Important
この機能は ベータ版です。 アカウント管理者は、[ プレビュー] ページからこの機能へのアクセスを制御できます。
Azure Databricks コーディング エージェント統合を使用すると、Cursor、Gemini CLI、Codex CLI、Claude Code などのコーディング エージェントのアクセスと使用を管理できます。 AI Gateway 上に構築され、コーディング ツールのレート制限、使用状況の追跡、推論テーブルを提供します。
Features
- アクセス: 1 つの請求書の下にあるさまざまなコーディング ツールとモデルに直接アクセスできます。
- 可観測性: すべてのコーディング ツールの使用状況、支出、メトリックを追跡するための 1 つの統合ダッシュボード。
- 統合ガバナンス: 管理者は、AI Gateway を介してモデルのアクセス許可とレート制限を直接管理できます。
Requirements
- アカウントに対して有効になっている AI ゲートウェイ (ベータ) プレビュー。
- AI ゲートウェイ (ベータ) でサポートされているリージョン内の Azure Databricks ワークスペース。
- ワークスペースに対して有効になっている Unity カタログ。 「Unity Catalog のワークスペースを有効にする」を参照してください。
サポートされているエージェント
次のコーディング エージェントがサポートされています。
設定
Cursor
AI ゲートウェイ エンドポイントを使用するように Cursor を構成するには:
手順 1: ベース URL と API キーを構成する
カーソルを開き、 設定>Cursor 設定>Models>API キーに移動します。
OpenAI ベース URL のオーバーライドを有効にし、URL を入力します。
https://<ai-gateway-url>/cursor/v1<ai-gateway-url>を AI ゲートウェイ エンドポイント URL に置き換えます。Azure Databricks の個人用アクセス トークンを OpenAI API キー フィールドに貼り付けます。
手順 2: カスタム モデルを追加する
- [カーソル設定] で [ + カスタム モデルの追加] をクリックします。
- AI ゲートウェイ エンドポイント名を追加し、トグルを有効にします。
注
現時点では、Azure Databricks によって作成された基盤モデル エンドポイントのみがサポートされています。
手順 3: 統合をテストする
-
Cmd+L(macOS) またはCtrl+L(Windows/Linux) で Ask モードを開き、モデルを選択します。 - メッセージを送信します。 すべての要求が Azure Databricks 経由でルーティングされるようになりました。
Codex CLI
手順 1: DATABRICKS_TOKEN環境変数を設定する
export DATABRICKS_TOKEN=<databricks_pat_token>
手順 2: Codex クライアントを構成する
~/.codex/config.tomlで Codex 構成ファイルを作成または編集します。
profile = "default"
[profiles.default]
model_provider = "proxy"
model = "databricks-gpt-5-2"
[model_providers.proxy]
name = "Databricks Proxy"
base_url = "https://<ai-gateway-url>/openai/v1"
env_key = "DATABRICKS_TOKEN"
wire_api = "responses"
<ai-gateway-url>を AI ゲートウェイ エンドポイント URL に置き換えます。
Gemini CLI
手順 1: Gemini CLI の最新バージョンをインストールする
npm install -g @google/gemini-cli@nightly
手順 2: 環境変数を構成する
ファイル ~/.gemini/.env を作成し、次の構成を追加します。 詳細については、 Gemini CLI 認証に関するドキュメント を参照してください。
GEMINI_MODEL=databricks-gemini-2-5-flash
GOOGLE_GEMINI_BASE_URL=https://<ai-gateway-url>/gemini
GEMINI_API_KEY_AUTH_MECHANISM="bearer"
GEMINI_API_KEY=<databricks_pat_token>
<ai-gateway-url>を AI Gateway エンドポイントの URL に置き換え、<databricks_pat_token>を個人用アクセス トークンに置き換えます。
Claude Code
手順 1: クロード コード クライアントを構成する
~/.claude/settings.json に次の構成を追加します。 詳細については、 Claude Code の設定に関するドキュメント を参照してください。
{
"env": {
"ANTHROPIC_MODEL": "databricks-claude-opus-4-6",
"ANTHROPIC_BASE_URL": "https://<ai-gateway-url>/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<databricks_pat_token>",
"ANTHROPIC_CUSTOM_HEADERS": "x-databricks-use-coding-agent-mode: true",
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"
}
}
<ai-gateway-url>を AI Gateway エンドポイントの URL に置き換え、<databricks_pat_token>を個人用アクセス トークンに置き換えます。
手順 2 (省略可能): OpenTelemetry メトリックコレクションを設定する
Claude Code から Unity カタログのマネージド デルタ テーブルにメトリックとログをエクスポートする方法の詳細については、「 OpenTelemetry データ収集の設定 」を参照してください。
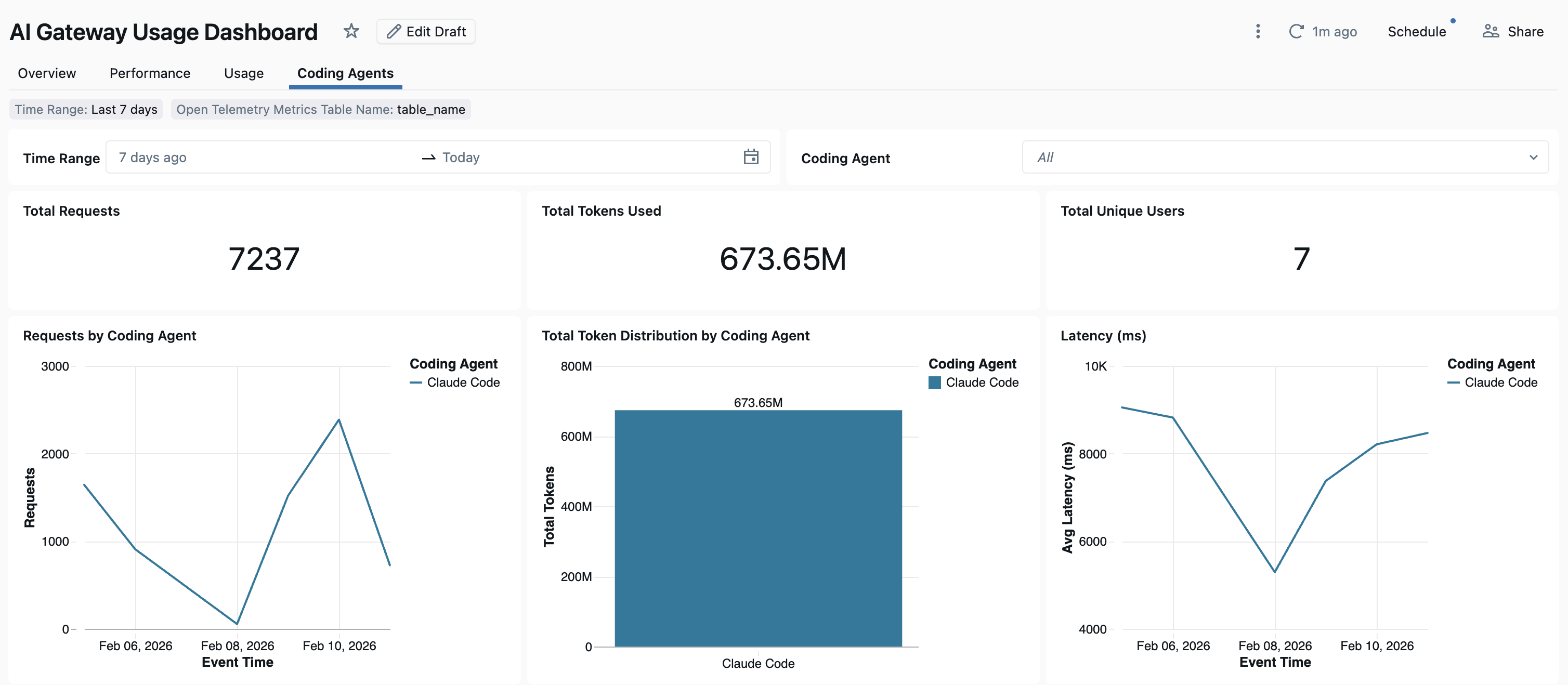
Dashboard
AI Gateway を使用してコーディング エージェントの使用状況を追跡すると、すぐに使用できるダッシュボードでメトリックを表示および監視できます。
ダッシュボードにアクセスするには、[AI ゲートウェイ] ページから [ダッシュボードの表示 ] を選択します。 これにより、コーディング ツールを使用するためのグラフを含む事前構成済みのダッシュボードが作成されます。
![[ダッシュボードの表示] ボタン](../_static/images/ai-gateway/view-dashboard-beta.png)
OpenTelemetry データ収集を設定する
Azure Databricks では、OpenTelemetry のメトリックとログを Claude Code から Unity カタログのマネージド デルタ テーブルにエクスポートできます。 すべてのメトリックは、OpenTelemetry 標準メトリック プロトコルを使用してエクスポートされた時系列データであり、ログは OpenTelemetry ログ プロトコルを使用してエクスポートされます。 使用可能なメトリックとイベントについては、「 Claude Code の監視の使用状況」を参照してください。
Requirements
- Azure Databricks プレビューで OpenTelemetry が有効になっています。 Azure Databricks プレビューの管理を参照してください。
手順 1: Unity カタログで OpenTelemetry テーブルを作成する
OpenTelemetry メトリックとログ スキーマを使用して事前構成された Unity カタログのマネージド テーブルを作成します。
メトリック テーブル
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_metrics (
name STRING,
description STRING,
unit STRING,
metric_type STRING,
gauge STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
sum STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
aggregation_temporality: STRING,
is_monotonic: BOOLEAN
>,
histogram STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
bucket_counts: ARRAY<LONG>,
explicit_bounds: ARRAY<DOUBLE>,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
min: DOUBLE,
max: DOUBLE,
aggregation_temporality: STRING
>,
exponential_histogram STRUCT<
attributes: MAP<STRING, STRING>,
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
scale: INT,
zero_count: LONG,
positive_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
negative_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
flags: INT,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
min: DOUBLE,
max: DOUBLE,
zero_threshold: DOUBLE,
aggregation_temporality: STRING
>,
summary STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
quantile_values: ARRAY<STRUCT<
quantile: DOUBLE,
value: DOUBLE
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
metadata MAP<STRING, STRING>,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
metric_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
ログ テーブル
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_logs (
event_name STRING,
trace_id STRING,
span_id STRING,
time_unix_nano LONG,
observed_time_unix_nano LONG,
severity_number STRING,
severity_text STRING,
body STRING,
attributes MAP<STRING, STRING>,
dropped_attributes_count INT,
flags INT,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
log_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
手順 2: クロード コード設定ファイルを更新する
env ファイルの~/.claude/settings.json ブロックに次の環境変数を追加して、メトリックとログのエクスポートを有効にします。
{
"env": {
"CLAUDE_CODE_ENABLE_TELEMETRY": "1",
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_METRICS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_METRICS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/metrics",
"OTEL_EXPORTER_OTLP_METRICS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_metrics",
"OTEL_METRIC_EXPORT_INTERVAL": "10000",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_LOGS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_LOGS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/logs",
"OTEL_EXPORTER_OTLP_LOGS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_logs",
"OTEL_LOGS_EXPORT_INTERVAL": "5000"
}
}
次の部分を置き換えます。
-
<workspace-url>を Azure Databricks ワークスペース URL と共に使用します。 -
<databricks_pat_token>個人用アクセス トークンを使用しなさい。 -
<catalog>.<schema>.<table_prefix>OpenTelemetry テーブルの作成時に使用されるカタログ、スキーマ、およびテーブル プレフィックスを使用します。
注
OTEL_METRIC_EXPORT_INTERVALの既定値は 6,0000 ミリ秒 (60 秒) です。 上の例では、10000 ミリ秒 (10 秒) に設定されています。
OTEL_LOGS_EXPORT_INTERVALの既定値は 5000 ミリ秒 (5 秒) です。
手順 3: クロード コードを実行する
claude
データは、5 分以内に Unity カタログ テーブルに反映されます。