適用対象:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() カサンドラ
カサンドラ
![]() グレムリン
グレムリン
![]() 表
表
大規模に相互接続された社会で生きていると、日々の生活の中で ソーシャル ネットワークに参加することになります。 ソーシャル ネットワークを使用して、友人や同僚、家族と交流し、共通の関心を持つ人々と情熱を分かち合うこともあります。
エンジニアや開発者なら、これらのネットワークでデータがどのように格納されて相互接続されるのか気になることでしょう。 または、特定のニッチ市場向けに新しいソーシャル ネットワークを作成または設計したことさえあるかもしれません。 そこで、"このすべてのデータはどのように保存されているのか" という大きな疑問が生じます。
写真、動画、音楽などの関連メディアと共に記事を投稿できる新しいソーシャル ネットワークを作成しているところを想像してください。 ユーザーは投稿にコメントしたり、投稿を評価したりできます。 メインの Web サイト ランディング ページに表示されてユーザーが操作できる投稿のフィードもあります。 これは最初は複雑ではないように思われますが、簡潔にするために、ここまでにしておきましょう。 (関係性の影響を受けるカスタム ユーザー フィードを深く掘り下げて考えることもできますが、それはこの記事の目的ではありません。)
では、このデータはどこにどのように保存すればよいのでしょうか。
SQL データベースの経験や、データのリレーショナル モデリングの知識を持っている人もいるかもしれません。 最初の図はたとえば次のようなものになります。
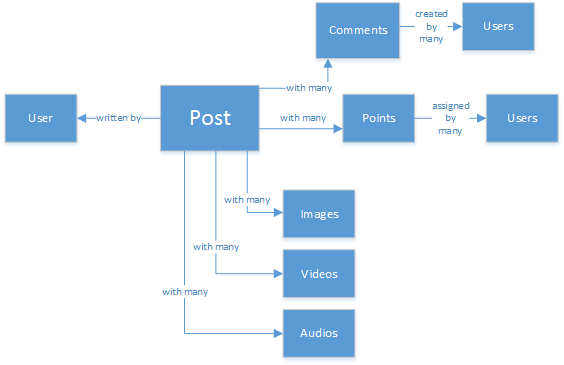
完全に正規化された見事なデータ構造ですが、拡張性がありません。
誤解しないでください。私は SQL データベースを長年使用してきました。 それは優れてはいますが、他のあらゆるパターン、手法、ソフトウェア プラットフォームと同様に、すべてのシナリオに最適というわけではありません。
このシナリオで SQL が最適な選択肢でないのはなぜでしょうか。 1 つの投稿の構造を見てみましょう。 Web サイトやアプリケーションでその投稿を表示する場合、たった 1 つの投稿を表示するために、8 つのテーブルを結合してクエリを実行しなければなりません。 動的に読み込まれ、画面に表示される投稿のストリームを想像してみてください。そうすれば、私が目指しているものがおわかりいただけると思います。
コンテンツを提供するために、こうした多数の結合を使用する何千ものクエリを解決できるだけの能力を備えた巨大な SQL インスタンスを使用することもできます。 しかし、よりシンプルなソリューションが存在するとしたら、そのようなことをする必要があるでしょうか。
NoSQL への道
この記事では、Azure の NoSQL データベースである Azure Cosmos DB を使って、コスト効果の高い方法でソーシャル プラットフォームのデータをモデル化する方法を説明します。 また、Gremlin 用 API などの Azure Cosmos DB の他の機能を使う方法もお話しします。 NoSQL のアプローチの採用、JSON 形式でのデータの保存、非正規化の適用により、これまで複雑であった投稿を次のような 1 つのドキュメントに変換できます。
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
また、投稿を 1 つのクエリで結合なしに取得できます。 このクエリははるかにシンプルでわかりやすい方法です。予算的にも、必要なリソースを減らして大きな成果を上げることができます。
Azure Cosmos DB では、自動的なインデックス付けによって、すべてのプロパティにインデックスが付けられます。 自動的なインデックス付けは、カスタマイズすることさえできます。 このスキーマフリーのアプローチにより、さまざまな動的構造でドキュメントを保存できます。 将来的には、カテゴリのリストやハッシュタグを投稿に関連付けたいのではないですか。 Azure Cosmos DB は、追加された属性を持つ新しいドキュメントを処理します。追加の作業は必要ありません。
投稿へのコメントは、親プロパティを使用して他の投稿と同様に処理できます。 (この方法により、オブジェクト マッピングが簡素化されます。)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
また、すべてのソーシャル インタラクションをカウンターとして別のオブジェクトに保存できます。
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
フィードの作成は、特定の関連度順で投稿 ID のリストを保持できるドキュメントを作成するだけのことです。
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
作成日順に並べ替えられた投稿を含む "最新の" ストリームを作成できます。 または、過去 24 時間により多くの "いいね" を獲得した投稿を含む "最もホットな" ストリームを作成することもできます。 フォロワーや関心事などのロジックに基づいて、ユーザーごとにカスタム ストリームを実装することさえできます。 それもやはり投稿のリストです。 これは、これらのリストの構築方法の問題ですが、読み取りパフォーマンスは引き続き制約を受けていません。 これらのリストのいずれかを取得したら、IN キーワードを使用して Azure Cosmos DB に対して 1 つのクエリを発行し、投稿のページを一度に取得します。
フィードのストリームは、Azure App Service のバックグラウンド プロセス (Webjobs) を使用して構築できました。 投稿が作成されたら、Azure StorageQueues を使用してバックグラウンド処理をトリガーし、Azure Webjobs SDK を使用して Webjobs をトリガーすることで、独自のカスタム ロジックに基づいてストリーム内での投稿の伝達を実装できます。
この同じ手法を使用して最終的に一貫した環境を構築することで、投稿に対する評価と「いいね」を遅延的に処理できます。
フォロワーの処理はさらに複雑です。 Azure Cosmos DB にはドキュメント サイズの制限があり、サイズの大きいドキュメントの読み取りと書き込みは、アプリケーションのスケーラビリティに影響を与えます。 よって次のような構造のドキュメントとしてフォロワーを保存する方法が考えられます。
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
この構造は、フォロワーが数千人のユーザーであれば問題なく機能するかもしれません。 ただし、一部の著名人がランクに参加すると、このアプローチによってドキュメント サイズが大きくなり、最終的にドキュメント サイズの上限に達する可能性があります。
この問題を解決するには、混成方式を使います。 ユーザー統計情報ドキュメントの一部として、次のようにフォロワーの数を保存します。
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
フォロワーの実際のグラフを Azure Cosmos DB の Gremlin 用 API を使用して保存し、各ユーザーの頂点と、"A が B をフォローする" という関係性を維持するエッジを作成できます。 Gremlin 用 API では、特定のユーザーのフォロワーを取得し、ユーザーの共通点を示唆するより複雑なクエリを作成できます。 ユーザーのお気に入りや楽しんでいるコンテンツ カテゴリをグラフに追加すれば、フォローしている人のお気に入りコンテンツを勧めたり、共通点の多いユーザーを見つけたりといった、高度なコンテンツ検出機能を備えたエクスペリエンスの創造に取り掛かることができます。
ユーザー統計情報ドキュメントを使用して、UI またはクイック プロファイル プレビューのカードを作成することもできます。
"ラダー (梯子)" パターンとデータの重複
投稿を参照する JSON ドキュメントでお気付きかと思いますが、同じユーザーが何度も出現します。 推測どおり、これらの重複は、この非正規化の場合、ユーザーを説明する情報が複数の場所に存在する可能性があることを意味します。
クエリの高速化を可能するために、データの重複が発生しています。 この副作用による問題は、何らかの操作によってユーザーのデータが変更された場合に、そのユーザーがこれまでに実行したすべてのアクティビティを見つけ、そのすべてを更新する必要があることです。 現実的ではなさそうですよね。
私たちは、アクティビティごとにアプリケーションで表示するユーザーのキー属性を識別することでこの問題を解決しようとしています。 アプリケーションで投稿を視覚的に示し、作成者の名前と写真だけを表示する場合、ユーザーのすべてのデータを "createdBy" 属性に保存するのはなぜでしょうか。 各コメントにユーザーの写真を表示するだけなら、そのユーザーのその他の情報は実際には不要です。 ここで、私が "ラダー パターン" と呼ぶものが関係するようになります。
例として、ユーザー情報を取得してみましょう。
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
この情報を調べることで、重要な情報とそうでない情報をすぐに見つけることができるため、次のように "ラダー" を作成できます。

最小の段はユーザーチャンクと呼ばれます。これは、ユーザーを識別する情報の最小単位であり、データの重複に対して使用されます。 重複するデータのサイズを "表示する" 情報だけに減らすことで、大規模な更新の可能性を低減しています。
真ん中の段は "ユーザー" と呼ばれます。 これは、Azure Cosmos DB のパフォーマンスに依存するほとんどのクエリで使用される完全なデータであり、最もアクセスが多く、重要です。 ここには、ユーザーチャンクで表される情報が含まれます。
最大の段が "拡張ユーザー" です。 それには、重要なユーザー情報と、実際には迅速に読み取る必要のないデータやサインイン プロセスのような最終的に使用するデータが含まれます。 このデータは、Azure Cosmos DB の外部、Azure SQL Database、または Azure Storage Tables に保存できます。
ユーザーを分割し、この情報をさまざまな場所に保存するのはなぜでしょうか。 それは、パフォーマンスの観点から言えば、ドキュメントのサイズが大きくなるほど、クエリのコストが高くなるからです。 ソーシャル ネットワークでパフォーマンスに依存するすべてのクエリを実行するための適切な情報で、ドキュメントをスリムに保ちます。 その他の情報は、完全なプロファイル編集、ログイン、利用状況分析のためのデータ マイニング、ビッグ データへの取り組みなどの最終的なシナリオ用に保存します。 データ マイニングのためのデータ収集は、Azure SQL Database で実行されるので、実際には収集に時間がかかってもかまいません。 私たちが気に掛けているのは、ユーザーに高速で軽快なエクスペリエンスを提供することです。 Azure Cosmos DB に保存されるユーザーは、次のコードのようになります。
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
さらに、投稿は次のようになります。
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
チャンクの属性が影響を受ける編集が発生しても、影響を受けたドキュメントを簡単に見つけることができます。
SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id" のような、インデックス付き属性を参照するクエリを使用し、チャンクを更新するだけです。
検索ボックス
ユーザーは、幸いにも多くのコンテンツを生成します。 コンテンツのストリームに直接存在しない可能性のあるコンテンツを検索して見つける機能を提供できる必要があります。作成者をフォローするのではなく、6 か月前に行われた古い投稿を見つけようとしているだけだからです。
Azure Cosmos DB を使用しているので、Azure AI Search を使用して、検索プロセスと UI 以外のコードを入力せずに、検索エンジンを数分で簡単に実装できます。
このプロセスがとても簡単な理由
Azure AI Search は、いわゆるインデクサーを実装しています。インデクサーは、データ リポジトリにフックを設定し、インデックス内のオブジェクトを自動的に追加、更新、または削除するバックグラウンド プロセスです。 Azure SQL Database インデクサー、Azure BLOB インデクサー、Azure Cosmos DB インデクサーがサポートされています。 Azure Cosmos DB から Azure AI Search への情報の移行は簡単です。 どちらのテクノロジも JSON 形式で情報を保存するので、必要なのは、インデックスを作成し、インデックス付けするドキュメントから属性をマップすることだけです。 これで終了です。 データのサイズに応じて、クラウド インフラストラクチャで最適なサービスとしての検索ソリューションによって、すべてのコンテンツを数分以内に検索できます。
Azure AI Search の詳細については、「 A Hitchhikers Guide to Search (検索のためのヒッチハイカー ガイド)」をご覧ください。
基礎となる知識
日々増加し続けるすべてのコンテンツを保存した後に、"ユーザーからのこのすべての情報ストリームを使って何ができるのか" を考えていることに気付くかもしれません。
答えは簡単です。情報ストリームを活用し、情報ストリームから学ぶのです。
しかし、何を学ぶことができるのでしょうか。 簡単な例としては、センチメント分析、ユーザーの好みに基づくコンテンツのレコメンデーション、ソーシャル ネットワークで公開されるすべてのコンテンツが家族向けの安全なものであることを保証する自動コンテンツ モデレーターなどがあります。
人を夢中にさせるような話なので、シンプルなデータベースやファイルからこれらのパターンや情報を抽出するには、数理科学の博士号が必要と思っておられるでしょう。しかし、それは違います。
Azure Machine Learning は、フル マネージド クラウド サービスです。このサービスを利用することで、シンプルなドラッグ アンド ドロップ インターフェイスでのアルゴリズムを使用したワークフローの作成や、R での独自のアルゴリズムのコーディング、構築済みのすぐに使える API (Text Analytics、Content Moderator、Recommendations など) の使用が可能になります。
これらの Machine Learning シナリオを実現するには、Azure Data Lake を使用してさまざまなソースから情報を取り込むことができます。 U-SQL を使用して情報を処理し、Azure Machine Learning で処理できる出力を生成することもできます。
利用できる別のオプションとして、Azure AI サービスを使用したユーザーのコンテンツの分析があります。ユーザーが何を書いているかを Text Analytics API で分析してコンテンツを深く理解できるだけではなく、望ましくないコンテンツや成人向けのコンテンツを Computer Vision API で検出し、それに応じて対処することもできます。 Azure AI サービスには、使用するために機械学習の知識を必要としない、すぐに利用できるソリューションが多く含まれています。
世界規模のソーシャル エクスペリエンス
私が対処しなければならない最後の重要な記事があります: スケーラビリティ。 アーキテクチャを設計するときは、各コンポーネントが自動的に拡張できるようにする必要があります。 最終的には、より多くのデータを処理する必要があります。または、より大きな地理的範囲を持つ必要があります。 Azure Cosmos DB を使用すると、両方のタスクをターンキー エクスペリエンスとして実現できます。
Azure Cosmos DB では、動的なパーティション分割をすぐに使用できます。 ドキュメントの属性として定義されている特定のパーティション キーに基づいて、パーティションが自動的に作成されます。 正しいパーティション キーの定義は、設計時に行う必要があります。 詳細については、Azure Cosmos DB でのパーティション分割に関するページを参照してください。
ソーシャル エクスペリエンスでは、パーティション分割戦略をクエリおよび書き込みの方法と整合させる必要があります。 (たとえば、同じパーティション内の読み取りが望ましい、書き込みを複数のパーティションに分散させることによって "ホット スポット" を回避する、など。)たとえば、一時的なキー (日/月/週)、コンテンツのカテゴリ、地理的リージョン、ユーザーに基づいてパーティション分割できます。 データのクエリを実行し、ソーシャル エクスペリエンスでデータを表示する方法に大きく依存します。
Azure Cosmos DB では、すべてのパーティションでクエリ ( 集計を含む) が透過的に実行されるため、データの増加に合わせてロジックを追加する必要はありません。
トラフィックやリソースの消費量 (RU (要求ユニット) で測定) は、時間の経過と共に増加します。 ユーザー ベースの拡大に合わせて、読み取りと書き込みが頻繁に行われます。 ユーザー ベースは、より多くのコンテンツの作成と読み取りを開始します。 そのため、スループットを拡張する機能が重要です。 RU は簡単に増やすことができます。 これを行うには、Azure portal でいくつかの選択を行うか、 API を使用してコマンドを発行します。
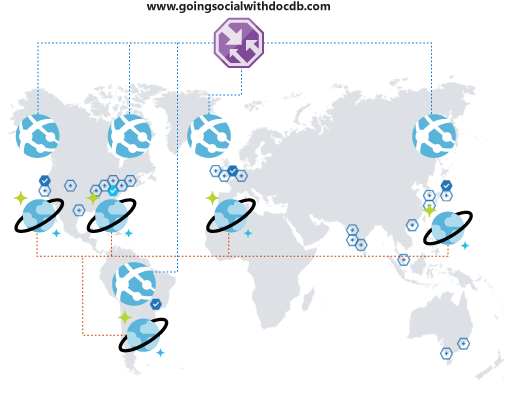
状況が好転し続けるとどうなるでしょう。 自分のプラットフォームが、国およびリージョン、または大陸のユーザーのに認識されて、使われるようになることを想像してください。 嬉しい驚きですね。
でもちょっと待ってください。 やがて、そのプラットフォームでの体験が最適ではないことに気付きます。 運用リージョンから離れているので、待ち時間は相当なものになります。 当然ですが、その人たちにやめてほしくはありません。 グローバル展開を広げる簡単な手段があればいいと思うでしょう。 あるのです。
Azure Cosmos DB を使用すると、2 つの選択を使用 してデータをグローバル かつ透過的にレプリケートし、 クライアント コードから使用可能なリージョンの中から自動的に選択できます。 また、このプロセスは複数のフェールオーバー リージョンを確保できることも意味します。
データをグローバルにレプリケートするときは、クライアントがそのデータを利用できるかどうかを確認する必要があります。 Web フロントエンドを使用する場合、またはモバイル クライアントから API にアクセスする場合は、Azure Traffic Manager をデプロイし、必要なリージョンすべてに Azure App Service の複製を作成します。その際に、拡張されたグローバル カバレッジをサポートするためのパフォーマンス構成を使用します。 クライアントがフロントエンドまたは API にアクセスすると、最も近い App Service にルーティングされます。これにより、ローカルの Azure Cosmos DB レプリカに接続されます。
まとめ
この記事では、低コストのサービスを使用して Azure で完全なソーシャル ネットワークを作成する代替手段を明らかにしています。 「ラダー」と呼ばれる多層ストレージ ソリューションとデータ分散の使用を促進することで、結果を提供します。
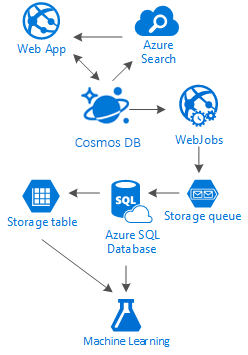
実際には、この種のシナリオに対応する特効薬はありません。 優れたソーシャル アプリケーションを提供する Azure Cosmos DB の速度と自由度、Azure AI Search のような最高クラスの検索ソリューションの背後にあるインテリジェンス、言語に依存しないアプリケーションではなく、強力なバックグラウンド プロセスをホストする Azure App Services の柔軟性、大量のデータを保存する拡張可能な Azure Storage と Azure SQL Database、プロセスにフィードバックを提供することができ、適切なコンテンツを適切なユーザーに提供するうえで役立つ知識とインテリジェンスを生み出す Azure Machine Learning の分析力など、優れたサービスの組み合わせによって生まれる相乗効果により、優れた体験を構築することが可能になります。
次のステップ
Azure Cosmos DB のユース ケースの詳細については、Azure Cosmos DB の一般的なユース ケースに関するページをご覧ください。