Azure OpenAI in Azure AI Foundry Models lets you tailor our models to your personal datasets by using a process known as fine-tuning. This customization step lets you get more out of the service by providing:
- Higher quality results than what you can get just from prompt engineering
- The ability to train on more examples than can fit into a model's max request context limit.
- Token savings due to shorter prompts
- Lower-latency requests, particularly when using smaller models.
In contrast to few-shot learning, fine tuning improves the model by training on many more examples than can fit in a prompt, letting you achieve better results on a wide number of tasks. Because fine tuning adjusts the base model’s weights to improve performance on the specific task, you won’t have to include as many examples or instructions in your prompt. This means less text sent and fewer tokens processed on every API call, potentially saving cost, and improving request latency.
We use LoRA, or low rank adaptation, to fine-tune models in a way that reduces their complexity without significantly affecting their performance. This method works by approximating the original high-rank matrix with a lower rank one, thus only fine-tuning a smaller subset of important parameters during the supervised training phase, making the model more manageable and efficient. For users, this makes training faster and more affordable than other techniques.
There are two unique fine-tuning experiences in the Azure AI Foundry portal:
- Hub/Project view - supports fine-tuning models from multiple providers including Azure OpenAI, Meta Llama, Microsoft Phi, etc.
- Azure OpenAI centric view - only supports fine-tuning Azure OpenAI models, but has support for additional features like the Weights & Biases (W&B) preview integration.
If you are only fine-tuning Azure OpenAI models, we recommend the Azure OpenAI centric fine-tuning experience which is available by navigating to https://ai.azure.com/resource/overview.
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Prerequisites
- Read the When to use Azure OpenAI fine-tuning guide.
- An Azure subscription. Create one for free.
- An Azure OpenAI resource that's located in a region that supports fine-tuning of the Azure OpenAI model. Check the Model summary table and region availability for the list of available models by region and supported functionality. For more information, see Create a resource and deploy a model with Azure OpenAI.
- Fine-tuning access requires Cognitive Services OpenAI Contributor.
- If you do not already have access to view quota, and deploy models in Azure AI Foundry portal you will require additional permissions.
Supported models
Consult the models page to check which regions currently support fine-tuning.
Or you can fine tune a previously fine-tuned model, formatted as base-model.ft-{jobid}.
Review the workflow for Azure AI Foundry portal
Take a moment to review the fine-tuning workflow for using Azure AI Foundry portal:
- Prepare your training and validation data.
- Use the Create a fine-tuned model dialog in Azure AI Foundry portal to train your custom model.
- Select a training method.
- Select a base model.
- Choose your training type
- Choose your training data.
- Optionally, choose your validation data.
- Optionally, configure task parameters for your fine-tuning job.
- Optionally, enable auto-deployment for the resulting custom model.
- Review your choices and train your new custom model.
- Check the status of your custom fine-tuned model.
- Deploy your custom model for use.
- Use your custom model.
- Optionally, analyze your custom model for performance and fit.
Prepare your training and validation data
Your training data and validation data sets consist of input and output examples for how you would like the model to perform.
The training and validation data you use must be formatted as a JSON Lines (JSONL) document and must be formatted in the conversational format that is used by the Chat completions API.
It's generally recommended to use the instructions and prompts that you found worked best in every training example. This will help you get the best results, especially if you have fewer than a hundred examples.
Example file format
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Multi-turn chat file format Azure OpenAI
Multiple turns of a conversation in a single line of your jsonl training file is also supported. To skip fine-tuning on specific assistant messages add the optional weight key value pair. Currently weight can be set to 0 or 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chat completions with vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
In addition to the JSONL format, training and validation data files must be encoded in UTF-8 and include a byte-order mark (BOM). The file must be less than 512 MB in size.
Datasets size consideration
The more training examples you have, the better. Fine-tuning jobs will not proceed without at least 10 training examples, but such a small number isn't enough to noticeably influence model responses. It is best practice to provide hundreds, if not thousands, of training examples to be successful. It's recommended to start with 50 well-crafted training data.
In general, doubling the dataset size can lead to a linear increase in model quality. But keep in mind, low quality examples can negatively impact performance. If you train the model on a large amount of internal data, without first pruning the dataset for only the highest quality examples you could end up with a model that performs much worse than expected.
Creating a fine-tuned model
Azure AI Foundry portal provides the Create a fine-tuned model dialog, so in one place you can easily create and train a fine-tuned model for your Azure resource.
Go to the Azure AI Foundry portal at https://ai.azure.com/ and sign in with credentials that have access to your Azure OpenAI resource. During the sign-in workflow, select the appropriate directory, Azure subscription, and Azure OpenAI resource.
In Azure AI Foundry portal, browse to the Tools > Fine-tuning pane, and select Fine-tune model.

Select a model to fine-tune, and then select Next to continue.


You should now see the Create a fine-tuned model dialog.

Choose your training method
The first step is to confirm you model choice and the training method. Not all models support all training methods.
- Supervised Fine Tuning (SFT): supported by all non-reasoning models.
- Direct Preference Optimization (Preview) (DPO): supported by GPT-4o.
- Reinforcement Fine Tuning (Preview) (RFT): supported by reasoning models, like o4-mini.
When selecting the model, you may also select a previously fine-tuned model.
Choose your training type
Select the training tier you'd like to use for your fine-tuning job:
- Standard: training occurs in the current Azure OpenAI resource's region, providing data residency.
- Global (Preview): more affordable training per-token, does not offer data residency.
If you have no data residency requirements, Global is a good choice to take advantage of training capacity beyond your current region. While in public preview, Global may not be available within your current region. Consult
In some cases, Standard may not be available within your current region. If you require data residency, consult regions listed on the model availability for your chosen model.
Choose your training data
The next step is to either choose existing prepared training data or upload new prepared training data to use when customizing your model by selecting Add training data.
The Training data dialog displays any existing, previously uploaded datasets and also provides options to upload new training data.
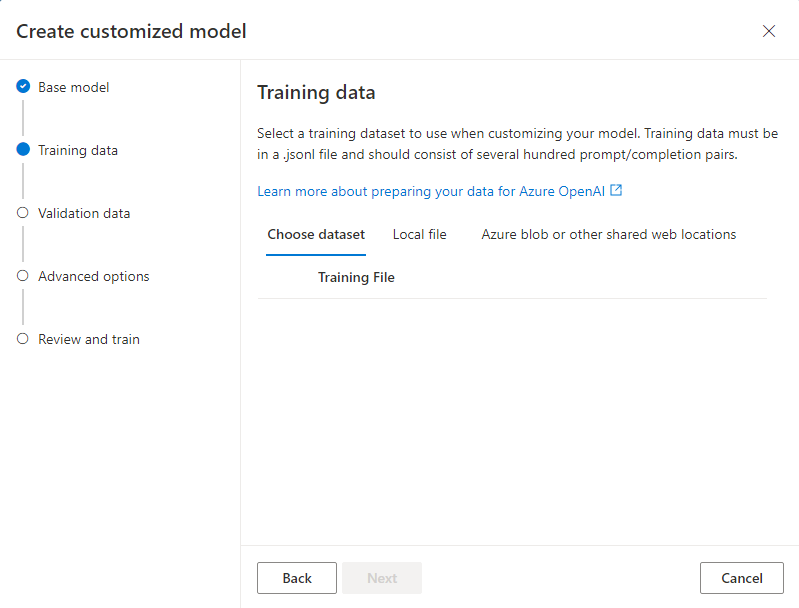
If your training data is already uploaded to the service, select Files from Connected AI resource.
- Select the file from the dropdown list shown.
To upload new training data, use one of the following options:
- Select Upload files to upload training data from a local file.
- Select Azure blob or other shared web locations to import training data from Azure Blob or another shared web location.
For large data files, we recommend that you import from an Azure Blob store. Large files can become unstable when uploaded through multipart forms because the requests are atomic and can't be retried or resumed. For more information about Azure Blob Storage, see What is Azure Blob Storage?
Note
Training data files must be formatted as JSONL files, encoded in UTF-8 with a byte-order mark (BOM). The file must be less than 512 MB in size.
Choose your validation data (optional)
If you have a validation dataset, select Add training data. You can either choose existing prepared validation data or upload new prepared validation data to use when customizing your model.
The Validation data dialog displays any existing, previously uploaded training and validation datasets and provides options by which you can upload new validation data.

If your validation data is already uploaded to the service, select Choose dataset.
- Select the file from the list shown in the Validation data pane.
To upload new validation data, use one of the following options:
- Select Local file to upload validation data from a local file.
- Select Azure blob or other shared web locations to import validation data from Azure Blob or another shared web location.
For large data files, we recommend that you import from an Azure Blob store. Large files can become unstable when uploaded through multipart forms because the requests are atomic and can't be retried or resumed.
Note
Similar to training data files, validation data files must be formatted as JSONL files, encoded in UTF-8 with a byte-order mark (BOM). The file must be less than 512 MB in size.
Make your model identifiable (optional)
We also recommend including a suffix parameter to make it easier to distinguish between different iterations of your fine-tuned model. A suffix takes a string of up to 18 characters and is used when naming the resulting fine-tuned model.
Configure training parameters (optional)
You may provide an optional seed and tune additional hyperparameters.
The seed controls the reproducibility of the job. Passing in the same seed and job parameters should produce the same results, but may differ in rare cases. If a seed isn't specified, one will be randomly generated for you.

The following hyperparameters are available for tuning via the Azure AI Foundry portal:
| Name | Type | Description |
|---|---|---|
| Batch Size | integer | The batch size to use for training. The batch size is the number of training examples used to train a single forward and backward pass. In general, we've found that larger batch sizes tend to work better for larger datasets. The default value as well as the maximum value for this property are specific to a base model. A larger batch size means that model parameters are updated less frequently, but with lower variance. |
| Learning Rate Multiplier | number | The learning rate multiplier to use for training. The fine-tuning learning rate is the original learning rate used for pre-training multiplied by this value. Larger learning rates tend to perform better with larger batch sizes. We recommend experimenting with values in the range 0.02 to 0.2 to see what produces the best results. A smaller learning rate may be useful to avoid overfitting. |
| Number of Epochs | integer | The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset. |
Enable auto deployment (optional)
To save time, you can optionally enable auto-deployment for your resulting model. If training completes successfully, the model will be deployed using the selected deployment type. The deployment will be named based on the unique name generated for your custom model and the optional suffix you may have provided earlier.

Note
Only Global Standard and Developer deployments are currently supported for auto-deployment. Neither of these options provide data residency. Consult the deployment type documentation for more details.
Review your choices and train your model
Review your choices and select Submit to start training your new fine-tuned model.
Check the status of your custom model
After you submit your fine-tuning job, you will see a page with details about your fine-tuned model. You can find the status and more information about your fine-tuned model on the Fine-tuning page in Azure AI Foundry portal.
Your job might be queued behind other jobs on the system. Training your model can take minutes or hours depending on the model and dataset size.
Checkpoints
When each training epoch completes a checkpoint is generated. A checkpoint is a fully functional version of a model which can both be deployed and used as the target model for subsequent fine-tuning jobs. Checkpoints can be particularly useful, as they may provide snapshots prior to overfitting. When a fine-tuning job completes you will have the three most recent versions of the model available to deploy.
Analyze your custom model
Azure OpenAI attaches a result file named results.csv to each fine-tuning job after it completes. You can use the result file to analyze the training and validation performance of your custom model. The file ID for the result file is listed for each custom model in the Result file Id column on the Models pane for Azure AI Foundry portal. You can use the file ID to identify and download the result file from the Data files pane of Azure AI Foundry portal.
The result file is a CSV file that contains a header row and a row for each training step performed by the fine-tuning job. The result file contains the following columns:
| Column name | Description |
|---|---|
step |
The number of the training step. A training step represents a single pass, forward and backward, on a batch of training data. |
train_loss |
The loss for the training batch. |
train_mean_token_accuracy |
The percentage of tokens in the training batch correctly predicted by the model. For example, if the batch size is set to 3 and your data contains completions [[1, 2], [0, 5], [4, 2]], this value is set to 0.83 (5 of 6) if the model predicted [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
The loss for the validation batch. |
validation_mean_token_accuracy |
The percentage of tokens in the validation batch correctly predicted by the model. For example, if the batch size is set to 3 and your data contains completions [[1, 2], [0, 5], [4, 2]], this value is set to 0.83 (5 of 6) if the model predicted [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
The validation loss calculated at the end of each epoch. When training goes well, loss should decrease. |
full_valid_mean_token_accuracy |
The valid mean token accuracy calculated at the end of each epoch. When training is going well, token accuracy should increase. |
You can also view the data in your results.csv file as plots in Azure AI Foundry portal. Select the link for your trained model, and you will see three charts: loss, mean token accuracy, and token accuracy. If you provided validation data, both datasets will appear on the same plot.
Look for your loss to decrease over time, and your accuracy to increase. If you see a divergence between your training and validation data, that may indicate that you are overfitting. Try training with fewer epochs, or a smaller learning rate multiplier.
Deploy a fine-tuned model
Once you're satisified with the metrics from your fine-tuning job, or you just want to move onto inference, you must deploy the model.
If you're deploying for further validation, consider deploying for testing using a Developer deployment.
If you're ready to deploy for production or have particular data residency needs, follow our deployment guide.
Use a deployed fine-tuned model
After your fine-tuned model deploys, you can use it like any other deployed model. You can use the Playground in Azure AI Foundry to experiment with your new deployment. You can also use the REST API to call your fine-tuned model from your own application. You can even begin to use this new fine-tuned model in your prompt flow to build your generative AI application.
Note
For chat models, the system message that you use to guide your fine-tuned model (whether it's deployed or available for testing in the playground) must be the same as the system message you used for training. If you use a different system message, the model might not perform as expected.
Continuous fine-tuning
Once you have created a fine-tuned model you may wish to continue to refine the model over time through further fine-tuning. Continuous fine-tuning is the iterative process of selecting an already fine-tuned model as a base model and fine-tuning it further on new sets of training examples.
To perform fine-tuning on a model that you have previously fine-tuned you would use the same process as described in creating a fine-tuned model but instead of specifying the name of a generic base model you would specify your already fine-tuned model. A custom fine-tuned model would look like gpt-4o-2024-08-06.ft-d93dda6110004b4da3472d96f4dd4777-ft

Clean up your deployments, custom models, and training files
When you're done with your custom model, you can delete the deployment and model. You can also delete the training and validation files you uploaded to the service, if needed.
Delete your model deployment
Important
After you deploy a customized model, if at any time the deployment remains inactive for greater than fifteen (15) days, the deployment is deleted. The deployment of a customized model is inactive if the model was deployed more than fifteen (15) days ago and no completions or chat completions calls were made to it during a continuous 15-day period.
The deletion of an inactive deployment doesn't delete or affect the underlying customized model, and the customized model can be redeployed at any time. As described in Azure OpenAI in Azure AI Foundry Models pricing, each customized (fine-tuned) model that's deployed incurs an hourly hosting cost regardless of whether completions or chat completions calls are being made to the model. To learn more about planning and managing costs with Azure OpenAI, refer to the guidance in Plan to manage costs for Azure OpenAI.
You can delete the deployment for your custom model on the Deployments pane in Azure AI Foundry portal. Select the deployment to delete, and then select Delete to delete the deployment.
Delete your custom model
You can delete a custom model on the Models pane in Azure AI Foundry portal. Select the custom model to delete from the Customized models tab, and then select Delete to delete the custom model.
Note
You can't delete a custom model if it has an existing deployment. You must first delete your model deployment before you can delete your custom model.
Delete your training files
You can optionally delete training and validation files that you uploaded for training, and result files generated during training, on the Management > Data + indexes pane in Azure AI Foundry portal. Select the file to delete, and then select Delete to delete the file.






Prerequisites
- Read the When to use Azure OpenAI fine-tuning guide.
- An Azure subscription. Create one for free.
- An Azure OpenAI resource. For more information, see Create a resource and deploy a model with Azure OpenAI.
- The following Python libraries:
os,json,requests,openai. - The OpenAI Python library should be at least version 0.28.1.
- Fine-tuning access requires Cognitive Services OpenAI Contributor.
- If you do not already have access to view quota, and deploy models in Azure AI Foundry portal you will require additional permissions.
Note
The REST API does not currently support Global training jobs. Inspecting Global training jobs via the API may return incorrect information.
Supported models
Consult the models page to check which regions currently support fine-tuning.
Or you can fine tune a previously fine-tuned model, formatted as base-model.ft-{jobid}.
Review the workflow for the Python SDK
Take a moment to review the fine-tuning workflow for using the Python SDK with Azure OpenAI:
- Prepare your training and validation data.
- Select a base model.
- Upload your training data.
- Train your new customized model.
- Check the status of your customized model.
- Deploy your customized model for use.
- Use your customized model.
- Optionally, analyze your customized model for performance and fit.
Prepare your training and validation data
Your training data and validation data sets consist of input and output examples for how you would like the model to perform.
The training and validation data you use must be formatted as a JSON Lines (JSONL) document and must be formatted in the conversational format that is used by the Chat completions API.
If you would like a step-by-step walk-through of fine-tuning a gpt-4o-mini-2024-07-18 please refer to the Azure OpenAI fine-tuning tutorial
Example file format
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Multi-turn chat file format
Multiple turns of a conversation in a single line of your jsonl training file is also supported. To skip fine-tuning on specific assistant messages add the optional weight key value pair. Currently weight can be set to 0 or 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chat completions with vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
In addition to the JSONL format, training and validation data files must be encoded in UTF-8 and include a byte-order mark (BOM). The file must be less than 512 MB in size.
Create your training and validation datasets
The more training examples you have, the better. Fine tuning jobs will not proceed without at least 10 training examples, but such a small number is not enough to noticeably influence model responses. It is best practice to provide hundreds, if not thousands, of training examples to be successful.
In general, doubling the dataset size can lead to a linear increase in model quality. But keep in mind, low quality examples can negatively impact performance. If you train the model on a large amount of internal data, without first pruning the dataset for only the highest quality examples you could end up with a model that performs much worse than expected.
Upload your training data
The next step is to either choose existing prepared training data or upload new prepared training data to use when customizing your model. After you prepare your training data, you can upload your files to the service. There are two ways to upload training data:
For large data files, we recommend that you import from an Azure Blob store. Large files can become unstable when uploaded through multipart forms because the requests are atomic and can't be retried or resumed. For more information about Azure Blob storage, see What is Azure Blob storage?
Note
Training data files must be formatted as JSONL files, encoded in UTF-8 with a byte-order mark (BOM). The file must be less than 512 MB in size.
The following Python example uploads local training and validation files by using the Python SDK, and retrieves the returned file IDs.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-10-21" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Create a customized model
After you upload your training and validation files, you're ready to start the fine-tuning job.
The following Python code shows an example of how to create a new fine-tune job with the Python SDK:
In this example we are also passing the seed parameter. The seed controls the reproducibility of the job. Passing in the same seed and job parameters should produce the same results, but may differ in rare cases. If a seed isn't specified, one will be generated for you.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
You can also pass additional optional parameters like hyperparameters to take greater control of the fine-tuning process. For initial training we recommend using the automatic defaults that are present without specifying these parameters.
The current supported hyperparameters for fine-tuning are:
| Name | Type | Description |
|---|---|---|
batch_size |
integer | The batch size to use for training. The batch size is the number of training examples used to train a single forward and backward pass. In general, we've found that larger batch sizes tend to work better for larger datasets. The default value as well as the maximum value for this property are specific to a base model. A larger batch size means that model parameters are updated less frequently, but with lower variance. |
learning_rate_multiplier |
number | The learning rate multiplier to use for training. The fine-tuning learning rate is the original learning rate used for pre-training multiplied by this value. Larger learning rates tend to perform better with larger batch sizes. We recommend experimenting with values in the range 0.02 to 0.2 to see what produces the best results. A smaller learning rate can be useful to avoid overfitting. |
n_epochs |
integer | The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset. |
seed |
integer | The seed controls the reproducibility of the job. Passing in the same seed and job parameters should produce the same results, but may differ in rare cases. If a seed isn't specified, one will be generated for you. |
To set custom hyperparameters with the 1.x version of the OpenAI Python API:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-10-21" # This API version or later is required
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4.1-2025-04-14", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Check fine-tuning job status
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
List fine-tuning events
To examine the individual fine-tuning events that were generated during training, you might need to upgrade your OpenAI client library to the latest version with pip install openai --upgrade to run this command.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Checkpoints
When each training epoch completes a checkpoint is generated. A checkpoint is a fully functional version of a model which can both be deployed and used as the target model for subsequent fine-tuning jobs. Checkpoints can be particularly useful, as they may provide snapshots prior to overfitting. When a fine-tuning job completes you will have the three most recent versions of the model available to deploy. The final epoch will be represented by your fine-tuned model, the previous two epochs will be available as checkpoints.
You can run the list checkpoints command to retrieve the list of checkpoints associated with an individual fine-tuning job. You might need to upgrade your OpenAI client library to the latest version with pip install openai --upgrade to run this command.
response = client.fine_tuning.jobs.checkpoints.list(job_id)
print(response.model_dump_json(indent=2))
Analyze your customized model
Azure OpenAI attaches a result file named results.csv to each fine-tune job after it completes. You can use the result file to analyze the training and validation performance of your customized model. The file ID for the result file is listed for each customized model, and you can use the Python SDK to retrieve the file ID and download the result file for analysis.
The following Python example retrieves the file ID of the first result file attached to the fine-tuning job for your customized model, and then uses the Python SDK to download the file to your current working directory for analysis.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
The result file is a CSV file that contains a header row and a row for each training step performed by the fine-tuning job. The result file contains the following columns:
| Column name | Description |
|---|---|
step |
The number of the training step. A training step represents a single pass, forward and backward, on a batch of training data. |
train_loss |
The loss for the training batch. |
train_mean_token_accuracy |
The percentage of tokens in the training batch correctly predicted by the model. For example, if the batch size is set to 3 and your data contains completions [[1, 2], [0, 5], [4, 2]], this value is set to 0.83 (5 of 6) if the model predicted [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
The loss for the validation batch. |
validation_mean_token_accuracy |
The percentage of tokens in the validation batch correctly predicted by the model. For example, if the batch size is set to 3 and your data contains completions [[1, 2], [0, 5], [4, 2]], this value is set to 0.83 (5 of 6) if the model predicted [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
The validation loss calculated at the end of each epoch. When training goes well, loss should decrease. |
full_valid_mean_token_accuracy |
The valid mean token accuracy calculated at the end of each epoch. When training is going well, token accuracy should increase. |
You can also view the data in your results.csv file as plots in Azure AI Foundry portal. Select the link for your trained model, and you will see three charts: loss, mean token accuracy, and token accuracy. If you provided validation data, both datasets will appear on the same plot.
Look for your loss to decrease over time, and your accuracy to increase. If you see a divergence between your training and validation data that can indicate that you are overfitting. Try training with fewer epochs, or a smaller learning rate multiplier.
Deploy a fine-tuned model
Once you're satisfied with the metrics from your fine-tuning job, or you just want to move onto inference, you must deploy the model.
If you're deploying for further validation, consider deploying for testing using a Developer deployment.
Unlike the previous SDK commands, deployment must be done using the control plane API which requires separate authorization, a different API path, and a different API version.
| variable | Definition |
|---|---|
| token | There are multiple ways to generate an authorization token. The easiest method for initial testing is to launch the Cloud Shell from the Azure portal. Then run az account get-access-token. You can use this token as your temporary authorization token for API testing. We recommend storing this in a new environment variable. |
| subscription | The subscription ID for the associated Azure OpenAI resource. |
| resource_group | The resource group name for your Azure OpenAI resource. |
| resource_name | The Azure OpenAI resource name. |
| model_deployment_name | The custom name for your new fine-tuned model deployment. This is the name that will be referenced in your code when making chat completion calls. |
| fine_tuned_model | Retrieve this value from your fine-tuning job results in the previous step. It will look like gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. You will need to add that value to the deploy_data json. Alternatively you can also deploy a checkpoint, by passing the checkpoint ID which will appear in the format ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-41-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-01"} # control plane API version rather than dataplane API for this call
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Learn more about cross region deployment and use the deployed model here.
If you're ready to deploy for production or have particular data residency needs, follow our deployment guide.
Continuous fine-tuning
Once you have created a fine-tuned model you might want to continue to refine the model over time through further fine-tuning. Continuous fine-tuning is the iterative process of selecting an already fine-tuned model as a base model and fine-tuning it further on new sets of training examples.
To perform fine-tuning on a model that you have previously fine-tuned you would use the same process as described in create a customized model but instead of specifying the name of a generic base model you would specify your already fine-tuned model's ID. The fine-tuned model ID looks like gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-10-21"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7"
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
We also recommend including the suffix parameter to make it easier to distinguish between different iterations of your fine-tuned model. suffix takes a string, and is set to identify the fine-tuned model. With the OpenAI Python API a string of up to 18 characters is supported that will be added to your fine-tuned model name.
If you are unsure of the ID of your existing fine-tuned model this information can be found in the Models page of Azure AI Foundry, or you can generate a list of models for a given Azure OpenAI resource using the REST API.
Clean up your deployments, customized models, and training files
When you're done with your customized model, you can delete the deployment and model. You can also delete the training and validation files you uploaded to the service, if needed.
Delete your model deployment
Important
After you deploy a customized model, if at any time the deployment remains inactive for greater than fifteen (15) days, the deployment is deleted. The deployment of a customized model is inactive if the model was deployed more than fifteen (15) days ago and no completions or chat completions calls were made to it during a continuous 15-day period.
The deletion of an inactive deployment doesn't delete or affect the underlying customized model, and the customized model can be redeployed at any time. As described in Azure OpenAI in Azure AI Foundry Models pricing, each customized (fine-tuned) model that's deployed incurs an hourly hosting cost regardless of whether completions or chat completions calls are being made to the model. To learn more about planning and managing costs with Azure OpenAI, refer to the guidance in Plan to manage costs for Azure OpenAI.
You can use various methods to delete the deployment for your customized model:
Delete your customized model
Similarly, you can use various methods to delete your customized model:
Note
You can't delete a customized model if it has an existing deployment. You must first delete your model deployment before you can delete your customized model.
Delete your training files
You can optionally delete training and validation files that you uploaded for training, and result files generated during training, from your Azure OpenAI subscription. You can use the following methods to delete your training, validation, and result files:
- Azure AI Foundry
- The REST APIs
- The Python SDK
The following Python example uses the Python SDK to delete the training, validation, and result files for your customized model:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Prerequisites
- Read the When to use Azure OpenAI fine-tuning guide.
- An Azure subscription. Create one for free.
- An Azure OpenAI resource. For more information, see Create a resource and deploy a model with Azure OpenAI.
- Fine-tuning access requires Cognitive Services OpenAI Contributor.
- If you don't already have access to view quota, and deploy models in Azure AI Foundry portal you'll require additional permissions.
Note
The REST API does not currently support Global training jobs. Inspecting Global training jobs via the API may return incorrect information.
Supported models
Consult the models page to check which regions currently support fine-tuning.
Or you can fine tune a previously fine-tuned model, formatted as base-model.ft-{jobid}.
Review the workflow for the REST API
Take a moment to review the fine-tuning workflow for using the REST APIS and Python with Azure OpenAI:
- Prepare your training and validation data.
- Select a base model.
- Upload your training data.
- Train your new customized model.
- Check the status of your customized model.
- Deploy your customized model for use.
- Use your customized model.
- Optionally, analyze your customized model for performance and fit.
Prepare your training and validation data
Your training data and validation data sets consist of input and output examples for how you would like the model to perform.
The training and validation data you use must be formatted as a JSON Lines (JSONL) document and must be formatted in the conversational format that is used by the Chat completions API.
If you would like a step-by-step walk-through of fine-tuning a gpt-4o-mini-2024-07-18 please refer to the Azure OpenAI fine-tuning tutorial.
Example file format
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Multi-turn chat file format
Multiple turns of a conversation in a single line of your jsonl training file is also supported. To skip fine-tuning on specific assistant messages add the optional weight key value pair. Currently weight can be set to 0 or 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chat completions with vision
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
In addition to the JSONL format, training and validation data files must be encoded in UTF-8 and include a byte-order mark (BOM). The file must be less than 512 MB in size.
Create your training and validation datasets
The more training examples you have, the better. Fine tuning jobs will not proceed without at least 10 training examples, but such a small number is not enough to noticeably influence model responses. It is best practice to provide hundreds, if not thousands, of training examples to be successful.
In general, doubling the dataset size can lead to a linear increase in model quality. But keep in mind, low quality examples can negatively impact performance. If you train the model on a large amount of internal data without first pruning the dataset for only the highest quality examples, you could end up with a model that performs much worse than expected.
Upload your training data
The next step is to either choose existing prepared training data or upload new prepared training data to use when fine-tuning your model. After you prepare your training data, you can upload your files to the service. There are two ways to upload training data:
For large data files, we recommend that you import from an Azure Blob store. Large files can become unstable when uploaded through multipart forms because the requests are atomic and can't be retried or resumed. For more information about Azure Blob storage, see What is Azure Blob storage?
Note
Training data files must be formatted as JSONL files, encoded in UTF-8 with a byte-order mark (BOM). The file must be less than 512 MB in size.
Upload training data
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Upload validation data
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Create a customized model
After you uploaded your training and validation files, you're ready to start the fine-tuning job. The following code shows an example of how to create a new fine-tuning job with the REST API.
In this example we are also passing the seed parameter. The seed controls the reproducibility of the job. Passing in the same seed and job parameters should produce the same results, but can differ in rare cases. If a seed is not specified, one will be generated for you.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
You can also pass additional optional parameters like hyperparameters to take greater control of the fine-tuning process. For initial training we recommend using the automatic defaults that are present without specifying these parameters.
The current supported hyperparameters for fine-tuning are:
| Name | Type | Description |
|---|---|---|
batch_size |
integer | The batch size to use for training. The batch size is the number of training examples used to train a single forward and backward pass. In general, we've found that larger batch sizes tend to work better for larger datasets. The default value as well as the maximum value for this property are specific to a base model. A larger batch size means that model parameters are updated less frequently, but with lower variance. |
learning_rate_multiplier |
number | The learning rate multiplier to use for training. The fine-tuning learning rate is the original learning rate used for pre-training multiplied by this value. Larger learning rates tend to perform better with larger batch sizes. We recommend experimenting with values in the range 0.02 to 0.2 to see what produces the best results. A smaller learning rate can be useful to avoid overfitting. |
n_epochs |
integer | The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset. |
seed |
integer | The seed controls the reproducibility of the job. Passing in the same seed and job parameters should produce the same results, but may differ in rare cases. If a seed isn't specified, one will be generated for you. |
Check the status of your customized model
After you start a fine-tune job, it can take some time to complete. Your job might be queued behind other jobs in the system. Training your model can take minutes or hours depending on the model and dataset size. The following example uses the REST API to check the status of your fine-tuning job. The example retrieves information about your job by using the job ID returned from the previous example:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
List fine-tuning events
To examine the individual fine-tuning events that were generated during training:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Checkpoints
When each training epoch completes a checkpoint is generated. A checkpoint is a fully functional version of a model which can both be deployed and used as the target model for subsequent fine-tuning jobs. Checkpoints can be particularly useful, as they may provide snapshots prior to overfitting. When a fine-tuning job completes you will have the three most recent versions of the model available to deploy. The final epoch will be represented by your fine-tuned model, the previous two epochs will be available as checkpoints.
You can run the list checkpoints command to retrieve the list of checkpoints associated with an individual fine-tuning job:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Analyze your customized model
Azure OpenAI attaches a result file named results.csv to each fine-tune job after it completes. You can use the result file to analyze the training and validation performance of your customized model. The file ID for the result file is listed for each customized model, and you can use the REST API to retrieve the file ID and download the result file for analysis.
The following Python example uses the REST API to retrieve the file ID of the first result file attached to the fine-tuning job for your customized model, and then downloads the file to your working directory for analysis.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
The result file is a CSV file that contains a header row and a row for each training step performed by the fine-tuning job. The result file contains the following columns:
| Column name | Description |
|---|---|
step |
The number of the training step. A training step represents a single pass, forward and backward, on a batch of training data. |
train_loss |
The loss for the training batch. |
train_mean_token_accuracy |
The percentage of tokens in the training batch correctly predicted by the model. For example, if the batch size is set to 3 and your data contains completions [[1, 2], [0, 5], [4, 2]], this value is set to 0.83 (5 of 6) if the model predicted [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
The loss for the validation batch. |
validation_mean_token_accuracy |
The percentage of tokens in the validation batch correctly predicted by the model. For example, if the batch size is set to 3 and your data contains completions [[1, 2], [0, 5], [4, 2]], this value is set to 0.83 (5 of 6) if the model predicted [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
The validation loss calculated at the end of each epoch. When training goes well, loss should decrease. |
full_valid_mean_token_accuracy |
The valid mean token accuracy calculated at the end of each epoch. When training is going well, token accuracy should increase. |
You can also view the data in your results.csv file as plots in Azure AI Foundry portal. Select the link for your trained model, and you will see three charts: loss, mean token accuracy, and token accuracy. If you provided validation data, both datasets will appear on the same plot.
Look for your loss to decrease over time, and your accuracy to increase. If you see a divergence between your training and validation data that may indicate that you are overfitting. Try training with fewer epochs, or a smaller learning rate multiplier.
Deploy a fine-tuned model
Once you're satisfied with the metrics from your fine-tuning job, or you just want to move onto inference, you must deploy the model.
If you're deploying for further validation, consider deploying for testing using a Developer deployment.
If you're ready to deploy for production or have particular data residency needs, follow our deployment guide.
| variable | Definition |
|---|---|
| token | There are multiple ways to generate an authorization token. The easiest method for initial testing is to launch the Cloud Shell from the Azure portal. Then run az account get-access-token. You can use this token as your temporary authorization token for API testing. We recommend storing this in a new environment variable. |
| subscription | The subscription ID for the associated Azure OpenAI resource. |
| resource_group | The resource group name for your Azure OpenAI resource. |
| resource_name | The Azure OpenAI resource name. |
| model_deployment_name | The custom name for your new fine-tuned model deployment. This is the name that will be referenced in your code when making chat completion calls. |
| fine_tuned_model | Retrieve this value from your fine-tuning job results in the previous step. It will look like gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. You'll need to add that value to the deploy_data json. Alternatively you can also deploy a checkpoint, by passing the checkpoint ID which will appear in the format ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Learn more about cross region deployment and use the deployed model here.
Continuous fine-tuning
Once you have created a fine-tuned model, you might want to continue to refine the model over time through further fine-tuning. Continuous fine-tuning is the iterative process of selecting an already fine-tuned model as a base model and fine-tuning it further on new sets of training examples.
To perform fine-tuning on a model that you have previously fine-tuned, you would use the same process as described in create a customized model but instead of specifying the name of a generic base model you would specify your already fine-tuned model's ID. The fine-tuned model ID looks like gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
We also recommend including the suffix parameter to make it easier to distinguish between different iterations of your fine-tuned model. suffix takes a string, and is set to identify the fine-tuned model. The suffix can contain up to 40 characters (a-z, A-Z, 0-9,- and _) that will be added to your fine-tuned model name.
If you're unsure of the ID of your fine-tuned model this information can be found in the Models page of Azure AI Foundry, or you can generate a list of models for a given Azure OpenAI resource using the REST API.
Clean up your deployments, customized models, and training files
When you're done with your customized model, you can delete the deployment and model. You can also delete the training and validation files you uploaded to the service, if needed.
Delete your model deployment
You can use various methods to delete the deployment for your customized model:
Delete your customized model
Similarly, you can use various methods to delete your customized model:
Note
You can't delete a customized model if it has an existing deployment. You must first delete your model deployment before you can delete your customized model.
Delete your training files
You can optionally delete training and validation files that you uploaded for training, and result files generated during training, from your Azure OpenAI subscription. You can use the following methods to delete your training, validation, and result files:
Next steps
- Explore the fine-tuning capabilities in the Azure OpenAI fine-tuning tutorial.
- Review fine-tuning model regional availability
- Learn more about Azure OpenAI quotas