コンテナー化されたアプリケーションは、実行に時間がかかり、分断状態になり、コンテナーを再起動して修復する必要が生じる場合があります。 Azure Container Instances では liveness probe がサポートされており、重要な機能が動作しない場合、コンテナー グループ内のコンテナーを再起動するように構成できます。 liveness probe は Kubernetes liveness probe と同じように振る舞います。
この記事では、liveness probe を含むコンテナー グループをデプロイする方法について説明し、シミュレーションした異常なコンテナーの自動再起動方法を示します。
Azure Container Instances では readiness probes もサポートされます。これにより、コンテナーの準備ができたときにのみ、トラフィックが確実にコンテナーに到達するように構成できます。
YAML のデプロイ
次のコードを使用して liveness-probe.yaml ファイルを作成します。 このファイルは、最終的に異常状態になる NGINX コンテナーから構成されるコンテナー グループを定義します。
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
次のコマンドを実行して、上記の YAML 構成を使用してこのコンテナー グループをデプロイします。
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
開始コマンド
デプロイには、コンテナーの初回の実行開始時に実行される開始コマンドを定義する command プロパティが含まれています。 このプロパティは、文字列の配列を受け入れます。 このコマンドでは、異常な状態に移行しているコンテナーがシミュレートされます。
最初に、bash セッションが開始され、/tmp ディレクトリ内に healthy という名前のファイルが作成されます。 その後、30 秒間スリープ状態になり、ファイルを削除してから 10 分間スリープ状態になります。
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
Liveness コマンド
このデプロイは、liveness 検査として動作する exec liveness コマンドをサポートする livenessProbe を定義します。 このコマンドがゼロ以外の値で終了すると、コンテナーが強制終了されて再起動し、healthy ファイルが見つからなかったことが通知されます。 このコマンドが終了コード 0 で正常終了した場合、アクションは何も行われません。
periodSeconds プロパティは、liveness コマンドを 5 秒ごとに実行することを指定します。
liveness の出力を確認する
最初の 30 秒以内には、start コマンドによって作成された healthy ファイルが存在します。 liveness コマンドで healthy ファイルの存在が検査されると、状態コードで 0 が返り、再起動が行われないように成功が通知されます。
30 秒後、cat /tmp/healthy で異常が発生し始め、異常イベントと強制終了イベントが発生します。
これらのイベントは、Azure Portal または Azure CLI から表示できます。
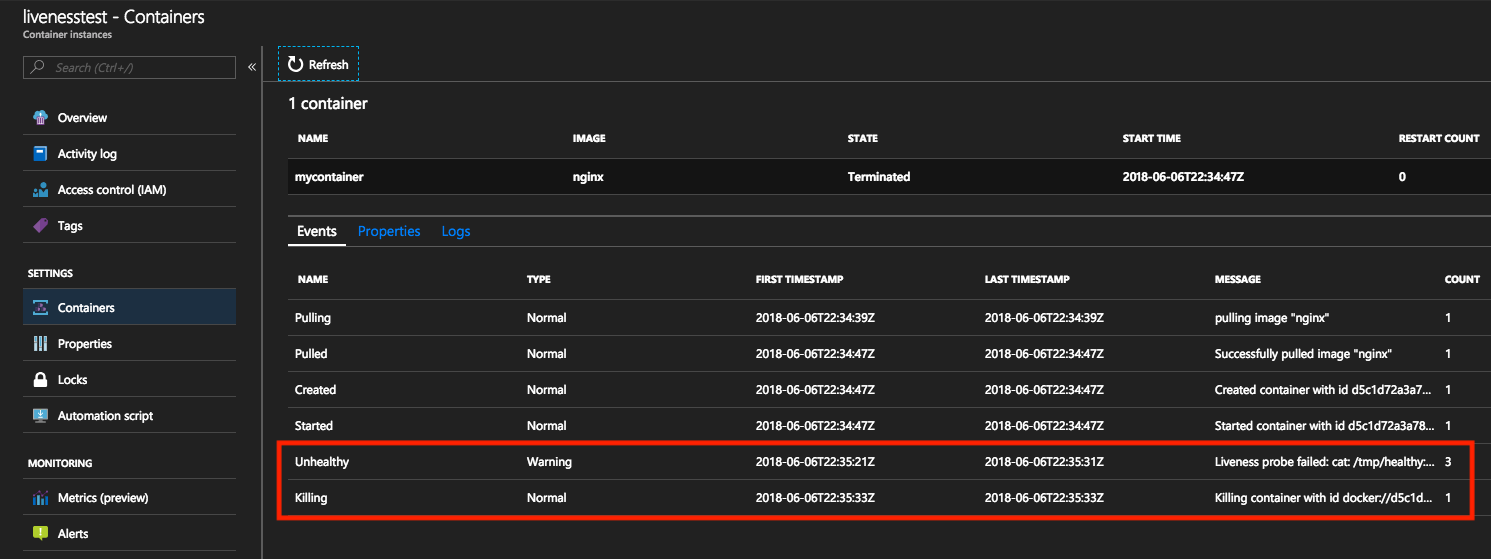
Azure portal でイベントを表示することによって、liveness コマンドの失敗時に種類が Unhealthy のイベントがトリガーされます。 後続のイベントの種類は Killing であり、再起動を開始できるコンテナーの削除を示します。 コンテナーの再起動カウントは、このイベントが発生するたびに増分されます。
パブリック IP アドレスやノード固有のコンテンツなどのリソースが保持されるように再起動が適切に完了します。

liveness probe が継続的に失敗し、過剰な回数の再起動がトリガーされる場合、お使いのコンテナーは指数バック オフ遅延になります。
Liveness probe および再起動のポリシー
再起動ポリシーは、liveness probe によってトリガーされる再起動動作よりも優先されます。 たとえば、restartPolicy = Never "および" liveness probe を設定した場合、コンテナー グループは、liveness 検査の失敗により再起動されることはありません。 コンテナー グループはコンテナー グループの再起動ポリシーである Never に従います。
次のステップ
タスク ベースのシナリオでは、前提となる機能が正しく動作しない場合に、自動再起動を有効にするために liveness probe が必要になる場合があります。 タスク ベースのコンテナーの実行に関する詳細については、「Azure Container Instances でコンテナー化タスクを実行する」を参照してください。