Azure Databricks のようなクラウド ネイティブの Data Analytics プラットフォームにとって、明確なディザスター リカバリー パターンは非常に重要です。 データ チームが Azure Databricks プラットフォームを使用できることは、ハリケーンや地震などの地域的な災害や別のソースによって引き起こされる場合でも、リージョン全体のクラウド サービス プロバイダーが停止するまれなケースでも使用できることです。
多くの場合、Azure Databricks は、アップストリーム データ インジェスト サービス (バッチ/ストリーミング)、ADLS などのクラウド ネイティブ ストレージ (2023 年 3 月 6 日より前に作成されたワークスペース、Azure Blob Storage 用)、ビジネス インテリジェンス アプリなどのダウンストリーム ツールとサービス、オーケストレーション ツールなど、多くのサービスを含む、全体的なデータ エコシステムの中核となる部分です。 ユース ケースによっては、地域的なサービス全体の停止にとりわけ影響を受けやすい場合があります。
この記事では、Databricks プラットフォームのリージョンをまたがるディザスター リカバリー ソリューションを成功に導くための概念とベスト プラクティスについて説明します。
リージョン内の高可用性の保証
このトピックの残りの部分では、リージョン間のディザスター リカバリーの実装に焦点を当てていますが、Azure Databricks が単一リージョン内で提供する高可用性の保証を理解することが重要です。 リージョン内の高可用性の保証には、次のコンポーネントが含まれます。
Databricks コントロール プレーンの可用性
Databricks コントロール プレーンはゾーン障害に対する回復性があり、ゾーン障害から約 15 分以内に自動的に回復する必要があります。 定期的なゾーン 障害テストでこれを検証します。
すべてのステートレス コントロール プレーン サービスは、ゾーン全体のすべての VM だけでなく、個々の VM の損失を自動的に処理できます。 ワークスペース データは、リージョン内のゾーン間でレプリケートされたデータベースに格納されます。 Databricks ランタイム イメージの提供に使用されるストレージ アカウントもリージョン内で冗長であり、すべてのリージョンにはプライマリがダウンしたときに使用されるセカンダリ ストレージ アカウントがあります。 「Azure Databricks のリージョン」を参照してください。
ゾーン障害の回復性では、ダウンしているゾーンが最大 1 つだけサポートされ、複数のゾーンをサポートする Azure リージョンでのみ使用できます。
コンピューティング プレーンの可用性
ワークスペースの可用性は、コントロール プレーンの可用性に依存します (前述のとおり)。 DBFS ルートのストレージ アカウントがゾーン冗長ストレージ (ZRS) または Geo ゾーン冗長ストレージ (GZRS) (既定は Geo 冗長ストレージ (GRS)) で構成されている場合、DBFS ルート上のデータは影響を受けません。
クラスターのノードは、Azure コンピューティング プロバイダーからノードを要求することによって、異なる可用性ゾーンからプルされます (残りのゾーンの容量が要求を満たすために十分な場合)。 ノードが失われた場合、クラスター マネージャーが Azure コンピューティング プロバイダーに交換ノードを要求し、それによって使用可能な AZ からノードがプルされます。 唯一の例外は、ドライバー ノードが失われた場合です。 この場合、クラスター マネージャーはジョブとクラスターを再起動します。
ディザスター リカバリーの概要
ディザスター リカバリーには、自然または人による災害の後に重要なテクノロジ インフラストラクチャとシステムの復旧または継続を可能にする一連のポリシー、ツール、手順が含まれます。 Azure のような大規模クラウド サービスは、多くの顧客にサービスを提供し、1 つの障害に対する保護機能が組み込まれています。 たとえば、リージョンは複数の異なる電源に接続した建物のグループであり、その目的は、1 つの電源が失われてもリージョンがシャットダウンしないことの保証です。 それでも、クラウド リージョンの障害は起こりうるものであり、中断の程度や組織への影響はさまざまです。
ディザスター リカバリー計画を実装する前に、 ディザスター リカバリー (DR) と 高可用性 (HA) の違いを理解することが重要です。
高可用性は、システムの回復性の特性です。 高可用性は、安定した稼働時間または稼働時間の割合で定義されるのが通例である最小レベルの運用パフォーマンスを保証するものです。 高可用性は、プライマリ システムの機能として設計することによって (プライマリ システムと同じリージョンに) 実装されます。 たとえば、Azure などのクラウド サービスには、ADLS などの高可用性サービスがあります (2023 年 3 月 6 日より前に作成されたワークスペースの場合、Azure Blob Storage)。 高可用性は、大規模で明示的な準備を Azure Databricks の顧客に要求するものではありません。
これに対し、ディザスター リカバリー計画には、クリティカルなシステムがリージョンのレベルで大規模に停止する事態に対処するために、特定の組織にとって有効である意思決定とソリューションが必要です。 この記事では、一般的なディザスター リカバリーの用語、一般的なソリューション、Azure Databricks を使用したディザスター リカバリー計画のベスト プラクティスについて説明します。
用語
リージョンの用語
この記事では、リージョンに関して次の定義を使用します。
プライマリ リージョン: 一般的で日常的な Data Analytics ワークロードを、ユーザーが対話形式および自動化された形式で実行する地理的リージョン。
セカンダリ リージョン: プライマリ リージョンの停止中に IT チームが Data Analytics ワークロードを一時的に移動する地理的リージョン。
geo 冗長ストレージ: Azure では、非同期のストレージ レプリケーション プロセスを使用したストレージ永続化のために、リージョン横断の geo 冗長ストレージが用意されています。
重要
ディザスター リカバリー プロセスの場合、Databricks では、Azure サブスクリプション内の各ワークスペースに対して Azure Databricks によって作成される ADLS (2023 年 3 月 6 日より前に作成されたワークスペース、Azure Blob Storage) などのデータのリージョン間重複に geo 冗長ストレージを使用 しないことを お勧めします。 一般に、差分テーブルにはディープ クローンを使用し、データを Delta 形式に変換して、可能であれば他のデータ形式に対して Deep Clone を使用します。
デプロイ状態の用語
この記事では、デプロイ状態について次の定義を使用します。
アクティブ デプロイ: ユーザーは、Azure Databricks ワークスペースのアクティブ デプロイに接続してワークロードを実行できます。 ジョブは、Azure Databricks スケジューラまたはその他のメカニズムを使用して定期的にスケジュールされます。 このデプロイでは、データ ストリームを実行することもできます。 ドキュメントによっては、アクティブ デプロイはホット デプロイとも呼ばれます。
パッシブ デプロイ: プロセスはパッシブ デプロイでは実行されません。 IT チームは、コード、構成、その他の re:[Databricks] オブジェクトをパッシブデプロイにデプロイするための自動化された手順を設定できます。 このデプロイは、現在のアクティブ デプロイがダウンしている場合にのみアクティブになります。 ドキュメントによっては、パッシブ デプロイはコールド デプロイとも呼ばれます。
重要
プロジェクトでは、必要に応じて、異なるリージョンに複数のパッシブ デプロイを含めて、リージョンの停止を解決するための選択肢を増やすことができます。
通常、チームはアクティブ/ パッシブ ディザスター リカバリー戦略と呼ばれるアクティブなデプロイを一度に 1 つだけ持ちます。 あまり一般的ではありませんが、2 つのアクティブ デプロイを同時に運用する、アクティブ/アクティブと呼ばれるディザスター リカバリー ソリューション戦略もあります。
ディザスター リカバリーの業界用語
2 つの重要な業界用語を理解し、チームのために定義する必要があります。
目標復旧時点: 目標復旧時点 (RPO) は、メジャー インシデントの発生時に、超過すると IT サービスからデータ (トランザクション) が失われる可能性がある最長の目標期間です。 Azure Databricks デプロイには、メインの顧客データは格納されません。 これは、ADLS (2023 年 3 月 6 日より前に作成されたワークスペース、Azure Blob Storage) などの別のシステムや、管理下にある他のデータ ソースに格納されます。 Azure Databricks コントロール プレーンには、ジョブやノートブックなどの一部のオブジェクトが部分的または完全に格納されます。 Azure Databricks の場合、RPO は、ジョブやノートブックの変更などのオブジェクトが失われる可能性がある最大ターゲット期間として定義されます。 また、ADLS (2023 年 3 月 6 日より前に作成されたワークスペース、Azure Blob Storage) またはその他のデータ ソースの管理下で、独自の顧客データの RPO を定義する必要があります。
目標復旧時間: 目標復旧時間 (RTO) は、災害発生後にビジネス プロセスを復旧しなければならない期限を表す時間とサービス レベルの目標です。
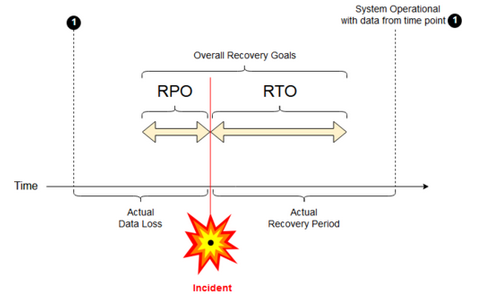
ディザスター リカバリーとデータの破損
ディザスター リカバリー ソリューションは、データの破損を軽減するものではありません。 プライマリ リージョンで破損したデータは、プライマリ リージョンからセカンダリ リージョンにレプリケートされ、両方のリージョンで破損します。 この種の障害を軽減する、Delta タイム トラベルのようなその他の方法があります。
一般的な復旧ワークフロー
Azure Databricks のディザスター リカバリー シナリオは通常、次のように進行します。
プライマリ リージョンで使用しているクリティカルなサービスで障害が発生します。 これは、Azure Databricks のデプロイに影響を及ぼすデータ ソース サービスまたはネットワークである可能性があります。
クラウド プロバイダーと協力して状況を調査します。
会社がプライマリ リージョンで問題が修復されるのを待てない場合は、セカンダリ リージョンにフェールオーバーすることを決定できます。
同じ問題の影響がセカンダリ リージョンには及ばないことを確認します。
セカンダリ リージョンにフェールオーバーします。
- ワークスペース内のすべてのアクティビティを停止します。 ユーザーがワークロードを停止します。 ユーザーまたは管理者は、可能であれば最近の変更のバックアップを取るように指示されます。 停止のため、ジョブがすでに失敗していない場合は、シャットダウンされます。
- セカンダリ リージョンで復旧手順を開始します。 復旧手順では、ルーティングを更新し、セカンダリ リージョンへの接続とネットワーク トラフィックの名前を変更します。
- テストが終了したら、セカンダリ リージョンの稼働を宣言します。 これで、実稼働ワークロードを再開できます。 ユーザーは、新しくアクティブになったデプロイにログインできます。 スケジュールまたは遅延していたジョブをもう一度トリガーできます。
Azure Databricks コンテキストでの詳細な手順については、「フェールオーバーのテスト」を参照してください。
ある時点で、プライマリ リージョンの問題が軽減され、この事実を確認します。
プライマリ リージョンに復元 (フェールバック) します。
- セカンダリ リージョンでのすべての作業を中止します。
- プライマリ リージョンで復旧手順を開始します。 復旧手順では、プライマリ リージョンへの接続とネットワーク トラフィックのルーティングと名前変更が処理されます。
- 必要に応じて、プライマリ リージョンにデータをレプリケートします。 複雑さを減らすために、レプリケートする必要があるデータの量を最小限にします。 たとえば、セカンダリ デプロイでの実行時に読み取り専用であるジョブに関しては、そのデータをプライマリ リージョンのプライマリ デプロイにレプリケートする必要はないかもしれません。 ただし、1 つの運用ジョブを実行する必要があり、プライマリ リージョンへのデータ レプリケーションが必要な場合があります。
- プライマリ リージョンでデプロイをテストします。
- プライマリ リージョンが稼働状態であり、アクティブ デプロイであることを宣言します。 実稼働ワークロードを再開します。
プライマリ リージョンへの復元の詳細については、「 復元のテスト (フェールバック)」を参照してください。
重要
これらの手順の間に、データの損失が発生する可能性があります。 組織では、許容できるデータ損失の規模と、この損失を軽減するための可能な対策を定義する必要があります。
ステップ 1: ビジネス ニーズを理解する
最初のステップは、ビジネス ニーズを定義して理解することです。 クリティカルなデータ サービスと、各サービスの RPO と RTO の期待値を定義します。
各システムの実際の許容度を調査します。 ディザスター リカバリー、フェールオーバー、フェールバックはコストがかかり、他のリスクを伴う可能性があることを覚えておいてください。 その他のリスクとしては、データの破損、データの重複 (間違ったストレージの場所に書き込む場合)、間違った場所にログインして変更を加えたユーザーなどがあります。
ビジネスに影響を与えるすべての Azure Databricks 統合ポイントをマップします。
- ディザスター リカバリー ソリューションで、対話型プロセス、自動化されたプロセス、またはその両方に対応する必要がありますか?
- どのデータ サービスを使用していますか? 一部はオンプレミスである可能性があります。
- 入力データはどのようにしてクラウドに到達しますか?
- 誰がこのデータを使用しますか? ダウンストリームではどのプロセスが使用しますか?
- ディザスター リカバリーの変更を認識する必要があるサードパーティの統合はありますか?
ディザスター リカバリー計画をサポートできるツールまたはコミュニケーション戦略を決定します。
- ネットワーク構成をすばやく変更するために、どのツールを使用しますか?
- 自然で保守しやすい形でディザスター リカバリー ソリューションを組み込めるよう、構成を事前に定義し、モジュール化することができますか?
- ディザスター リカバリーのフェールオーバーとフェールバックの変更について、内部チームとサード パーティ (統合、ダウンストリーム コンシューマー) に通知する通信ツールとチャネルはどれですか? どのように彼らの確認を確認しますか?
- どのようなツールまたは特別なサポートが必要になりますか?
- 完全な復旧が行われるまで、どのようなサービスがシャットダウンされますか?
ステップ 2: ビジネス ニーズを満たすプロセスを選択する
ソリューションでは、コントロール プレーン、コンピューティング プレーン、およびデータ ソース内の正しいデータをレプリケートする必要があります。 ディザスター リカバリー用の冗長ワークスペースは、リージョンによって異なるコントロール プレーンにマップする必要があります。 同期 ツールまたは CI/CD ワークフローのいずれかのスクリプト ベースのソリューションを使用して、データの同期を定期的に維持する必要があります。 コンピューティング プレーン ネットワーク自体の内部から (例: Databricks Runtime ワーカーから) データを同期する必要はありません。
VNet インジェクション機能 (すべてのサブスクリプションとデプロイの種類で使用できるわけではありません) を使用する場合、Terraform のようなテンプレートベースのツールを使用して、両方のリージョンにこれらのネットワークを整合性のある形でデプロイすることができます。
さらに、データ ソースが必要に応じてリージョン間でレプリケートされることを保証する必要があります。
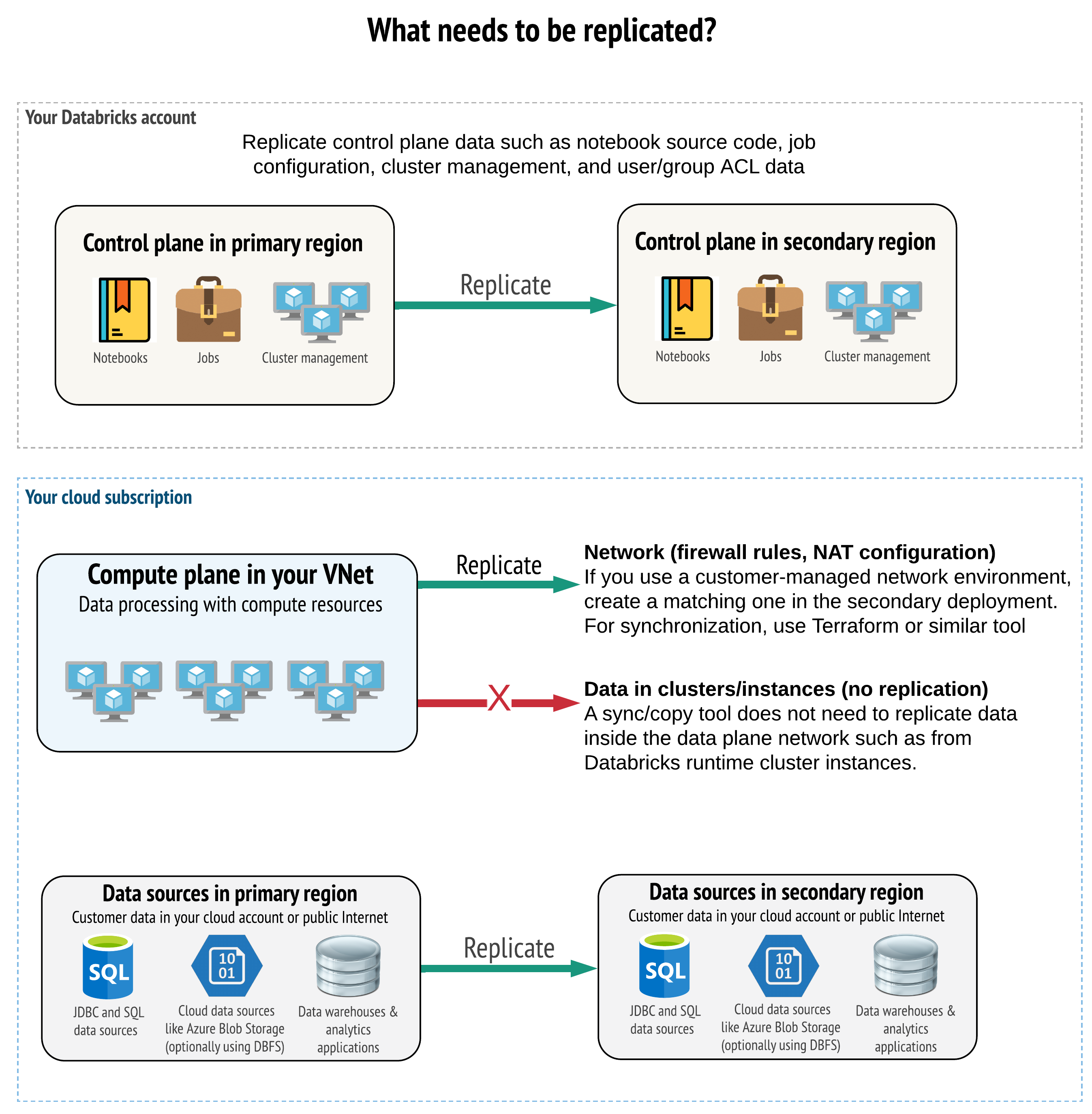
一般的なベスト プラクティス
ディザスター リカバリー計画を成功に導くための一般的なベスト プラクティスには、以下のものがあります。
ビジネスにとって重要であり、ディザスター リカバリーで実行する必要があるプロセスを理解します。
関係するサービス、処理されているデータ、データ フローの内容、格納場所を明確に特定します。
可能な限りサービスとデータを分離します。 たとえば、ディザスター リカバリー用のデータのために特別なクラウド ストレージ コンテナーを作成するか、災害時に必要な Azure Databricks オブジェクトを別のワークスペースに移動します。
Databricks コントロール プレーンに格納されていないその他のオブジェクトに関して、プライマリ デプロイとセカンダリ デプロイの間で整合性を維持する必要があります。
警告
ベスト プラクティスは、ワークスペースの DBFS ルート アクセスに使用されるルート ADLS (2023 年 3 月 6 日より前に作成されたワークスペース、Azure Blob Storage の場合) にデータを格納しないことをお勧めします。 DBFS ルート ストレージは、運用環境の顧客データではサポートされていません。 また、Databricks では、ライブラリ、構成ファイル、または init スクリプトをこの場所に格納しないことをお勧めします。
データ ソースの場合は、可能であれば、レプリケーションと冗長性のためにネイティブ Azure ツールを使用して、ディザスター リカバリー リージョンにデータをレプリケートすることをお勧めします。
リカバリー ソリューションの戦略を選択する
典型的なディザスター リカバリー ソリューションには、2 つ (以上) のワークスペースが関係します。 いくつかの戦略から選択できます。 中断の潜在的な長さ (数時間または 1 日)、ワークスペースが完全に動作していることを確認する作業、プライマリ リージョンに復元 (フェールバック) する作業を検討します。
アクティブ/パッシブ ソリューションの戦略
アクティブ/パッシブ ソリューションは最も一般的で、最も簡単なソリューションであり、この記事ではこの種類のソリューションに焦点を当てます。 アクティブ/パッシブ ソリューションでは、アクティブ デプロイからパッシブ デプロイにデータとオブジェクトの変更を同期します。 必要に応じて、異なるリージョンに複数のパッシブ デプロイを配置することもできますが、この記事ではパッシブ デプロイを 1 つにするアプローチに焦点を当てます。 ディザスター リカバリーイベント中は、セカンダリ リージョンのパッシブ デプロイがアクティブ デプロイになります。
この戦略には主に 2 つのバリエーションがあります。
- 統合 (エンタープライズ向け) ソリューション: 組織全体をサポートするアクティブおよびパッシブデプロイの 1 つのセットです。
- 部門またはプロジェクト別のソリューション: 部門またはプロジェクトのドメインごとに個別のディザスター リカバリー ソリューションを維持します。 部門間でディザスター リカバリーの詳細を分離し、各チーム固有のニーズに基づいてチームごとに異なるプライマリ リージョンとセカンダリ リージョンを使用したいと考える組織もあります。
読み取り専用のユース ケースにはパッシブ デプロイを使用するなど、その他のバリエーションもあります。 ユーザー クエリなど、読み取り専用のワークロードがある場合、データやノートブックやジョブなどの Azure Databricks オブジェクトを変更しない場合は、パッシブ ソリューションでいつでも実行できます。
アクティブ/アクティブ ソリューションの戦略
アクティブ/アクティブ ソリューションでは、両方のリージョンのすべてのデータ プロセスを常に並列実行します。 運用チームは、ジョブなどのデータ プロセスについて、両方のリージョンで正常に終了した時点ではじめて完了とマークされることを保証する必要があります。 オブジェクトは実稼働では変更できず、開発/ステージングから実稼働への厳密な CI/CD 昇格に従う必要があります。
アクティブ/アクティブ ソリューションは最も複雑な戦略であり、両方のリージョンでジョブが実行されるため、追加の財務コストが発生します。
アクティブ/パッシブ戦略と同様、これは統合型の組織ソリューションとして、または部門別に実装できます。
ワークフローによっては、すべてのワークスペースについてセカンダリ システムに同等のワークスペースが必要ではない場合があります。 たとえば、開発またはステージングのワークスペースは複製が不要な場合があります。 開発パイプラインの設計が適切であれば、必要に応じてこれらのワークスペースを簡単に再構築できる場合があります。
ツールを選択する
プライマリ リージョンとセカンダリ リージョンのワークスペース間でデータの類似性をできる限り保持するためのツールには、主に 2 つのアプローチがあります。
- プライマリからセカンダリにコピーする同期クライアント: 同期クライアントは、プライマリ リージョンからセカンダリ リージョンに運用データと資産をプッシュします。 通常、これはスケジュールに基づいて実行されます。
- 並列デプロイ用の CI/CD ツール: 実稼働のコードとアセットに対して、実稼働システムへの変更を両方のリージョンに同時にプッシュする CI/CD ツールを使用します。 たとえば、ステージング/開発から実稼働にプッシュされたコードとアセットは、CI/CD システムの働きによって同時に、両方のリージョンで使用可能になります。 中核となる考え方は、Azure Databricks ワークスペース内のすべての成果物を infrastructure-as-code (コードとしてのインフラストラクチャ) として扱うことです。 ほとんどの成果物はプライマリとセカンダリ両方のワークスペースに同時デプロイできますが、ディザスター リカバリーイベントの終了後にしかデプロイできない成果物もあります。 ツールについては、「オートメーション スクリプト、サンプル、プロトタイプ」を参照してください。
次の図は、これら 2 つのアプローチを対比しています。
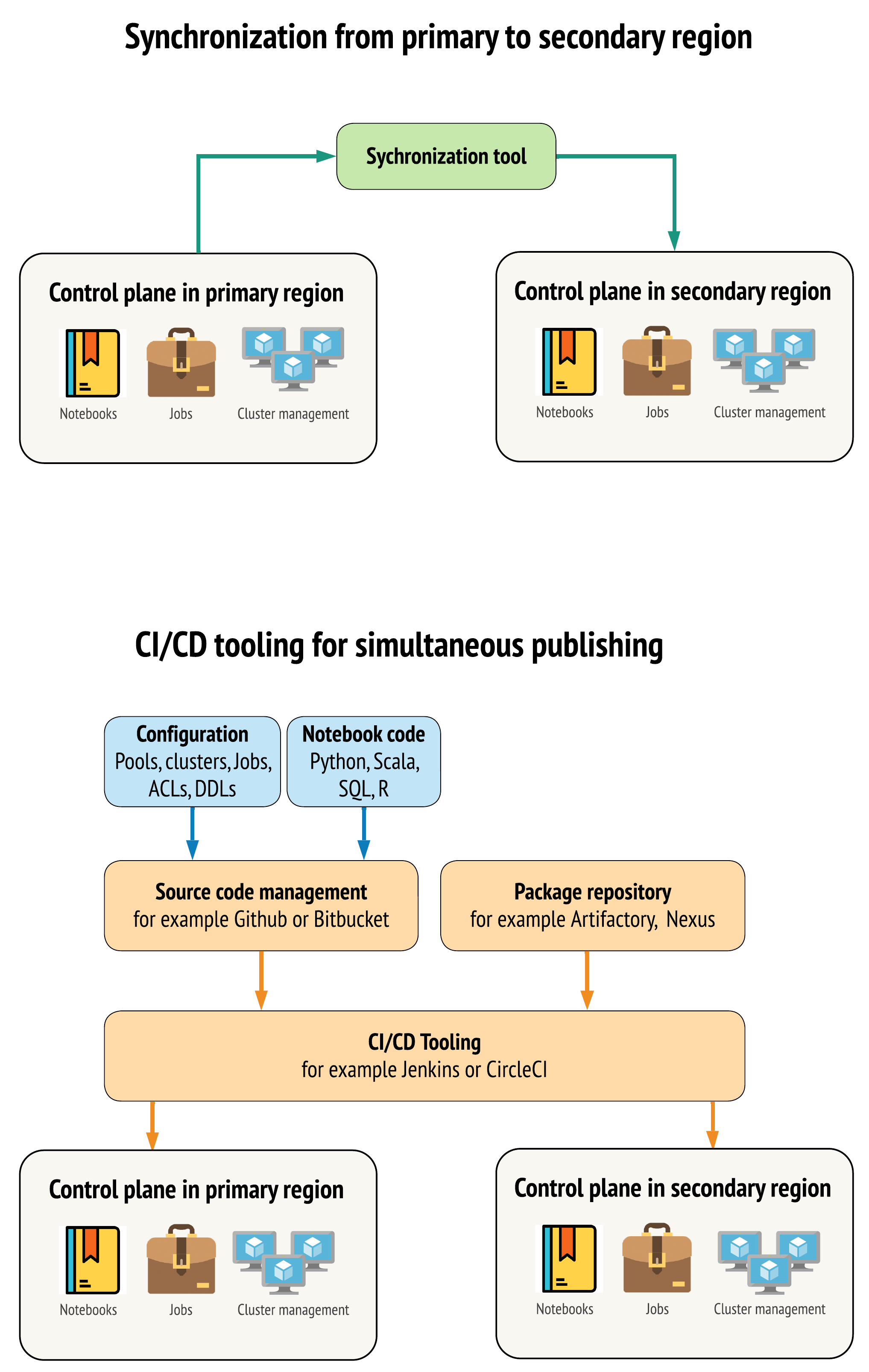
ニーズに応じて、アプローチを組み合わせることができます。 たとえば、ノートブックのソース コードには CI/CD を使用し、プールやアクセス制御などの構成には同期を使用します。
次の表では、各ツール オプションを使用してさまざまな種類のデータを処理する方法について説明します。
| 説明 | CI/CD ツールでの処理方法 | 同期ツールを使用して処理する方法 |
|---|---|---|
| ソース コード: ノートブック ソースのエクスポートとパッケージ化されたライブラリのソース コード | プライマリとセカンダリの両方に同時デプロイします。 | プライマリからセカンダリにソース コードを同期します。 |
| ユーザーとグループ | Git でメタデータを構成として管理します。 または、両方のワークスペースに同じ ID プロバイダー (IdP) を使用します。 ユーザーとグループのデータをプライマリ デプロイとセカンダリ デプロイに同時デプロイします。 | 両方のリージョンで SCIM またはその他の自動化を使用します。 手動作成は "非推奨" ですが、使用する場合は両方で同時に行う必要があります。 手動セットアップを使用する場合は、スケジュールされた自動プロセスを作成して、2 つのデプロイ間のユーザーとグループの一覧を比較します。 |
| プール構成 | Git でテンプレートにすることができます。 プライマリとセカンダリに同時デプロイします。 ただし、セカンダリの min_idle_instances は、ディザスター リカバリー イベントまではゼロである必要があります。 |
API または CLI を使用してセカンダリ ワークスペースに同期されるときに、任意の min_idle_instances で作成されたプール。 |
| ジョブの構成 | Git でテンプレートにすることができます。 プライマリ デプロイの場合、ジョブ定義をそのままデプロイします。 セカンダリ デプロイの場合は、ジョブをデプロイし、コンカレンシーを 0 に設定します。 これにより、このデプロイでジョブが無効になり、余計な実行を防止します。 セカンダリ デプロイがアクティブになったら、コンカレンシーの値を変更します。 | ジョブが何らかの理由で既存の <interactive> クラスターで実行される場合、同期クライアントはセカンダリ ワークスペース内の対応する cluster_id にマップする必要があります。 |
| アクセス制御リスト (ACL) | Git でテンプレートにすることができます。 ノートブック、フォルダー、クラスターの場合、プライマリ デプロイとセカンダリ デプロイに同時デプロイします。 ただし、ディザスター リカバリー イベントまではジョブのデータを保持します。 | Permissions API では、クラスター、ジョブ、プール、ノートブック、およびフォルダーのアクセス制御を設定できます。 同期クライアントは、セカンダリ ワークスペース内の各オブジェクトの対応するオブジェクト ID にマップする必要があります。 Databricks では、アクセス制御をレプリケートする "前" に、これらのオブジェクトの同期と並行して、プライマリ ワークスペースからセカンダリ ワークスペースへのオブジェクト ID のマップを作成することが推奨されています。 |
| ライブラリ | ソース コードとクラスター/ジョブ テンプレートに含めます。 | 一元化されたリポジトリ、DBFS、またはクラウド ストレージからカスタム ライブラリを同期します (マウントできます)。 |
| クラスター初期化スクリプト | 必要に応じて、ソース コードに含めます。 | より簡単な同期を行う場合は、可能であれば、プライマリ ワークスペースの共通フォルダーまたは少数のフォルダーに init スクリプトを格納します。 |
| マウント ポイント | ノートブックベースのジョブまたはコマンド API のみを使用して作成された場合は、ソース コードに含めます。 | Azure Data Factory (ADF) アクティビティとして実行できるジョブを使用します。 ワークスペースが異なるリージョンにある場合、ストレージのエンドポイントが変わる可能性があることに注意してください。 これは、データのディザスター リカバリー戦略にも大きく依存します。 |
| テーブル メタデータ | ノートブックベースのジョブまたはコマンド API のみを使用して作成された場合は、ソース コードと共に含めます。 これは、内部の Azure Databricks メタストアと、外部で構成されたメタストアのどちらにも当てはまります。 | Spark Catalog API を使用してメタストア間のメタデータ定義を比較するか、ノートブックまたはスクリプトを使用してテーブルの作成を表示します。 基になるストレージのテーブルはリージョンベースにすることができ、メタストア インスタンス間で異なる点に注意してください。 |
| シークレット | コマンド API のみを使用して作成された場合は、ソース コードに含めます。 一部のシークレット コンテンツについては、プライマリとセカンダリの間で変更が必要な場合があることに注意してください。 | シークレットは、API を使用して両方のワークスペースに作成されます。 一部のシークレット コンテンツについては、プライマリとセカンダリの間で変更が必要な場合があることに注意してください。 |
| クラスター構成 | Git でテンプレートにすることができます。 プライマリ デプロイとセカンダリ デプロイに同時デプロイしますが、セカンダリ デプロイではディザスター リカバリーイベントまで終了する必要があります。 | クラスターは、API または CLI を使用してセカンダリ ワークスペースに同期された後に作成されます。 自動終了の設定によっては、必要に応じて明示的に終了することができます。 |
| ノートブック、ジョブ、フォルダーのアクセス許可 | Git でテンプレートにすることができます。 プライマリ デプロイとセカンダリ デプロイに同時デプロイします。 | Permissions API を使用してレプリケートします。 |
リージョンと複数のセカンダリ ワークスペースを選択する
ディザスター リカバリー トリガーを完全に制御できる必要があります。 いつでも、どのような理由でも、これをトリガーすることを決定できます。 フェールバック (通常の運用) モードで操作を再開する前に、ディザスター リカバリーの安定化に責任を持つ必要があります。 通常、これは、運用とディザスター リカバリーのニーズに対応するために複数の Azure Databricks ワークスペースを作成し、セカンダリ フェールオーバー リージョンを選択する必要があることを意味します。
Azure で、使用可能な製品と VM の種類に加えて、データ レプリケーションを確認します。
ステップ 3: ワークスペースを準備して 1 回限りのコピーを実行する
ワークスペースが既に実稼働である場合、1 回限りのコピー操作を実行して、パッシブ デプロイをアクティブ デプロイと同期させるのが一般的です。 この 1 回限りのコピーにより、以下が処理されます。
- データ レプリケーション: クラウド レプリケーション ソリューションまたは Delta Deep Clone 操作を使用してレプリケートします。
- トークン生成: トークン生成を使用して、レプリケーションと将来のワークロードを自動化します。
- ワークスペース レプリケーション: 「ステップ 4 : データ ソースを準備する」で説明されている方法を使用して、ワークスペース レプリケーションを使用します。
- ワークスペースの検証: -ワークスペースとプロセスが正常に実行され、期待どおりの結果が得られることを確認するためのテストを行います。
最初の 1 回限りのコピー操作の後、後続のコピー操作と同期操作が高速になります。 ツールからのログ記録には、変更の内容とタイミングも記録されます。
ステップ 4: データ ソースを準備する
Azure Databricks では、バッチ処理またはデータ ストリームを使用して、さまざまなデータ ソースを処理できます。
データ ソースからのバッチ処理
データがバッチ処理される場合、通常は、簡単にレプリケートしたり、別のリージョンに配信したりできるデータ ソースに存在します。
たとえば、クラウド ストレージの場所にデータが定期的にアップロードされる場合があります。 セカンダリ リージョンのディザスター リカバリー モードでは、ファイルがセカンダリ リージョン ストレージにアップロードされることを確認する必要があります。 ワークロードは、セカンダリ リージョン ストレージから読み取り、セカンダリ リージョン ストレージに書き込む必要があります。
データ ストリーム
データ ストリームの処理は、より大きな課題です。 ストリーミング データは、さまざまなソースから取り込み、処理し、ストリーミング ソリューションに送信できます。
- Kafka などのメッセージ キュー
- データベース変更データ キャプチャ ストリーム
- ファイルベースの連続処理
- ファイルベースのスケジュールされた処理 (トリガー ワンスとも呼ばれる)
以上のいずれの場合も、ディザスター リカバリー モードを処理し、セカンダリ リージョンのセカンダリ デプロイを使用するようにデータ ソースを構成する必要があります。
ストリーム ライターは、処理されたデータに関する情報をチェックポイントに格納します。 このチェックポイントにはデータの場所 (通常はクラウド ストレージ) を含めることができ、ストリームの再起動が確実に成功するよう、この場所を新しい場所に変更する必要があります。 たとえば、チェックポイント配下の source サブフォルダーには、ファイルベースのクラウド フォルダーが格納されている場合があります。
このチェックポイントを、適切なタイミングでレプリケートする必要があります。 チェックポイントの間隔を新しいクラウド レプリケーション ソリューションと同期することを検討してください。
チェックポイントの更新はライターの機能であるため、データ ストリームの取り込みまたは処理、および別のストリーミング ソースへの格納に適用されます。
ストリーミング ワークロードの場合、顧客が管理するストレージでチェックポイントが構成されていることを確認して、最後の障害の時点からワークロードを再開するためにチェックポイントをセカンダリ リージョンにレプリケートできるようにします。 プライマリ プロセスと並行してセカンダリ ストリーミング プロセスを実行することもできます。
ステップ 5: ソリューションを実装してテストする
ディザスター リカバリーのセットアップを定期的にテストして、正しく機能することを確認します。 ディザスター リカバリー ソリューションを必要なときに使用できない場合、ディザスター リカバリー ソリューションを維持しても価値はありません。 企業によっては、数か月ごとにリージョンを切り替えます。 定期的なスケジュールでリージョンを切り替えることによって、想定とプロセスをテストし、それらが復旧のニーズを満たしていることを確認できます。 これにより、緊急事態に備えたポリシーと手順を組織が理解していることも保証されます。
重要
現実的な条件下でディザスター リカバリー ソリューションを定期的にテストしてください。
オブジェクトまたはテンプレートが見つからない場合でも、プライマリ ワークスペースに格納されている情報に依存する必要がある場合は、計画を変更してこれらの障害を取り除くか、セカンダリ システムでこの情報をレプリケートするか、他の方法で使用できるようにします。
プロセスと構成全般に必要な組織の変更をテストします。 ディザスター リカバリー計画はデプロイ パイプラインに影響を与えます。同期する必要がある内容をチームが認識することが重要です。ディザスター リカバリー ワークスペースを設定したら、インフラストラクチャ (手動またはコード)、ジョブ、ノートブック、ライブラリ、およびその他のワークスペース オブジェクトがセカンダリ リージョンで使用できることを確認する必要があります。
標準の作業プロセスと構成パイプラインを拡張してすべてのワークスペースに変更をデプロイする方法について、チームと相談してください。 すべてのワークスペースでユーザー ID を管理します。 ジョブの自動化や新しいワークスペースの監視などのツールを忘れずに構成してください。
構成ツールの変更を計画し、テストします。
- インジェスト: データ ソースの場所と、それらのソースがデータを取得する場所を理解します。 可能であれば、ソースをパラメーター化し、セカンダリ デプロイとセカンダリ リージョンを操作するための個別の構成テンプレートがあることを確認します。 フェールオーバーの計画を準備し、すべての前提をテストします。
- 実行の変更: ジョブやその他のアクションをトリガーするスケジューラがある場合は、セカンダリ デプロイまたはそのデータ ソースを操作する個別のスケジューラを構成することが必要な場合があります。 フェールオーバーの計画を準備し、すべての前提をテストします。
- 対話型接続: REST API、CLI ツール、またはその他のサービス (JDBC/ODBC など) を使用する場合のリージョンの中断によって、構成、認証、およびネットワーク接続がどのように影響を受ける可能性があるかを検討します。 フェールオーバーの計画を準備し、すべての前提をテストします。
- 自動化の変更: すべての自動化ツールについて、フェールオーバーの計画を作成し、すべての想定をテストします。
- 出力: 出力データまたはログを生成するツールについては、フェールオーバーの計画を準備し、すべての前提条件をテストします。
フェールオーバーをテストする
ディザスター リカバリーは、さまざまなシナリオによってトリガーされる可能性があります。 予期しない中断によってトリガーされることがあります。 クラウド ネットワーク、クラウド ストレージ、別のコア サービスなど、一部のコア機能が停止する場合があります。 システムを正常にシャットダウンするためのアクセス権がないため、復旧を試みる必要があります。 ただし、このプロセスは、シャットダウンまたは計画停止によってトリガーされる場合もあれば、2 つのリージョン間でのアクティブ デプロイの定期的な切り替えによりトリガーされる場合もあります。
フェールオーバーをテストするときは、システムに接続してシャットダウン プロセスを実行します。 すべてのジョブが完了し、クラスターが終了していることを確認します。
同期クライアント (または CI/CD ツール) は、関連する Azure Databricks オブジェクトとリソースをセカンダリ ワークスペースにレプリケートできます。 セカンダリ ワークスペースをアクティブ化するために、以下の一部または全部がプロセスに含まれる場合があります。
- テストを実行して、プラットフォームが最新であることを確認します。
- プライマリ リージョンのプールとクラスターを無効にして、障害が発生したサービスがオンラインに戻ってもプライマリ リージョンで新しいデータの処理が開始しないようにします。
- 復旧プロセスは次のとおりです。
- 最も新しく同期されたデータの日付を確認します。 [_](# dr-terminology) を参照してください。 この手順の詳細は、データの同期方法と固有のビジネス ニーズによって異なります。
- データ ソースを安定させ、それらがすべて使用可能であることを確認します。 Azure Cloud SQL、Delta Lake、Parquet、またはその他のファイルなど、すべての外部データ ソースを含めます。
- ストリーミング復旧ポイントを見つけます。 そこから再起動し、潜在的な重複を特定して排除する準備ができているプロセスを設定します (Delta Lake Lake を使用すると、この作業が容易になります)。
- データ フロー プロセスを完了し、ユーザーに通知します。
- 関連するプールを開始します (または、関連する数に
min_idle_instancesを増やします)。 - 関連するクラスターを開始します (終了していない場合)。
- ジョブの同時実行を変更し、関連するジョブを実行します。 これらは、1 回限りの実行または定期的な実行である可能性があります。
- Azure Databricks ワークスペースの URL またはドメイン名を使用する外部ツールの場合は、新しいコントロール プレーンを考慮するように構成を更新します。 たとえば、REST API と JDBC/ODBC 接続の URL を更新します。 コントロール プレーンが変更されると、Azure Databricks Web アプリケーションの顧客向け URL が変更されるため、組織のユーザーに新しい URL を通知します。
復元のテスト (フェールバック)
フェールバックは制御が容易で、メンテナンス期間に実行できます。 この計画には、以下の一部または全部が含まれる可能性があります。
- プライマリ リージョンが復元されたことを確認します。
- セカンダリ リージョンのプールとクラスターを無効にして、新しいデータの処理を開始しないようにします。
- セカンダリ ワークスペース内の新規または変更された資産をプライマリ デプロイに同期します。 フェールオーバー スクリプトの設計によっては、同じスクリプトを実行して、セカンダリ (ディザスター リカバリー) リージョンからプライマリ (運用) リージョンにオブジェクトを同期できる場合があります。
- 新しいデータ更新をプライマリ デプロイに同期します。 ログとデルタ テーブルの監査証跡を使用して、データの損失を保証できます。
- ディザスター リカバリー リージョンのすべてのワークロードをシャットダウンします。
- ジョブとユーザーの URL をプライマリ リージョンに変更します。
- テストを実行して、プラットフォームが最新であることを確認します。
- 関連するプールを開始します (または、関連する数に
min_idle_instancesを増やします)。 - 関連するクラスターを開始します (終了していない場合)。
- ジョブの同時実行を変更し、関連するジョブを実行します。 これらは、1 回限りの実行または定期的な実行である可能性があります。
- 必要に応じて、将来のディザスター リカバリーのためにセカンダリ リージョンをもう一度設定します。
自動化スクリプト、サンプル、プロトタイプ
ディザスター リカバリー プロジェクトで検討する自動化スクリプトには、次のようなものがあります。
- Databricks では、独自の同期プロセスの開発に役立つ Databricks Terraform プロバイダー を使用することをお勧めします。
- サンプル スクリプトとプロトタイプ スクリプトについては、Databricks ワークスペース移行ツールに関するページも参照してください。 Azure Databricks オブジェクトに加えて、関連する Azure Data Factory パイプラインをレプリケートして、セカンダリ ワークスペースにマップされているリンクされたサービスをオブジェクトが参照するようにします。
- Databricks Sync (DBSync) プロジェクトは、Databricks ワークスペースのバックアップ、復元、同期を行うオブジェクト同期ツールです。