Important
PostgreSQL のAzure Cosmos DBは廃止パスにあり、新しいプロジェクトでは推奨されなくなりました。 代わりに、次の 2 つのサービスのいずれかを使用します。
PostgreSQL ワークロードの場合: Azure Database For PostgreSQL のエラスティック クラスター機能を使用して、オープンソースの Citus 拡張機能に含まれる水平スケールアウトおよび分散 PostgreSQL 機能を使用します。 移行のガイダンスについては、「 Elastic Cluster を使用したAzure Database for PostgreSQLへの移行を参照してください。
NoSQL ワークロードの場合は、99.999% 可用性サービス レベル アグリーメント (SLA)、インスタント 自動スケール、および複数のリージョン間の自動フェールオーバーを含む分散データベース ソリューションに対して Azure Cosmos DB for NoSQL を使用します。
コロケーションとは、同じノード上に関連情報をまとめて格納することを意味します。 ネットワーク トラフィックを使用せずに必要なすべてのデータを入手できる場合に、クエリは高速化できます。 関連データを異なるノードに併置することで、各ノードでクエリを並列に効率的に実行できます。
ハッシュ分散テーブルへのデータ コロケーション
Azure Cosmos DB for PostgreSQL では、ディストリビューション列の値のハッシュが、シャードのハッシュ範囲に収まる場合、行がシャードに格納されます。 同じハッシュ範囲のシャードは常に同じノードに配置されます。 ディストリビューション列の値が同じ行は、テーブル全体で常に同じノードに置かれます。 ハッシュ分散テーブルの概念は、行ベースのシャーディングとも呼ばれます。 スキーマ ベースのシャーディングでは、分散スキーマ内のテーブルは常に併置されます。

コロケーションの実例
マルチテナント Web アナリティクス SaaS に含まれる可能性がある次のテーブルがあるとします。
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
ここで、顧客向けのダッシュボードで発行される可能性があるクエリに応答したいと考えます。 サンプル クエリは、"テナント 6 の '/blog' で始まるすべてのページに対する過去 1 週間の訪問数を返す" です。
データが単一 PostgreSQL サーバーにあった場合は、SQL で提供される豊富なリレーショナル操作セットを使用してクエリを簡単に表現できました。
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
このクエリのワーキング セットがメモリに収まる限り、単一サーバー テーブルは適切なソリューションです。 Azure Cosmos DB for PostgreSQL でデータ モデルをスケーリングする機会について考えてみましょう。
ID によるテーブルの分散
単一サーバーのクエリは、テナント数と各テナントに格納されているデータが増えると同時に、速度低下が始まります。 ワーキング セットがメモリに収まらなくなり、CPU がボトルネックになります。
この場合、Azure Cosmos DB for PostgreSQL を使用して、多数のノード間でデータをシャード化できます。 シャード化することになった場合に行う必要がある最初の最も重要な選択は、ディストリビューション列です。 イベント テーブルに event_id を使用し、page_id テーブルに page を使用した単純な選択から始めましょう。
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
さまざまな worker 間でデータが分散されている場合、単一の PostgreSQL ノードの場合と同様に、結合を実行できません。 代わりに 2 つのクエリを発行する必要があります。
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
その後、2 つの手順の結果をアプリケーションで結合する必要があります。
クエリの実行では、ノード間に分散しているシャード内のデータを参照する必要があります。
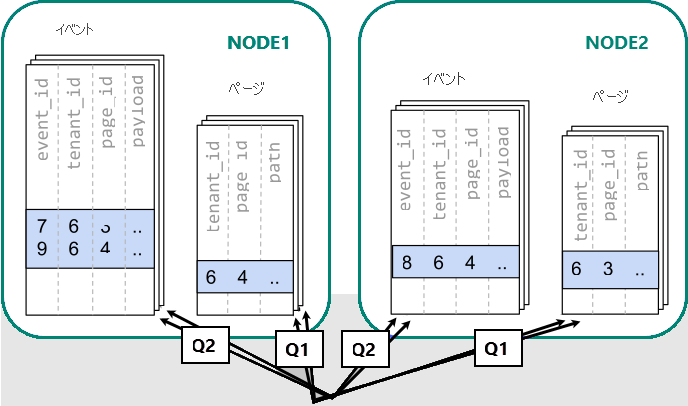
この場合、データの分散によって、大きな欠点が生じます。
- 各シャードに対するクエリと複数のクエリの実行によるオーバーヘッド。
- クライアントに多くの行を返す Q1 のオーバーヘッド。
- Q2 が大きくなる。
- 複数の手順でクエリを記述する必要性によって、アプリケーションの変更が必要である。
データが分散されているため、クエリを並列化できます。 これは、クエリが実行する作業の量が、多くのシャードに照会するオーバーヘッドより大幅に大きい場合にのみ有益です。
テナントによるテーブルの分散
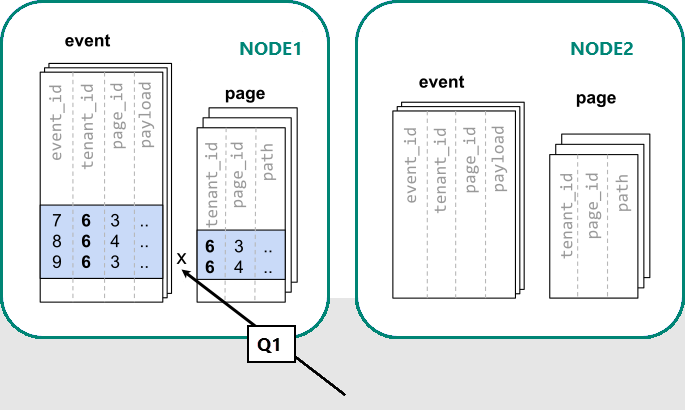
Azure Cosmos DB for PostgreSQL では、同じディストリビューション列の値を持つ行が、同じノード上に置かれることが保証されます。 最初からやり直して、tenant_id をディストリビューション列としてテーブルを作成できます。
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
これで Azure Cosmos DB for PostgreSQL では、元の単一サーバーのクエリに変更なしで答えられるようになりました (Q1)。
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
tenant_id でのフィルターと結合のため、Azure Cosmos DB for PostgreSQL は、その特定のテナントのデータを格納する併置されたシャードのセットを使用して、クエリ全体に応答できることを認識します。 単一の PostgreSQL ノードは、1 手順でクエリに応答できます。
場合によっては、クエリとテーブル スキーマを変更して、一意の制約にテナント ID を含めて、条件を結合する必要があります。 通常これは簡単な変更で済みます。
次のステップ
- マルチテナントのチュートリアルで、テナント データを併置する方法について参照してください。