Important
Azure Cosmos DB for PostgreSQL は、新しいプロジェクトではサポートされなくなりました。 このサービスは、新しいプロジェクトには使用しないでください。 代わりに、次の 2 つのサービスのいずれかを使用します。
Azure Cosmos DB for NoSQL は、99.999% 可用性サービス レベル アグリーメント (SLA)、インスタント 自動スケール、および複数のリージョン間の自動フェールオーバーを使用する 大規模 なシナリオ向けに設計された分散データベース ソリューションに使用します。
オープンソースの Citus 拡張機能を使用して、シャード化された PostgreSQL 用の Azure Database For PostgreSQL のエラスティック クラスター機能 を使用します。
この記事では、Azure Portal を使用して Azure Cosmos DB for PostgreSQL のアラートを設定する方法について説明します。 お使いの Azure のサービスの監視メトリックに基づいて、アラートを受け取ることができます。
指定したメトリックの値がしきい値を超えた場合に、アラートがトリガーされるように設定します。 条件が最初に一致したときにアラートがトリガーされ、その後も引き続きトリガーが行われます。
アラートがトリガーされたときに実行されるように構成できるアクションは次のとおりです。
- サービスの管理者および共同管理者に電子メール通知を送信する。
- 指定した追加の電子メール アドレスに電子メールを送信する。
- Webhook を呼び出す。
アラート ルールを構成したり、その情報を取得したりするには、以下を使用します。
Azure Portal でメトリックのアラート ルールを作成する
Azure Portal で、監視する Azure Cosmos DB for PostgreSQL サーバーを選択します。
サイドバーの [監視] セクションで、[アラート] を選択し、[作成] または [アラート ルールの作成] を選択します。
![[アラート ルールの作成] の選択を示すスクリーンショット。](media/howto-alert-on-metric/2-alert-rules.png)
[シグナルの選択] 画面が開きます。 アラート通知のシグナルの一覧からメトリックを選択します。 この例では、[ストレージの割合] を選択します。
![スクリーンショットは、複数のシグナルを表示できる [シグナル ロジックの構成] ページを示しています。](media/howto-alert-on-metric/6-configure-signal-logic.png)
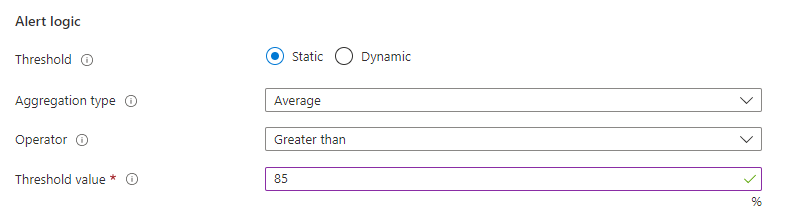
[アラート ルールの作成] ページの [条件] タブの [アラート ロジック] で、次の項目を完了します。
- [しきい値] で、[静的] を選択します。
- [集計の種類] は、[平均] を選択します。
- [演算子] として、[次の値より大きい] を選択します。
- [しきい値] には「85」を入力します。
[アクション] タブを選択し、[アクション グループの作成] を選択して、アラートに関する通知を受信する新しいグループを作成します。
[アクション グループの作成] フォームで、[サブスクリプション]、[リソース グループ]、および [リージョン] を選択し、グループの名前と表示名を入力します。
![[アクション グループの作成] フォームを示すスクリーンショット。](media/howto-alert-on-metric/9-add-action-group.png)
ページの下部にある [次へ: 通知] を選択します。
[通知] タブの [通知の種類] で、[メール/SMS メッセージ/プッシュ/音声] を選択します。
[メール/SMS メッセージ/プッシュ/音声] フォームで、通知の種類と任意の受信者のメール アドレスと電話番号を入力し、[OK] を選択します。
![[アラート ルールの作成] ページを示すスクリーンショット。](media/howto-alert-on-metric/10-action-group-type.png)
[アクション グループの作成] フォームで、新しい通知の名前を入力します。
[確認と作成] を選択し、次に [作成] を選択してアクション グループを作成します。 新しいアクション グループが作成され、[アラート ルールの作成] ページの [アクション] タブの [アクション グループ名] に表示されます。
ページの下部にある [次へ: 詳細] を選択します。
[詳細] タブで、ルールの重大度を選択します。 ルールに簡単に識別できる名前を付け、必要に応じて説明を追加します。
![アラートの [詳細] タブを示すスクリーンショット。](media/howto-alert-on-metric/11-name-description-severity.png)
[確認と作成] を選択し、次に [作成] を選択してアラートを作成します。 数分後にアラートがアクティブになり、前述のようにトリガーされます。
アラートを管理する
アラートを作成したら、それを選択して次のアクションを実行できます。
- このアラートに関連するメトリックのしきい値と、前日の実際の値を示すグラフを表示する。
- アラート ルールを編集または削除する。
- アラートを無効にして通知を一時的に停止するか、有効にして通知の受け取りを再開します。
推奨されるアラート
設定する推奨アラートの例をいくつか次に示します。
ディスク領域
監視とアラートは、すべての運用環境のクラスターにとって重要です。 正常に動作するには、基になる PostgreSQL データベースに空きディスク領域が必要です。 ディスクがいっぱいになると、データベース サーバー ノードはオフラインになり、領域が使用可能になるまで起動できません。 その時点で、この状況を解決するには、Microsoft にサポートを要求する必要があります。
運用環境以外で使用する場合であっても、すべてのクラスターのすべてのノードでディスク領域アラートを設定することをお勧めします。 ディスク領域使用量アラートでは、介入してノードを正常な状態に保つために必要な事前警告が提供されます。 最良の結果を得るには、75%、85%、95% の使用率で一連のアラートを試してみてください。 データ インジェストが速いほどディスクがいっぱいになるのも速いため、選択するパーセンテージは、データ インジェストの速度に依存します。
ディスクが容量制限に近づいたら、次の方法で空き領域を増やしてみます。
- データ保持ポリシーを検討します。 可能であれば、古いデータをコールド ストレージに移動します。
- クラスターにノードを追加し、シャードを再調整することを検討します。 再調整を行うと、より多くのコンピューターにデータが分散されます。
- ワーカー ノードの容量を増やすことを検討します。 各ワーカーに許されるストレージの最大量は 2 TiB です。 ただし、ノードを追加する方が短時間で完了するため、ノードのサイズを変更する前に、ノードを追加する必要があります。
CPU 使用率
CPU 使用率の監視は、パフォーマンスのベースラインを確立するのに役立ちます。 たとえば、CPU 使用率が通常は約 40 - 60% であるとします。 CPU 使用率が急に 95% 程度まで上昇し始めたら、異常があることがわかります。 CPU 使用率は、有機的成長を反映する場合もありますが、不適切なクエリを示していることもあります。 CPU アラートを作成するときは、長期間の増加が検出されて、瞬間的な急増が無視されるように、集計単位を長く設定します。
次のステップ
- アラートでの webhook の構成に関する詳細情報を確認します。
- メトリック収集の概要 情報を入手して、サービスの可用性と応答性を確認します。