Azure Cosmos DB には、運用データに関する大規模な分析と BI レポートを可能にするさまざまなオプションが用意されています。
Azure Cosmos DB データに関する意味のある分析情報を得るには、Cosmos DB 内の複数のデータベースやコレクションにわたって合計、カウントなどの集計関数を使用してクエリを実行し、場合によっては Azure SQL Database や Lakehouse などの他のデータ ソースに対してクエリを実行する必要があります。 このようなクエリには大量の計算能力が必要であり、要求ユニット (RU) が多くなる可能性があるため、これらのクエリはミッション クリティカルなワークロードのパフォーマンスに影響を与える可能性があります。
トランザクション ワークロードを複雑な分析クエリによるパフォーマンスの影響から分離し、組織内の他のデータ ソースとそのデータを統合するために、Azure Cosmos DB と Microsoft Fabric は、Azure Cosmos DB ミラーリングと Microsoft Fabric 内の Cosmos DB を活用して、ETL 要件をゼロにしたコスト効率の高い分析ソリューションを提供することで、これらの課題に対処します。
重要
Synapse Link for Cosmos DB は、新しいプロジェクトではサポートされなくなりました。 この機能は使用しないでください。
現在 GA になっている Microsoft Fabric 用の Azure Cosmos DB ミラーリングを使用してください。 ミラーリングは、同じゼロ ETL の利点を提供し、Microsoft Fabric と完全に統合されています。 詳細については、 Cosmos DB ミラーリングの概要に関するページを参照してください。
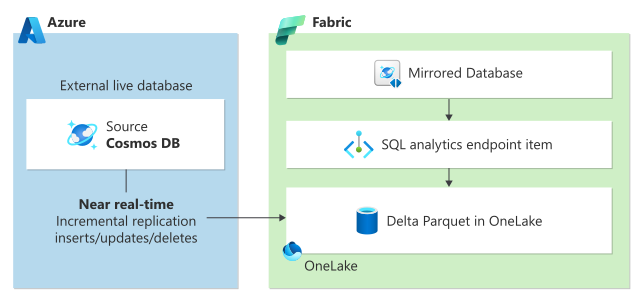
オプション 1: Azure Cosmos DB データを Microsoft Fabric にミラーリングする
Microsoft Fabric でのミラーリングにより、既存の Azure Cosmos DB データを Microsoft Fabric の残りのデータと統合して、トランザクション システムと分析システム間の完全なワークロード分離を実現する真のハイブリッド トランザクション/分析処理 (HTAP) を実現するシームレスな ETL なしのエクスペリエンスが提供されます。 Azure Cosmos DB データは、トランザクション ワークロードや要求ユニット (RU) の使用にパフォーマンスに影響を与えることなく、ほぼリアルタイムで Fabric OneLake に継続的に直接レプリケートされます。
OneLake のデータは、オープンソースのデルタ形式で格納され、Fabric 上のすべての分析エンジンで自動的に使用できるようになります。
組み込みの Power BI 機能を使用して、DirectLake モードの OneLake のデータにアクセスできます。 Fabric での Copilot の機能強化により、生成 AI の機能を使用して、ビジネス データに関する重要な分析情報を取得できます。 Power BI に加えて、T-SQL を使用して複雑な集計クエリを実行したり、データ探索に Spark を使用したりできます。 ノートブック内のデータにシームレスにアクセスし、データ サイエンスを使用して機械学習モデルを構築できます。
ミラーリングを使い始めるには、ミラーリングのチュートリアルの概要を扱うページを参照してください。
オプション 2: Fabric の Azure Cosmos DB
Microsoft Fabric の Cosmos DB は、管理エクスペリエンスが簡素化された AI 最適化 NoSQL データベースです。 開発者は、Fabric で Cosmos DB を使用して、一般的なデータベース管理タスクを実行しなくても、摩擦の少ない AI アプリケーションを構築できます。 分析ユーザーとして、Cosmos DB は待機時間の短いサービス レイヤーとして使用でき、レポートをより高速にし、数千人のユーザーに同時にサービスを提供できます。
Microsoft Fabric の Cosmos DB は、Azure Cosmos DB for NoSQL と同じインフラストラクチャである同じエンジンを使用しますが、Fabric に緊密に統合されています。 Cosmos DB は、半構造化データや進化するデータ モデルに最適なスキーマレス データ モデルを提供します。は、待ち時間が短く、高可用性が組み込まれた無限の自動スケーリングと瞬時スケーリングを提供します。
Fabric で Cosmos DB の使用を開始するには、「Microsoft Fabric での Cosmos DB データベースの作成」を参照してください。