Azure Data Factory (ADF) は、データに対してアクティビティの組み合わせを実行するために使用できるクラウドベースのデータ統合サービスです。 ADF を使用して、データ移動とデータ変換を調整し、自動化するためのデータ駆動型ワークフローを作成します。 Azure Data Factory の Azure Data Explorer コマンド アクティビティを使用すると、ADF ワークフロー内で Azure Data Explorer 管理コマンド を実行できます。 この記事では、Azure Data Explorer コマンド アクティビティを含むルックアップ アクティビティと ForEach アクティビティを含むパイプラインを作成する方法について説明します。
前提条件
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- データのソース。
- データ ファクトリ。 データ ファクトリを作成します。
新しいパイプラインを作成する
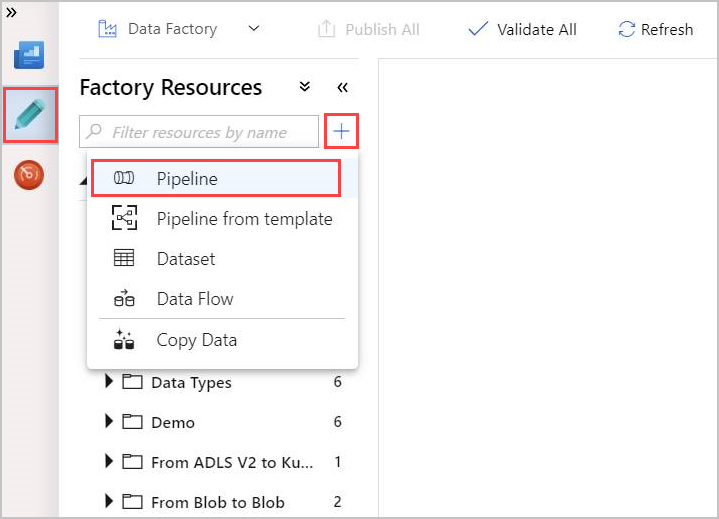
作成者の鉛筆ツールを選択します。
+を選択して新しいパイプラインを作成し、ドロップダウンから [パイプライン] を選択します。
ルックアップ アクティビティを作成する
ルックアップ アクティビティは、Azure Data Factory でサポートされている任意のデータ ソースからデータセットを取得できます。 ForEach またはその他のアクティビティの Lookup アクティビティからの出力を使用できます。
[アクティビティ]ウィンドウの [全般] で、[ルックアップ] アクティビティを選択します。 右のメイン キャンバスにドラッグ アンド ドロップします。
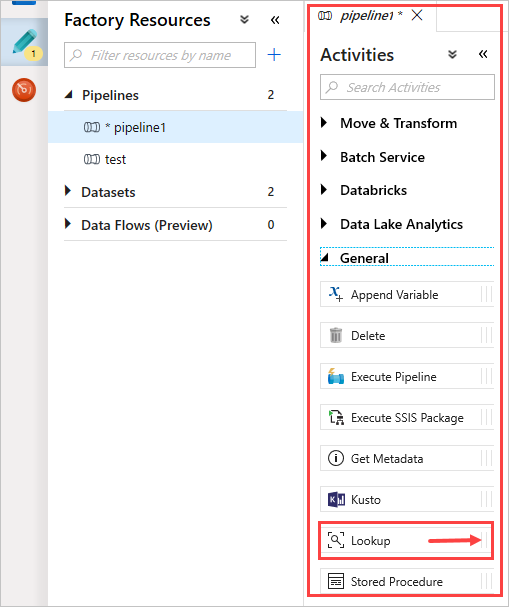
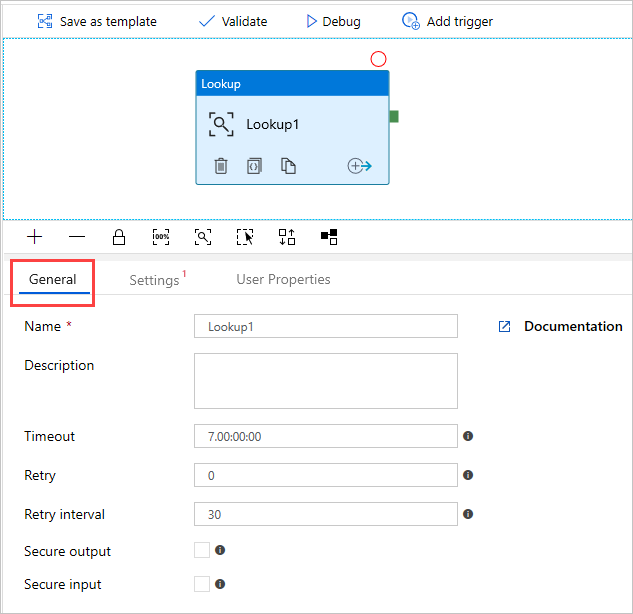
これで、キャンバスには作成したルックアップ アクティビティが含まれます。 キャンバスの下のタブを使用して、関連するパラメーターを変更します。 [全般] で、アクティビティの名前を変更します。
ヒント
空のキャンバス領域を選択して、パイプラインのプロパティを表示します。 パイプラインの名前を変更するには、[全般] タブを使用します。 パイプラインの名前は pipeline-4-docs です。
ルックアップ アクティビティで Azure Data Explorer データセットを作成する
[設定]で、事前に作成した Azure Data Explorer のソース データセットを選択するか、[ + 新規] を選択して新しいデータセットを作成します。
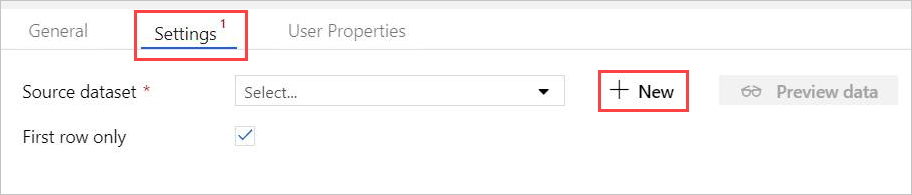
[新しいデータセット] ウィンドウから Azure Data Explorer (Kusto) データセットを選択します。 [続行] を選択して新しいデータセットを追加します。
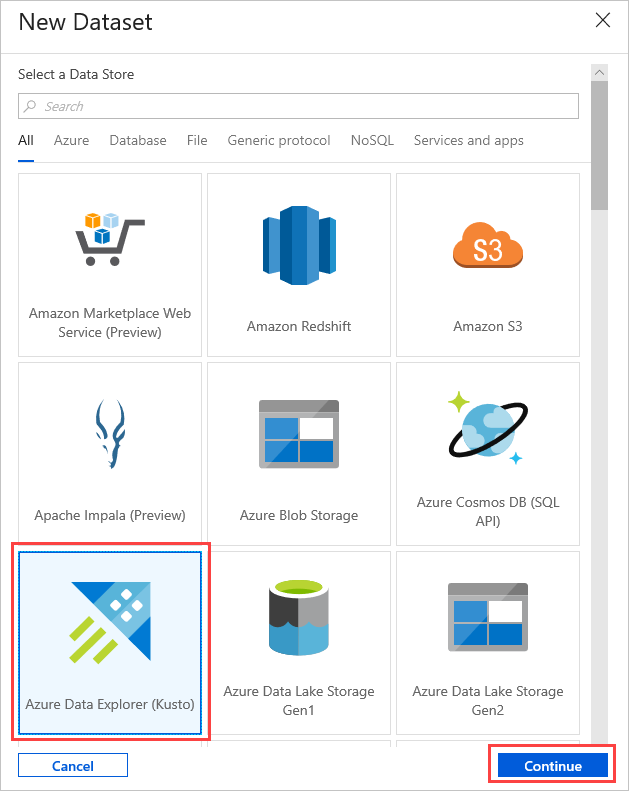
新しい Azure Data Explorer データセット パラメーターは、[設定] で表示できます。 パラメーターを更新するには、[編集] を選択します。
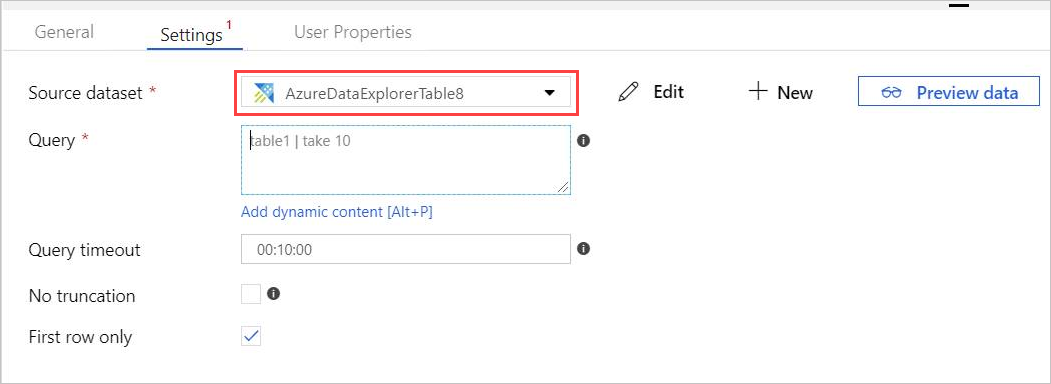
メインキャンバスで AzureDataExplorerTable のタブが新しく開きます。
- [全般] を選択し、データセット名を編集します。
- データセットのプロパティを編集するには、[接続] を選択します。
- ドロップダウンから [リンクされたサービス ] を選択するか、[ + 新規 ] を選択して新しいリンクされたサービスを作成します。
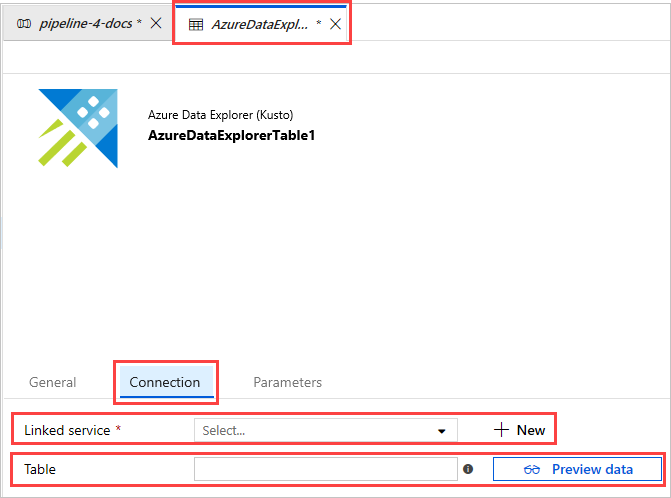
新しいリンクされたサービスを作成する場合、[New Linked Service (Azure Data Explorer)]\(新しいリンクされたサービス (Azure Data Explorer)\) ページが開きます。
- Azure Data Explorer のリンクされたサービスの [名前] を選択します。 必要に応じて [説明] を追加します。
- 必要に応じて、[Connect via integration runtime]\(統合ランタイム経由で接続\) で現在の設定を変更します。
-
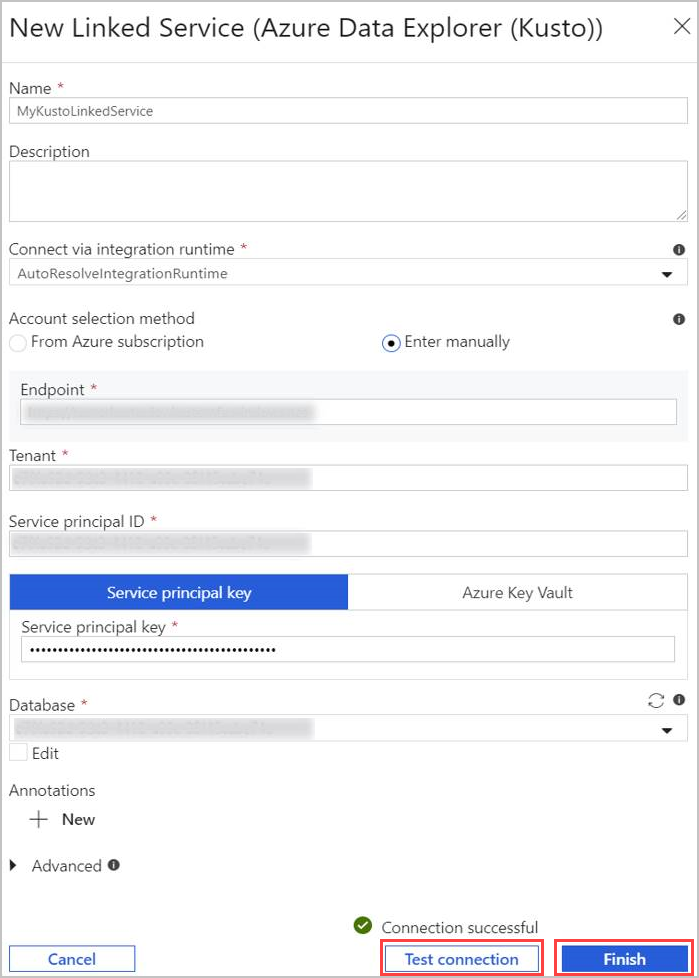
Account の選択方法で次の 2 つの方法のいずれかを使用してクラスターを選択します。
- [From Azure subscription]\(Azure サブスクリプションから\) ラジオ ボタンを選択し、[Azure サブスクリプション] アカウントを選択します。 次に、自分の [クラスター] を選択します。 ドロップダウンには、自分に属するクラスターのみが一覧表示されます。
- または、[手動で入力] ラジオ ボタンを選択し、自分の [エンドポイント] (クラスタの URL) を入力します。
- [テナント] を指定します。
- [サービス プリンシパル ID] を入力します。 この値は 、Azure portal の [アプリの登録>Overview>Application (クライアント) ID] で見つけます。 プリンシパルには、使用するコマンドに必要なアクセス許可レベルに従って、適切なアクセス許可が必要です。
- [サービス プリンシパル キー] ボタンを選択し、[サービス プリンシパル キー] を入力します。
- ドロップダウン メニューから [データベース] を選択します。 または、[編集] チェックボックスをオンにし、データベース名を入力します。
- [Test Connection]\(接続のテスト\) を選択して、作成したリンクされたサービスの接続をテストします。 セットアップに接続できる場合は、緑色のチェックマーク が 表示されます。
- [完了] を選択して、リンクされたサービスの作成を完了します。
リンクされたサービスを設定した後、 AzureDataExplorerTable>Connection で テーブル 名を追加します。 [データのプレビュー] を選択して、データが正しく表示されていることを確認します。
データセットの準備が整い、パイプラインの編集を続けることができます。
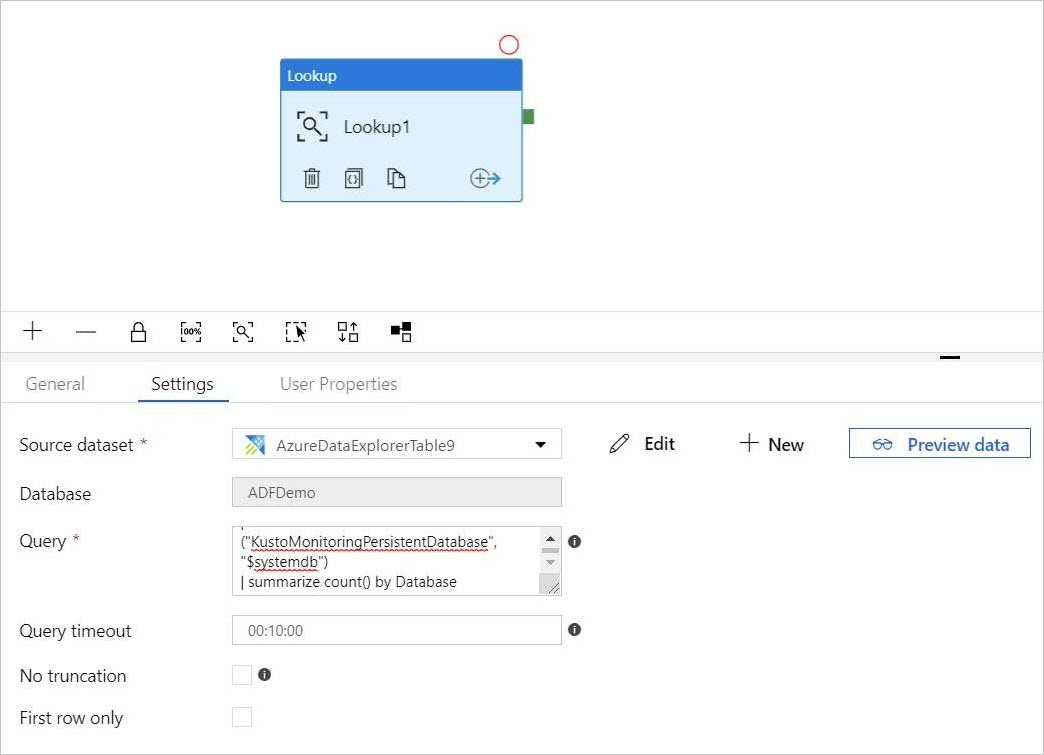
ルックアップ アクティビティにクエリを追加する
pipeline-4-docs>Settings で、[クエリ] テキスト ボックスにクエリを追加します。次に例を示します。
ClusterQueries | where Database !in ("KustoMonitoringPersistentDatabase", "$systemdb") | summarize count() by Database必要に応じて、クエリ タイムアウト または [No truncation]\(切り捨てしない) および [First row only]\(先頭行のみ\) プロパティを変更します。 このフローでは、既定の クエリ タイムアウト を維持し、チェック ボックスをオフにします。
For-Each アクティビティを作成する
For-Each アクティビティを使用してコレクションを反復処理し、指定されたアクティビティをループで実行します。
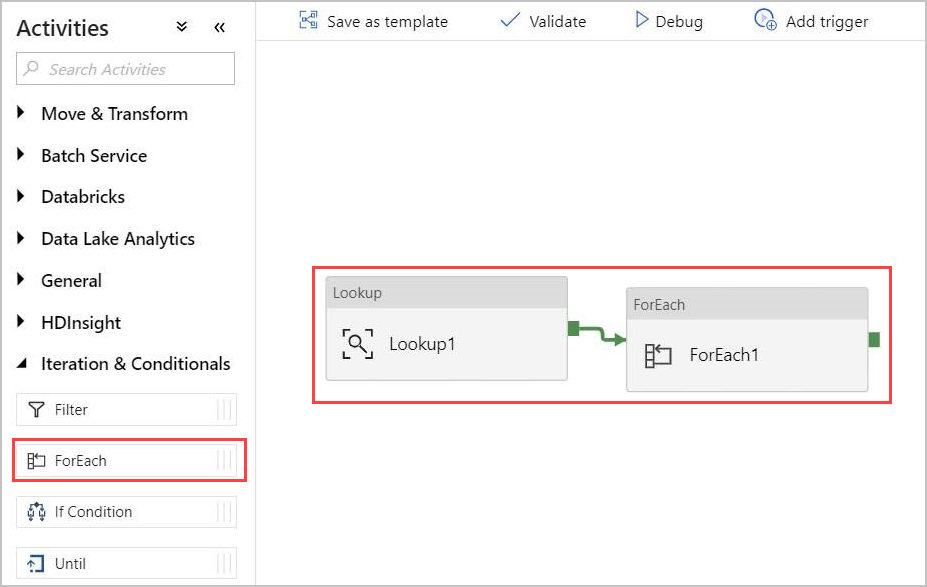
パイプラインに For-Each アクティビティを追加します。 このアクティビティは、ルックアップ アクティビティから返されたデータを処理します。
[ アクティビティ ] ウィンドウの [ イテレーションと条件] で、 ForEach アクティビティを選択します。 キャンバスにドラッグ アンド ドロップします。
ルックアップ アクティビティの出力と、キャンバス内の ForEach アクティビティの入力を線で繋いで接続します。
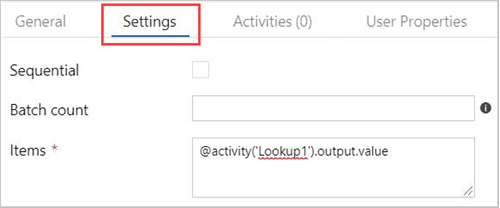
キャンバスで [ForEach] アクティビティを選択します。 [設定] タブで、次のようにします。
[シーケンシャル] チェックボックスをオンにしてルックアップ結果のシーケンシャル処理を行うか、オフのままにして並列処理を作成する。
バッチ カウント を設定する
[項目] で、出力値 @activity('Lookup1').output.value への参照を指定する
ForEach アクティビティ内に Azure Data Explorer コマンド アクティビティを作成する
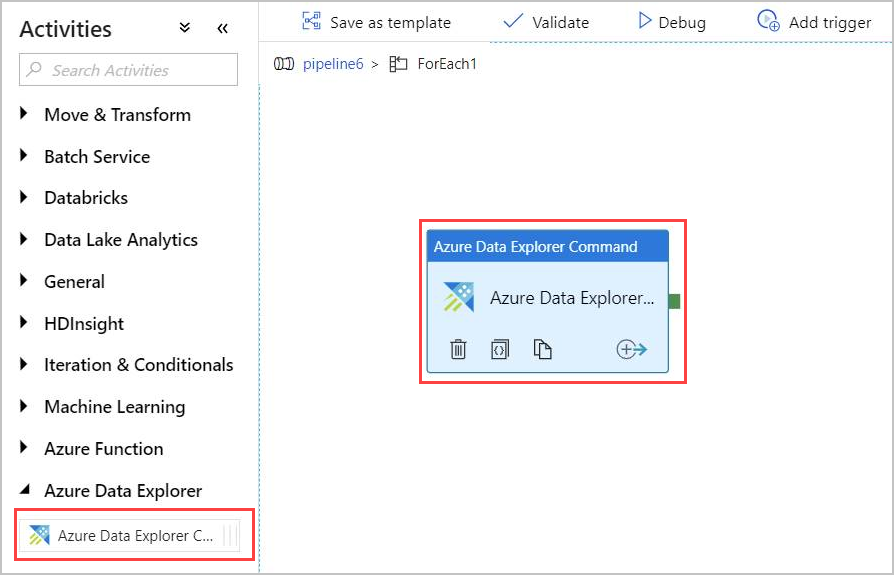
キャンバスで ForEach アクティビティをダブルクリックして、新しいキャンバスで開きます。 ForEach 内のアクティビティを指定します。
[アクティビティ] ウィンドウの [Azure Data Explorer] で [Azure Data Explorer コマンド] アクティビティを選択し、キャンバスにドラッグ アンド ドロップします。
[ 接続 ] タブで、前に作成したのと同じリンクされたサービスを選択します。
![Azure Data Explorer の [コマンド アクティビティの接続] タブ。](media/data-factory-command-activity/adx-command-activity-connection-tab.png)
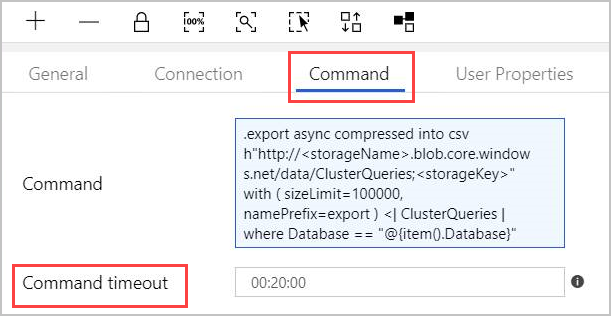
[コマンド] タブで、次のコマンドを指定します。
.export async compressed into csv h"http://<storageName>.blob.core.windows.net/data/ClusterQueries;<storageKey>" with ( sizeLimit=100000, namePrefix=export ) <| ClusterQueries | where Database == "@{item().Database}"[コマンド] は、指定されたクエリの結果を圧縮形式で BLOB ストレージにエクスポートするよう Azure Data Explorer に指示します。 これは、非同期で実行されます (非同期修飾子を使用)。 このクエリは、ルックアップ アクティビティの結果の各行のデータベース列に対応します。 コマンド タイムアウトは変更せずに残すことができます。
注
コマンド アクティビティには次の制限があります。
- サイズ制限: 1 MB の応答サイズ
- 制限時間: 20 分 (既定)、1 時間 (最大)。
- 必要に応じて、 AdminThenQuery を使用してクエリを結果に追加して、結果のサイズまたは時間を短縮できます。
これでパイプラインの準備ができました。 パイプライン名を選択すると、メイン パイプライン ビューに戻ることができます。

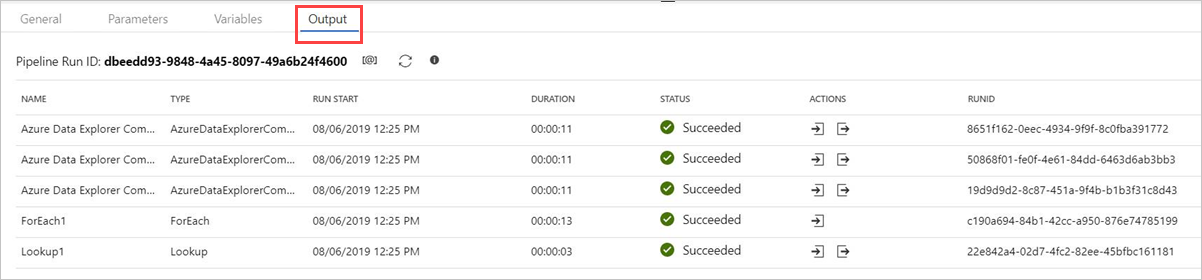
パイプラインを公開する前に、[デバッグ] を選択します。 パイプラインの進行状況は、[ 出力 ] タブで監視できます。
[ すべて発行] を選択し、[ トリガーの追加] を選択してパイプラインを実行します。
管理コマンドの出力
次のセクションでは、コマンド アクティビティの出力の構造について説明します。 パイプラインの次のアクティビティでは、この出力を使用できます。
非同期以外の管理コマンドの戻り値
非同期以外の管理コマンドでは、返される値の構造はルックアップ アクティビティの結果の構造に似ています。
countフィールドには、返されたレコードの数が表示されます。 固定配列フィールド value にはレコードの一覧が含まれています。
{
"count": "2",
"value": [
{
"ExtentId": "1b9977fe-e6cf-4cda-84f3-4a7c61f28ecd",
"ExtentSize": 1214.0,
"CompressedSize": 520.0
},
{
"ExtentId": "b897f5a3-62b0-441d-95ca-bf7a88952974",
"ExtentSize": 1114.0,
"CompressedSize": 504.0
}
]
}
非同期管理コマンドの戻り値
非同期管理コマンドでは、非同期操作が完了するかタイムアウトになるまで、アクティビティはバックグラウンドで操作テーブルをポーリングします。したがって、返される値には、指定された .show operations OperationId プロパティのの結果が含まれます。 操作が正常に完了したことを確認するには、State および Status の各プロパティの値を確認します。
{
"count": "1",
"value": [
{
"OperationId": "910deeae-dd79-44a4-a3a2-087a90d4bb42",
"Operation": "TableSetOrAppend",
"NodeId": "",
"StartedOn": "2019-06-23T10:12:44.0371419Z",
"LastUpdatedOn": "2019-06-23T10:12:46.7871468Z",
"Duration": "00:00:02.7500049",
"State": "Completed",
"Status": "",
"RootActivityId": "f7c5aaaf-197b-4593-8ba0-e864c94c3c6f",
"ShouldRetry": false,
"Database": "MyDatabase",
"Principal": "<some principal id>",
"User": "<some User id>"
}
]
}