Important
Azure Cosmos DB for PostgreSQL は、新しいプロジェクトではサポートされなくなりました。 このサービスは、新しいプロジェクトには使用しないでください。 代わりに、次の 2 つのサービスのいずれかを使用します。
Azure Cosmos DB for NoSQL は、99.999% 可用性サービス レベル アグリーメント (SLA)、インスタント 自動スケール、および複数のリージョン間の自動フェールオーバーを使用する 大規模 なシナリオ向けに設計された分散データベース ソリューションに使用します。
オープンソースの Citus 拡張機能を使用して、シャード化された PostgreSQL 用の Azure Database For PostgreSQL のエラスティック クラスター機能 を使用します。
シャード キーを使用して大きなテーブルを併置する
リアルタイム運用分析アプリケーションのシャード キーを選択するには、次のガイドラインに従います。
- 大きなテーブルに共通する列を選択します。
- データにおける自然なディメンション、またはアプリケーションの中心的な部分である列を選択します。 以下に、いくつかの例を示します。
- 金融業界では、セキュリティの傾向を分析するアプリケーションの多くで
security_idを使用します。 - Web サイトの使用状況メトリックを分析するユーザー分析ワークロードでは、
user_idが適切な分散列です。
- 金融業界では、セキュリティの傾向を分析するアプリケーションの多くで
大きなテーブルを併置することにより、SQL クエリをワーカー ノードに並列でプッシュダウンできます。 クエリのプッシュダウンにより、ネットワーク上のノード間でデータがシャッフルされるのを回避できます。 JOIN、集計、ロールアップ、フィルター、LIMIT などの操作を効率的に実行できます。
併置されたテーブルに対する並列分散クエリを視覚化するために、次の図を考えてみてください。
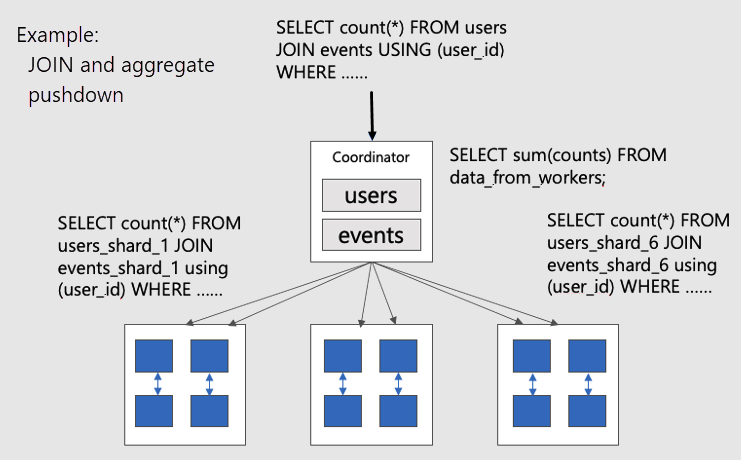
users および events テーブルはどちらも user_id によってシャード化されるため、同じユーザー ID に関連している行は、同じワーカー ノードにまとめて配置されます。 ワーカー間で情報をプルすることなく SQL JOIN を実行できます。
リアルタイム アプリに最適なデータ モデル
続けて、ユーザー Web サイトのアクセスとメトリックを分析するアプリケーションの例を見てみましょう。 2 つの "ファクト" テーブル (users と events) があり、より小さな "ディメンション" テーブルが別にあります。
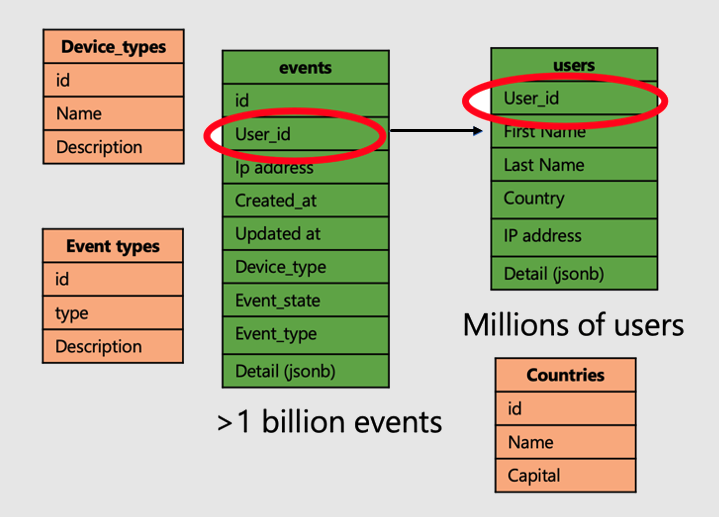
Azure Cosmos DB for PostgreSQL で分散テーブルの効果を高めるには、次の手順に従います。
- 共通の列で大きなファクト テーブルを分散します。 今回の例では、users と events を
user_idで分散します。 - 小さいディメンション テーブル (
device_types、countries、event_types) を参照テーブルとしてマークします。 - 分散テーブルに対する主キー、一意キー、外部キーの各制約に分散列を必ず含めます。 列を含めるために、キーを複合化することが必要な場合があります。 参照テーブルのキーを更新する必要があります。
- 大きな分散テーブルを結合するときは、必ずシャード キーを使用して結合します。
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
次のステップ
これで、スケーラブルなアプリのデータ モデリングの調査が完了しました。 次の手順では、選択したプログラミング言語を使用してデータベースに接続してクエリを実行します。