急速に進化する生成 AI の領域では、GPT-3.5 のような大規模言語モデル (LLM) が自然言語処理を大きく変えました。 しかし、AI の新たなトレンドは、AI アプリケーションを強化する上で極めて重要な役割を果たすベクトル ストアの使用です。
このチュートリアルでは、Azure Cosmos DB for MongoDB (仮想コア)、LangChain、OpenAI を使用して、LLM とその制限について説明するとともに、優れた AI パフォーマンスを実現する取得拡張生成 (RAG) を実装する方法について説明します。 急速に導入が進む"取得拡張生成" (RAG) のパラダイムを探索し、LangChain フレームワーク、Azure OpenAI モデルについて簡単に説明します。 最後に、これらの概念を実際のアプリケーションに統合します。 閲覧者は最後まで、これらの概念の理解を深めることができます。
大規模言語モデル (LLM) とその制限の理解
大規模言語モデル (LLM) は、膨大なテキスト データセットでトレーニングされた高度なディープ ニューラル ネットワーク モデルで、人間が作成したようなテキストを理解し、生成できます。 自然言語処理において画期的である一方、LLM には次のような固有の制限があります。
- 幻覚: LLM では、"幻覚" として知られる、事実と異なる情報や、根拠のない情報が生成されます。
- 古いデータ: LLM は静的なデータセットでトレーニングが行われるため、最新の情報が含まれていない可能性があり、現在の妥当性が制限されます。
- ユーザーのローカル データへのアクセスなし: LLM は個人データやローカライズされたデータに直接アクセスできないため、パーソナライズされた回答を提供する機能が制限されます。
- トークン制限: LLM には対話ごとに最大トークン制限があり、一度に処理できるテキスト量が制限されます。 たとえば、OpenAI の gpt-3.5-turbo のトークン制限は 4096 です。
検索拡張生成 (RAG) を活用する
検索補強世代 (RAG) は、LLM の制限を克服するために設計されたアーキテクチャです。 RAG は、入力クエリに基づいて関連するドキュメントを検索するためにベクトル検索を使用し、より正確な応答を生成するために LLM にこれらのドキュメントをコンテキストとして提供します。 RAG は、事前トレーニング済みのパターンにのみ依存するのではなく、最新の関連情報を取り入れることで応答を強化します。 このアプローチは次のことに役立ちます。
- 幻覚の最小化: 事実情報に基づいた応答の根拠。
- 最新情報の確保: 最新の応答が得られるように、最新のデータを取得します。
- 外部データベースの活用: 個人データに直接アクセスすることはできませんが、RAG は外部のユーザー固有のナレッジ ベースとの統合を可能にします。
- トークン使用の最適化: 最も関連性の高いドキュメントにフォーカスすることで、RAG はトークンの使用を効率化します。
このチュートリアルでは、Azure Cosmos DB for MongoDB (仮想コア) を使用して RAG を実装し、データに合わせた質問応答アプリケーションを構築する方法について説明します。
アプリケーション アーキテクチャの概要
以下のアーキテクチャ図は、RAG 実装の主要コンポーネントを示しています。
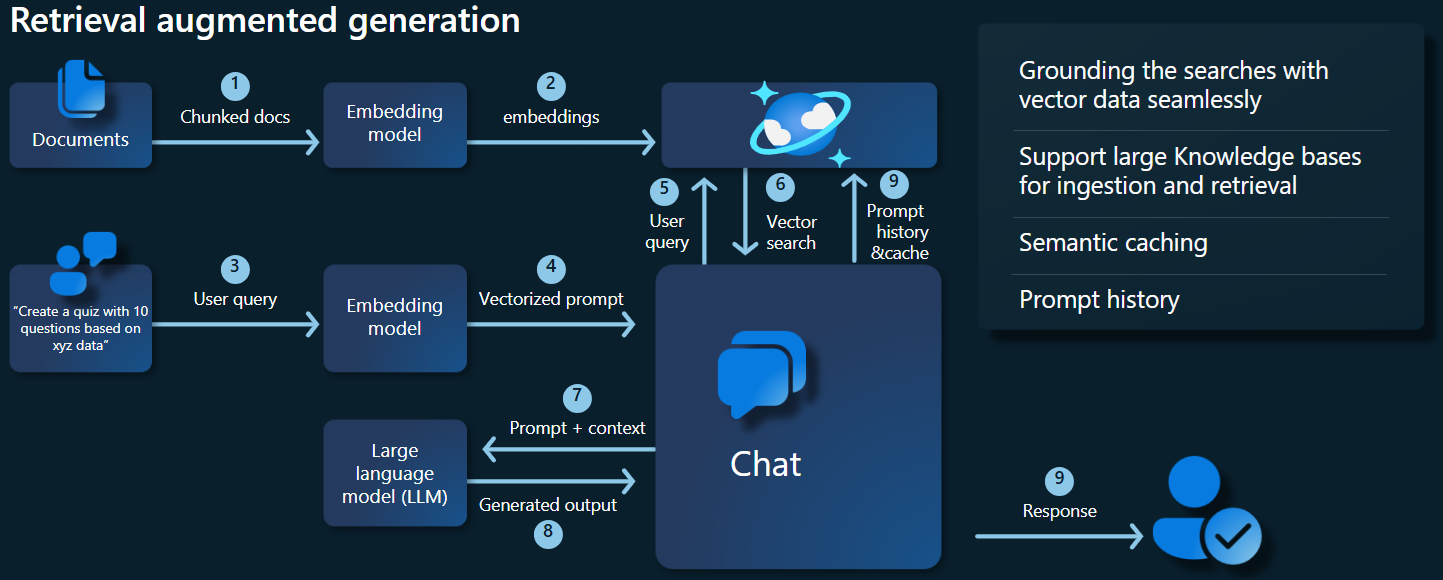
主要コンポーネントとフレームワーク
次に、このチュートリアルで使用するさまざまなフレームワーク、モデル、コンポーネントについて、それぞれの役割とニュアンスを強調しながら説明します。
Azure Cosmos DB for MongoDB (vCore)
Azure Cosmos DB for MongoDB (仮想コア) は、AI を活用したアプリケーションに不可欠なセマンティック類似検索をサポートします。 さまざまな形式のデータをベクトル埋め込みとして表現することができ、ソース データやメタデータと一緒に格納できます。 階層ナビゲーション可能な小さい世界 (HNSW) のような近似最近傍アルゴリズムを使用すると、これらの埋め込みは、高速な意味的類似性検索のためにクエリを実行できます。
LangChain フレームワーク
LangChain は、チェーン用の標準インターフェイス、複数のツール統合、一般的なタスク用のエンドツーエンド チェーンを提供することで、LLM アプリケーションの作成を簡略化します。 AI 開発者は、外部データソースを活用した LLM アプリケーションを構築できます。
LangChain の主要な側面:
- チェーン: 特定のタスクを解決するコンポーネントのシーケンス。
- コンポーネント: LLM ラッパー、ベクトル ストア ラッパー、プロンプト テンプレート、データ ローダー、テキスト スプリッター、取得などのモジュール。
- モジュール性: 開発、デバッグ、メンテナンスを簡略化します。
- 使用頻度: 急速に普及し、ユーザーのニーズに合わせて進化しているオープンソース プロジェクトです。
Azure App Services インターフェイス
App Services には、Gen-AI アプリケーションのためのユーザーフレンドリな Web インターフェイスを構築するための堅牢なプラットフォームが用意されています。 このチュートリアルでは、Azure App Service を使用して、アプリケーション用の対話型の Web インターフェイスを作成します。
OpenAI モデル
OpenAI は AI 研究のリーダーであり、言語生成、テキスト ベクター化、画像作成、音声テキスト変換などのさまざまなモデルが用意されています。 このチュートリアルでは、言語ベースのアプリケーションを理解し、生成するために重要な OpenAI の埋め込みと言語モデルを使用します。
埋め込みモデルと言語生成モデル
| カテゴリ | テキスト埋め込みモデル | 言語モデル |
|---|---|---|
| 目的 | テキストをベクトル埋め込みに変換します。 | 自然言語の理解と生成。 |
| 関数 | テキスト データを数値の高次元配列に変換し、テキストの意味をキャプチャします。 | 指定された入力を理解し、人間が生成したようなテキストを作成します。 |
| 出力 | 数値 (ベクトル埋め込み) の配列。 | テキスト、回答、翻訳、コードなど。 |
| 出力例 | 各埋め込みは、モデルによって決定された次元を用いて、テキストの意味を数値で表します。 たとえば、text-embedding-ada-002 は 1536 次元のベクトルを生成します。 |
提供された入力に基づいて生成された、コンテキストに関連した一貫性のあるテキスト。 たとえば、gpt-3.5-turbo は質問に対する回答を生成したり、テキストを翻訳したり、コードを書いたりすることができます。 |
| 一般的な使用例 | - セマンティック検索 | - チャットボット |
| - レコメンデーション システム | - コンテンツの自動作成 | |
| - テキスト データのクラスタリングと分類 | - 言語の翻訳 | |
| - 情報の取得 | - 要約 | |
| データ表現 | 数値表現 (埋め込み) | 自然言語テキスト |
| 次元 | 配列の長さは、埋め込み空間の次元数に相当します (例: 1536 次元)。 | 通常はトークンの列として表現され、コンテキストによって長さが決まります。 |
アプリケーションの主なコンポーネント
- Azure Cosmos DB for MongoDB vCore: ベクトル埋め込みの格納とクエリ実行。
- LangChain: アプリケーションの LLM ワークフローの構築。 次のようなツールを活用します。
- ドキュメント ローダー: ディレクトリからドキュメントを読み込んで処理します。
- ベクトル ストア統合: Azure Cosmos DB にベクトル埋め込みを格納し、クエリを実行します。
- AzureCosmosDBVectorSearch: Cosmos DB ベクトル検索のラッパー
- Azure App Services: Cosmic Food アプリのユーザー インターフェイスの構築。
- Azure OpenAI: 次のような LLM と埋め込みモデルの提供。
- text-embedding-ada-002: テキストを 1536 次元のベクトル埋め込みに変換するテキスト埋め込みモデル。
- gpt-3.5-turbo: 自然言語の理解と生成のための言語モデル。
環境を設定する
Azure Cosmos DB for MongoDB (仮想コア) を使用して取得拡張生成 (RAG) の最適化を始めるには、次の手順に従ってください。
- Microsoft Azure で次のリソースを作成します。
- Azure Cosmos DB for MongoDB 仮想コア クラスター: クイック スタート ガイドを参照してください。
- Azure OpenAI リソース (以下を使用):
- 埋め込みモデル デプロイ (例:
text-embedding-ada-002)。 - チャット モデル デプロイ (例:
gpt-35-turbo)。
- 埋め込みモデル デプロイ (例:
サンプル ドキュメント
このチュートリアルでは、ドキュメントを使用して単一のテキスト ファイルを読み込みます。 これらのファイルは src フォルダーの data というディレクトリに保存する必要があります。 その内容は次のとおりです。
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
ドキュメントを読み込む
Cosmos DB for MongoDB (仮想コア) の接続文字列、データベース名、コレクション名、インデックスを設定します。
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]埋め込みクライアントを初期化します。
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )データから埋め込みを作成し、データベースに保存し、ベクトル ストアである Cosmos DB for MongoDB (仮想コア) への接続を返します。
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )コレクションに以下の HNSWベクトル インデックスを作成します (インデックスの名前は上記と同じです)。
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Cosmos DB for MongoDB (仮想コア) を使用してベクトル検索を実行する
ベクトル ストアに接続します。
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )クエリで Cosmos DB ベクトル検索を使用して意味的類似性検索を実行する関数を定義します (このコード スニペットは単なるテスト関数であることに注意してください)。
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)RAG 関数を実装するためにチャット クライアントを初期化します。
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )RAG 関数を作成します。
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )指定されたパラメーターに基づいて、ベクトル ストアを関連ドキュメントの検索ができる取得に変換します。
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )azure_openai_chat モデルと vector_store_retriever を使用して、コンテキストに関連したドキュメント検索を確保し、会話の履歴を認識する取得チェーンを作成します。
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)言語モデル (azure_openai_chat) と指定されたプロンプト (context_prompt) を使用して、取得したドキュメントを一貫性のある応答に結合するチェーンを作成します。
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)履歴認識取得チェーンとドキュメント結合チェーンを統合し、取得プロセス全体を処理するチェーンを作成します。 この RAG チェーンを実行することで、コンテキストに沿った正確な回答を取得および生成できます。
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
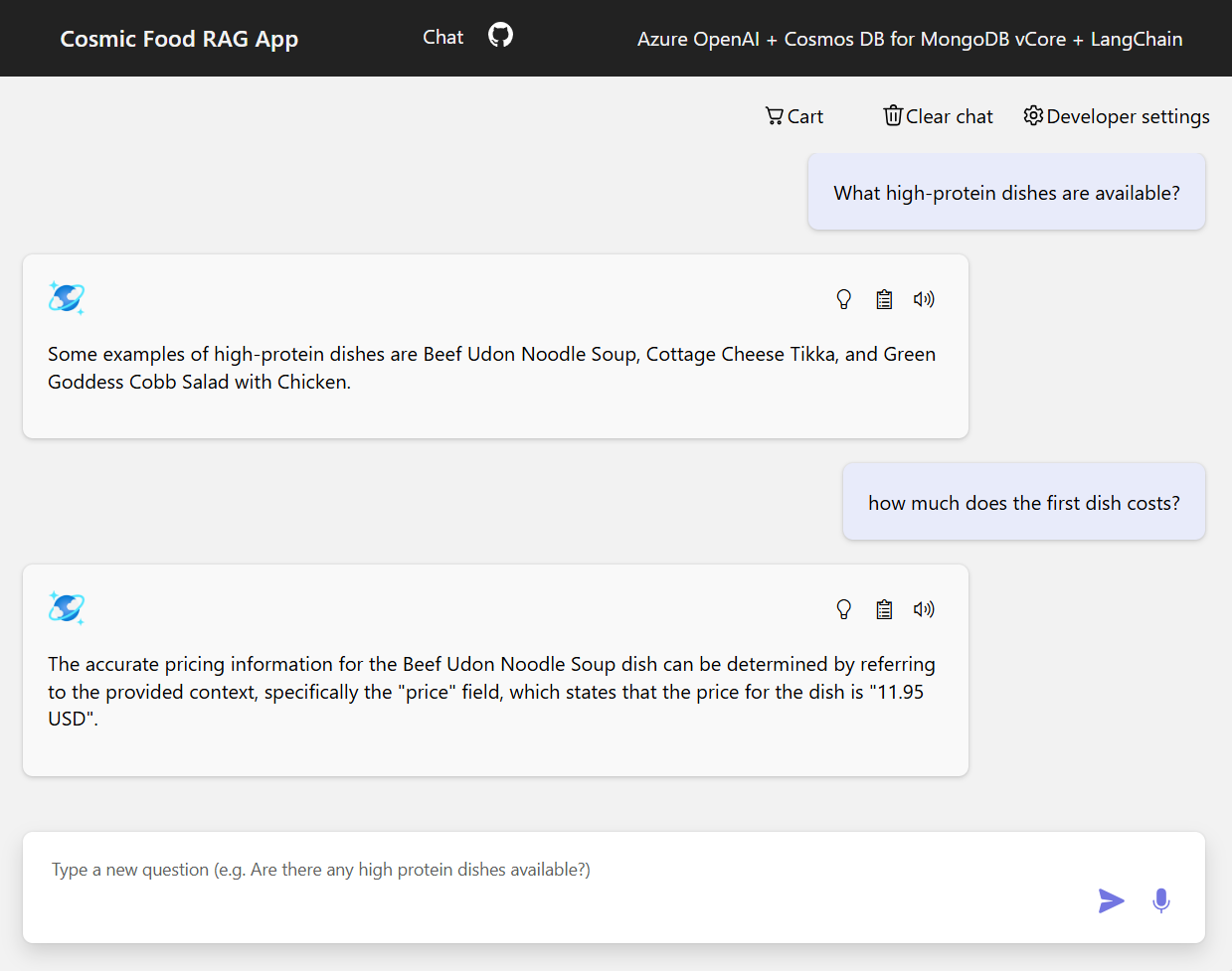
サンプル出力
以下のスクリーンショットは、さまざまな質問に対する出力を示しています。 純粋な意味類似性検索は、ソース ドキュメントから生テキストを返します。一方、RAG アーキテクチャを使用した質問応答アプリは、取得したドキュメント コンテンツと言語モデルを組み合わせることで、正確でパーソナライズされた回答を生成します。
まとめ
このチュートリアルでは、Cosmos DB をベクトル ストアとして使用し、個人データと対話する質問回答アプリの構築方法について説明しました。 LangChain と Azure OpenAI で取得拡張生成 (RAG) アーキテクチャを活用することで、LLM アプリケーションにベクトル ストアが不可欠であることを実証しました。
RAG は、AI、特に自然言語処理における大きな進歩であり、これらのテクノロジーを組み合わせることで、さまざまなユース ケースに対応した強力な AI 駆動型アプリケーションを作成できます。