Azure Data Explorer は、高速でフル マネージドのデータ分析サービスです。 アプリケーション、Web サイト、IoT デバイスなど、多くのソースからストリーミングされる大量のデータをリアルタイムで分析できます。
Oracle Server、Netezza、Teradata、または SQL Server のデータベースから Azure Data Explorer にデータをコピーするには、複数のテーブルから大量のデータを読み込む必要があります。 通常は、複数のスレッドを並列して使用して単一のテーブルから行が読み込まれるように、各テーブルでデータをパーティション化する必要があります。 この記事では、これらのシナリオで使用するテンプレートについて説明します。
Azure Data Factory テンプレートは、 定義済みの Data Factory パイプラインです。 これらのテンプレートは、Data Factory の使用をすぐに開始し、データ統合プロジェクトの開発時間を短縮するのに役立ちます。
Lookup アクティビティと ForEach アクティビティを使用して、データベースから Azure Data Explorer への一括コピー テンプレートを作成します。 データのコピーを高速化するために、テンプレートを使用して、データベースまたはテーブルごとに多数のパイプラインを作成できます。
重要
コピーするデータの量に適したツールを使用してください。
- データベースから Azure Data Explorer への一括コピー テンプレートを使用して、SQL Server や Google BigQuery などのデータベースから Azure Data Explorer に大量のデータをコピーします。
- Data Factory データのコピー ツールを使用して、少量または中程度の量のデータを含むいくつかのテーブルを Azure Data Explorer にコピーします。
[前提条件]
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- データ ファクトリ。 データ ファクトリを作成します。
- データのソース。
ControlTableDataset の作成
ControlTableDataset は、パイプライン内のソースからコピー先にコピーされるデータを示します。 行数は、データのコピーに必要なパイプラインの合計数を示します。 ソース データベースの一部として ControlTableDataset を定義する必要があります。
SQL Server のソース テーブル形式の例を次のコードに示します。
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
コード要素については、次の表で説明します。
| プロパティ | 説明 | 例 |
|---|---|---|
| PartitionId | コピー順序 | 1 |
| SourceQuery | パイプラインの実行時にコピーされるデータを示すクエリ | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''>
|
| ADXTableName | 宛先テーブル名 | MyAdxTable |
ControlTableDataset の形式が異なる場合は、その形式に対応する ControlTableDataset を作成します。
データベースから Azure Data Explorer への一括コピー テンプレートを使用する
[ はじめに ] ウィンドウで、[ テンプレートからパイプラインを作成 ] を選択して、[ テンプレート ギャラリー ] ウィンドウを開きます。
![Azure Data Factory の [始めましょう] ウィンドウ](media/data-factory-template/adf-get-started.png)
[データベースから Azure Data Explorer への一括コピー] テンプレートを選択します。
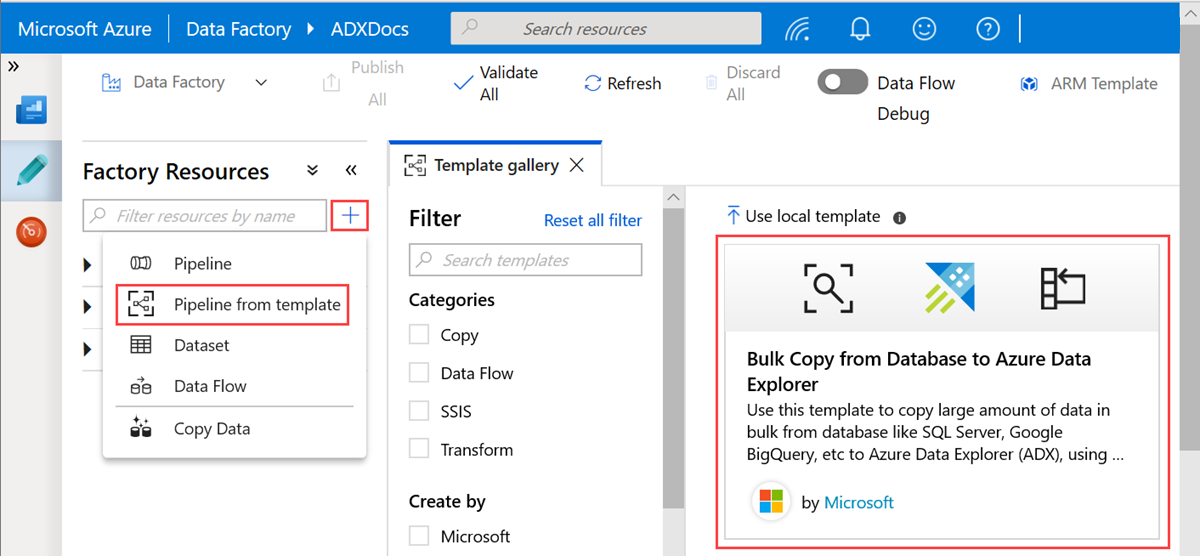
[ データベースから Azure Data Explorer への一括コピー ] ウィンドウの [ ユーザー入力] で、次の手順に従ってデータセットを指定します。
ある。 ControlTableDataset ドロップダウン リストで、ソースからコピー先にコピーされるデータと、コピー先の場所を示す、コントロール テーブルへのリンクされたサービスを選択します。
b。 SourceDataset ドロップダウン リストで、ソース データベースへのリンクされたサービスを選択します。
c. AzureDataExplorerTable ドロップダウン リストで、Azure Data Explorer テーブルを選択します。 データセットが存在しない場合は、 Azure Data Explorer のリンクされたサービスを作成 してデータセットを追加します。
d. このテンプレートを使用する を選択します。
![[データベースから Azure Data Explorer への一括コピー] ウィンドウ](media/data-factory-template/configure-bulk-copy-adx-template.png)
アクティビティの外部にあるキャンバス内の領域を選択して、テンプレート パイプラインにアクセスします。 [ パラメーター ] タブを選択して、名前 (コントロール テーブル 名 ) や 既定値 (列名) など、テーブルのパラメーターを入力します。
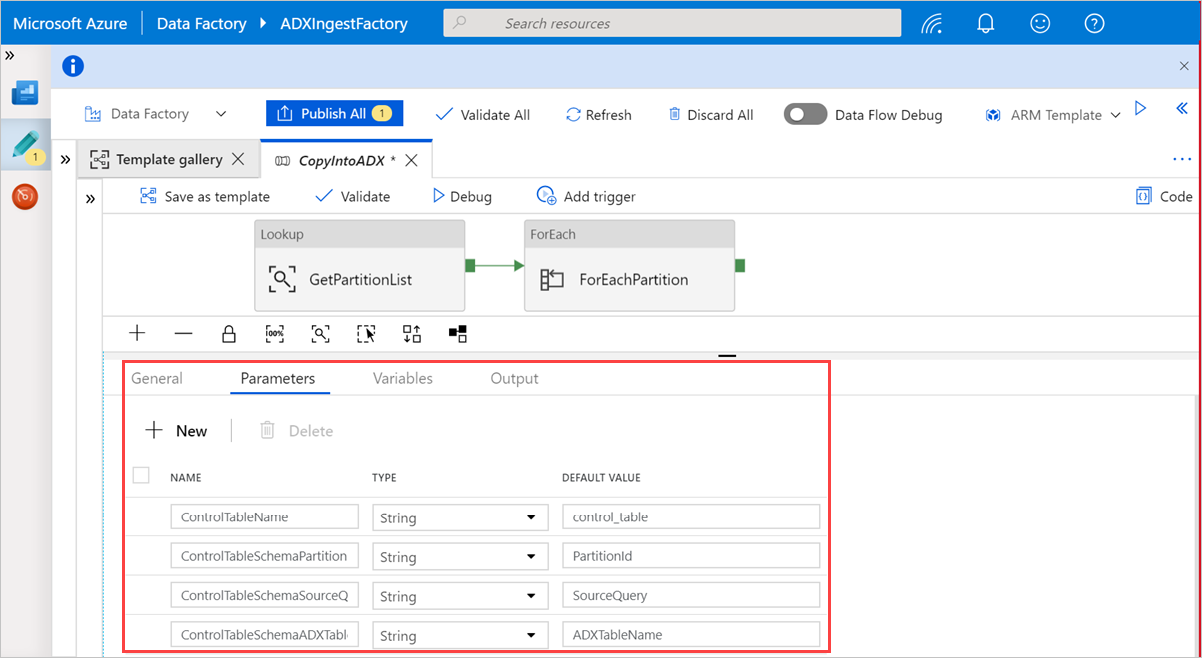
[ 参照] で [GetPartitionList ] を選択し、既定の設定を表示します。 クエリが自動的に作成されます。
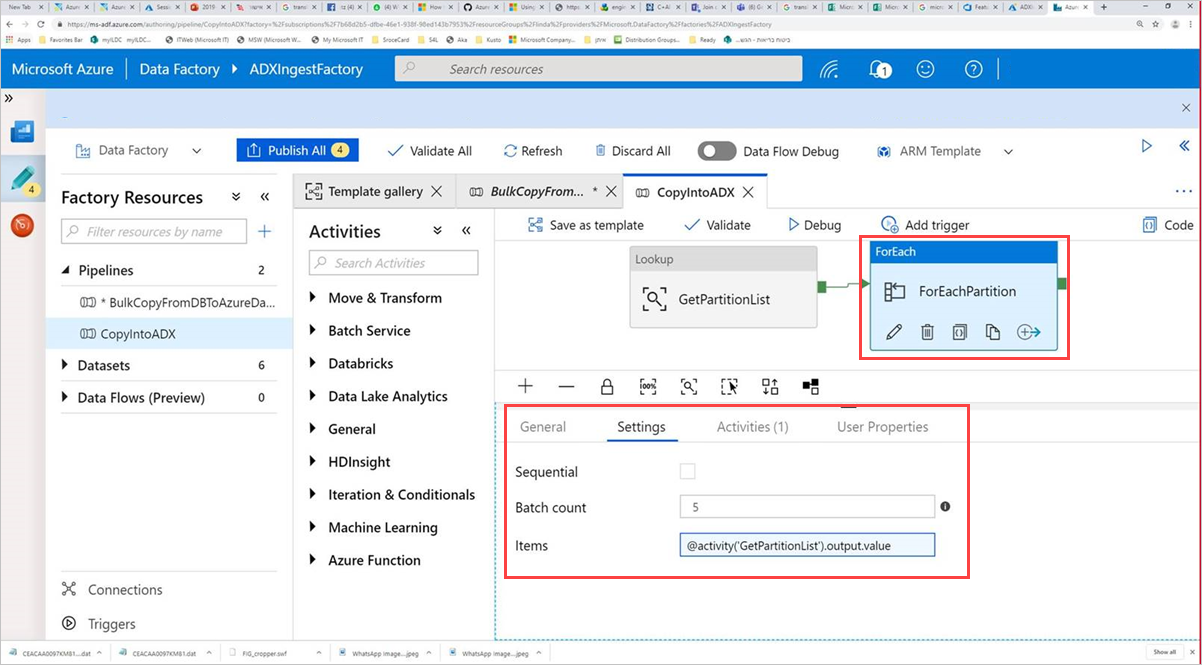
コマンド アクティビティ ForEachPartition を選択し、[ 設定] タブを選択し、次の操作を行います。
ある。 [ バッチカウント ] ボックスに、1 ~ 50 の数値を入力します。 この選択により、 ControlTableDataset 行の数に達するまで並列で実行されるパイプラインの数が決まります。
b。 パイプライン バッチが並列で実行されるようにするには、[シーケンシャル] チェック ボックスをオンにしないでください。
ヒント
ベスト プラクティスは、データをより迅速にコピーできるように、多数のパイプラインを並列で実行することです。 効率を高めるために、ソース テーブル内のデータをパーティション分割し、日付とテーブルに従ってパイプラインごとに 1 つのパーティションを割り当てます。
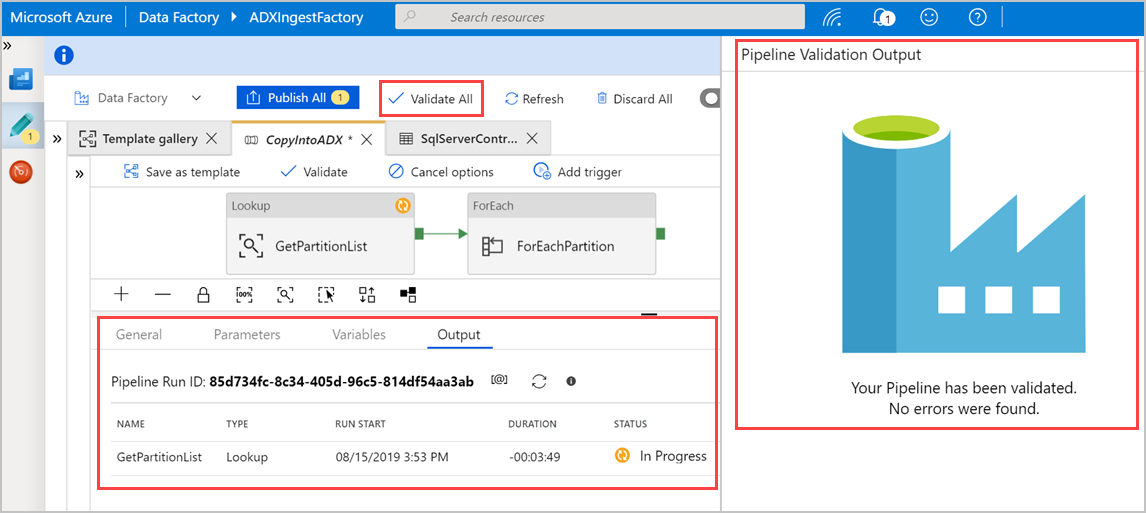
[ すべて検証 ] を選択して Azure Data Factory パイプラインを検証し、[ パイプラインの検証出力 ] ウィンドウに結果を表示します。
必要に応じて、[ デバッグ] を選択し、[ トリガーの追加] を選択してパイプラインを実行します。
![[デバッグ] ボタンと [パイプラインの実行] ボタン](media/data-factory-template/trigger-run-of-pipeline.png)
これで、テンプレートを使用して、データベースとテーブルから大量のデータを効率的にコピーできるようになりました。
関連コンテンツ
- Azure Data Factory 用 Azure Data Explorer コネクタについて説明します。
- Data Factory UI でリンクされたサービス、データセット、パイプラインを編集します。
- Azure Data Explorer Web UI でデータのクエリを実行します。