Azure Data Lake Storage Gen1 のパフォーマンス チューニング
Data Lake Storage Gen1 は、I/O 集中型分析とデータ移動での高スループットをサポートします。 Data Lake Storage Gen1 では、利用可能なすべてのスループット (1 秒あたりに読み書き可能なデータの量) を利用することが、最適なパフォーマンスを得るために重要となります。 並列での読み取り数と書き込み数をできるだけ多くすることで、これを実現します。
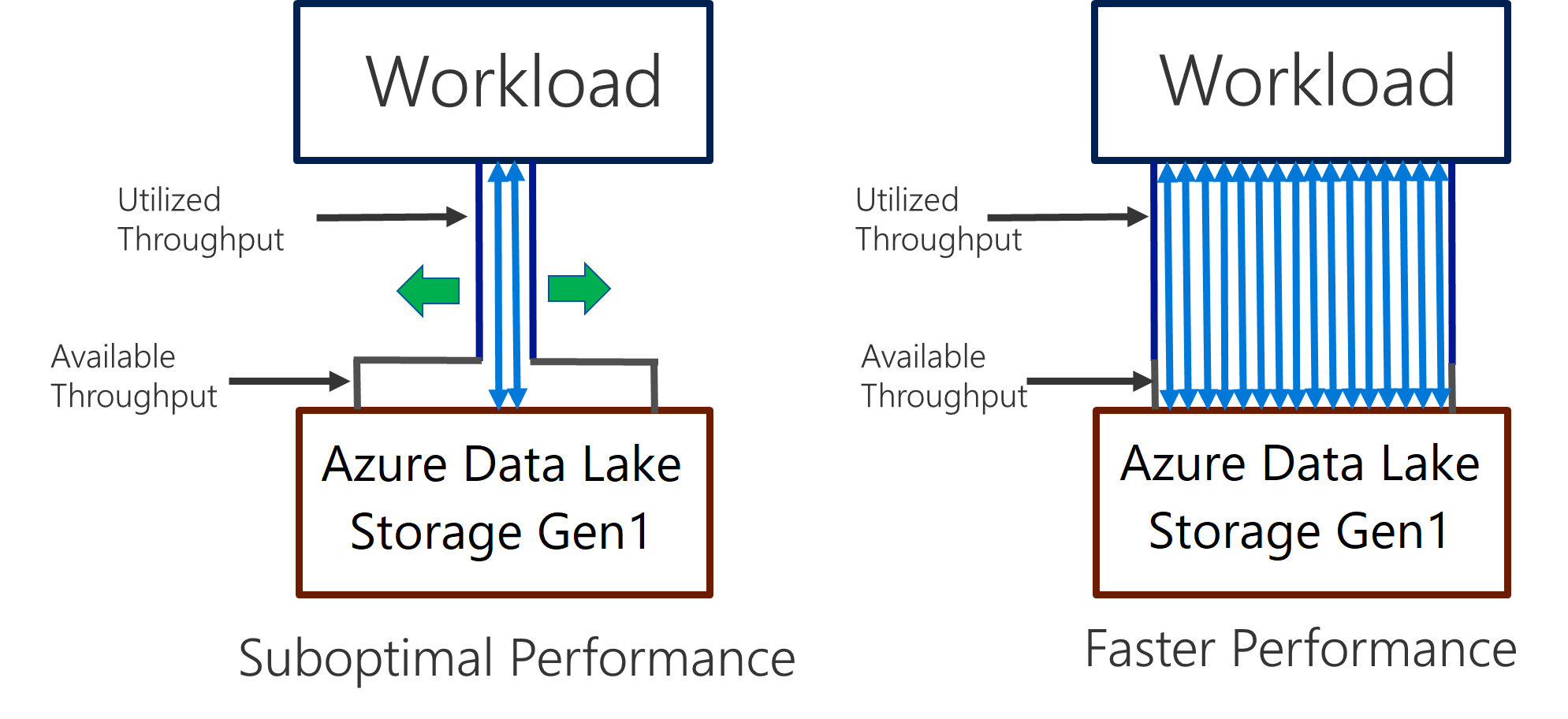
Data Lake Storage Gen1 は、あらゆる分析シナリオで必要とされるスループットを提供するようにスケーリングできます。 既定では、Data Lake Storage Gen1 アカウントは、広範なカテゴリのユース ケースのニーズを満たすのに十分なスループットを自動的に提供します。 お客様が既定の制限に達した場合、Microsoft サポートに連絡して、さらに高いスループットを提供するように Data Lake Storage Gen1 アカウントを構成することができます。
データ インジェスト
ソース システムから Data Lake Storage Gen1 にデータを取り込む場合には、ソース ハードウェア、ソース ネットワーク ハードウェア、Data Lake Storage Gen1 へのネットワークの接続性がボトルネックとなる可能性があることを考慮することが重要です。
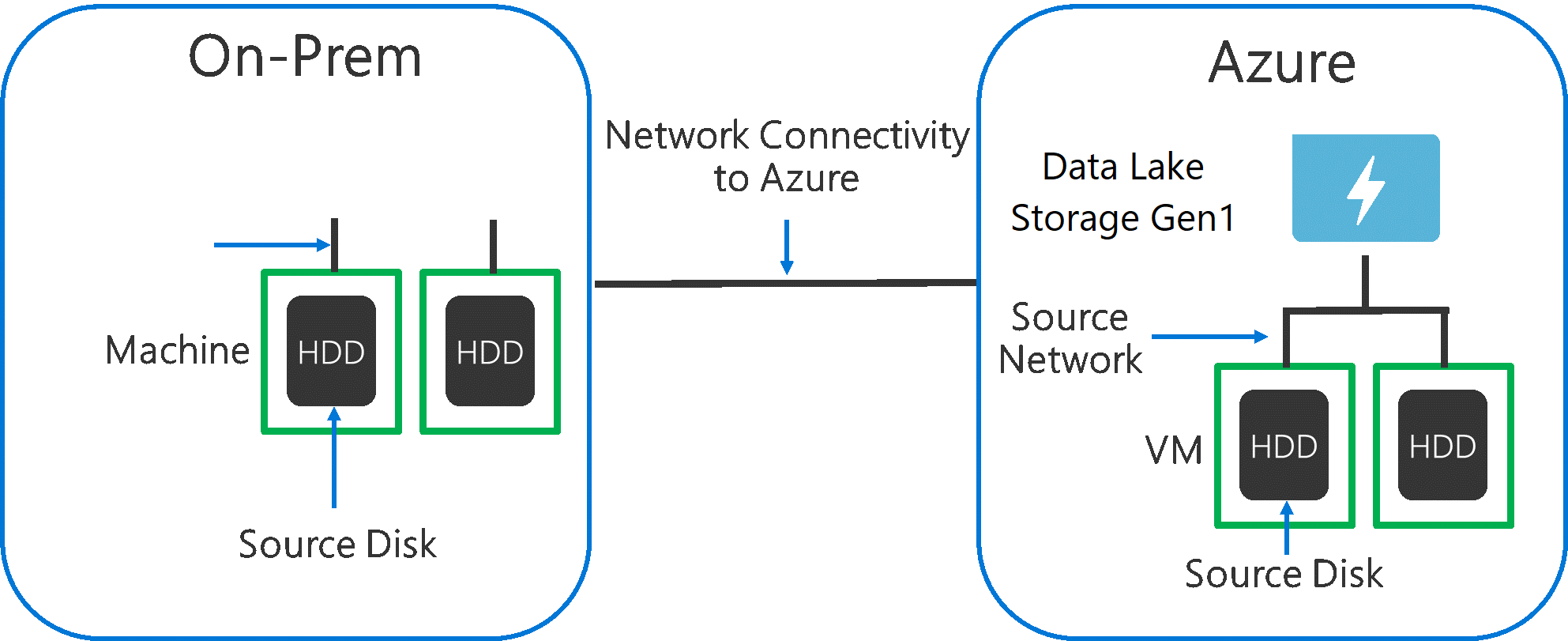
これらの要因がデータの移動に影響を与えないようにすることが重要です。
ソース ハードウェア
オンプレミス マシンを使用しているか、または Azure の VM を使用しているかに関わらず、適切なハードウェアを慎重に選択する必要があります。 ソース ディスク ハードウェアには、HDD よりも SSD を選び、高速スピンドルを備えたディスク ハードウェアをお選びください。 ソース ネットワーク ハードウェアには、考えられる最速の NIC を使用してください。 Azure に関しては、適度に強力なディスクとネットワーク ハードウェアを備えた Azure D14 VM をお勧めします。
Data Lake Storage Gen1 へのネットワーク接続
ソース データと Data Lake Storage Gen1 との間のネットワーク接続はボトルネックになることがあります。 ソース データがオンプレミスの場合、Azure ExpressRoute で専用のリンクを使用することを検討してください。 ソース データが Azure にある場合、データが Data Lake Storage Gen1 アカウントと同じ Azure リージョンにあると、パフォーマンスは最適となります。
データ インジェスト ツールの最大並列化処理の構成
ソース ハードウェアとネットワーク接続性のボトルネックに対処したら、次はデータ インジェスト ツールを構成します。 次の表に、一般的なインジェスト ツールの主要な設定の概要と、それらのパフォーマンス チューニングに関する詳細な記事を示します。 ご自身のシナリオで使用すべきツールの詳細については、この記事をご覧ください。
| ツール | 設定 | 詳細 |
|---|---|---|
| PowerShell | PerFileThreadCount、ConcurrentFileCount | リンク |
| AdlCopy | Azure Data Lake Analytics ユニット | リンク |
| DistCp | -m (マッパー) | リンク |
| Azure Data Factory | parallelCopies | リンク |
| Sqoop | fs.azure.block.size、-m (マッパー) | リンク |
データ セットの構成
データが Data Lake Storage Gen1 に保存されると、ファイル サイズ、ファイル数、フォルダー構造がパフォーマンスに影響を与えるようになります。 次のセクションでは、これらの領域に関するベスト プラクティスについて説明します。
ファイル サイズ
通常、HDInsight や Azure Data Lake Analytics などの分析エンジンでは、ファイルごとのオーバーヘッドがあります。 データを多数の小さなファイルとして保存すると、パフォーマンスに悪影響を及ぼすことがあります。
一般に、パフォーマンスを向上させるには、データをより大きなサイズのファイルにまとめます。 データ セットを 256 MB か、それ以上のサイズのファイルにまとめることが多いでしょう。 画像やバイナリ データなどの場合、並行して処理することはできません。 このような場合は、個々のファイルを 2 GB 未満に維持することをお勧めします。
場合によっては、データ パイプラインで小さなファイルを多数含む生データの制御が制限されることがあります。 ダウンストリーム アプリケーションでは、"調理" のプロセスを設けて、より大きいファイルを生成することをお勧めします。
フォルダー内の時系列データの整理
Hive および ADLA のワークロードでは、時系列データのパーティションを削除すると、一部のクエリがデータのサブセットのみを読み取るようにできるため、パフォーマンスを向上させることができます。
時系列データを取り込むこれらのパイプラインでは、多くの場合、ファイルに構造化されたファイル名やフォルダー名が付けられます。 次に示すのは、日付によって構成されたデータの一般的な例です: \DataSet\YYYY\MM\DD\datafile_YYYY_MM_DD.tsv。
フォルダーとファイル名の両方に、日時の情報が示されていることに注意してください。
日付と時刻については、次に示すのが一般的なパターンです: \DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv。
繰り返しになりますが、フォルダーとファイルの整理については、より大きなファイルサイズに最適化され、各フォルダーに妥当な数のファイルが配置されるような選択を行ってください。
HDInsight の Hadoop および Spark ワークロードでの I/O 集中型ジョブの最適化
ジョブは、大きく次の 3 つのカテゴリに分けられます。
- CPU 集中型 これらのジョブは、計算時間は長くかかりますが、I/O 時間は最小限で済みます。 機械学習や自然言語処理のジョブなどが、その例です。
- メモリ集中型 これらのジョブは、大量のメモリを使用します。 PageRank やリアルタイム分析のジョブなどが、その例です。
- I/O 集中型 これらのジョブは、大半の時間を I/O 処理に費やします。 読み取りおよび書き込み操作のみを行うコピー ジョブなどが一般的な例です。 その他の例には、大量のデータを読み取ってデータ変換を行った後、保存場所に書き戻すデータ準備ジョブなどがあります。
次のガイダンスは、I/O 集中型ジョブにのみ適用されます。
HDInsight クラスターの一般的な考慮事項
- HDInsight のバージョン 最適なパフォーマンスを得るには、HDInsight の最新リリースを使用してください。
- リージョン。 Data Lake Storage Gen1 アカウントは HDInsight クラスターと同じリージョンに配置します。
HDInsight クラスターは、2 つのヘッド ノードと複数のワーカー ノードで構成されます。 各ワーカー ノードは、特定数のコアとメモリを提供します。これは VM の種類によって決まります。 ジョブの実行時には、YARN がリソース ネゴシエーターとなり、コンテナー作成で使用可能なメモリとコアを割り当てます。 各コンテナーは、ジョブを完了するために必要なタスクを実行します。 コンテナーは、タスクを迅速に処理するために並列で実行されます。 そのため、できるだけ多くの並列コンテナーを実行することでパフォーマンスが向上します。
HDInsight クラスター内には 3 つのレイヤーがあります。これらは、コンテナー数を増やし、使用可能なすべてのスループットを使用するようにチューニングできます。
- 物理レイヤー
- YARN レイヤー
- ワークロード レイヤー
物理レイヤー
より多くのノードと大きなサイズの VM、またはそのどちらかで、クラスターを実行します。 次の図に示すように、クラスターを大きくすると、より多くの YARN コンテナーを実行できます。

より大きなネットワーク帯域幅を備えた VM を使用します。 ネットワーク帯域幅が Data Lake Storage Gen1 のスループットよりも小さい場合、ネットワーク帯域幅の容量がボトルネックとなる可能性があります。 VM によって、ネットワーク帯域幅のサイズは異なります。 できる限り大きなネットワーク帯域幅を備えた VM タイプを選択してください。
YARN レイヤー
より小さい YARN コンテナーを使用します。 各 YARN コンテナーのサイズを小さくして、同じ容量のリソースを備えたコンテナーの数を増やします。
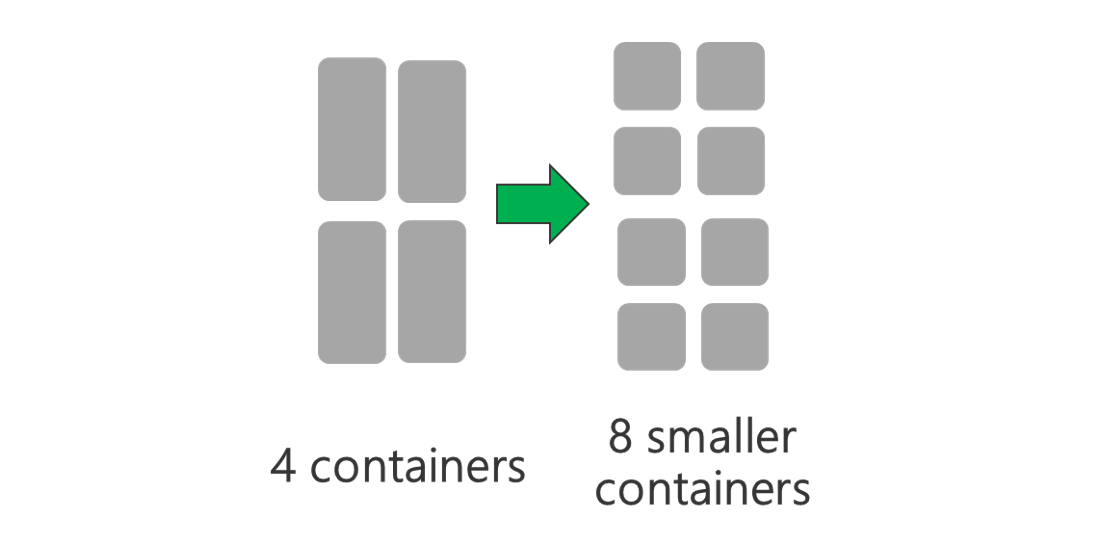
ワークロードによっては、YARN コンテナーが常に必要とする最小サイズが存在します。 選択したコンテナーが小さすぎる場合、ジョブでメモリ不足の問題が発生します。 通常、YARN コンテナーは 1 GB 以上にする必要があります。 3 GB の YARN コンテナーを検討するのが一般的です。 一部のワークロードでは、それよりも大きい YARN コンテナーが必要な場合もあります。
YARN コンテナーあたりのコア数を増やします。 各コンテナーで実行される並列タスクの数を増やすには、各コンテナーに割り当てるコアの数を増やします。 これは、コンテナーごとに複数のタスクを実行する Spark のようなアプリケーションで有効です。 各コンテナーで単一スレッドを実行する Hive のようなアプリケーションでは、コンテナーごとのコア数を増やすよりもコンテナー数を増やすことをお勧めします。
ワークロード レイヤー
使用可能なすべてのコンテナーを使用します。 すべてのリソースが使用されるように、タスク数を使用可能なコンテナー数と同じ数、またはそれ以上に設定します。
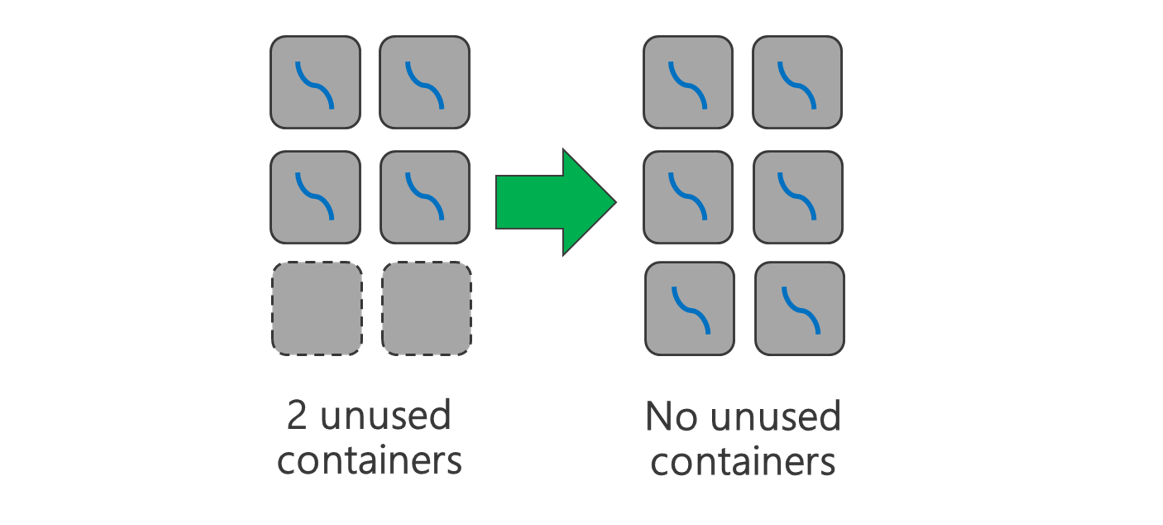
タスクでエラーが発生するとコストがかかります。 各タスクで大量のデータを処理すると、タスクでエラーが発生した場合、再試行に高いコストがかかることになります。 そのため、多数のタスクを作成し、各タスクで少量のデータを処理するようにすることをお勧めします。
上記の一般的なガイドラインに加え、各アプリケーションには、チューニングで使用できるアプリケーション固有のさまざまなパラメーターがあります。 次の表に、パラメーターの一部と、各アプリケーションでパフォーマンス チューニングを開始するためのリンクを示します。
| ワークロード | タスク数を設定するパラメーター |
|---|---|
| HDInsight 上の Spark |
|
| HDInsight の Hive |
|
| HDInsight の MapReduce |
|
| HDInsight の Storm |
|