適用対象: ![]() NoSQL
NoSQL
この記事では、Amazon DynamoDB から Azure Cosmos DB for NoSQL への データ移行 について説明します。 開始する前に、データ移行とアプリケーション移行の違いを理解しておくことが重要です。
- データ移行には、ソース システム (この場合は DynamoDB) からのデータのエクスポート、変換などの追加処理の実行、最後に Azure Cosmos DB へのデータの書き込みなど、多くの手順が含まれている可能性があります。
- アプリケーションの移行には、DynamoDB ではなく Azure Cosmos DB を使用するようにアプリケーションをリファクタリングすることが含まれます。 このプロセスには、クエリの適応と書き換え、パーティション分割戦略の再設計、インデックス作成、一貫性の確保などが含まれます。
要件に応じて、アプリケーションの移行と並行してデータを移行できます。 ただし、多くの場合、データ移行はアプリケーション移行の前提条件です。 アプリケーションの移行の詳細については、「 Amazon DynamoDB から Azure Cosmos DB へのアプリケーションの移行」を参照してください。
移行の手法
さまざまな移行手法を使用できます。 よく使用される 2 つの手法は次のとおりです。
オンライン移行: アプリケーションでダウンタイムを許容できないため、リアルタイムのデータ移行が必要な場合は、この手法を選択します。
オフライン移行: メンテナンス期間中にアプリケーションを一時的に停止できる場合は、オフライン モードでデータ移行を実行できます。 最初に、DynamoDB から中間の場所にデータをエクスポートします。 次に、データを Azure Cosmos DB にインポートします。
この手法にはいくつかのオプションがあります。 この記事では、そのようなオプションの 1 つについて説明します。
特定の要件に基づいて手法を選択します。 それらを組み合わせることもできます。 たとえば、オフライン プロセスを使用してデータを一括移行し、オンライン モードに切り替えることができます。 この選択は、Azure Cosmos DB と並行して DynamoDB を (一時的に) 使用し続け、データをリアルタイムで同期する必要がある場合に適しています。
実際の移行の前に概念実証フェーズを使用して、オプションを十分に評価してテストすることをお勧めします。 このフェーズは、複雑さを評価し、実現可能性を評価し、移行計画を微調整するのに役立ちます。
オフライン移行のアプローチ
この記事に従うアプローチは、DynamoDB から Azure Cosmos DB にデータを移行する多くの方法の 1 つに過ぎません。 これには、独自の長所と短所のセットがあります。 オフライン移行のアプローチの一覧を以下に示します。
| アプローチ | 長所 | 短所 |
|---|---|---|
| DynamoDB から S3 にエクスポートし、Azure Data Factory を使用して Azure Data Lake Storage Gen2 に読み込み、Azure Databricks 上の Spark を使用して Azure Cosmos DB に書き込みます。 | 保存と処理を分離します。 Spark は、スケーラビリティと柔軟性 (追加のデータ変換、処理) を提供します。 | マルチステージ プロセスにより、複雑さと全体的な待機時間が増加します。 Spark に関する知識が必要です。 |
| DynamoDB から S3 にエクスポートし、Azure Data Factory を使用して S3 から読み取り、Azure Cosmos DB に書き込みます。 | ローコード/ノーコードアプローチ。 Spark スキルセットは必要ありません。 単純なデータ変換に適しています。 | 複雑な変換を実装するのは難しい場合があります。 |
| Azure Databricks 上の Spark を使用して DynamoDB から読み取り、Azure Cosmos DB に書き込みます。 | 直接処理では追加のストレージ コストが回避されるため、小規模なデータセットに適しています。 複雑な変換をサポートします (Spark)。 | RCU 消費による DynamoDB 側のコストが高くなります。 (S3 エクスポートは使用されません。)Spark に関する知識が必要です。 |
オンライン移行のアプローチ
オンライン移行では、通常、変更データ キャプチャ (CDC) メカニズムを使用して、DynamoDB からのデータ変更をストリーミングします。 これらの変更は、多くの場合、リアルタイムまたはほぼリアルタイムになる傾向があります。 ストリーミング データを処理して Azure Cosmos DB に書き込むには、別のコンポーネントを構築する必要があります。 オンライン移行のアプローチの一覧を以下に示します。
| アプローチ | 長所 | 短所 |
|---|---|---|
| DynamoDB ストリームで DynamoDB CDC を使用し、AWS Lambda を使用して処理し、Azure Cosmos DB に書き込みます。 | DynamoDB Streams では、順序付けの保証が提供されます。 イベント駆動型処理。 単純なデータ変換に適しています。 | DynamoDB ストリームのデータリテンション期間は 24 時間です。 カスタム ロジック (ラムダ関数) を記述する必要があります。 |
| DynamoDB CDC と Kinesis データ ストリームを使用し、Kinesis または Flink を使用して処理し、Azure Cosmos DB に書き込みます。 | 複雑なデータ変換 (Flink によるウィンドウ化/集計) をサポートし、処理をより適切に制御できます。 リテンション期間は柔軟です (24 時間から 365 日まで延長可能)。 | 順序が保証されません。 カスタム ロジック (Flink ジョブ、Kinesis Data Streams コンシューマー) を記述する必要があります。 ストリーム処理の専門知識が必要です。 |
オフライン移行のチュートリアル
このセクションでは、Azure Data Factory、Azure Data Lake Storage、Azure Databricks での Spark を使用してデータを移行する方法について説明します。 次の図は、主な手順を示しています。

- ネイティブの DynamoDB エクスポート機能を使用して、DynamoDB テーブルから DynamoDB JSON 形式で S3 にデータをエクスポートします。
- Azure Data Factory パイプラインを使用して、S3 の DynamoDB テーブル データを Data Lake Storage Gen2 に書き込みます。
- Azure Databricks 上の Spark を使用して Azure Storage 内のデータを処理し、Azure Cosmos DB にデータを書き込みます。
前提条件
続行する前に、次の項目を作成します。
- Azure Cosmos DB アカウント
- ストレージ アカウントはStandard 汎用 v2 型の
- Azure Data Factory
- からデータを移行する AWS アカウントと Amazon DynamoDB テーブル
ヒント
新しい DynamoDB テーブルでこのチュートリアルを試す場合は、 このデータ ローダー ツール を使用して、サンプル データをテーブルに設定できます。
手順 1: DynamoDB から Amazon S3 にデータをエクスポートする
DynamoDB S3 エクスポートは、DynamoDB データを Amazon S3 バケットにエクスポートするための組み込みソリューションです。 必要な S3 アクセス許可の設定など、このプロセスを実行する手順については、 DynamoDB のドキュメントに従ってください。 DynamoDB では、エクスポートされたデータのファイル形式として DynamoDB JSON と Amazon Ion がサポートされています。
このチュートリアルでは、DynamoDB JSON 形式でエクスポートされたデータを使用します。
手順 2: Azure Data Factory を使用して S3 データを Azure Storage に転送する
次のコマンドを使用して、GitHub リポジトリをローカル コンピューターに複製します。 リポジトリには、この記事の後半で使用する Azure Data Factory パイプライン テンプレートと Spark ノートブックが含まれています。
git clone https://github.com/AzureCosmosDB/migration-dynamodb-to-cosmosdb-nosql
Azure portal を使用して、リンクされたサービスを作成します。
Azure portal で、Azure Data Factory に移動します。 [Studio の起動] を選択して Azure Data Factory Studio を開きます。
Amazon S3 用の Azure Data Factory のリンクされたサービスを作成します。 前にテーブル データをエクスポートした S3 バケットの詳細を入力します。
Azure Data Lake Storage Gen2 のリンクされたサービスを作成します。 前に作成したストレージ アカウントの詳細を入力します。

Azure portal を使用して Azure Data Factory パイプラインを作成します。 Data Factory パイプラインは、1 つのタスクを連携して実行するアクティビティの論理的なグループです。
Data Factory Studio で、[ 作成者 ] タブに移動します。
プラス記号を選択します。 表示されたメニューで、[ パイプライン] を選択し、[ パイプライン テンプレートからインポート] を選択します。
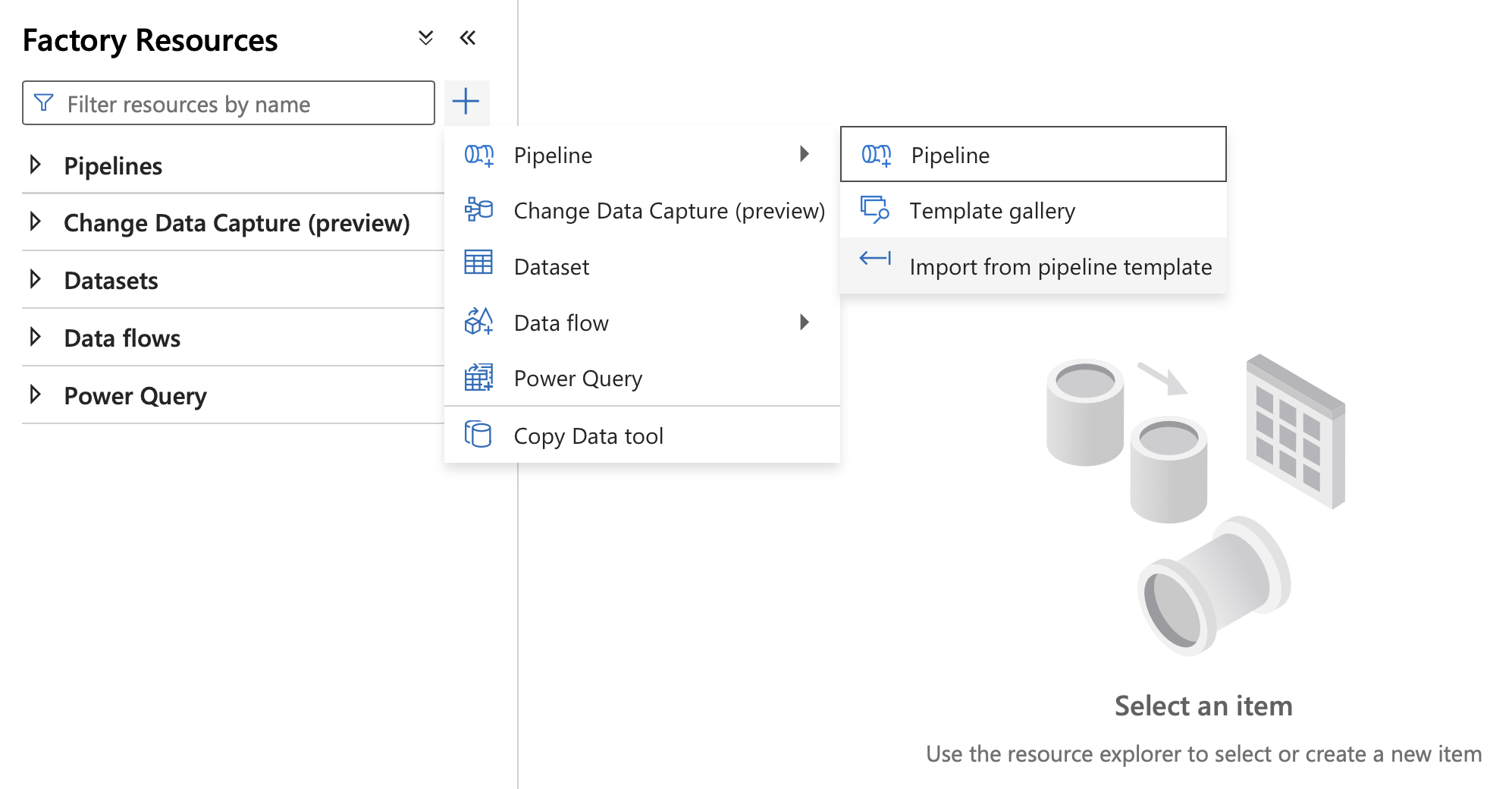
GitHub リポジトリから複製したテンプレート ファイル (S3ToADLSGen2.zip) を選択します。
構成で、Amazon S3 と Azure Data Lake Storage Gen2 用に作成したリンクされたサービスを選択します。 次に、[ このテンプレートを使用して パイプラインを作成する] を選択します。

パイプラインを選択し、[ ソース] に移動して、ソース (Amazon S3) データセットを編集します。
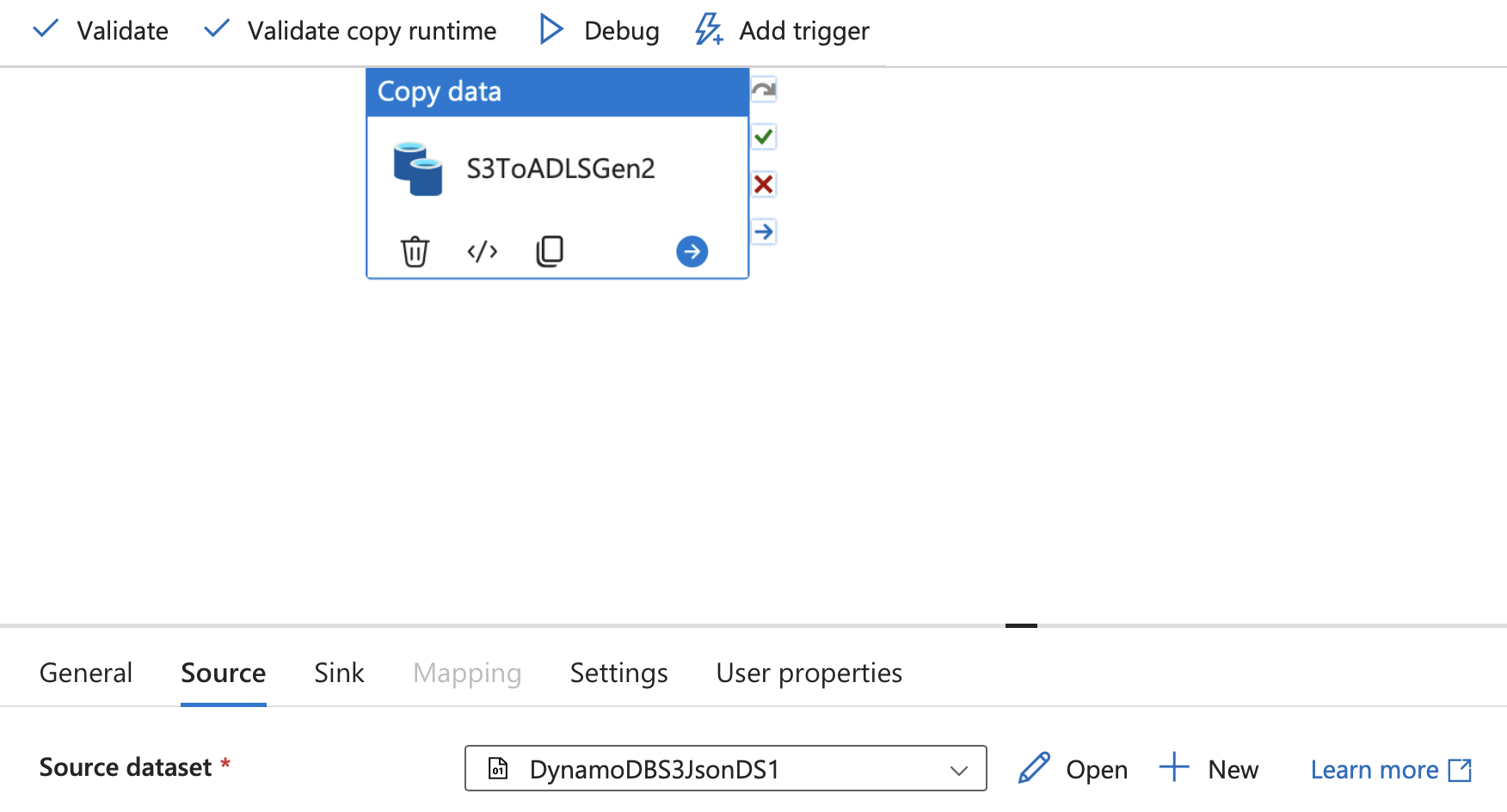
[ファイル パス] で、Amazon S3 バケット内のエクスポートされたファイルへのパスを入力します。
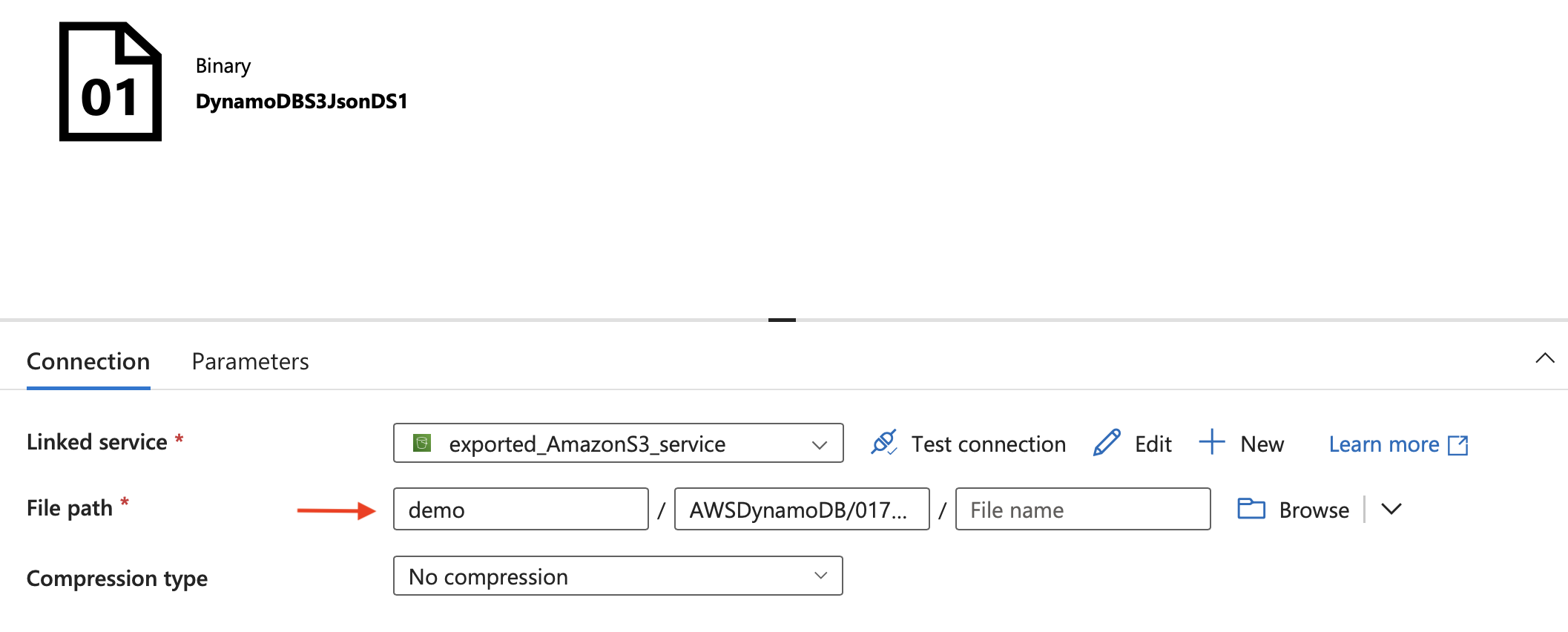
重要
シンク データセットを編集して、S3 からのデータが格納されるストレージ コンテナーの名前を更新することもできます。 既定では、コンテナーには
s3datacopyという名前が付けられます。変更が完了したら、[ すべて発行 ] を選択してパイプラインを発行します。




パイプラインを手動でトリガーするには、次の操作を実行します:
パイプラインを選択します。 パイプライン エディターの上部にある [ トリガーの追加] を選択します。
[ 今すぐトリガー] を選択し、[ OK] を選択します。
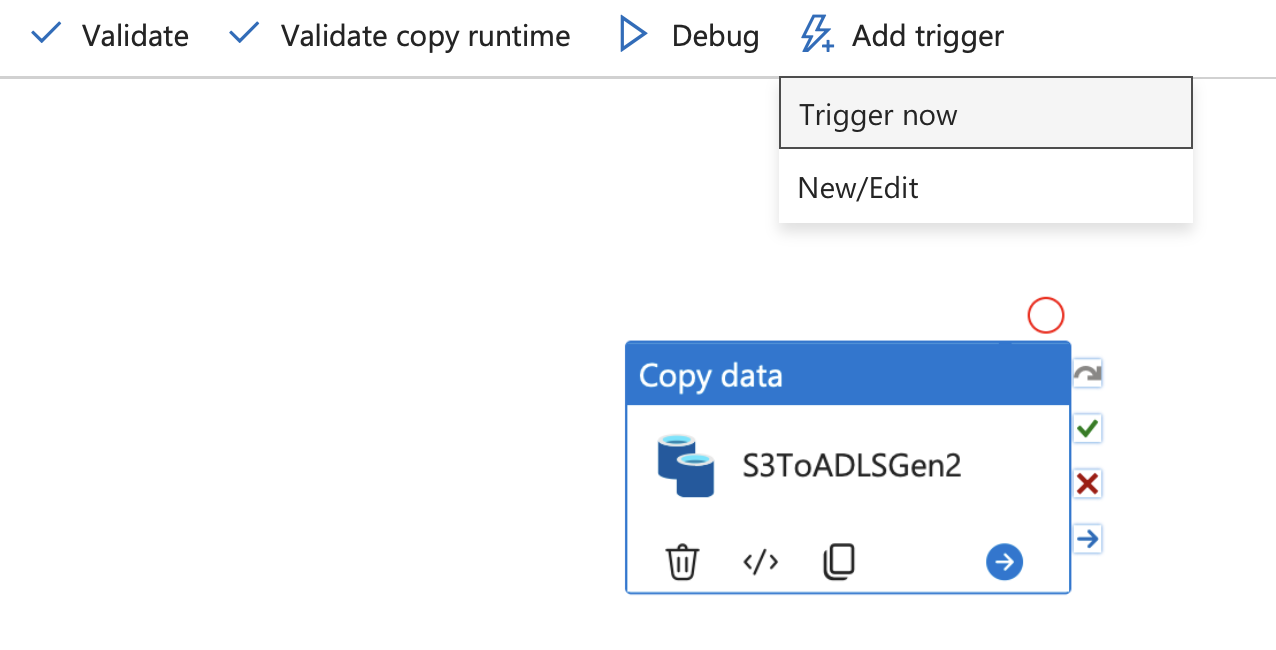

パイプラインが引き続き実行されると、 それを監視できます。 正常に完了したら、前に作成した Azure ストレージ アカウント内のコンテナーの一覧を確認します。

S3 バケットの内容と共に、新しいコンテナーが作成されたことを確認します。

手順 3: Azure Databricks 上の Spark を使用して Data Lake Storage Gen2 データを Azure Cosmos DB にインポートする
このセクションでは、Azure Cosmos DB Spark コネクタを使用して Azure Cosmos DB にデータを書き込む方法について説明します。 Azure Cosmos DB Spark コネクタは、Azure Cosmos DB NoSQL API の Apache Spark サポートを提供します。 これを使用して、Python と Scala の Apache Spark DataFrames を使用して Azure Cosmos DB の読み取りと書き込みを行うことができます。
まず、Azure Databricks ワークスペースを作成します。 Azure Cosmos DB Spark コネクタ、Apache Spark、JVM、Scala、Databricks ランタイムなどのコンポーネントのバージョン互換性については、 互換性マトリックスを参照してください。

Azure Databricks ワークスペースを作成したら、 ドキュメントに従って適切な Spark コネクタのバージョンをインストールします。 この記事の残りの手順は、Databricks Runtime 15.4 (Scala 2.12) 上の Spark 3.5.0 でコネクタ バージョン 4.36.0 と連携します。 コネクタの Maven 座標については、 Maven Central リポジトリを参照してください。

GitHub (migration.ipynb) のノートブックには、Data Lake Storage Gen2 からデータを読み取って Azure Cosmos DB に書き込むための Spark コードがあります。 ノートブックを Azure Databricks ワークスペースにインポートします。
Microsoft Entra ID 認証の構成
OAuth 2.0 資格情報と Microsoft Entra ID サービス プリンシパルを使用して、Azure Databricks から Azure Storage に接続します。 ドキュメントに従って、次の手順を完了します。
Microsoft Entra ID アプリケーションを登録し、新しいクライアント シークレットを作成します。 これは 1 回限りのステップです。
プロセスの一環として、クライアント ID、クライアント シークレット、およびテナント ID をメモします。 以降の手順で使用します。
Azure ストレージ アカウントの [アクセス制御 (IAM)]で、作成した Microsoft Entra ID アプリケーションに ストレージ BLOB データ閲覧者 ロールを割り当てます。
Azure Cosmos DB の Microsoft Entra ID 認証を構成するには、次の手順を実行します:
Azure Cosmos DB アカウントの [アクセス制御 (IAM)] で、作成した Microsoft Entra ID アプリケーションに Cosmos DB オペレーター ロールを割り当てます。
Azure CLI で次のコマンドを使用して、Azure Cosmos DB ロール定義を作成し、ロール定義 ID を取得します。 Azure CLI を設定していない場合は、代わりに Azure portal から直接 Azure Cloud Shell を使用することを選択できます。
az cosmosdb sql role definition create --resource-group "<resource-group-name>" --account-name "<account-name>" --body '{ "RoleName": "<role-definition-name>", "Type": "CustomRole", "AssignableScopes": ["/"], "Permissions": [{ "DataActions": [ "Microsoft.DocumentDB/databaseAccounts/readMetadata", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/items/*", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/*" ] }] }' // List the role definition you created to fetch its unique identifier in the JSON output. Record the id value of the JSON output. az cosmosdb sql role definition list --resource-group "<resource-group-name>" --account-name "<account-name>"ロール定義を作成し、ロール定義 ID を取得したら、次のコマンドを使用して 、Microsoft Entra ID アプリケーションに関連付けられているサービス プリンシパル ID を取得します。
AppIdを Microsoft Entra ID アプリケーションのクライアント ID に置き換えます。SP_ID=$(az ad sp list --filter "appId eq '{AppId}'" | jq -r '.[0].id')次のコマンドを使用して、ロールの割り当てを作成します。 リソース グループ名、Azure Cosmos DB アカウント名、ロール定義 ID を必ず置き換えてください。
az cosmosdb sql role assignment create --resource-group <enter resource group name> --account-name <enter cosmosdb account name> --scope "/" --principal-id $SP_ID --role-definition-id <enter role definition ID> --scope "/"
ノートブックで手順を実行する
最初の 2 つの手順を実行して、必要な依存関係をインストールします:
pip install azure-cosmos azure-mgmt-cosmosdb azure.mgmt.authorization
dbutils.library.restartPython()
3 番目の手順では、Data Lake Storage Gen2 から DynamoDB データを読み取り、DataFrame に格納します。 手順を実行する前に、次の情報をセットアップの対応する値に置き換えます。
| 変数 | 説明 |
|---|---|
storage_account_name |
Azure ストレージ アカウント名。 |
container_name |
Azure ストレージ コンテナー名。 (例: s3datacopy)。 |
file_path |
Azure ストレージ コンテナー内のエクスポートされた JSON ファイルを含むフォルダーへのパス。 (例: AWSDynamoDB/01738047791106-7ba095a9/data/*)。 |
client_id |
Microsoft Entra ID アプリケーションのアプリケーション (クライアント) ID ( [概要 ] ページにあります)。 |
tenant_id |
Microsoft Entra ID アプリケーションのディレクトリ (テナント) ID ( [概要 ] ページにあります)。 |
client_secret |
Microsoft Entra ID アプリケーションに関連付けられているクライアント シークレットの値 ( 証明書とシークレットにあります)。 |
必要に応じて、次のセル (4 番目の手順) を実行して、データ変換を実行したり、カスタム ロジックを実装したりできます。 たとえば、Azure Cosmos DB に書き込む前に、 id フィールドをデータに追加できます。
5 番目の手順を実行して、Azure Cosmos DB データベースとコンテナーを作成します。 Azure Cosmos DB Spark コネクタのカタログ API を使用します。 次の情報をセットアップの対応する値に置き換えます:
| 変数 | 説明 |
|---|---|
cosmosEndpoint |
Azure Cosmos DB アカウントの URI。 |
cosmosDatabaseName |
作成する Azure Cosmos DB データベースの名前。 |
cosmosContainerName |
作成する Azure Cosmos DB コンテナーの名前。 |
subscriptionId |
Azure サブスクリプション ID。 |
resourceGroupName |
Azure Cosmos DB リソース グループ名。 |
partitionKeyPath |
コンテナーのパーティション キー。 (例: /id)。 |
throughput |
コンテナーのスループット。 (例: 1000)。コンテナーに関連付けるスループットに注意してください。 移行するデータの量によっては、この値の調整が必要になる場合があります。 |
client_id |
Microsoft Entra ID アプリケーションのアプリケーション (クライアント) ID ( [概要 ] ページにあります)。 |
tenant_id |
Microsoft Entra ID アプリケーションのディレクトリ (テナント) ID ( [概要 ] ページにあります)。 |
client_secret |
Microsoft Entra ID アプリケーションに関連付けられているクライアント シークレットの値 ( 証明書とシークレットにあります)。 |
6 番目と最後の手順を実行して、Azure Cosmos DB にデータを書き込みます。 次の情報をセットアップの対応する値に置き換えます:
| 変数 | 説明 |
|---|---|
cosmosEndpoint |
Azure Cosmos DB アカウントの URI。 |
cosmosDatabaseName |
作成する Azure Cosmos DB データベースの名前。 |
cosmosContainerName |
作成する Azure Cosmos DB コンテナーの名前。 |
subscriptionId |
Azure サブスクリプション ID。 |
resourceGroupName |
Azure Cosmos DB リソース グループ名。 |
client_id |
Microsoft Entra ID アプリケーションのアプリケーション (クライアント) ID ( [概要 ] ページにあります)。 |
tenant_id |
Microsoft Entra ID アプリケーションのディレクトリ (テナント) ID ( [概要 ] ページにあります)。 |
client_secret |
Microsoft Entra ID アプリケーションに関連付けられているクライアント シークレットの値 ( 証明書とシークレットにあります)。 |
セルの実行が完了したら、Azure Cosmos DB コンテナーを調べて、データが正常に移行されたことを確認します。