Important
Azure Cosmos DB for PostgreSQL は、新しいプロジェクトではサポートされなくなりました。 このサービスは、新しいプロジェクトには使用しないでください。 代わりに、次の 2 つのサービスのいずれかを使用します。
Azure Cosmos DB for NoSQL は、99.999% 可用性サービス レベル アグリーメント (SLA)、インスタント 自動スケール、および複数のリージョン間の自動フェールオーバーを使用する 大規模 なシナリオ向けに設計された分散データベース ソリューションに使用します。
オープンソースの Citus 拡張機能を使用して、シャード化された PostgreSQL 用の Azure Database For PostgreSQL のエラスティック クラスター機能 を使用します。
シャード キーとしてのテナント ID
テナント ID は、ワークロードのルート、またはデータ モデルの階層の最上位にある列です。 たとえば、この SaaS e コマース スキーマでは、ストア ID になります。
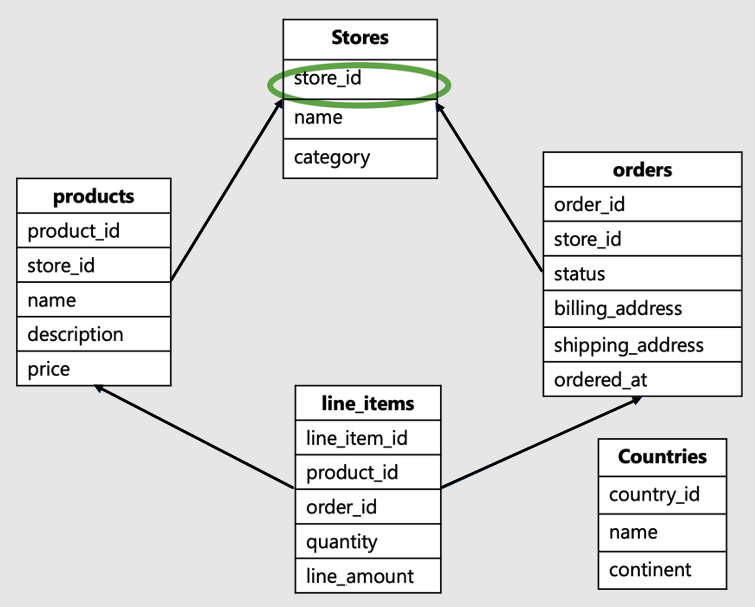
このデータ モデルは、Shopify などのビジネスでは一般的です。 複数のオンライン ストアのサイトをホストし、各ストアが独自のデータを操作します。
- このデータ モデルには、Stores、products、orders、line_items、Countries など、多数のテーブルがあります。
- Stores テーブルは階層の最上位にあります。 products、orders、line_items はすべて Stores に関連付けられているため、階層内で下位になります。
- Countries テーブルは個々のストアに関連せず、複数のストアに共通です。
この例では、階層の最上位にある store_id がテナントの識別子です。 これが適切なシャード キーです。
store_id をシャード キーとして選択すると、1 つのストアのすべてのテーブルにまたがるデータを 1 つのワーカーで収集できます。
ストア別にテーブルを併置することには、次のような利点があります。
- 外部キー、JOIN などの SQL カバレッジを提供します。 1 つのテナントのトランザクションは、各テナントが存在する 1 つのワーカー ノードに局所化されます。
- 1 桁ミリ秒のパフォーマンスを実現します。 1 つのテナントに対するクエリは、並列化されず 1 つのノードにルーティングされるため、ネットワーク ホップを最適化しつつ、コンピューティングやメモリをスケーリングできます。
- スケーリングします。 テナント数が増加したら、ノードを追加したり、新しいノードにテナントをリバランスしたり、大規模テナントを独自のノードに分離したりできます。 テナントの分離により、専用リソースを提供できます。
マルチテナント アプリに最適なデータ モデル
この例では、ストア固有のテーブルをストア ID によって分散し、countries を参照テーブルにする必要があります。
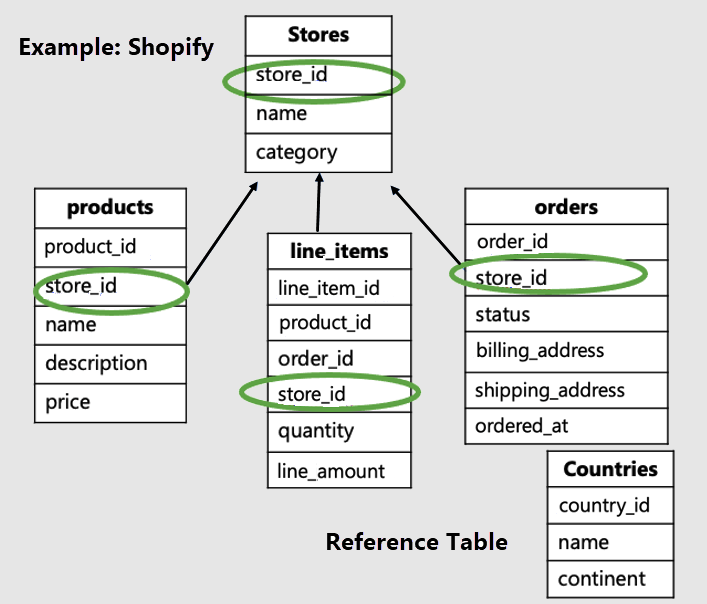
テナント固有のテーブルにはテナント ID があり、分散されていることに注意してください。 この例では、Stores、products、line_items が分散されます。 残りのテーブルは参照テーブルです。 この例では、Countries テーブルは参照テーブルです。
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
すべての大きなテーブルにはテナント ID が必要です。
- 既存のマルチテナント アプリを Azure Cosmos DB for PostgreSQL に移行する場合は、少し非正規化し、大きなテーブルにテナント ID 列がない場合は追加し、列の欠損値をバックフィルする必要があります。
- Azure Cosmos DB for PostgreSQL 上の新しいアプリの場合は、すべてのテナント固有テーブルにテナント ID が存在することを確認します。
分散テーブルに対する主キー、一意キー、外部キーの各制約に、複合キーの形式でテナント ID を必ず含めてください。 たとえば、テーブルに id の主キーがある場合は、それを複合キー (tenant_id,id) に変えます。
参照テーブルのキーを変更する必要はありません。
パフォーマンス最適化のためのクエリの考慮事項
テナント ID でフィルター処理する分散クエリは、マルチテナント アプリで最も効率的に実行されます。 クエリのスコープが常に 1 つのテナントであることを確認します。
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
元のフィルター条件で目的の行が明確に識別されている場合でも、テナント ID フィルターを追加する必要があります。 テナント ID フィルターは、一見冗長ですが、クエリを 1 つのワーカー ノードにルーティングする方法を Azure Cosmos DB for PostgreSQL に指示します。
同様に、2 つの分散テーブルを結合するときは、両方のテーブルのスコープが 1 つのテナントであることを確認します。 スコープ設定を行うには、結合条件にテナント ID が含まれることを確認します。
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
いくつかの一般的なアプリケーション フレームワーク用のヘルパー ライブラリがあり、これらを利用すると、クエリにテナント ID を簡単に含めることができます。 手順は以下のとおりです。
次のステップ
これで、スケーラブルなアプリのデータ モデリングの調査が完了しました。 次の手順では、選択したプログラミング言語を使用してデータベースに接続してクエリを実行します。