out string action))
{
Console.WriteLine($" Action={action}");
}
break;
}
}
else if (result.Reason == ResultReason.RecognizedSpeech)
{
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
}
else if (result.Reason == ResultReason.NoMatch)
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
}
else if (result.Reason == ResultReason.Canceled)
{
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?");
}
}
コードを確認する
この時点で、コードは次のようになります。
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
static void Main(string[] args)
{
IntentPatternMatchingWithMicrophoneAsync().Wait();
}
private static async Task IntentPatternMatchingWithMicrophoneAsync()
{
var config = SpeechConfig.FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
using (var recognizer = new IntentRecognizer(config))
{
// Creates a Pattern Matching model and adds specific intents from your model. The
// Id is used to identify this model from others in the collection.
var model = new PatternMatchingModel("YourPatternMatchingModelId");
// Creates a pattern that uses groups of optional words. "[Go | Take me]" will match either "Go", "Take me", or "".
var patternWithOptionalWords = "[Go | Take me] to [floor|level] {floorName}";
// Creates a pattern that uses an optional entity and group that could be used to tie commands together.
var patternWithOptionalEntity = "Go to parking [{parkingLevel}]";
// You can also have multiple entities of the same name in a single pattern by adding appending a unique identifier
// to distinguish between the instances. For example:
var patternWithTwoOfTheSameEntity = "Go to floor {floorName:1} [and then go to floor {floorName:2}]";
// NOTE: Both floorName:1 and floorName:2 are tied to the same list of entries. The identifier can be a string
// and is separated from the entity name by a ':'
// Adds some intents to look for specific patterns.
model.Intents.Add(new PatternMatchingIntent("ChangeFloors", patternWithOptionalWords, patternWithOptionalEntity, patternWithTwoOfTheSameEntity));
model.Intents.Add(new PatternMatchingIntent("DoorControl", "{action} the doors", "{action} doors", "{action} the door", "{action} door"));
// Creates the "floorName" entity and set it to type list.
// Adds acceptable values. NOTE the default entity type is Any and so we do not need
// to declare the "action" entity.
model.Entities.Add(PatternMatchingEntity.CreateListEntity("floorName", EntityMatchMode.Strict, "ground floor", "lobby", "1st", "first", "one", "1", "2nd", "second", "two", "2"));
// Creates the "parkingLevel" entity as a pre-built integer
model.Entities.Add(PatternMatchingEntity.CreateIntegerEntity("parkingLevel"));
var modelCollection = new LanguageUnderstandingModelCollection();
modelCollection.Add(model);
recognizer.ApplyLanguageModels(modelCollection);
Console.WriteLine("Say something...");
var result = await recognizer.RecognizeOnceAsync();
if (result.Reason == ResultReason.RecognizedIntent)
{
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id={result.IntentId}.");
var entities = result.Entities;
switch (result.IntentId)
{
case "ChangeFloors":
if (entities.TryGetValue("floorName", out string floorName))
{
Console.WriteLine($" FloorName={floorName}");
}
if (entities.TryGetValue("floorName:1", out floorName))
{
Console.WriteLine($" FloorName:1={floorName}");
}
if (entities.TryGetValue("floorName:2", out floorName))
{
Console.WriteLine($" FloorName:2={floorName}");
}
if (entities.TryGetValue("parkingLevel", out string parkingLevel))
{
Console.WriteLine($" ParkingLevel={parkingLevel}");
}
break;
case "DoorControl":
if (entities.TryGetValue("action", out string action))
{
Console.WriteLine($" Action={action}");
}
break;
}
}
else if (result.Reason == ResultReason.RecognizedSpeech)
{
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
}
else if (result.Reason == ResultReason.NoMatch)
{
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
}
else if (result.Reason == ResultReason.Canceled)
{
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?");
}
}
}
}
}
}
アプリをビルドして実行する
これで、アプリをビルドし、Speech サービスを使用して音声認識をテストする準備ができました。
- コードをコンパイルする - Visual Studio のメニュー バーで、 [ビルド]>[ソリューションのビルド] の順に選択します。
- アプリを起動する - メニュー バーから [デバッグ]>[デバッグの開始] の順に選択するか、F5 キーを押します。
- 認識を開始する - ユーザーに何か話すように要求します。 既定の言語は English (英語) です。 音声が Speech Service に送信され、テキストとして文字起こしされて、コンソールに表示されます。
たとえば、"Take me to floor 2" (2 階に行く) と言った場合、次の出力が表示されます。
Say something...
RECOGNIZED: Text=Take me to floor 2.
Intent Id=ChangeFloors.
FloorName=2
別の例として、"Take me to floor 7" (7 階に行く) と言った場合の出力は、次のとおりです。
Say something...
RECOGNIZED: Text=Take me to floor 7.
Intent not recognized.
floorName の有効な値の一覧に 7 がなかったため、意図が認識されませんでした。
プロジェクトの作成
Visual Studio 2019 で新しい C++ コンソール アプリケーション プロジェクトを作成し、Speech SDK をインストールします。
定型コードを使用して開始する
helloworld.cpp を開き、このプロジェクトのスケルトンとして機能するコードを追加しましょう。
#include <iostream>
#include <speechapi_cxx.h>
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
int main()
{
std::cout << "Hello World!\n";
auto config = SpeechConfig::FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
Speech 構成を作成する
IntentRecognizer オブジェクトを初期化する前に、Azure AI サービス予測リソース用のキーと Azure リージョンを使用する構成を作成する必要があります。
"YOUR_SUBSCRIPTION_KEY"を、Azure AI サービスの実際の予測キーに置き換えます。"YOUR_SUBSCRIPTION_REGION"を Azure AI サービスの実際のリソース リージョンに置き換えます。
このサンプルでは、FromSubscription() メソッドを使用して SpeechConfig をビルドします。 使用可能なメソッドの完全な一覧については、SpeechConfig クラスに関する記事を参照してください。
IntentRecognizer を初期化する
次に、IntentRecognizer を作成します。 Speech 構成のすぐ下にこのコードを挿入します。
auto intentRecognizer = IntentRecognizer::FromConfig(config);
意図を追加する
いくつかのパターンを PatternMatchingModel と関連付け、それを IntentRecognizer に適用する必要があります。
まず PatternMatchingModel を作成し、いくつかの意図を追加します。 PatternMatchingIntent は構造体であるため、インライン構文を使用します。
注意
PatternMatchingIntent には複数のパターンを追加できます。
auto model = PatternMatchingModel::FromId("myNewModel");
model->Intents.push_back({"Take me to floor {floorName}.", "Go to floor {floorName}."} , "ChangeFloors");
model->Intents.push_back({"{action} the door."}, "OpenCloseDoor");
いくつかのカスタム エンティティを追加する
パターン マッチャーを最大限に活用するために、エンティティをカスタマイズすることができます。 "floorName" を利用可能なフロアのリストにします。
model->Entities.push_back({ "floorName" , Intent::EntityType::List, Intent::EntityMatchMode::Strict, {"one", "1", "two", "2", "lobby", "ground floor"} });
モデルを認識エンジンに適用する
ここで、モデルを IntentRecognizer に適用する必要があります。 複数のモデルを一度に使用して、API がモデルのコレクションを取得するようにすることができます。
std::vector<std::shared_ptr<LanguageUnderstandingModel>> collection;
collection.push_back(model);
intentRecognizer->ApplyLanguageModels(collection);
意図を認識する
IntentRecognizer オブジェクトから、RecognizeOnceAsync() メソッドを呼び出します。 このメソッドは、Speech サービスに対して、1 つのフレーズで音声を認識し、フレーズが識別されたら音声の認識を停止するよう要求します。 簡素化のため、結果が返されて完了するまで待機します。
このコードを意図の下に挿入します。
std::cout << "Say something ..." << std::endl;
auto result = intentRecognizer->RecognizeOnceAsync().get();
認識結果 (またはエラー) を表示する
Speech サービスによって認識結果が返されたら、結果を出力します。
次のコードを auto result = intentRecognizer->RecognizeOnceAsync().get(); の下に挿入します。
switch (result->Reason)
{
case ResultReason::RecognizedSpeech:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << "NO INTENT RECOGNIZED!" << std::endl;
break;
case ResultReason::RecognizedIntent:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << " Intent Id = " << result->IntentId.c_str() << std::endl;
auto entities = result->GetEntities();
if (entities.find("floorName") != entities.end())
{
std::cout << " Floor name: = " << entities["floorName"].c_str() << std::endl;
}
if (entities.find("action") != entities.end())
{
std::cout << " Action: = " << entities["action"].c_str() << std::endl;
}
break;
case ResultReason::NoMatch:
{
auto noMatch = NoMatchDetails::FromResult(result);
switch (noMatch->Reason)
{
case NoMatchReason::NotRecognized:
std::cout << "NOMATCH: Speech was detected, but not recognized." << std::endl;
break;
case NoMatchReason::InitialSilenceTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::InitialBabbleTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::KeywordNotRecognized:
std::cout << "NOMATCH: Keyword not recognized" << std::endl;
break;
}
break;
}
case ResultReason::Canceled:
{
auto cancellation = CancellationDetails::FromResult(result);
if (!cancellation->ErrorDetails.empty())
{
std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails.c_str() << std::endl;
std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl;
}
}
default:
break;
}
コードを確認する
この時点で、コードは次のようになります。
#include <iostream>
#include <speechapi_cxx.h>
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
int main()
{
auto config = SpeechConfig::FromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
auto intentRecognizer = IntentRecognizer::FromConfig(config);
auto model = PatternMatchingModel::FromId("myNewModel");
model->Intents.push_back({"Take me to floor {floorName}.", "Go to floor {floorName}."} , "ChangeFloors");
model->Intents.push_back({"{action} the door."}, "OpenCloseDoor");
model->Entities.push_back({ "floorName" , Intent::EntityType::List, Intent::EntityMatchMode::Strict, {"one", "1", "two", "2", "lobby", "ground floor"} });
std::vector<std::shared_ptr<LanguageUnderstandingModel>> collection;
collection.push_back(model);
intentRecognizer->ApplyLanguageModels(collection);
std::cout << "Say something ..." << std::endl;
auto result = intentRecognizer->RecognizeOnceAsync().get();
switch (result->Reason)
{
case ResultReason::RecognizedSpeech:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << "NO INTENT RECOGNIZED!" << std::endl;
break;
case ResultReason::RecognizedIntent:
std::cout << "RECOGNIZED: Text = " << result->Text.c_str() << std::endl;
std::cout << " Intent Id = " << result->IntentId.c_str() << std::endl;
auto entities = result->GetEntities();
if (entities.find("floorName") != entities.end())
{
std::cout << " Floor name: = " << entities["floorName"].c_str() << std::endl;
}
if (entities.find("action") != entities.end())
{
std::cout << " Action: = " << entities["action"].c_str() << std::endl;
}
break;
case ResultReason::NoMatch:
{
auto noMatch = NoMatchDetails::FromResult(result);
switch (noMatch->Reason)
{
case NoMatchReason::NotRecognized:
std::cout << "NOMATCH: Speech was detected, but not recognized." << std::endl;
break;
case NoMatchReason::InitialSilenceTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only silence, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::InitialBabbleTimeout:
std::cout << "NOMATCH: The start of the audio stream contains only noise, and the service timed out waiting for speech." << std::endl;
break;
case NoMatchReason::KeywordNotRecognized:
std::cout << "NOMATCH: Keyword not recognized." << std::endl;
break;
}
break;
}
case ResultReason::Canceled:
{
auto cancellation = CancellationDetails::FromResult(result);
if (!cancellation->ErrorDetails.empty())
{
std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails.c_str() << std::endl;
std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl;
}
}
default:
break;
}
}
アプリをビルドして実行する
これで、アプリをビルドし、Speech サービスを使用して音声認識をテストする準備ができました。
- コードをコンパイルする - Visual Studio のメニュー バーで、 [ビルド]>[ソリューションのビルド] の順に選択します。
- アプリを起動する - メニュー バーから [デバッグ]>[デバッグの開始] の順に選択するか、F5 キーを押します。
- 認識を開始する - ユーザーに何か話すように要求します。 既定の言語は English (英語) です。 音声が Speech Service に送信され、テキストとして文字起こしされて、コンソールに表示されます。
たとえば、"Take me to floor 2" (2 階に行く) と言った場合、次の出力が表示されます。
Say something ...
RECOGNIZED: Text = Take me to floor 2.
Intent Id = ChangeFloors
Floor name: = 2
別の例として、"Take me to floor 7" (7 階に行く) と言った場合、次の出力が表示されます。
Say something ...
RECOGNIZED: Text = Take me to floor 7.
NO INTENT RECOGNIZED!
7 がリストに含まれていなかったため、インテント ID は空です。
リファレンス ドキュメント | GitHub のその他のサンプル
このクイックスタートでは、Speech SDK for Java をインストールします。
プラットフォームの要件
ターゲット環境を選択してください。
Speech SDK for Java は、Windows、Linux、macOS との互換性があります。
Windows では、64 ビット ターゲット アーキテクチャを使う必要があります。 Windows 10 以降が必要です。
お使いのプラットフォームに対応した Visual Studio 2015、2017、2019、2022 の Microsoft Visual C++ 再頒布可能パッケージをインストールします。 このパッケージを初めてインストールする場合、再起動が必要になる可能性があります。
Speech SDK for Java は、ARM64 上の Windows をサポートしていません。
Azul Zulu OpenJDK などの Java Development Kit をインストールします。 Microsoft Build of OpenJDK またはお好みの JDK も機能する必要があります。
Speech SDK for Java をインストールする
一部の手順では、1.24.2 などの特定の SDK バージョンを使用します。 最新バージョンを確認するには、GitHub リポジトリを検索します。
ターゲット環境を選択してください。
このガイドでは、Java Runtime で Java 用の Speech SDK をインストールする方法について説明します。
サポートされるオペレーティング システム
以下のオペレーティング システム用の Speech SDK for Java パッケージを入手できます。
- Windows: 64 ビットのみ。
- Mac: macOS X バージョン 10.14 以降。
- Linux: サポートされている Linux ディストリビューションとターゲット アーキテクチャの一覧を参照してください。
Apache Maven を使用して Speech SDK for Java をインストールするには、次の手順に従います。
Apache Maven をインストールします。
新しいプロジェクトの配置場所のコマンド プロンプトを開き、新しい pom.xml ファイルを作成します。
次の XML の内容を pom.xml にコピーします。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.37.0</version> </dependency> </dependencies> </project>次の Maven コマンドを実行して、Speech SDK と依存関係をインストールします。
mvn clean dependency:copy-dependencies
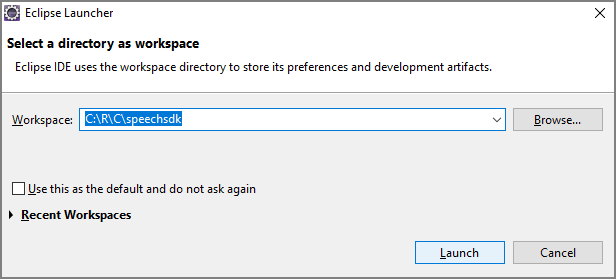
![Java プロジェクトが強調表示されている [新しいプロジェクト] ダイアログ ボックスのスクリーンショット。](media/sdk/qs-java-jre-02-select-wizard.png)
![Java プロジェクトを作成するための選択を示す、[新規 Java プロジェクト] ウィザードのスクリーンショット。](media/sdk/qs-java-jre-03-create-java-project.png)
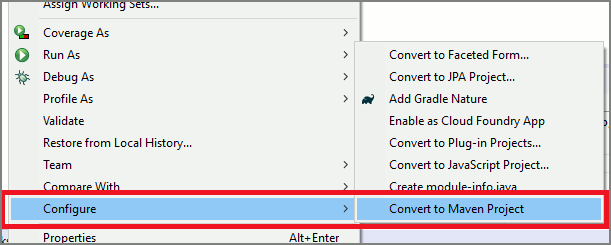
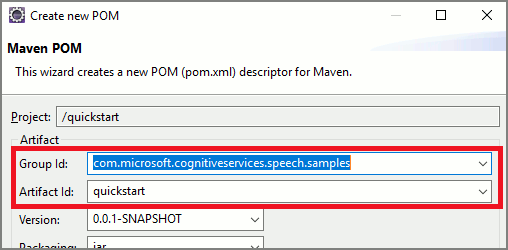

定型コードを使用して開始する
src ディレクトリから
Main.javaを開きます。ファイルの内容を、次のコードに置き換えます。
import java.util.ArrayList;
import java.util.Dictionary;
import java.util.concurrent.ExecutionException;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
public class Main {
public static void main(String[] args) throws InterruptedException, ExecutionException {
IntentPatternMatchingWithMicrophone();
}
public static void IntentPatternMatchingWithMicrophone() throws InterruptedException, ExecutionException {
SpeechConfig config = SpeechConfig.fromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
}
}
Speech 構成を作成する
IntentRecognizer オブジェクトを初期化する前に、Azure AI サービス予測リソース用のキーと Azure リージョンを使用する構成を作成する必要があります。
"YOUR_SUBSCRIPTION_KEY"を、Azure AI サービスの実際の予測キーに置き換えます。"YOUR_SUBSCRIPTION_REGION"を Azure AI サービスの実際のリソース リージョンに置き換えます。
このサンプルでは、fromSubscription() メソッドを使用して SpeechConfig をビルドします。 使用可能なメソッドの完全な一覧については、SpeechConfig クラスに関する記事を参照してください。
IntentRecognizer を初期化する
次に、IntentRecognizer を作成します。 Speech 構成のすぐ下にこのコードを挿入します。 自動で閉じることのできるインターフェイスを利用できるようにこれを試してみます。
try (IntentRecognizer recognizer = new IntentRecognizer(config)) {
}
意図を追加する
いくつかのパターンを PatternMatchingModel と関連付け、それを IntentRecognizer に適用する必要があります。
まず PatternMatchingModel を作成し、いくつかの意図を追加します。
注意
PatternMatchingIntent には複数のパターンを追加できます。
このコードを try ブロック内に挿入します。
// Creates a Pattern Matching model and adds specific intents from your model. The
// Id is used to identify this model from others in the collection.
PatternMatchingModel model = new PatternMatchingModel("YourPatternMatchingModelId");
// Creates a pattern that uses groups of optional words. "[Go | Take me]" will match either "Go", "Take me", or "".
String patternWithOptionalWords = "[Go | Take me] to [floor|level] {floorName}";
// Creates a pattern that uses an optional entity and group that could be used to tie commands together.
String patternWithOptionalEntity = "Go to parking [{parkingLevel}]";
// You can also have multiple entities of the same name in a single pattern by adding appending a unique identifier
// to distinguish between the instances. For example:
String patternWithTwoOfTheSameEntity = "Go to floor {floorName:1} [and then go to floor {floorName:2}]";
// NOTE: Both floorName:1 and floorName:2 are tied to the same list of entries. The identifier can be a string
// and is separated from the entity name by a ':'
// Creates the pattern matching intents and adds them to the model
model.getIntents().put(new PatternMatchingIntent("ChangeFloors", patternWithOptionalWords, patternWithOptionalEntity, patternWithTwoOfTheSameEntity));
model.getIntents().put(new PatternMatchingIntent("DoorControl", "{action} the doors", "{action} doors", "{action} the door", "{action} door"));
いくつかのカスタム エンティティを追加する
パターン マッチャーを最大限に活用するために、エンティティをカスタマイズすることができます。 "floorName" を利用可能なフロアのリストにします。 また、"parkingLevel" を、整数のエンティティにします。
このコードを意図の下に挿入します。
// Creates the "floorName" entity and set it to type list.
// Adds acceptable values. NOTE the default entity type is Any and so we do not need
// to declare the "action" entity.
model.getEntities().put(PatternMatchingEntity.CreateListEntity("floorName", PatternMatchingEntity.EntityMatchMode.Strict, "ground floor", "lobby", "1st", "first", "one", "1", "2nd", "second", "two", "2"));
// Creates the "parkingLevel" entity as a pre-built integer
model.getEntities().put(PatternMatchingEntity.CreateIntegerEntity("parkingLevel"));
モデルを認識エンジンに適用する
ここで、モデルを IntentRecognizer に適用する必要があります。 複数のモデルを一度に使用して、API がモデルのコレクションを取得するようにすることができます。
このコードをエンティティの下に挿入します。
ArrayList<LanguageUnderstandingModel> modelCollection = new ArrayList<LanguageUnderstandingModel>();
modelCollection.add(model);
recognizer.applyLanguageModels(modelCollection);
意図を認識する
IntentRecognizer オブジェクトから、RecognizeOnceAsync() メソッドを呼び出します。 このメソッドは、Speech サービスに対して、1 つのフレーズで音声を認識し、フレーズが識別されたら音声の認識を停止するよう要求します。
言語モデルを適用した後、次のコードを挿入します。
System.out.println("Say something...");
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
認識結果 (またはエラー) を表示する
Speech サービスによって認識結果が返されたら、結果を出力します。
次のコードを IntentRecognitionResult result = recognizer.recognizeOnceAsync.get(); の下に挿入します。
if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s", "Intent not recognized."));
}
else if (result.getReason() == ResultReason.RecognizedIntent)
{
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s %s", "Intent Id=", result.getIntentId() + "."));
Dictionary<String, String> entities = result.getEntities();
switch (result.getIntentId())
{
case "ChangeFloors":
if (entities.get("floorName") != null) {
System.out.println(String.format("%17s %s", "FloorName=", entities.get("floorName")));
}
if (entities.get("floorName:1") != null) {
System.out.println(String.format("%17s %s", "FloorName:1=", entities.get("floorName:1")));
}
if (entities.get("floorName:2") != null) {
System.out.println(String.format("%17s %s", "FloorName:2=", entities.get("floorName:2")));
}
if (entities.get("parkingLevel") != null) {
System.out.println(String.format("%17s %s", "ParkingLevel=", entities.get("parkingLevel")));
}
break;
case "DoorControl":
if (entities.get("action") != null) {
System.out.println(String.format("%17s %s", "Action=", entities.get("action")));
}
break;
}
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error)
{
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
コードを確認する
この時点で、コードは次のようになります。
package quickstart;
import java.util.ArrayList;
import java.util.concurrent.ExecutionException;
import java.util.Dictionary;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
public class Main {
public static void main(String[] args) throws InterruptedException, ExecutionException {
IntentPatternMatchingWithMicrophone();
}
public static void IntentPatternMatchingWithMicrophone() throws InterruptedException, ExecutionException {
SpeechConfig config = SpeechConfig.fromSubscription("YOUR_SUBSCRIPTION_KEY", "YOUR_SUBSCRIPTION_REGION");
try (IntentRecognizer recognizer = new IntentRecognizer(config)) {
// Creates a Pattern Matching model and adds specific intents from your model. The
// Id is used to identify this model from others in the collection.
PatternMatchingModel model = new PatternMatchingModel("YourPatternMatchingModelId");
// Creates a pattern that uses groups of optional words. "[Go | Take me]" will match either "Go", "Take me", or "".
String patternWithOptionalWords = "[Go | Take me] to [floor|level] {floorName}";
// Creates a pattern that uses an optional entity and group that could be used to tie commands together.
String patternWithOptionalEntity = "Go to parking [{parkingLevel}]";
// You can also have multiple entities of the same name in a single pattern by adding appending a unique identifier
// to distinguish between the instances. For example:
String patternWithTwoOfTheSameEntity = "Go to floor {floorName:1} [and then go to floor {floorName:2}]";
// NOTE: Both floorName:1 and floorName:2 are tied to the same list of entries. The identifier can be a string
// and is separated from the entity name by a ':'
// Creates the pattern matching intents and adds them to the model
model.getIntents().put(new PatternMatchingIntent("ChangeFloors", patternWithOptionalWords, patternWithOptionalEntity, patternWithTwoOfTheSameEntity));
model.getIntents().put(new PatternMatchingIntent("DoorControl", "{action} the doors", "{action} doors", "{action} the door", "{action} door"));
// Creates the "floorName" entity and set it to type list.
// Adds acceptable values. NOTE the default entity type is Any and so we do not need
// to declare the "action" entity.
model.getEntities().put(PatternMatchingEntity.CreateListEntity("floorName", PatternMatchingEntity.EntityMatchMode.Strict, "ground floor", "lobby", "1st", "first", "one", "1", "2nd", "second", "two", "2"));
// Creates the "parkingLevel" entity as a pre-built integer
model.getEntities().put(PatternMatchingEntity.CreateIntegerEntity("parkingLevel"));
ArrayList<LanguageUnderstandingModel> modelCollection = new ArrayList<LanguageUnderstandingModel>();
modelCollection.add(model);
recognizer.applyLanguageModels(modelCollection);
System.out.println("Say something...");
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s", "Intent not recognized."));
}
else if (result.getReason() == ResultReason.RecognizedIntent)
{
System.out.println("RECOGNIZED: Text= " + result.getText());
System.out.println(String.format("%17s %s", "Intent Id=", result.getIntentId() + "."));
Dictionary<String, String> entities = result.getEntities();
switch (result.getIntentId())
{
case "ChangeFloors":
if (entities.get("floorName") != null) {
System.out.println(String.format("%17s %s", "FloorName=", entities.get("floorName")));
}
if (entities.get("floorName:1") != null) {
System.out.println(String.format("%17s %s", "FloorName:1=", entities.get("floorName:1")));
}
if (entities.get("floorName:2") != null) {
System.out.println(String.format("%17s %s", "FloorName:2=", entities.get("floorName:2")));
}
if (entities.get("parkingLevel") != null) {
System.out.println(String.format("%17s %s", "ParkingLevel=", entities.get("parkingLevel")));
}
break;
case "DoorControl":
if (entities.get("action") != null) {
System.out.println(String.format("%17s %s", "Action=", entities.get("action")));
}
break;
}
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error)
{
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
}
}
}
アプリをビルドして実行する
これで、アプリをビルドし、音声サービスと埋め込みパターン マッチャーを使って意図認識をテストする準備ができました。
Eclipse で実行ボタンを選択するか、Ctrl + F11 キーを押してから、"Say something..." (何か話してください...) プロンプトの出力を確認します。 それが表示されたら、何か話して、出力を確認します。
たとえば、"Take me to floor 2" (2 階に行く) と言った場合、次の出力が表示されます。
Say something...
RECOGNIZED: Text=Take me to floor 2.
Intent Id=ChangeFloors.
FloorName=2
別の例として、"Take me to floor 7" (7 階に行く) と言った場合の出力は、次のとおりです。
Say something...
RECOGNIZED: Text=Take me to floor 7.
Intent not recognized.
floorName の有効な値の一覧に 7 がなかったため、意図が認識されませんでした。