Azure DevOps Services は、高性能パイプライン、無料のプライベート Git リポジトリ、構成可能なかんばんボード、広範囲で自動化された継続的テスト機能など、開発向け共同作業ツールを提供します。 Azure Pipelines は Azure DevOps の機能であり、あらゆる言語、プラットフォーム、クラウドと連動する高性能パイプラインでコードをデプロイするよう、CI/CD を管理できます。 Azure Data Explorer - Pipeline Tools は Azure Pipelines のタスクであり、リリース パイプラインを作成し、データベースの変更を Azure Data Explorer データベースにデプロイできます。 Visual Studio Marketplace で無料で利用できます。 拡張機能には、次の基本的なタスクが含まれています。
Azure Data Explorer コマンド - Azure Data Explorer クラスターに対して管理者コマンドを実行する
Azure Data Explorer クエリ - Azure Data Explorer クラスターに対してクエリを実行し、結果を解析する
Azure Data Explorer クエリ サーバー ゲート - クエリ結果に応じてリリースをゲートするエージェントレス タスク
このドキュメントでは、 Azure Data Explorer - Pipeline Tools タスクを使用してスキーマの変更をデータベースにデプロイする簡単な例について説明します。 完全な CI/CD パイプラインについては、Azure DevOps ドキュメントを参照してください。
前提条件
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- Azure Data Explorer クラスター セットアップ:
- Microsoft Entra アプリケーションをプロビジョニングすることで、Microsoft Entra アプリを作成します。
- Azure Data Explorer データベースのアクセス許可を管理することで、Azure Data Explorer データベース上の Microsoft Entra アプリへのアクセスを許可します。
- Azure DevOps セットアップ:
- 拡張機能のインストール
Azure DevOps インスタンスの所有者である場合は、Marketplace から拡張機能をインストールします。それ以外の場合は、Azure DevOps インスタンスの所有者に問い合わせてインストールを依頼してください。

リリース用にコンテンツを準備する
次の方法を使用して、タスク内のクラスターに対して管理者コマンドを実行できます。
検索パターンを使用して、ローカル エージェント フォルダー (ビルド ソースまたはリリース 成果物) から複数のコマンド ファイルを取得します。 単一行オプションは、ファイルごとに 1 つのコマンドを使用して複数のファイルをサポートします。

コマンドをインラインで記述します。
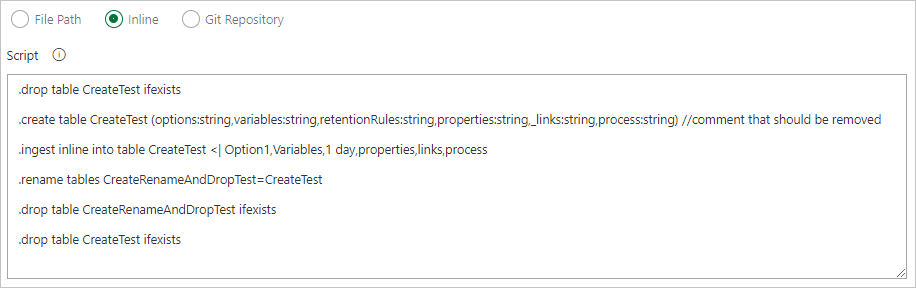
Git ソース管理から直接コマンド ファイルを取得するファイル パスを指定します (推奨)。
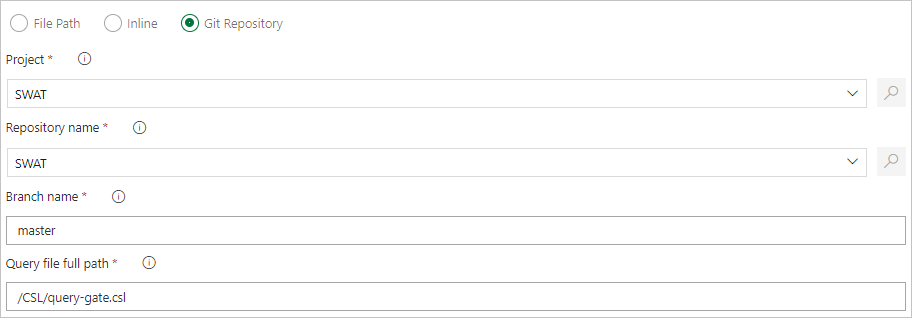
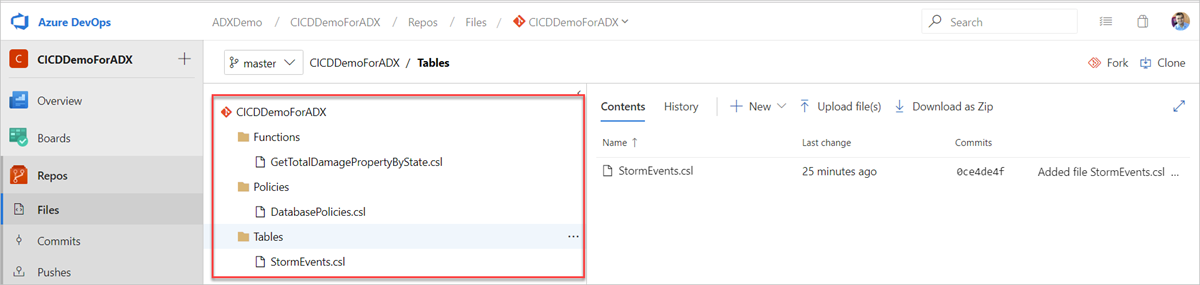
Git リポジトリでサンプル フォルダー (Functions、Policies、Tables) を作成します。 サンプル リポジトリから各フォルダーにファイルをコピーし、変更をコミットします。 次のワークフローを実行するためのサンプル ファイルが提供されます。
ヒント
自分のワークフローを作成するときには、コードがべき等性を持つようにすることをお勧めします。 たとえば、
.create-merge tableではなく.create tableを使用し、.create-or-alter関数の代わりに.create関数を使用します。
リリース パイプラインの作成
Azure DevOps 組織にサインインします。
左側のメニューから [ Pipelines>Releases ] を選択し、[ 新しいパイプライン] を選択します。
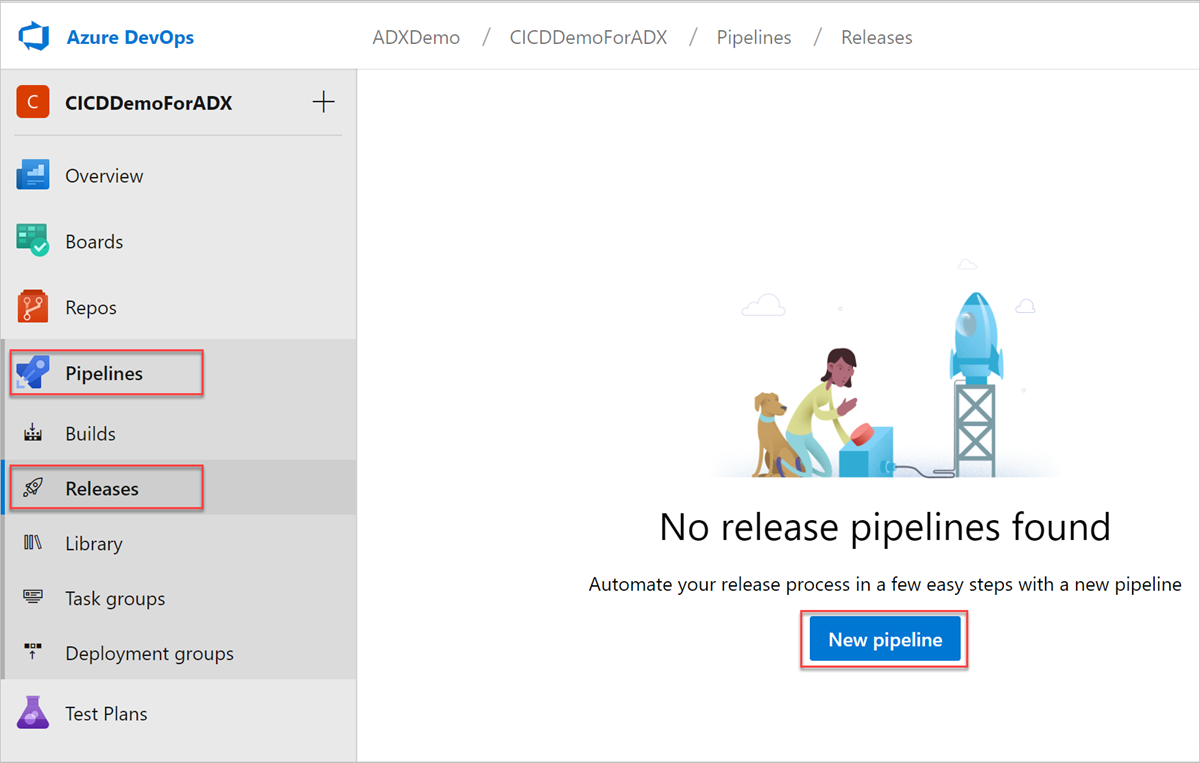
[新しいリリース パイプライン] ウィンドウが開きます。 [パイプライン] タブの [テンプレートの選択] ウィンドウで [空のジョブ] を選択します。
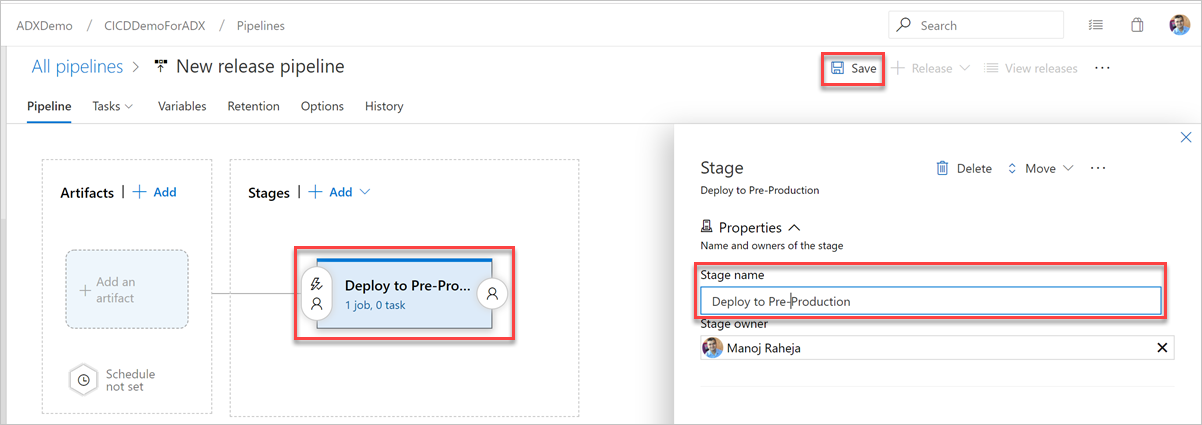
[ステージ] ボタンを選択します。 [ステージ] ウィンドウで、ステージ名を追加し、[保存] を選択してパイプラインを保存します。
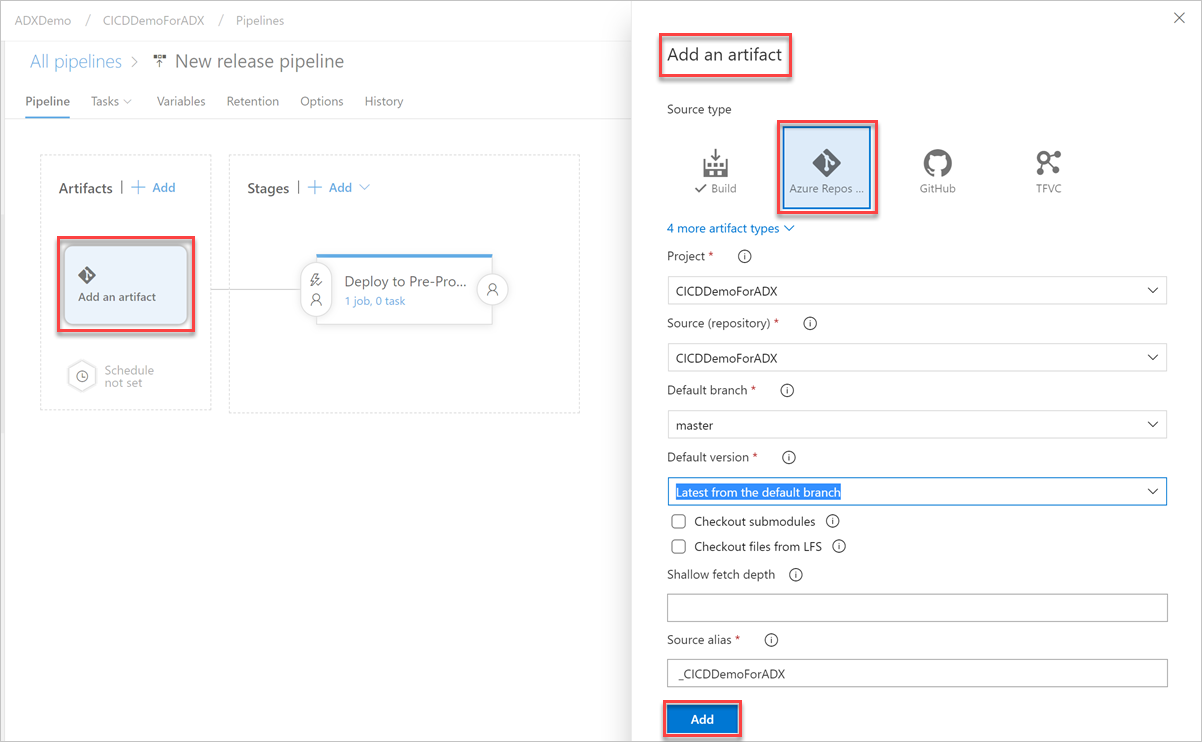
[成果物の追加] ボタンを選択します。 [成果物の追加] ペイン内で、コードが存在するリポジトリを選択し、関連情報を入力して、[追加] を選択します。 保存を選択して、パイプラインを保存します。
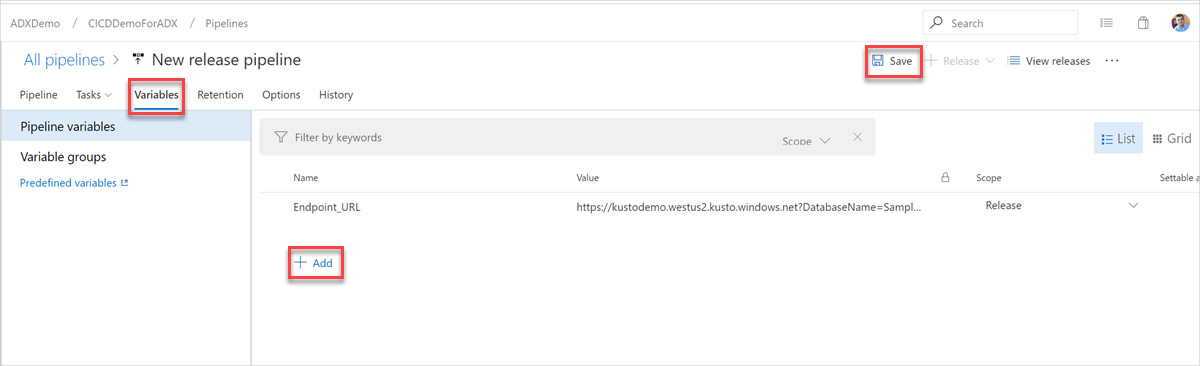
[ 変数 ] タブで、[ + 追加 ] を選択して、タスクで使用される エンドポイント URL の変数を作成します。 エンドポイントの 名前 と 値 を入力し、[ 保存] を選択してパイプラインを保存します。
エンドポイント URL を見つけるには、Azure portal 内で Azure Data Explorer クラスターの [概要] ページに移動し、クラスター URI をコピーします。 変数 URI は
https://<ClusterURI>?DatabaseName=<DBName>の形式で作成します。 たとえば、https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB のように指定します。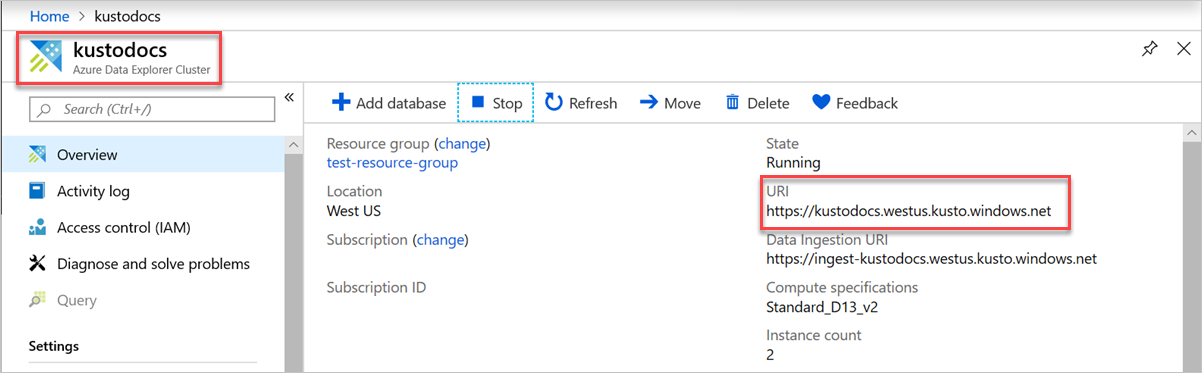
フォルダーを展開するタスクを作成する
[ パイプライン ] タブで、タスクを追加する 1 つのジョブ、0 個のタスク を選択します。
次の手順を繰り返して、テーブル、関数、およびポリシーの各フォルダーからファイルをデプロイするコマンド タスクを作成します。
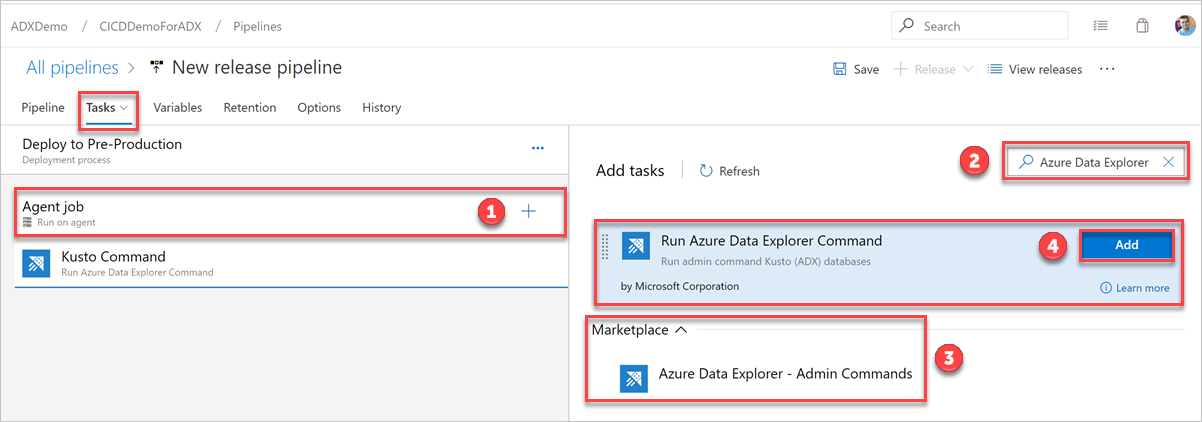
[タスク] タブで、の によって を選択し、 Azure Data Explorer を検索します。[Run Azure Data Explorer Command]\(Azure Data Explorer コマンドの実行\) の [追加] を選択します。
[Kusto Command]\(Kusto コマンド\) を選択し、次の情報でタスクを更新します。
表示名: タスクの名前。 たとえば、
Deploy <FOLDER>の<FOLDER>は、作成している展開タスクのフォルダー名です。ファイル パス: 各フォルダーのパスを
*/<FOLDER>/*.cslとして指定します。ここで、<FOLDER>はタスクの関連するフォルダーです。エンドポイント URL: 前の手順で作成した
EndPoint URL変数を指定します。Use Service Endpoint (サービス エンドポイントを使用する): このオプションを選択します。
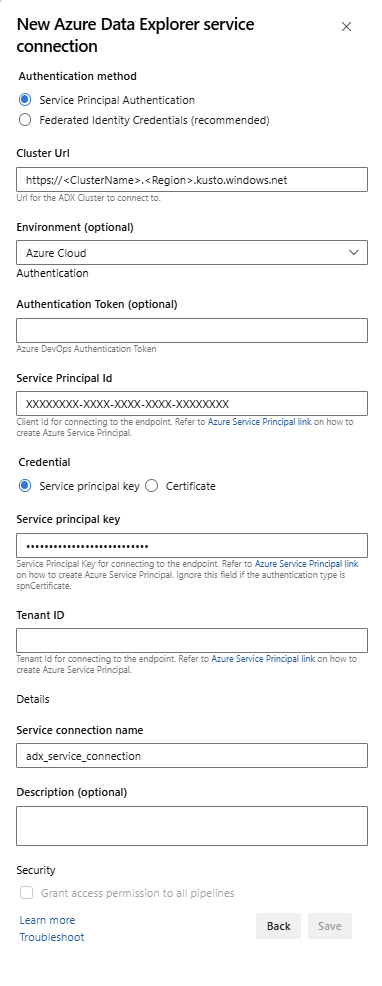
Service Endpoint (サービス エンドポイント): 既存のサービスエンドポイントを選択するか、新しいものを作成し ([+ 新規])、[Add Azure Data Explorer service connection]\(Azure Data Explorer サービス接続の追加\) ウィンドウに次の情報を入力します。
設定 提案された値 認証方法 フェデレーション ID 資格情報 (FIC) を設定する (推奨)、またはサービス プリンシパル認証 (SPA) を選択します。 接続名 このサービス エンドポイントを識別する名前を入力します クラスター URL 値は、Azure portal の Azure Data Explorer クラスターの概要セクションにあります サービス プリンシパル ID Microsoft Entra アプリ ID (前提条件として作成) を入力します サービス プリンシパル アプリのキー Microsoft Entra アプリ キー (前提条件として作成) を入力します Microsoft Entra テナント ID Microsoft Entra テナント (microsoft.com や contoso.com など) を入力します
[この接続の使用をすべてのパイプラインに許可します] チェックボックスを選択し、[OK] を選択します。
管理者コマンドが実行時間の長い非同期操作である場合は、[ 長い非同期管理者コマンドが完了するまで待機する ] チェック ボックスをオンにします。 有効にすると、タスクはコマンドが完了するまで、
.show operationsを使用して操作の状態をポーリングします。
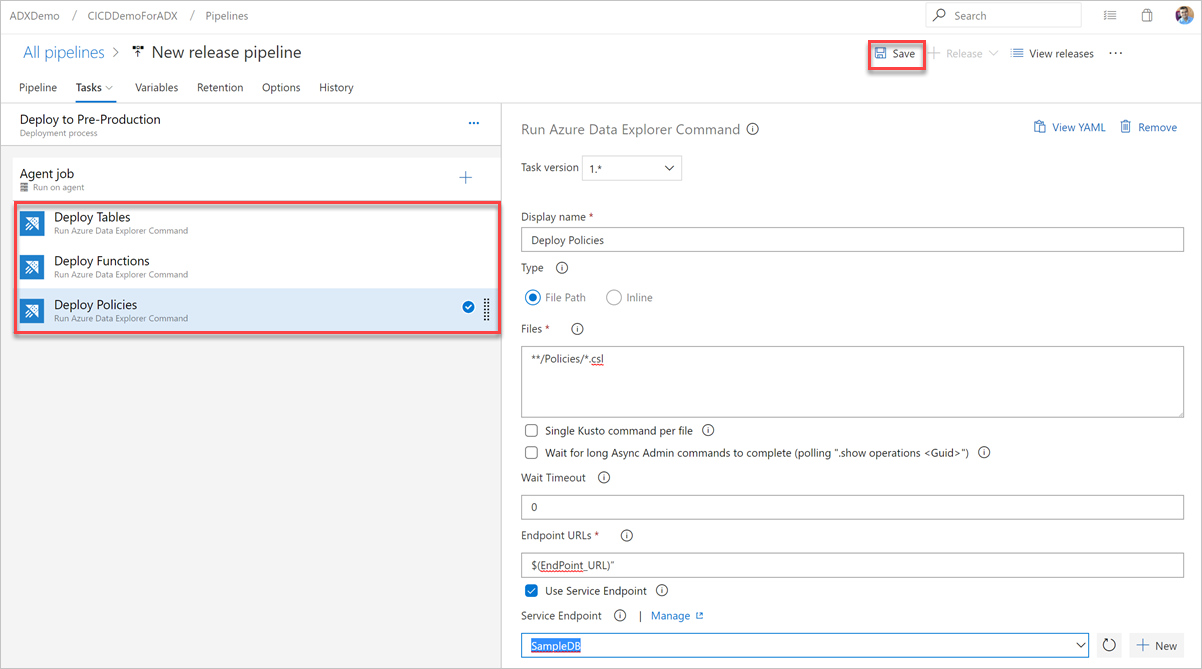
[保存] を選択し、[タスク] タブで、[テーブルの展開]、[関数の展開]、[ポリシーの展開] の 3 つのタスクがあることを確認します。
クエリ タスクを作成する
必要に応じて、クラスターに対してクエリを実行するタスクを作成します。 ビルドまたはリリース パイプライン内でクエリを実行すると、データセットを検証し、そのクエリ結果に基づいてステップを成功または失敗させることができます。 タスクの成功条件は、クエリによって返される内容に応じて、行数のしきい値または 1 つの値に基づくことができます。
[タスク] タブで、Agent job の横の + を選択し、Azure Data Explorer を検索します。
[Run Azure Data Explorer Query]\(Azure Data Explorer クエリの実行\) の [追加] を選択します。
[Kusto Query]\(Kusto クエリ\) を選択し、次の情報でタスクを更新します。
- 表示名: タスクの名前。 たとえば、「Query cluster」にします。
- 種類: Inline を選択します。
- クエリ: 実行するクエリを入力します。
-
エンドポイント URL: 前に作成した
EndPoint URL変数を指定します。 - Use Service Endpoint (サービス エンドポイントを使用する): このオプションを選択します。
- Service Endpoint (サービス エンドポイント): サービス エンドポイントを選択します。
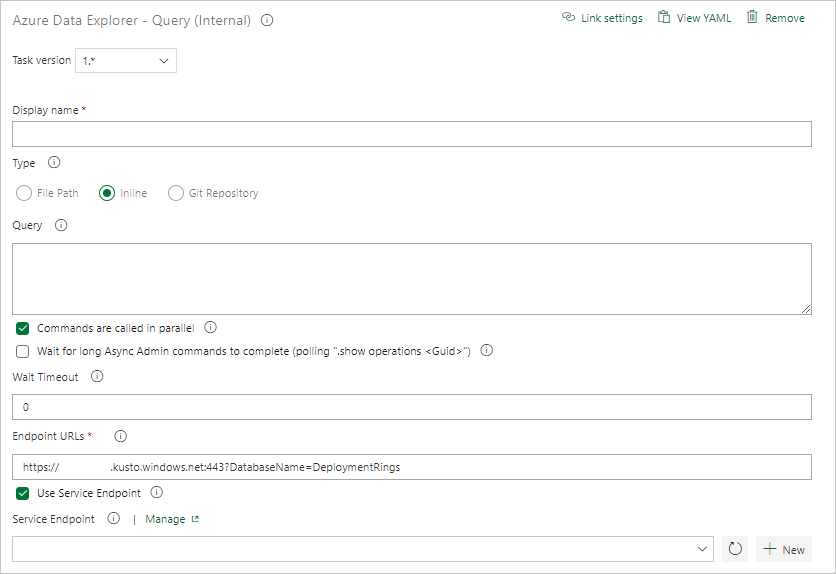
[タスクの結果] で、次のようにクエリの結果に基づいてタスクの成功条件を選択します。
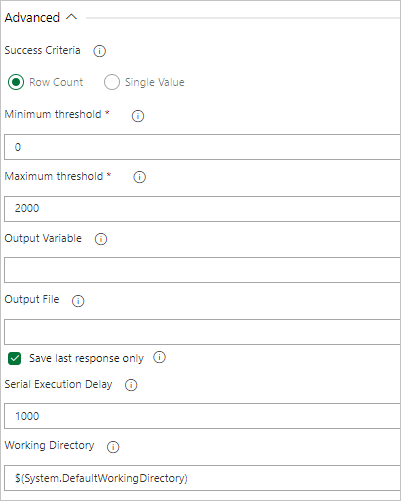
クエリから行が返される場合は、[行数] を選択 し、必要な条件を指定します。
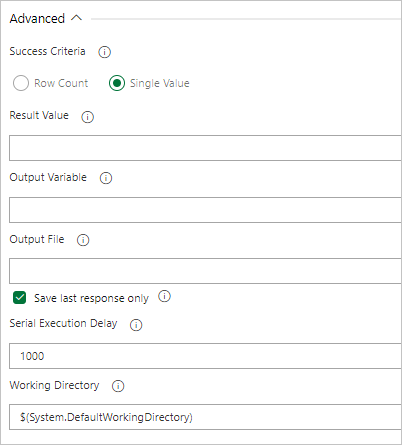
クエリから値が返される場合は、[単一値] を選択し、期待される結果を指定します。
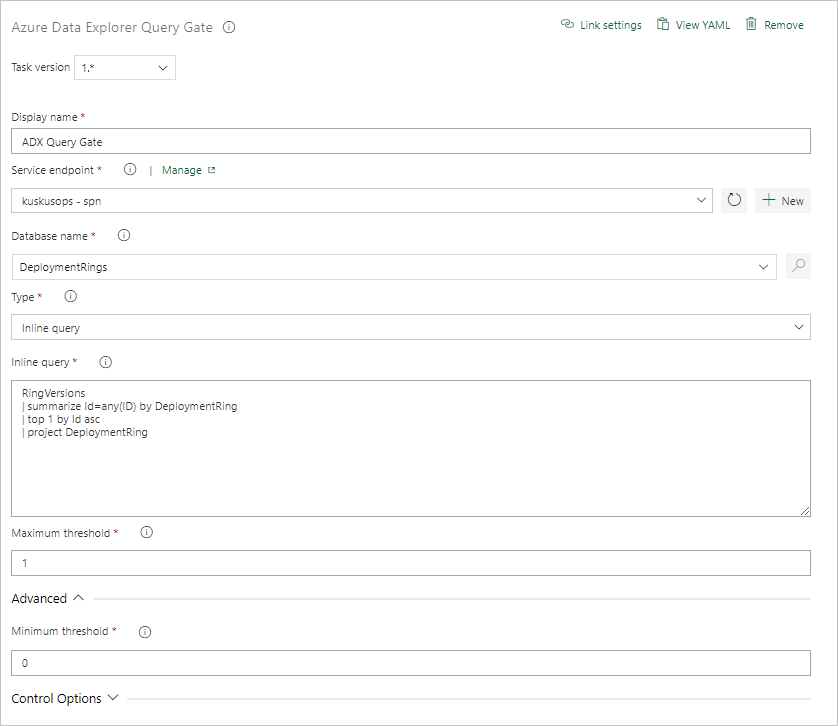
クエリ サーバー ゲート タスクを作成する
必要に応じて、クラスターに対してクエリを実行し、クエリ結果の行数に応じてリリースの進行状況を保留にするタスクを作成します。 サーバー クエリ ゲート タスクはエージェントレス ジョブです。つまり、クエリは Azure DevOps Server 上で直接実行されます。
[タスク] タブで、+ を「エージェントレス ジョブ」で選択し、Azure Data Explorer を検索します。
[Run Azure Data Explorer Query Server Gate] で [追加] を選択します。
[Kusto Query Server Gate]\(Kusto クエリ サーバー ゲート\) を選択し、[Server Gate Test]\(サーバー ゲート テスト\) を選択します。
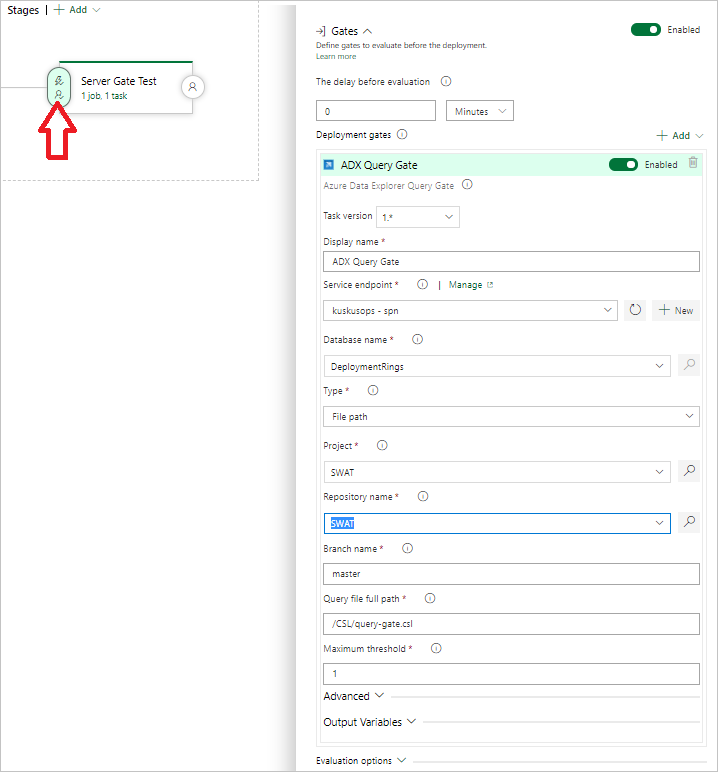
次の情報を入力してタスクを構成します。
- 表示名: ゲートの名前。
- Service Endpoint (サービス エンドポイント): サービス エンドポイントを選択します。
- データベース名: データベース名を指定します。
- 種類: [Inline query]\(インライン クエリ\) を選択します。
- クエリ: 実行するクエリを入力します。
- [Maximum threshold]\(最大しきい値\): クエリの成功条件となる最大行数を指定します。
注意
リリースを実行すると、次のような結果が表示されます。
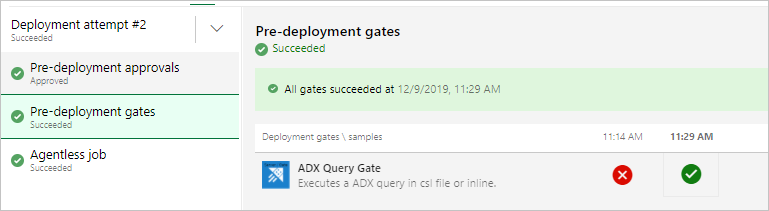
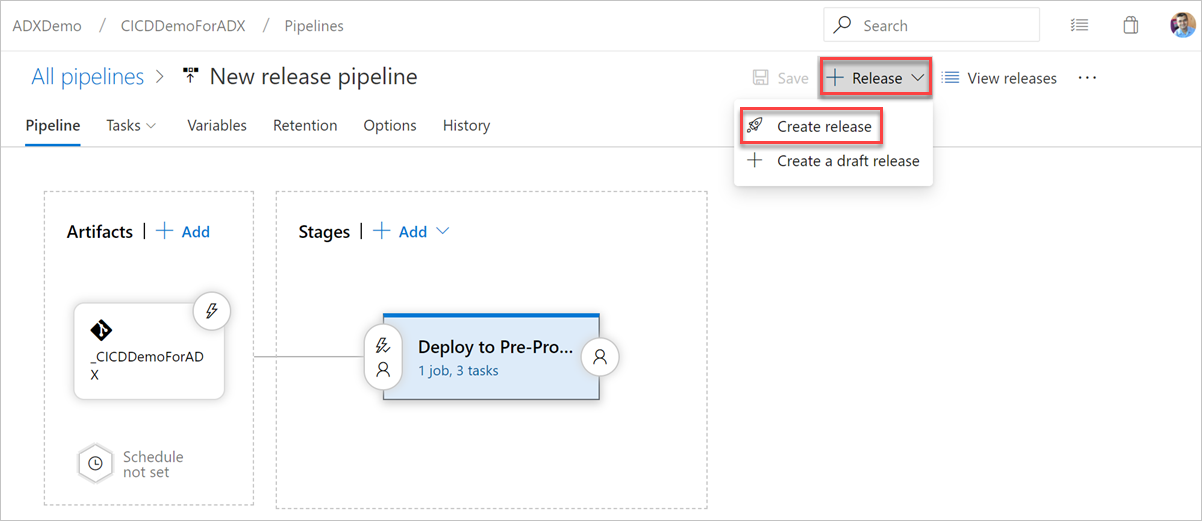
リリースを実行する
[+ リリース]>リリースを作成してリリースを開始します。
[ログ] タブで、デプロイ状態が成功であることを確認します。
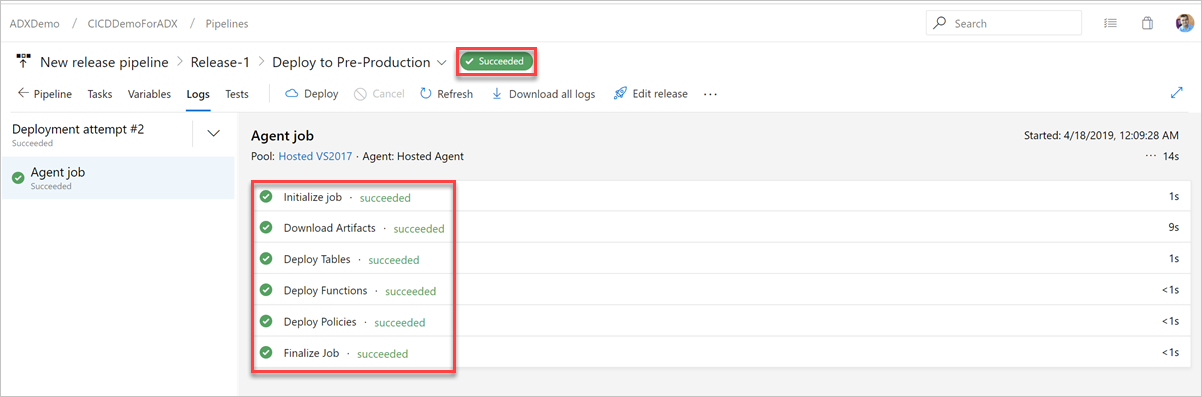
これで、運用前の展開用リリース パイプラインの作成が完了しました。
Azure Data Explorer DevOps タスクのキーレス認証のサポート
この拡張機能では、Azure Data Explorer クラスターのキーレス認証がサポートされています。 キーレス認証を使用すると、キーを使用せずに Azure Data Explorer クラスターに対して認証を行うことができます。 セキュリティが強化され、管理が容易になります。
注意
Kusto Fabric クラスター URL は、ワークロード ID フェデレーション (WIF) とマネージド ID 認証ではサポートされていません。
Azure Data Explorer サービス接続内でフェデレーション ID 資格情報 (FIC) 認証を使用する
注意
拡張機能バージョン 4.0.x 以降、Azure Data Explorer サービス エンドポイントでは、サービス プリンシパル認証に加えて、ワークロード ID フェデレーション (WIF) 認証がサポートされています。
DevOps インスタンス内で、[プロジェクト設定]>[サービス接続]>[新しいサービス接続]>[Azure Data Explorer] に移動します。
[フェデレーション ID 資格情報] を選択し、クラスターの URL、サービス プリンシパル ID、テナント ID、サービス接続名を入力し、[保存] を選択します。
Azure portal 内で、Microsoft Entra アプリを開いて指定したサービス プリンシパルを表示します。
[証明書とシークレット] の下で、[フェデレーション資格情報] を選択します。
![Microsoft Entra アプリの [フェデレーション資格情報] タブを示すスクリーンショット。](media/devops/credential.png)
[資格情報の追加] を選択してから [フェデレーション資格情報のシナリオ] の [その他の発行者] を選択し、次の情報を使用して設定を入力します。
[発行者]:
<https://vstoken.dev.azure.com/{System.CollectionId}>。この{System.CollectionId}は Azure DevOps 組織のコレクション ID です。 コレクション ID は、次の方法で確認できます。- Azure DevOps クラシック リリース パイプライン内で、[ジョブの初期化] を選択します。 ログの中にコレクション ID が表示されます。
[サブジェクト識別子]:
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>。この{DevOps_Org_name}は Azure DevOps 組織名、{Project_Name}はプロジェクト名、{Service_Connection_Name}は前に作成したサービス接続名です。注意
サービス接続名にスペースがある場合は、フィールドのスペースと共に使用できます。 (例:
sc://MyOrg/MyProject/My Service Connection)。[名前]: 資格情報の名前を入力します。
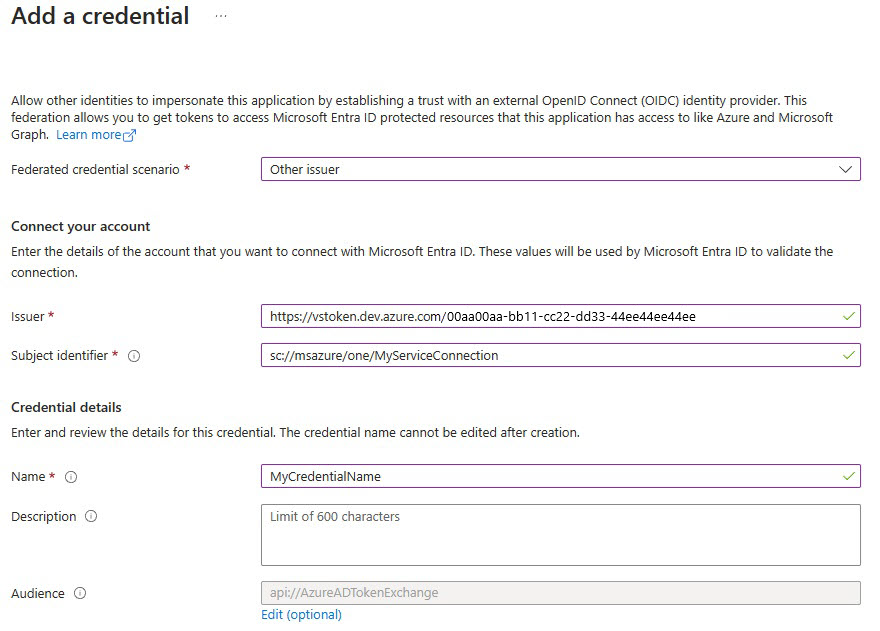
[追加] を選択します。
Azure Resource Manager (ARM) サービス接続内でフェデレーション ID 資格情報またはマネージド ID を使用する
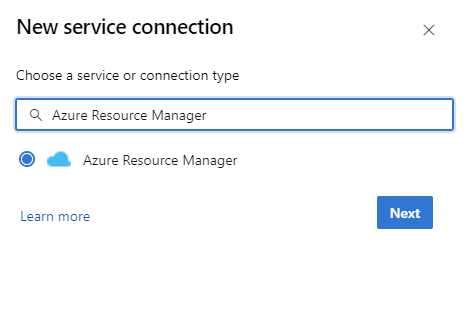
DevOps インスタンス内で、[プロジェクト設定]>[サービス接続]>[新しいサービス接続]>[Azure Resource Manager] に移動します。
[ 認証方法] で、 ワークロード ID フェデレーション (自動) を選択して続行します。 手動の ワークロード ID フェデレーション (手動) オプションを使用して、ワークロード ID フェデレーションの詳細または マネージド ID オプションを指定することもできます。 Azure Resource Manager (ARM) サービス接続で Azure Resource Management を使用してマネージド ID を設定する方法について説明します。
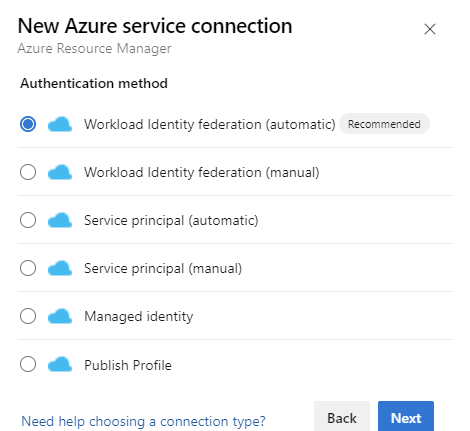
必要な詳細を入力し、[検証] を選択してから、[保存] を選択します。
YAML パイプラインの構成
パイプライン スキーマ内の Azure DevOps Web UI または YAML コードを使用してタスクを構成できます。
この拡張機能には 3 つのパイプライン タスクが用意されています。すべて YAML 経由でアクセスできます。
-
Azure Data Explorer コマンド (
ADXAdminCommand@5) - ADX クラスターに対して管理者/制御コマンドを実行する - Azure Data Explorer クエリ - ADX クラスターに対してクエリを実行し、結果を解析する
- Azure Data Explorer Query Server Gate — クエリ結果に応じてリリースをゲートするエージェントレス タスク
ヒント
セキュリティを強化するには、パイプラインに資格情報を直接格納するのではなく、Azure Resource Manager サービス接続経由で ワークロード ID フェデレーション または マネージド ID 認証を使用します。 これらのキーレス認証方法が推奨されるベスト プラクティスです。
管理コマンドのサンプル - インライン コマンド
次の例では、ワークロード ID フェデレーション (WIF) とマネージド ID 認証をサポートする Azure Resource Manager (ARM) サービス接続を使用してインライン管理者コマンドを実行します。
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Run inline ADX admin command'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'inline'
inlineCommands: |
.create-merge table MyTable (Id:int, Name:string, Timestamp:datetime)
.create-or-alter function MyFunction() { MyTable | take 10 }
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
管理コマンドのサンプル - ファイル ベースのコマンド
次の例では、AAD アプリ登録認証を使用して、glob パターンに一致するファイルから管理コマンドを実行します。
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema from files'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
aadAppId: '$(AAD_APP_ID)'
aadAppKey: '$(AAD_APP_KEY)'
aadTenantId: '$(AAD_TENANT_ID)'
continueOnError: true
ファイルの名前付け規則に応じて、glob パターンとして **/*.kql を使用することもできます。
管理者コマンドのサンプル - Azure Resource Manager サービス接続
次の例では、キーレス認証で ワークロード ID フェデレーション (WIF) と マネージド ID を サポートする Azure Resource Manager サービス接続を使用します。
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema via ARM service connection'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
condition: ne(variables['ProductVersion'], '')
タスク入力パラメーター
次の表では、 ADXAdminCommand@5 タスクのキー入力パラメーターについて説明します。
| パラメーター | 説明 |
|---|---|
clusterUri |
Kusto クラスターのベース URI (たとえば、 https://<ClusterName>.<Region>.kusto.windows.net) |
databaseName |
ターゲット データベースの名前 |
commandsSource |
コマンドのソース: インライン KQL コマンドのinline、またはファイル ベースのコマンドのfiles |
inlineCommands |
実行するインライン KQL コマンド ( commandsSource が inlineされている場合に使用) |
commandFilesPattern |
スクリプト ファイルの Glob パターン ( commandsSource が filesされている場合に使用されます)、たとえば、 **/*.csl や **/*.kql |
aadAppId |
AAD アプリ認証の Microsoft Entra App (サービス プリンシパル) ID |
aadAppKey |
AAD アプリ認証用の Microsoft Entra アプリ キー/シークレット |
aadTenantId |
AAD アプリ認証の Microsoft Entra テナント ID |
azureSubscription |
ARM ベースの認証用の Azure Resource Manager サービス接続の名前 (WIF とマネージド ID をサポート) |
認証方法
拡張機能では、次の認証方法がサポートされています。
-
Azure Active Directory (AAD) アプリの登録 -
aadAppId、aadAppKey、aadTenantIdを使用してサービス プリンシパルで認証します。 資格情報をセキュリティで保護されたパイプライン変数として格納します。 - 証明書ベースの認証 - サービス プリンシパル認証には、アプリ キーの代わりに証明書を使用します。 証明書の詳細をセキュリティで保護されたパイプライン変数として格納します。
-
マネージド ID — マネージド ID で構成された Azure Resource Manager サービス接続を使用します。
azureSubscription入力をサービス接続名に設定します。 -
ワークロード ID フェデレーション (WIF) - ワークロード ID フェデレーション (自動または手動) で Azure Resource Manager サービス接続を使用します。 これは、推奨されるキーレス アプローチです。
azureSubscription入力をサービス接続名に設定します。
注意
ワークロード ID フェデレーション (WIF) は、拡張機能に新しく追加されています。 これにより、シークレットレス認証が有効になり、新しいパイプラインに推奨されるアプローチです。 セットアップ手順については、「 Azure Resource Manager (ARM) サービス接続でフェデレーション ID 資格情報またはマネージド ID を使用する」を参照してください。
クエリ のサンプル
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@5
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DatabaseName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true