適用対象:
![]() カサンドラ
カサンドラ
この記事では、Azure Cosmos DB for Apache Cassandra におけるパーティション分割のしくみについて説明します。
Cassandra 用 API では、パーティション分割を使用して、キースペースに存在する個別のテーブルをスケーリングし、アプリケーションのパフォーマンスのニーズを満たします。 パーティションは、テーブル内の各レコードに関連付けられているパーティション キーの値に基づいて形成されます。 1 つのパーティション内のレコードはすべて、パーティション キーの値が同じです。 Azure Cosmos DB では、パーティションの物理リソースへの配置が透過的かつ自動的に管理され、テーブルのスケーラビリティとパフォーマンスのニーズが効率的に満たされます。 アプリケーションのスループットとストレージの要件が上がると、Azure Cosmos DB はデータを移動し、より多くの物理マシンに分散します。
開発者の観点からは、Azure Cosmos DB for Apache Cassandra のパーティション分割は、ネイティブ Apache Cassandra の場合と同じように動作します。 ただし、バックグラウンドではいくつかの違いがあります。
Apache Cassandra と Azure Cosmos DB の違い
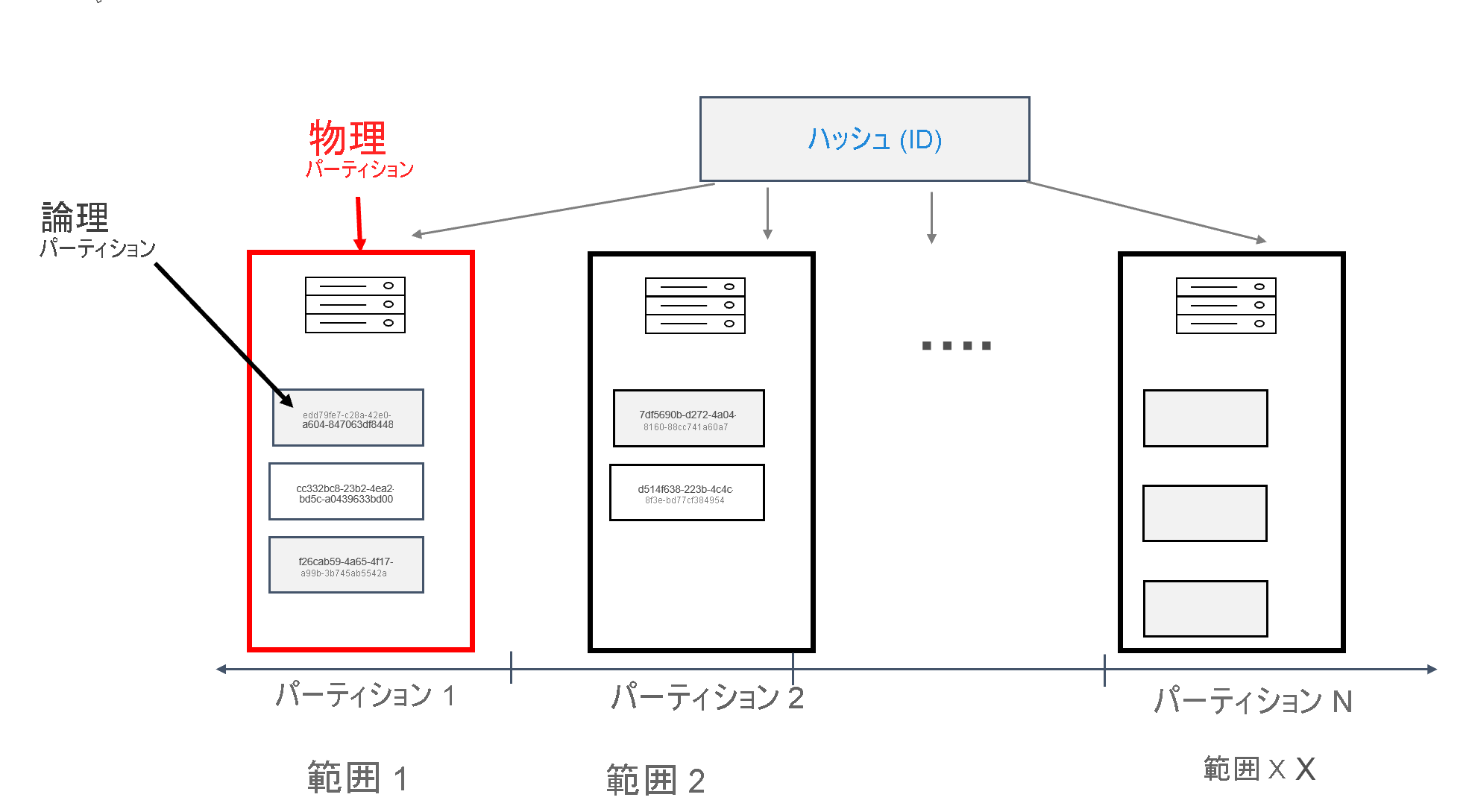
Azure Cosmos DB では、パーティションが格納されている各マシンは、物理パーティションと呼ばれます。 物理パーティションは、仮想マシンに似ています (専用のコンピューティング ユニットや物理リソースのセット)。 このコンピューティング ユニットに格納された各パーティションは、Azure Cosmos DB で論理パーティションと呼ばれます。 Apache Cassandra に既に慣れている場合は、Cassandra での通常のパーティションと同じように論理パーティションを考えることができます。
Apache Cassandra では、パーティションに格納できるデータのサイズの上限に 100 MB が推奨されます。 Azure Cosmos DB の Cassandra 用 API では、論理パーティションあたり最大 20 GB、物理パーティションあたり最大 30 GB のデータが許容されています。 Azure Cosmos DB では、Apache Cassandra とは異なり、物理パーティションで使用できるコンピューティング容量は、要求ユニットと呼ばれる単一のメトリックを使用して表されます。これにより、コア数、メモリ、または IOPS ではなく、秒あたりの要求数の点でワークロードを考えることができます。 このため、それぞれの要求のコストを把握すると、容量計画をさらに簡単に行うことができます。 それぞれの物理パーティションには、利用できるコンピューティングとして最高 10000 RU を割り当てることができます。 スケーラビリティ オプションの詳細については、Cassandra 用 API でのエラスティック スケールに関する記事をご覧ください。
Azure Cosmos DB では、各物理パーティションはレプリカ セットとも呼ばれる一連のレプリカで構成され、パーティションごとに少なくとも 4 つのレプリカがあります。 これは、レプリケーション係数を 1 に設定できる Apache Cassandra とは対照的です。 ただし、データを持つ唯一のノードがダウンした場合は、これによって可用性が低下します。 Cassandra 用 API では、常に 4 のレプリケーション係数 (3 のクォーラム) があります。 Azure Cosmos DB は自動的にレプリカ セットを管理しますが、これらは、Apache Cassandra でさまざまなツールを使用して保持する必要があります。
Apache Cassandra には、パーティション キーのハッシュであるトークンの概念があります。 トークンは、値の範囲が -2^63 から -2^63 - 1 までの murmur3 64 バイト ハッシュに基づいています。 この範囲は、Apache Cassandra では通常 "トークン リング" と呼ばれます。 トークン リングはトークン範囲に分散され、これらの範囲は、ネイティブの Apache Cassandra クラスターに存在するノード間で分割されます。 Azure Cosmos DB のパーティション分割は、同様の方法で実装されますが、別のハッシュアルゴリズムを使用し、より大きな内部トークン リングを使用する点が異なります。 ただし、外部では Apache Cassandra と同じトークン範囲を公開しています。つまり、-2 ^ 63 から -2 ^ 63-1 までです。
Primary key (プライマリ キー)
Cassandra 用 API 内のテーブルはすべて、primary key が定義されている必要があります。 主キーの構文を次に示します。
column_name cql_type_definition PRIMARY KEY
さまざまなユーザーのメッセージを格納するユーザー テーブルを作成するとします。
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
この設計では、id フィールドを主キーとして定義しました。 主キーは、テーブル内のレコードの識別子として機能し、Azure Cosmos DB のパーティション キーとしても使用されます。 前に説明した方法で主キーが定義されている場合、各パーティションには 1 つのレコードのみが存在します。 これは、データベースにデータを書き込むときに、完全に水平でスケーラブルな分布になり、キー値ルックアップ ユース ケースに理想的です。 アプリケーションは、読み取りパフォーマンスを最大にするために、テーブルからデータを読み取るときにはいつでも主キーを提供する必要があります。
複合主キー
Apache Cassandra には compound keys の概念もあります。 複合primary keyは複数の列から構成されており、最初の列はpartition keyで、追加列はすべてclustering keysです。
compound primary keyの構文は次に示すとおりです。
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
上記の設計を変更し、特定のユーザーのメッセージを効率的に取得できるようにするとします。
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
この設計では、主キーとして user を定義し、クラスター化キーとして id を定義しています。 必要な数だけクラスター化キーを定義できますが、同じパーティションに複数のレコードが追加されるという結果になるように、クラスター化キーのそれぞれの値 (または値の組み合わせ) は一意である必要があります。次に例を示します。
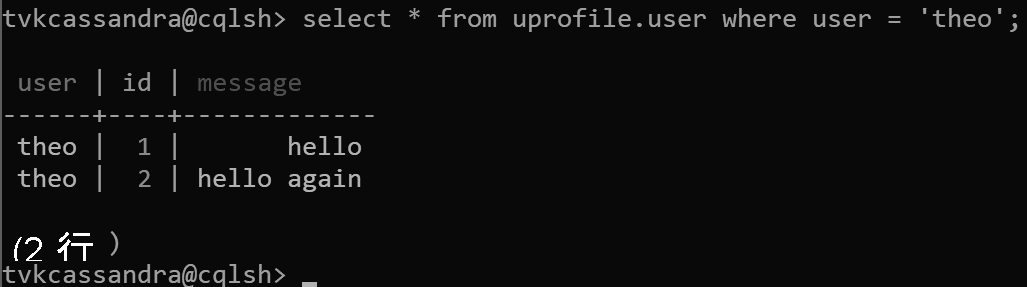
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
データは返されると、Apache Cassandra で想定されているように、クラスター化キーによって並べ替えられます。
警告
複合主キーを持つテーブル内のデータに対してクエリを実行するときに、パーティション キー "および" クラスタリング キー以外の他のインデックスのないフィールドでフィルター処理する場合は、"パーティション キーにセカンダリ インデックスを明示的に追加" してください。
CREATE INDEX ON uprofile.user (user);
既定では、Azure Cosmos DB for Apache Cassandra によってパーティション キーにインデックスが適用されません。また、このシナリオでは、クエリ パフォーマンスがインデックスによって大幅に向上する可能性があります。 詳細については、セカンダリ インデックス作成に関する記事を参照してください。
この方法でモデル化されたデータを使用して、各パーティションに複数のレコードを割り当て、ユーザー別にグループ化することができます。 そのため、partition key (この場合は user) によって効率的にルーティングされるクエリを発行して、特定のユーザーのすべてのメッセージを取得できます。
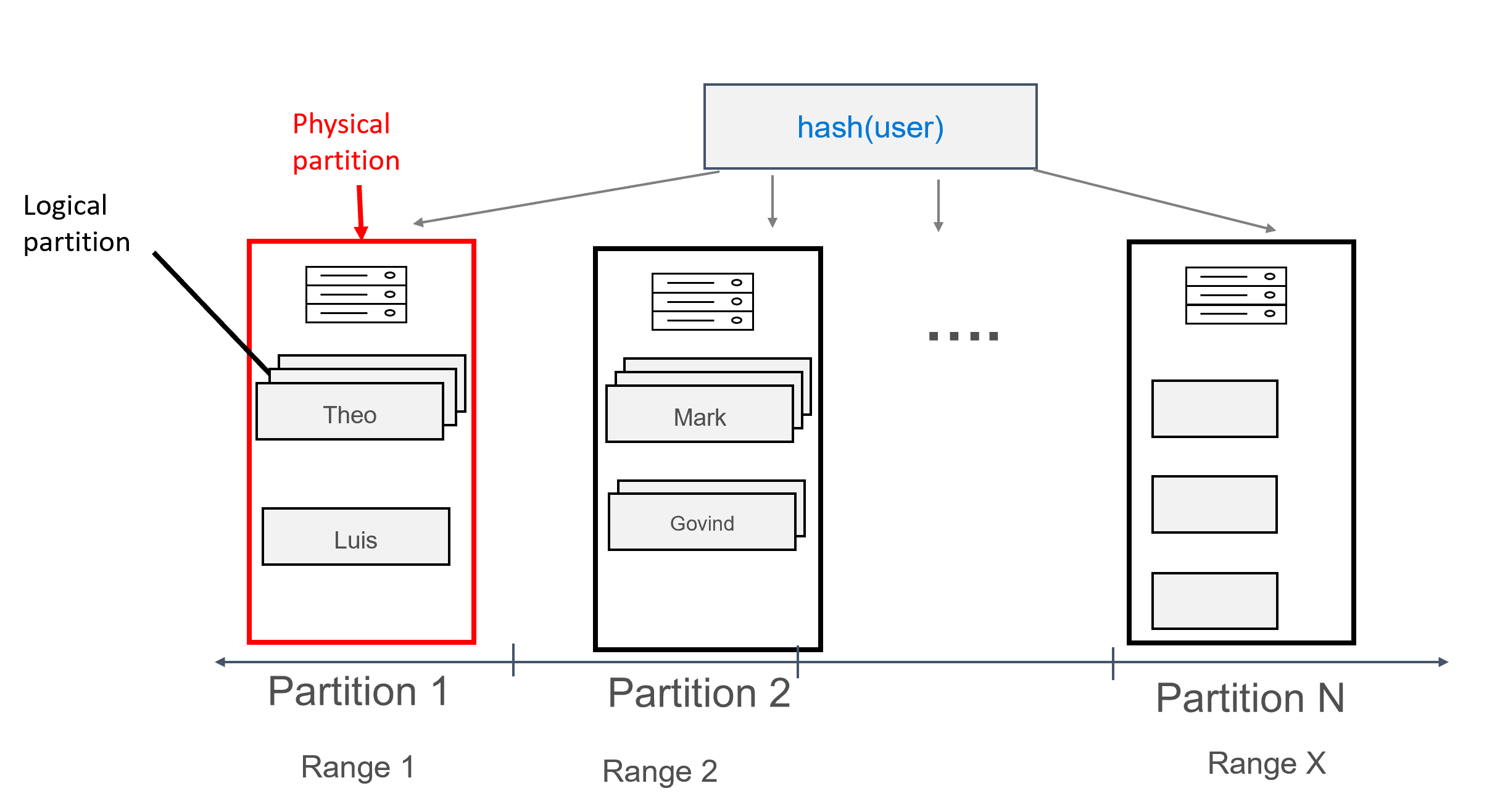
複合パーティション キー
複合パーティション キーは、基本的には複合キーと同じように機能しますが、複数の列を複合パーティション キーとして指定することができます。 複合パーティション キーの構文を次に示します。
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
たとえば、次のようにすることができます。この場合、firstname と lastname の一意の組み合わせによってパーティション キーが形成され、id がクラスター化キーになります。
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
次のステップ
- Azure Cosmos DB でのパーティション分割と水平スケーリングについて理解します。
- Azure Cosmos DB におけるスループットのプロビジョニングについて理解します。
- Azure Cosmos DB の世界規模での分散について理解します。