Amazon S3 から Azure Data Lake Storage Gen2 にデータを移行する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新たに試用を開始する方法については、こちらをご覧ください。
数億ものファイルで構成されるペタバイト規模のデータを Amazon S3 から Azure Data Lake Storage Gen2 に移行するには、テンプレートを使用します。
Note
AWS S3 から Azure に小さなデータ ボリューム (たとえば、10 TB 未満) をコピーする場合は、Azure Data Factory のデータ コピー ツールを使用する方が効率的で簡単です。 この記事で説明するテンプレートは、必要以上のものになってしまいます。
ソリューション テンプレートについて
データのパーティションは、10 TB を超えるデータを移行する場合に特に推奨されます。 データをパーティション分割するには、"プレフィックス" 設定を利用し、Amazon S3 上のフォルダーとファイルを名前でフィルター処理します。その後、各 ADF コピー ジョブでパーティションを 1 つずつコピーできます。 複数の ADF コピー ジョブを同時に実行して、スループットを向上させることができます。
通常、データの移行では、1 回限りの履歴データの移行に加え、変更を AWS S3 から Azure に定期的に同期することが必要になります。 テンプレートには、以下の 2 つがあります。一方のテンプレートは 1 回限りの履歴データの移行を対象としており、もう一方のテンプレートは AWS S3 から Azure への変更の同期を対象としています。
履歴データを Amazon S3 から Azure Data Lake Storage Gen2 に移行するテンプレートの場合
このテンプレート ("テンプレート名: migrate historical data from AWS S3 to Azure Data Lake Storage Gen2 (AWS S3 から Azure Data Lake Storage Gen2 への履歴データの移行) ") では、Azure SQL Database の外部制御テーブルにパーティション一覧を記述していることを前提としています。 そのため、Lookup アクティビティを使用して外部制御テーブルからパーティション一覧を取得し、各パーティションを反復処理して、各 ADF コピー ジョブでパーティションを 1 つずつコピーするようにします。 コピー ジョブは、完了すると、Stored Procedure アクティビティを使用して、制御テーブル内の各パーティションのコピーの状態を更新します。
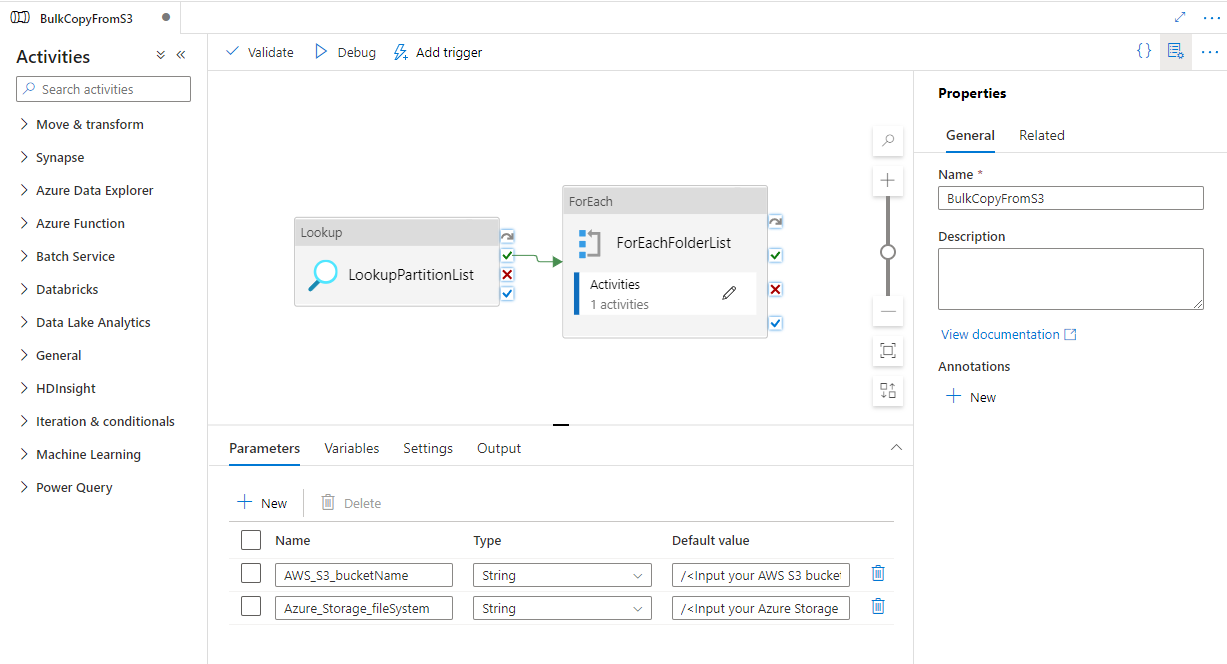
このテンプレートには、5 つのアクティビティが含まれています。
- Lookup では、Azure Data Lake Storage Gen2 にコピーされていないパーティションを外部制御テーブルから取得します。 テーブル名は s3_partition_control_table で、テーブルからデータを読み込むクエリは "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0" です。
- ForEach では、Lookup アクティビティからパーティション一覧を取得し、各パーティションを TriggerCopy アクティビティに対して反復処理します。 複数の ADF コピー ジョブを同時に実行するように batchCount を設定できます。 このテンプレートでは、2 が設定されています。
- ExecutePipeline では、CopyFolderPartitionFromS3 パイプラインを実行します。 別のパイプラインを作成して各コピー ジョブでパーティションをコピーする理由は、失敗したコピー ジョブを再実行して、その特定のパーティションを AWS S3 から再度読み込むことが簡単になるためです。 他のパーティションを読み込む他のすべてのコピー ジョブには影響しません。
- Copy では、各パーティションを AWS S3 から Azure Data Lake Storage Gen2 にコピーします。
- SqlServerStoredProcedure では、制御テーブル内の各パーティションのコピーの状態が更新されます。
このテンプレートには、次の 2 つのパラメーターが含まれています。
- AWS_S3_bucketName は、データの移行元の AWS S3 上にあるバケット名です。 AWS S3 上の複数のバケットからデータを移行する場合は、外部制御テーブルに 1 つ以上の列を追加して、パーティションごとにバケット名を格納することができます。また、その各列からデータを取得するように、パイプラインを更新できます。
- Azure_Storage_fileSystem は、データの移行先の Azure Data Lake Storage Gen2 上の fileSystem 名です。
変更されたファイルのみを Amazon S3 から Azure Data Lake Storage Gen2 にコピーするテンプレートの場合
このテンプレート ("テンプレート名: copy delta data from AWS S3 to Azure Data Lake Storage Gen2 (AWS S3 から Azure Data Lake Storage Gen2 へのデルタ データのコピー) ") では、各ファイルの LastModifiedTime を使用して、新規または更新済みのファイルのみを AWS S3 から Azure にコピーします。 ファイルまたはフォルダーが既に AWS S3 上のファイルまたはフォルダーの名前の一部であるタイムスライス情報 (例: /yyyy/mm/dd/file.csv) によって時間でパーティション分割されている場合は、このチュートリアルに移動して、新しいファイルを増分読み込みするための高パフォーマンスなアプローチを採用することができます。 このテンプレートでは、Azure SQL Database の外部制御テーブルにパーティション一覧を記述済みであることを前提としています。 そのため、Lookup アクティビティを使用して外部制御テーブルからパーティション一覧を取得し、各パーティションを反復処理して、各 ADF コピー ジョブでパーティションを 1 つずつコピーするようにします。 各コピー ジョブは、AWS S3 からのファイルのコピーを開始すると、LastModifiedTime プロパティに基づいて、新規または更新済みのファイルのみを識別してコピーします。 コピー ジョブは、完了すると、Stored Procedure アクティビティを使用して、制御テーブル内の各パーティションのコピーの状態を更新します。
このテンプレートには、次の 7 つのアクティビティが含まれています。
- Lookup では、パーティションを外部制御テーブルから取得します。 テーブル名は s3_partition_delta_control_table で、テーブルからデータを読み込むクエリは "select distinct PartitionPrefix from s3_partition_delta_control_table" です。
- ForEach では、パーティション一覧を Lookup アクティビティから取得し、各パーティションが TriggerDeltaCopy アクティビティに対して反復処理します。 複数の ADF コピー ジョブを同時に実行するように batchCount を設定できます。 このテンプレートでは、2 が設定されています。
- ExecutePipeline では、DeltaCopyFolderPartitionFromS3 パイプラインを実行します。 別のパイプラインを作成して各コピー ジョブでパーティションをコピーする理由は、失敗したコピー ジョブを再実行して、その特定のパーティションを AWS S3 から再度読み込むことが簡単になるためです。 他のパーティションを読み込む他のすべてのコピー ジョブには影響しません。
- Lookup では、最後のコピー ジョブの実行日時が外部制御テーブルから取得されます。そのため、新しいファイルまたは更新されたファイルは、LastModifiedTime を通じて特定できます。 テーブル名は s3_partition_delta_control_table で、テーブルからデータを読み込むクエリは "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1" です。
- Copy では、各パーティションの新しいファイルまたは変更されたファイルだけが AWS S3 から Azure Data Lake Storage Gen2 にコピーされます。 modifiedDatetimeStart のプロパティは、最後のコピー ジョブの実行日時に設定されます。 modifiedDatetimeEnd のプロパティは、現在のコピー ジョブの実行日時に設定されます。 時間には UTC タイム ゾーンが適用されることに注意してください。
- SqlServerStoredProcedure では、制御テーブル内の各パーティションのコピーの状態と、コピーが成功した場合の実行日時が更新されます。 SuccessOrFailure の列は、1 に設定されます。
- SqlServerStoredProcedure では、制御テーブル内の各パーティションのコピーの状態と、コピーが失敗した場合の実行日時が更新されます。 SuccessOrFailure の列は、0 に設定されます。
このテンプレートには、次の 2 つのパラメーターが含まれています。
- AWS_S3_bucketName は、データの移行元の AWS S3 上にあるバケット名です。 AWS S3 上の複数のバケットからデータを移行する場合は、外部制御テーブルに 1 つ以上の列を追加して、パーティションごとにバケット名を格納することができます。また、その各列からデータを取得するように、パイプラインを更新できます。
- Azure_Storage_fileSystem は、データの移行先の Azure Data Lake Storage Gen2 上の fileSystem 名です。
この 2 つのソリューション テンプレートの使用方法
履歴データを Amazon S3 から Azure Data Lake Storage Gen2 に移行するテンプレートの場合
AWS S3 のパーティション一覧を格納するために、Azure SQL Database 内に制御テーブルを作成します。
Note
テーブル名は、s3_partition_control_table です。 制御テーブルのスキーマは、PartitionPrefix と SuccessOrFailure です。ここで、PartitionPrefix は Amazon S3 内のフォルダーとファイルを名前でフィルター処理するための S3 のプレフィックスの設定であり、SuccessOrFailure は各パーティションのコピーの状態です。0 はこのパーティションが Azure にコピーされていないことを意味し、1 はこのパーティションが Azure に正常にコピーされたことを意味します。 制御テーブルには 5 つのパーティションが定義されており、各パーティションのコピーの既定の状態は 0 です。
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);制御テーブル用に同じ Azure SQL Database 上にストアド プロシージャを作成します。
注意
ストアド プロシージャの名前は、sp_update_partition_success です。 これは、ADF パイプラインの SqlServerStoredProcedure アクティビティによって呼び出されます。
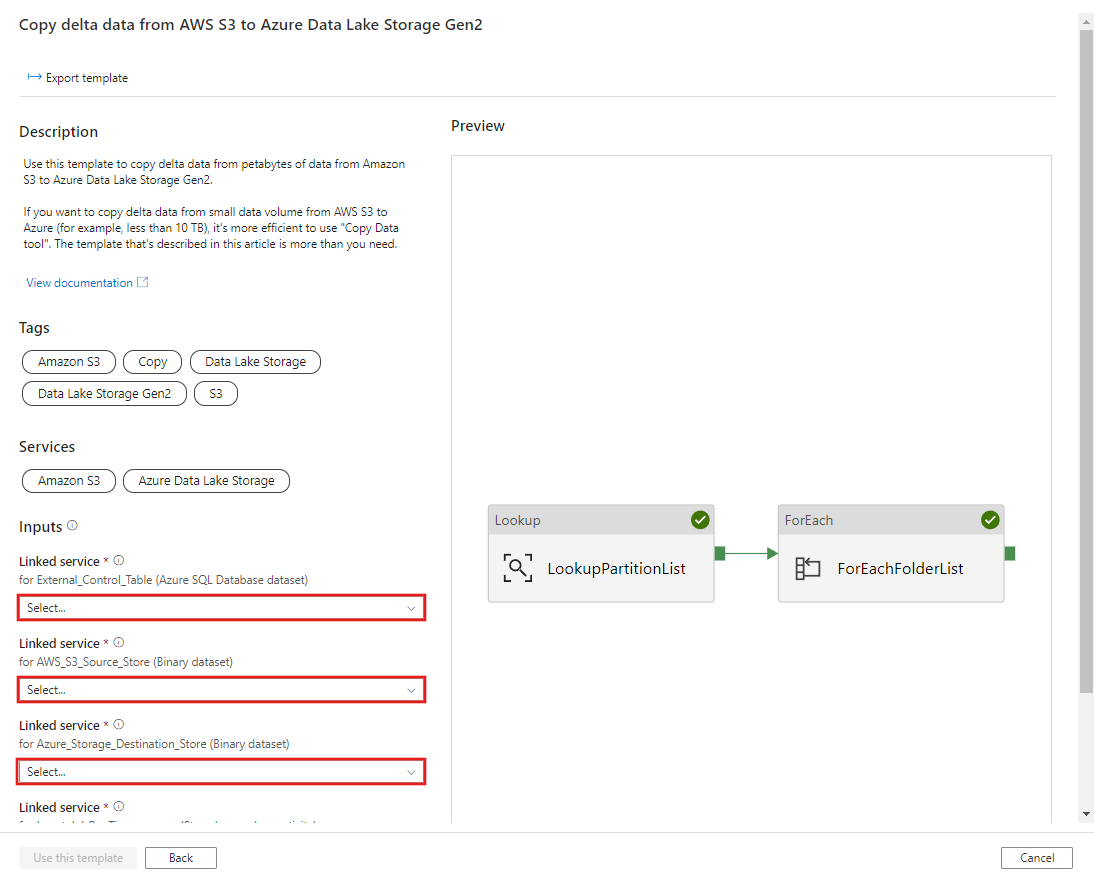
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOMigrate historical data from AWS S3 to Azure Data Lake Storage Gen2 (AWS S3 から Azure Data Lake Storage Gen2 への履歴データの移行) テンプレートに移動します。 外部制御テーブルへの接続を入力します。データ ソース ストアとして AWS S3、宛先ストアとして Azure Data Lake Storage Gen2 を指定します。 外部制御テーブルとストアド プロシージャは、同じ接続を参照していることに注意してください。
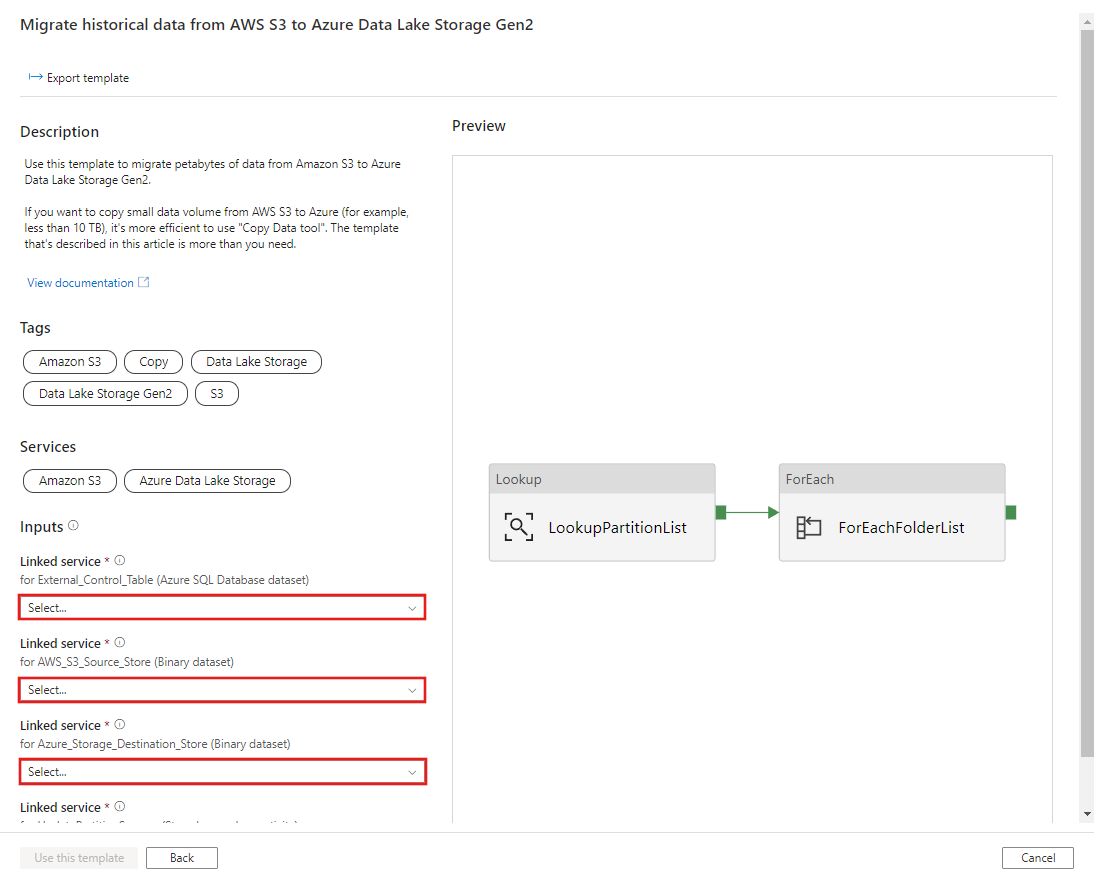
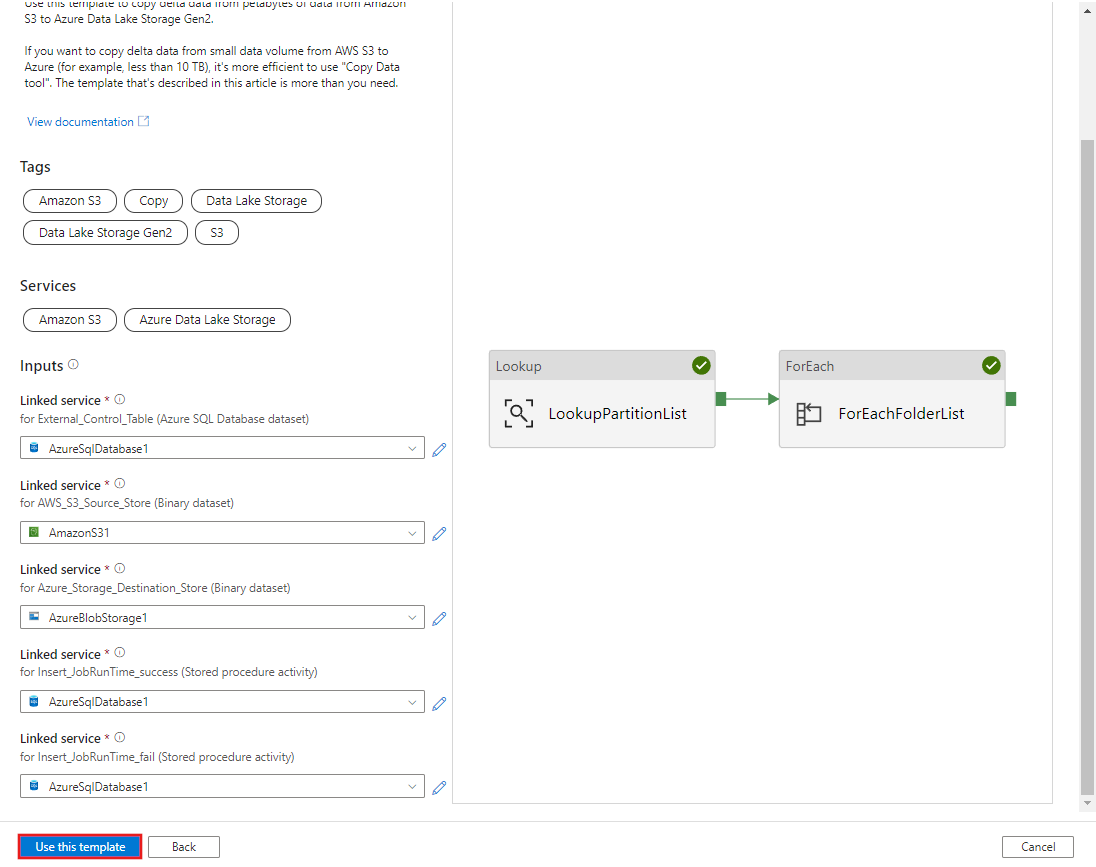
このテンプレートを使用する を選択します。
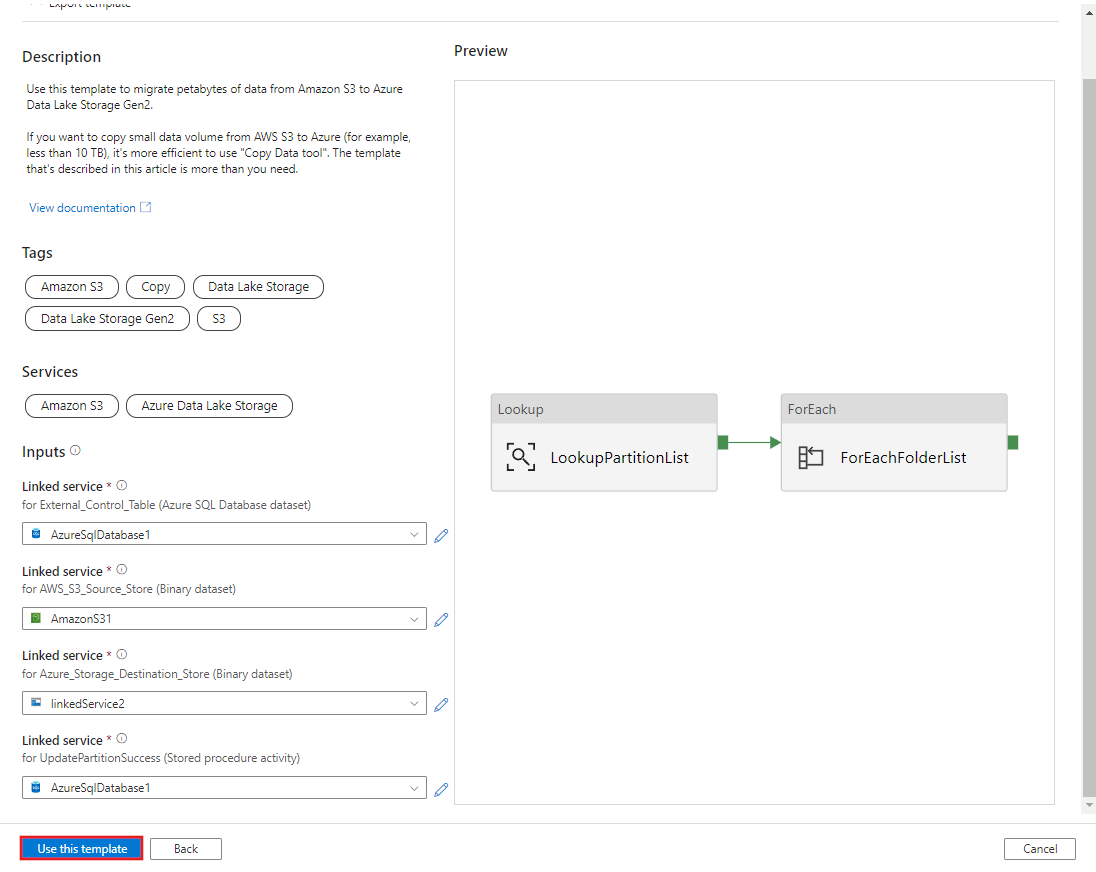
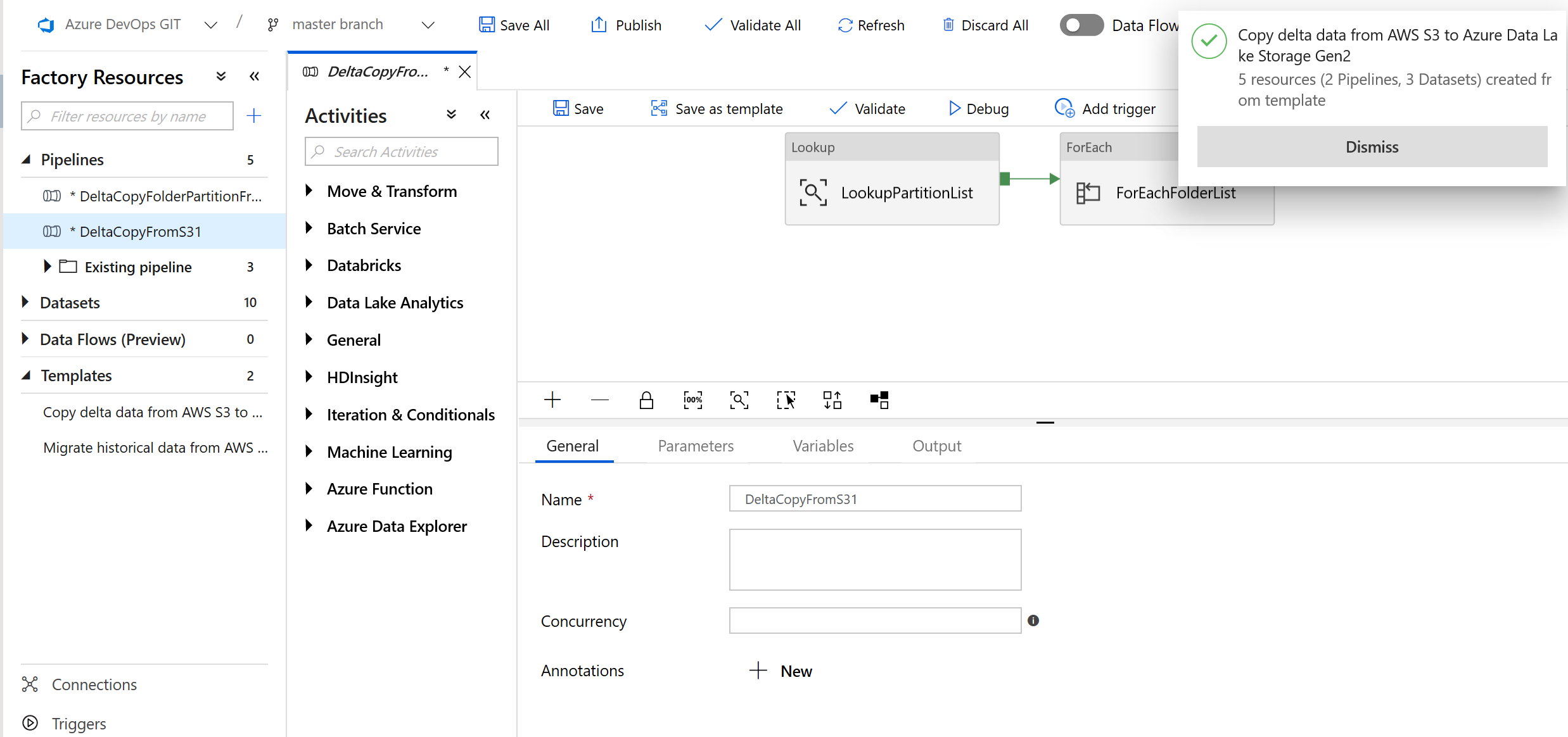
次の例に示すように、2 つのパイプラインと 3 つのデータセットが作成されたことがわかります。
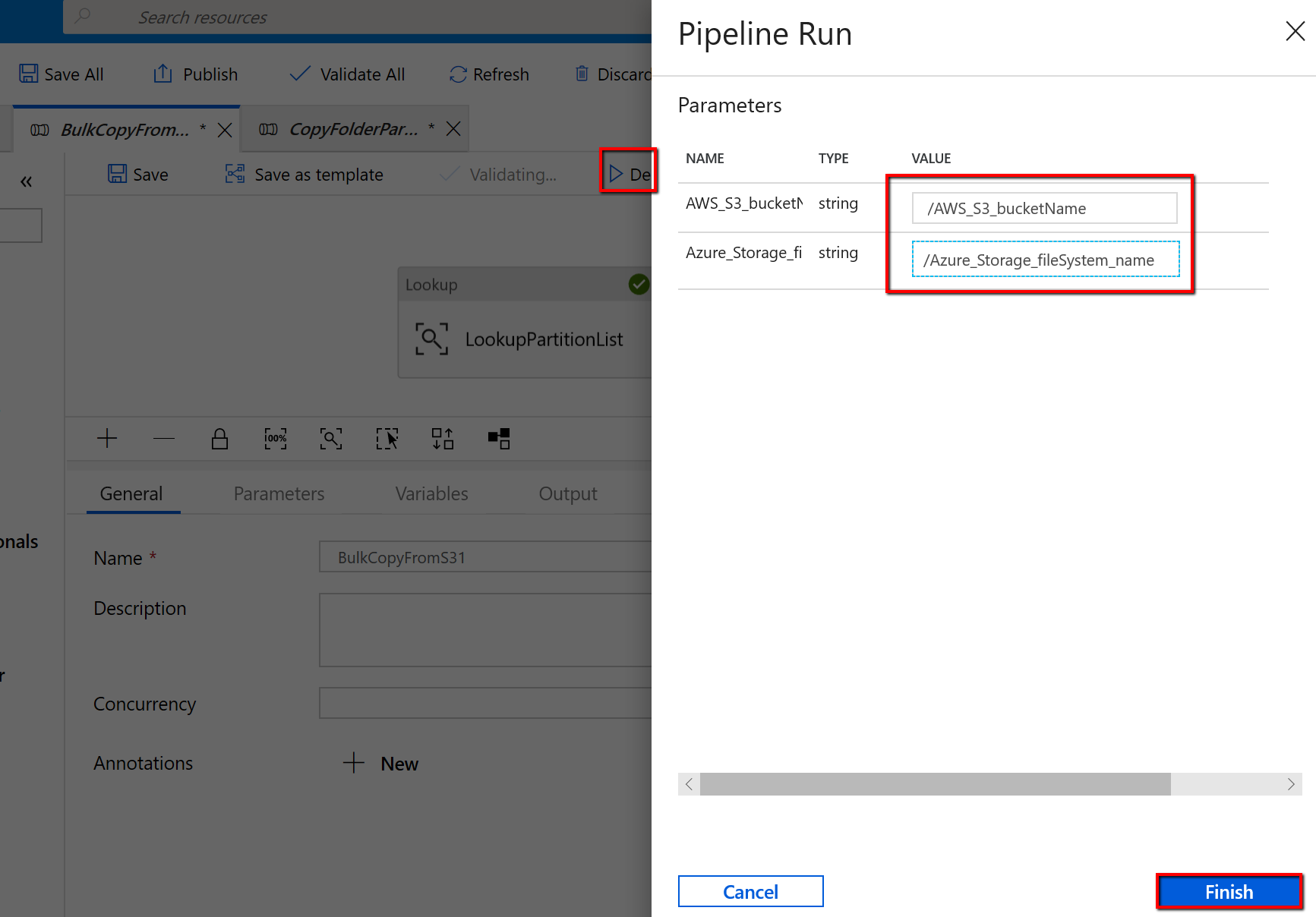
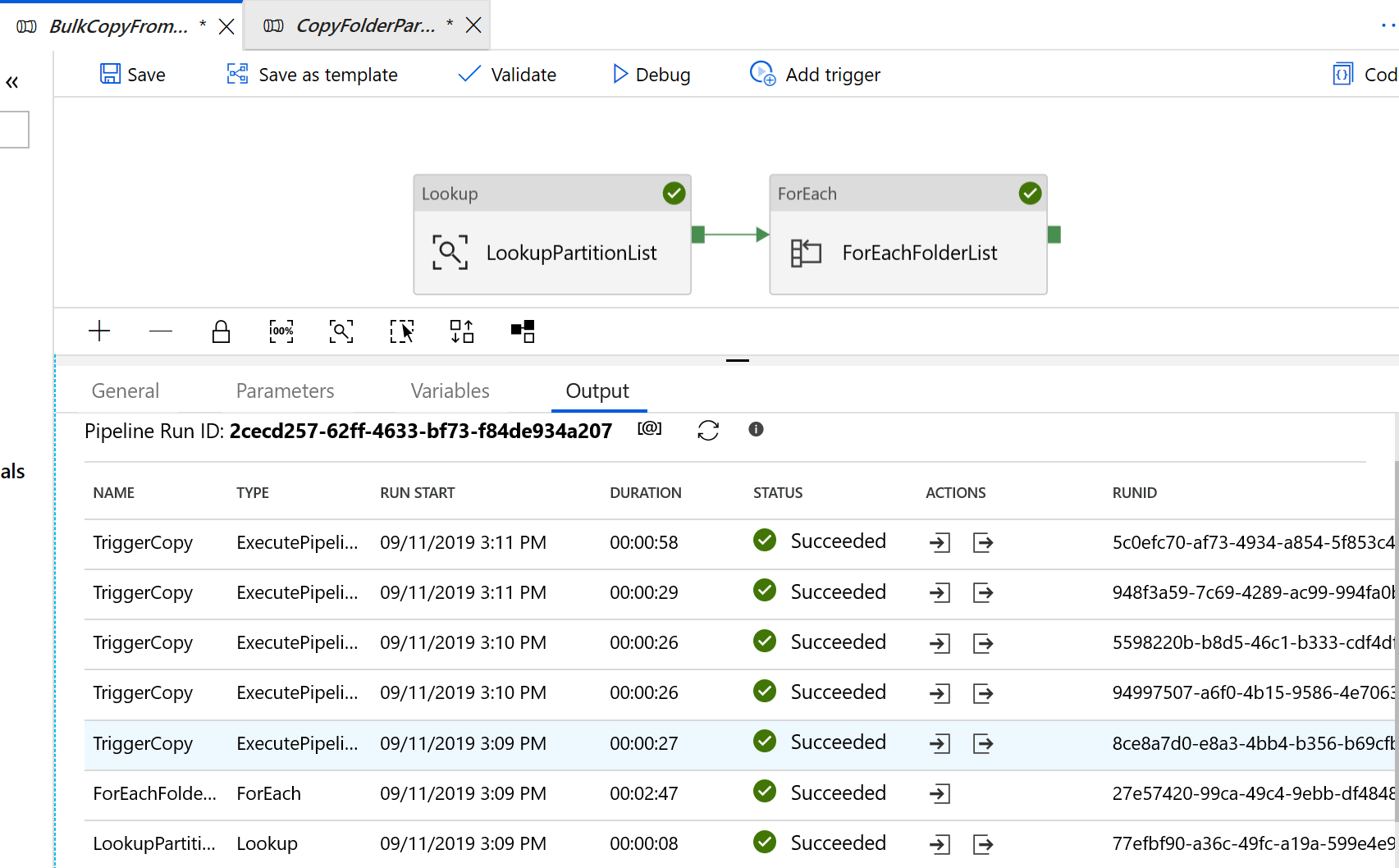
"BulkCopyFromS3" パイプラインに移動し、 [デバッグ] を選択し、 [パラメーター] を入力します。 次に、 [Finish]\(完了\) を選択します。
次の例のような結果が表示されます。
変更されたファイルのみを Amazon S3 から Azure Data Lake Storage Gen2 にコピーするテンプレートの場合
AWS S3 のパーティション一覧を格納するために、Azure SQL Database 内に制御テーブルを作成します。
Note
テーブル名は、s3_partition_delta_control_table です。 制御テーブルのスキーマは、PartitionPrefix、JobRunTime、および SuccessOrFailure です。この場合、PartitionPrefix は Amazon S3 内のフォルダーとファイルを名前でフィルター処理するための S3 のプレフィックスの設定、JobRunTime はコピー ジョブが実行されたときの datetime 値、SuccessOrFailure は各パーティションのコピーの状態です。0 はこのパーティションが Azure にコピーされていないことを意味し、1 はこのパーティションが Azure に正常にコピーされたことを意味します。 制御テーブルでは、5 つのパーティションが定義されています。 JobRunTime の既定値は、1 回限りの履歴データの移行が開始される時刻にすることができます。 ADF コピー アクティビティでは、その時刻以降に変更された AWS S3 上のファイルがコピーされます。 各パーティションのコピーの既定の状態は 1 です。
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);制御テーブル用に同じ Azure SQL Database 上にストアド プロシージャを作成します。
Note
このストアド プロシージャの名前は、sp_insert_partition_JobRunTime_success です。 これは、ADF パイプラインの SqlServerStoredProcedure アクティビティによって呼び出されます。
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOCopy delta data from AWS S3 to Azure Data Lake Storage Gen2 (AWS S3 から Azure Data Lake Storage Gen2 への差分データのコピー) テンプレートに移動します。 外部制御テーブルへの接続を入力します。データ ソース ストアとして AWS S3、宛先ストアとして Azure Data Lake Storage Gen2 を指定します。 外部制御テーブルとストアド プロシージャは、同じ接続を参照していることに注意してください。
このテンプレートを使用する を選択します。
次の例に示すように、2 つのパイプラインと 3 つのデータセットが作成されたことがわかります。
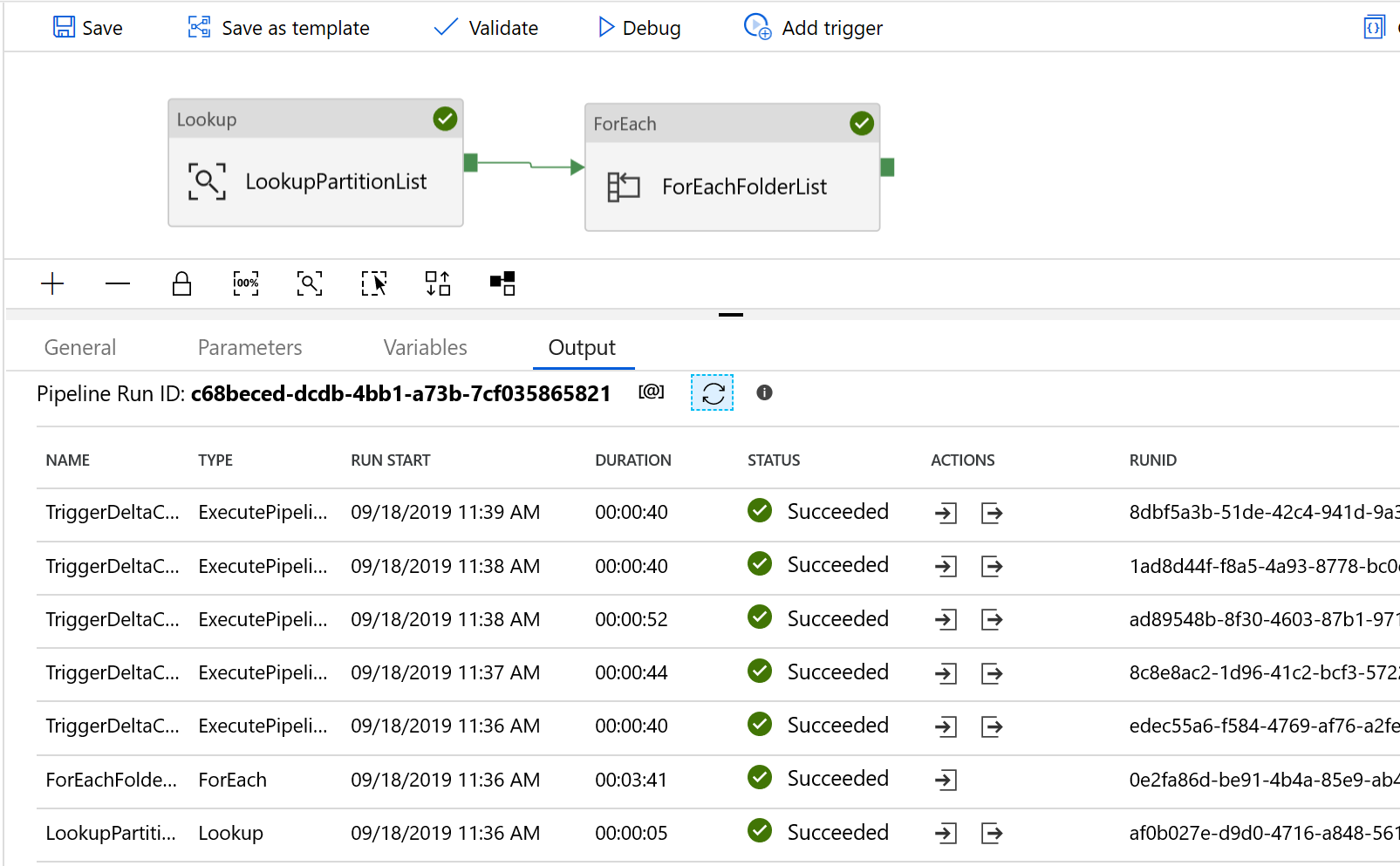
"DeltaCopyFromS3" パイプラインに移動し、 [デバッグ] を選択し、 [パラメーター] を入力します。 次に、 [Finish]\(完了\) を選択します。
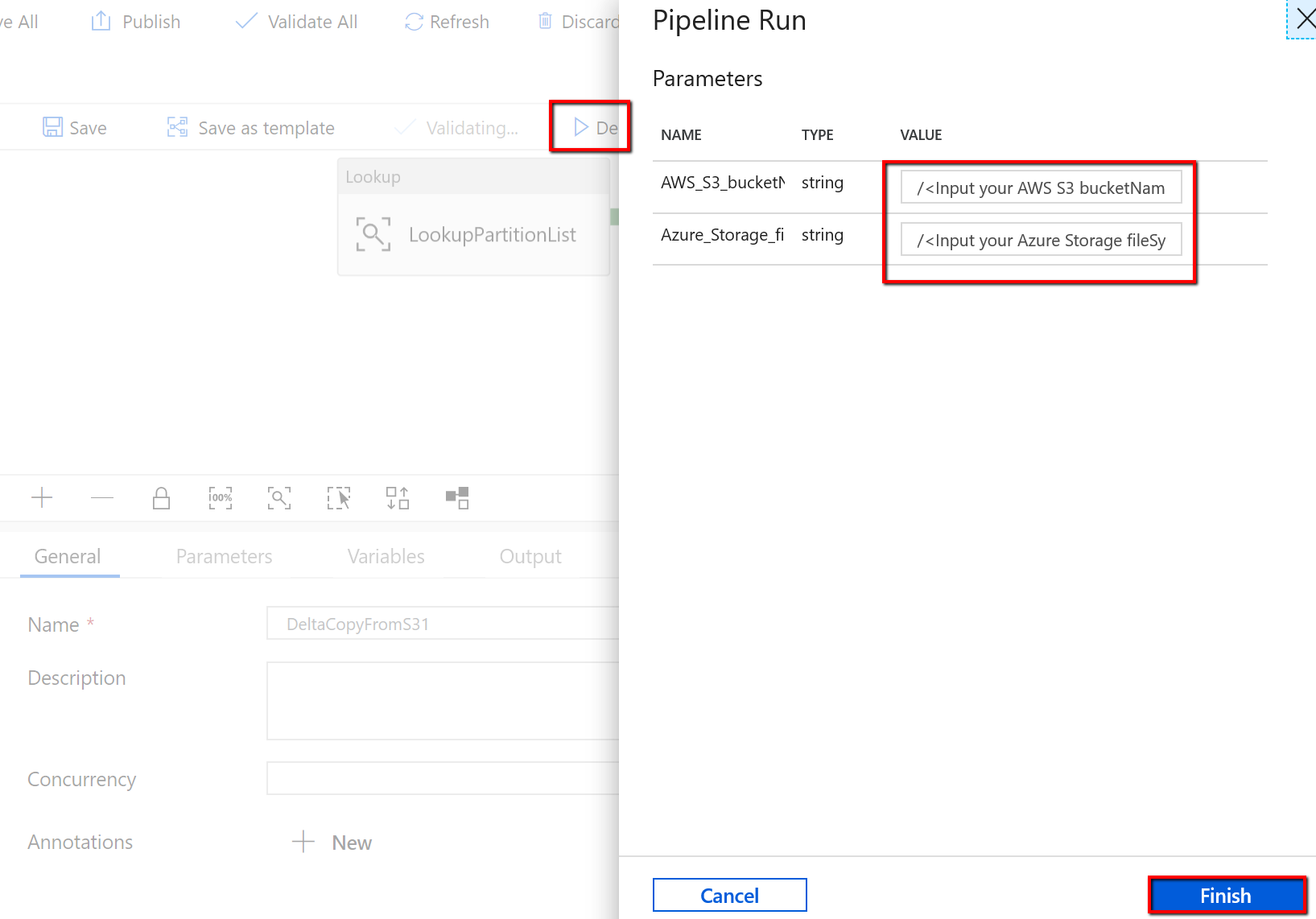
次の例のような結果が表示されます。
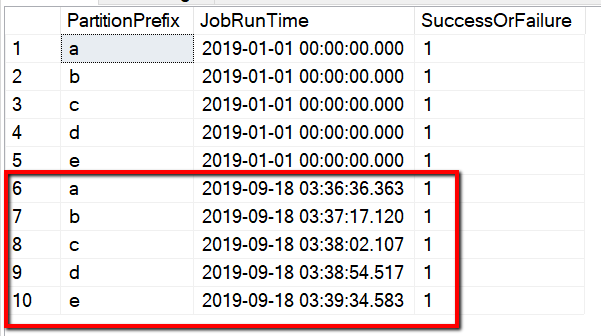
クエリ "select * from s3_partition_delta_control_table" による制御テーブルからの結果を確認することもできます。この出力は、次の例のようになります。
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示