Von Bedeutung
このドキュメントは廃止され、更新されない可能性があります。 このコンテンツに記載されている製品、サービス、またはテクノロジはサポートされなくなりました。 Datetime パターンを参照してください。
Databricks Runtime 7.0 では、 Date と Timestamp のデータ型が大幅に変更されました。 この記事では、以下について説明します。
-
Dateの種類とそれに関連するカレンダー。 -
Timestampの種類と、タイム ゾーンとの関係。 また、タイム ゾーン オフセットの解決の詳細と、Databricks Runtime 7.0 で使用される Java 8 の新しいタイム API での微妙な動作の変化についても説明します。 - 日付とタイムスタンプの値を構築するための API。
- Apache Spark ドライバーで日付オブジェクトとタイムスタンプ オブジェクトを収集するための一般的な落とし穴とベスト プラクティス。
日付とカレンダー
Dateは、年、月、日の各フィールドの組み合わせです (year=2012、month=12、day=31)。 ただし、年、月、日の各フィールドの値には、日付値が実際の有効な日付であることを確認するための制約があります。 たとえば、月の値は 1 から 12、日の値は 1 から 28,29,30、または 31 (年と月に応じて) である必要があります。
Dateの種類では、タイム ゾーンは考慮されません。
カレンダー
Dateフィールドに対する制約は、多くの可能なカレンダーの 1 つによって定義されます。
太陰暦のように、特定の地域でのみ使用されるものもあります。
ユリウス暦のように、歴史上のみ使用されるものもあります。 事実上の国際標準は グレゴリオ暦 であり、世界中のほぼすべての場所で市民目的で使用されています。 1582年に導入され、1582年以前の日付もサポートするように拡張されました。 この拡張カレンダーは、 プロレプティック グレゴリオ暦と呼ばれます。
Databricks Runtime 7.0 ではプロレプティック グレゴリオ暦が使用されています。これは、pandas、R、Apache Arrow などの他のデータ システムで既に使用されています。 Databricks Runtime 6.x 以下では、ユリウス暦とグレゴリオ暦の組み合わせを使用しました。1582 年より前の日付では、ユリウス暦が使用され、1582 年より後の日付にはグレゴリオ暦が使用されました。 これは従来の java.sql.Date API から継承され、Java 8 では proleptic グレゴリオ暦を使用する java.time.LocalDate によって置き換えられました。
タイムスタンプとタイム ゾーン
Timestamp型は、Date型を、時間、分、秒 (小数部を含むことができる) という新しいフィールドと、グローバル (セッション スコープ) タイム ゾーンと共に拡張します。 具体的な時間のインスタントを定義します。 たとえば、セッション タイム ゾーン UTC+01:00 の (year=2012、month=12、day=31、hour=23、minute=59、second=59.123456) などです。 Parquet などのテキスト以外のデータ ソースにタイムスタンプ値を書き込む場合、値はタイム ゾーン情報のないインスタント (UTC のタイムスタンプなど) になります。 セッション タイム ゾーンが異なるタイムスタンプ値を書き込んで読み取ると、時間、分、および 2 番目のフィールドの値が異なる場合がありますが、それらは同じ具体的な時間インスタントです。
時間、分、および 2 番目のフィールドには標準の範囲があります。時間は 0 ~ 23、分と秒は 0 ~ 59 です。 Spark では、秒の小数部を最大マイクロ秒の精度でサポートしています。 分数の有効範囲は 0 ~ 999,999 マイクロ秒です。
タイム ゾーンに応じて、任意の具体的な瞬間に、さまざまな壁時計の値を観察できます。
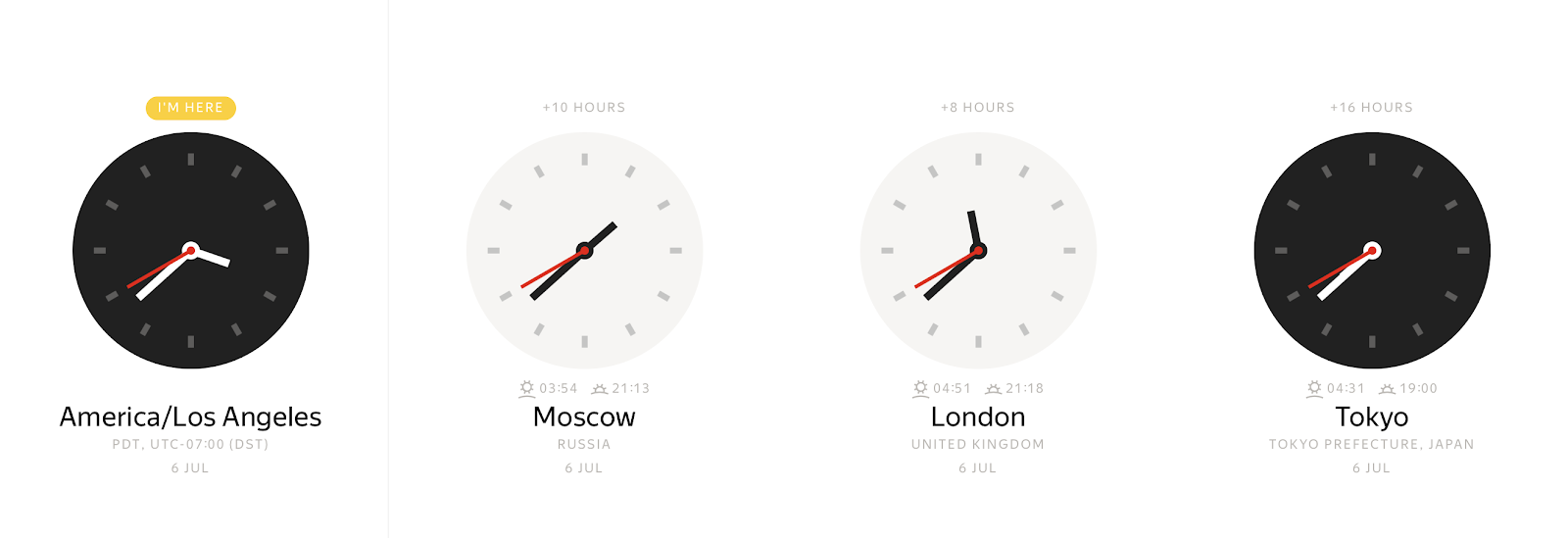
逆に、壁時計の値は、さまざまな時間の瞬間を表すことができます。
タイム ゾーン オフセットを使用すると、ローカル タイムスタンプをタイム インスタントに明確にバインドできます。 通常、タイム ゾーン オフセットは、グリニッジ標準時 (GMT) または UTC+0 (世界協定時刻) からの時間単位のオフセットとして定義されます。 このタイム ゾーン情報の表現はあいまいさを排除しますが、不便です。 ほとんどの人は、 America/Los_Angeles や Europe/Parisなどの場所を指摘することを好みます。 ゾーン オフセットからの抽象化のこの追加レベルにより、生活は簡単になりますが、複雑になります。 たとえば、タイム ゾーン名をオフセットにマップするには、特別なタイム ゾーン データベースを維持する必要があります。 Spark は JVM 上で実行されるため、マッピングを Java 標準ライブラリに委任します。このライブラリは、 インターネット割り当て番号機関タイム ゾーン データベース (IANA TZDB) からデータを読み込みます。 さらに、Java の標準ライブラリのマッピング メカニズムには、Spark の動作に影響を与えるいくつかの微妙な違いがあります。
Java 8 以降、JDK は日付/時刻操作とタイム ゾーン オフセット解決用に別の API を公開し、Databricks Runtime 7.0 ではこの API を使用しています。 タイム ゾーン名とオフセットのマッピングのソースは IANA TZDB と同じですが、Java 8 以降では Java 7 とは異なる方法で実装されます。
たとえば、 America/Los_Angeles タイム ゾーンの 1883 年より前のタイムスタンプ ( 1883-11-10 00:00:00) を見てみましょう。 1883年11月18日、北米のすべての鉄道が新しい標準時システムに切り替えたため、今年は他の人から目立ちます。 Java 7 タイム API を使用すると、ローカル タイムスタンプのタイム ゾーン オフセットを -08:00として取得できます。
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
同等の Java 8 API は、別の結果を返します。
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
1883年11月18日より前、北米の時間帯は地元の問題であり、ほとんどの都市や町は、有名な時計(教会の急な上、宝石商の窓など)によって維持された何らかの形式の現地太陽時間を使用していました。 そのため、このような奇妙なタイム ゾーン オフセットが表示されます。
この例では、Java 8 関数がより正確であり、IANA TZDB からの履歴データを考慮に入れていることを示しています。 Java 8 タイム API に切り替えた後、Databricks Runtime 7.0 は自動的に改善の恩恵を受け、タイム ゾーン オフセットを解決する方法をより正確にしました。
Databricks Runtime 7.0 は、 Timestamp 型のプロレプティック グレゴリオ暦にも切り替えました。
ISO SQL:2016 標準では、タイムスタンプの有効な範囲が0001-01-01 00:00:00から9999-12-31 23:59:59.999999に宣言されています。 Databricks Runtime 7.0 は標準に完全に準拠しており、この範囲のすべてのタイムスタンプをサポートしています。 Databricks Runtime 6.x 以降と比較して、次のサブ範囲に注意してください。
-
0001-01-01 00:00:00..1582-10-03 23:59:59.999999。 Databricks Runtime 6.x 以下ではユリウス暦が使用され、標準に準拠していません。 Databricks Runtime 7.0 は問題を修正し、年、月、日などのタイムスタンプに対する内部操作でプロレプティック グレゴリオ暦を適用します。カレンダーが異なるために、Databricks Runtime 6.x 以下に存在するいくつかの日付は Databricks Runtime 7.0 には存在しません。 たとえば、1000 年はグレゴリオ暦の閏年ではないため、1000-02-29 は有効な日付ではありません。 また、Databricks Runtime 6.x 以下では、タイムゾーン名がこのタイムスタンプ範囲に対してゾーンオフセットに誤って変換されます。 -
1582-10-04 00:00:00..1582-10-14 23:59:59.999999。 これは Databricks Runtime 7.0 の有効な範囲のローカル タイムスタンプです。Databricks Runtime 6.x 以降では、そのようなタイムスタンプが存在しませんでした。 -
1582-10-15 00:00:00..1899-12-31 23:59:59.999999。 Databricks Runtime 7.0 は、IANA TZDB の履歴データを使用してタイム ゾーン オフセットを正しく解決します。 Databricks Runtime 7.0 と比較すると、Databricks Runtime 6.x 以下では、前の例に示すように、タイム ゾーン名からのゾーン オフセットが正しく解決されない場合があります。 -
1900-01-01 00:00:00..2036-12-31 23:59:59.999999。 Databricks Runtime 7.0 と Databricks Runtime 6.x 以下の両方が ANSI SQL 標準に準拠しており、月の日の取得などの日時操作でグレゴリオ暦を使用します。 -
2037-01-01 00:00:00..9999-12-31 23:59:59.999999。 Databricks Runtime 6.x 以下では、タイム ゾーン オフセットと夏時間オフセットが正しく解決されない可能性があります。 Databricks Runtime 7.0 はサポートされていません。
タイム ゾーン名をオフセットにマッピングするもう 1 つの側面は、夏時間 (DST) が原因で発生する可能性があるローカル タイムスタンプの重複や、別の標準タイム ゾーン オフセットへの切り替えです。 たとえば、2019 年 11 月 3 日の 02:00:00 に、米国のほとんどの州では、時計が 1 時間から 01:00:00 に逆方向に回されました。 ローカル タイムスタンプ 2019-11-03 01:30:00 America/Los_Angeles は、 2019-11-03 01:30:00 UTC-08:00 または 2019-11-03 01:30:00 UTC-07:00にマップできます。 オフセットを指定せず、タイム ゾーン名 (たとえば、 2019-11-03 01:30:00 America/Los_Angeles) を設定した場合、Databricks Runtime 7.0 は以前のオフセットを受け取り、通常は "summer" に対応します。 この動作は Databricks Runtime 6.x 以降から分岐し、"winter" オフセットを受け取ります。 クロックが前方にジャンプするギャップの場合、有効なオフセットはありません。 一般的な 1 時間の夏時間の変更の場合、Spark はそのようなタイムスタンプを、"夏" 時刻に対応する次の有効なタイムスタンプに移動します。
前の例からわかるように、タイム ゾーン名とオフセットのマッピングはあいまいであり、1 対 1 ではありません。 可能な場合は、タイムスタンプを作成するときに、正確なタイム ゾーン オフセット ( 2019-11-03 01:30:00 UTC-07:00など) を指定することをお勧めします。
ANSI SQL と Spark SQL のタイムスタンプ
ANSI SQL 標準では、次の 2 種類のタイムスタンプが定義されています。
-
TIMESTAMP WITHOUT TIME ZONEまたはTIMESTAMP: ローカル タイムスタンプ (YEAR、MONTH、DAY、HOUR、MINUTE、SECOND)。 これらのタイムスタンプはどのタイム ゾーンにもバインドされず、ウォール クロックタイムスタンプです。 -
TIMESTAMP WITH TIME ZONE: ゾーン化されたタイムスタンプ (YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、TIMEZONE_HOUR、TIMEZONE_MINUTE)。 これらのタイムスタンプは、UTC タイム ゾーンのインスタントと、各値に関連付けられているタイム ゾーン オフセット (時間と分) を表します。
TIMESTAMP WITH TIME ZONEのタイム ゾーン オフセットは、タイムスタンプが表す物理的な時点には影響しません。これは、他のタイムスタンプ コンポーネントによって指定された UTC 時刻の瞬間で完全に表されるためです。 代わりに、タイム ゾーン オフセットは、表示、日付/時刻コンポーネント抽出 (たとえば、 EXTRACT) のタイムスタンプ値の既定の動作と、タイム ゾーンを知る必要があるその他の操作 (タイムスタンプへの月の追加など) にのみ影響します。
Spark SQL では、タイムスタンプの種類をTIMESTAMP WITH SESSION TIME ZONEとして定義します。これは、フィールド (YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、SESSION TZ) の組み合わせです。ここで、YEAR フィールドを介したSECONDは UTC タイム ゾーン内のタイム インスタントを識別し、SESSION TZ は SQL config spark.sql.session.timeZone から取得されます。 セッション タイム ゾーンは次のように設定できます。
- ゾーンオフセット
(+|-)HH:mm。 このフォームを使用すると、物理的な時点を明確に定義できます。 -
area/cityなど、リージョン IDAmerica/Los_Angelesの形式のタイム ゾーン名。 この形式のタイム ゾーン情報は、ローカル タイムスタンプの重複など、前に説明した問題の一部に起因します。 ただし、各 UTC タイム インスタントは、任意のリージョン ID の 1 つのタイム ゾーン オフセットと明確に関連付けられます。その結果、リージョン ID ベースのタイム ゾーンを持つ各タイムスタンプは、ゾーン オフセットを持つタイムスタンプに明確に変換できます。 既定では、セッション タイム ゾーンは Java 仮想マシンの既定のタイム ゾーンに設定されます。
Spark TIMESTAMP WITH SESSION TIME ZONE は次とは異なります。
-
TIMESTAMP WITHOUT TIME ZONEこの型の値は、複数の物理的な時間のインスタントにマップできますが、TIMESTAMP WITH SESSION TIME ZONEの任意の値は、具体的な物理的な時間のインスタントであるためです。 SQL 型は、たとえば UTC+0 など、すべてのセッションで 1 つの固定タイム ゾーン オフセットを使用してエミュレートできます。 その場合は、UTC のタイムスタンプをローカル タイムスタンプと見なします。 -
TIMESTAMP WITH TIME ZONE型の SQL 標準列の値に従って、異なるタイム ゾーン オフセットを持つことができます。 これは Spark SQL ではサポートされていません。
グローバル (セッション スコープ) タイム ゾーンに関連付けられているタイムスタンプは、Spark SQL によって新しく発明されたものではありません。 Oracle などの RDBMS では、タイムスタンプに対して同様の型 ( TIMESTAMP WITH LOCAL TIME ZONE) が提供されます。
日付とタイムスタンプを作成する
Spark SQL には、日付とタイムスタンプの値を作成するためのいくつかの方法が用意されています。
- パラメーターのない既定のコンストラクター:
CURRENT_TIMESTAMP()とCURRENT_DATE()。 - 他のプリミティブ Spark SQL 型 (
INT、LONG、およびSTRING)。 - Python datetime や Java クラスなどの外部型から
java.time.LocalDate/Instant。 - CSV、JSON、Avro、Parquet、ORC などのデータ ソースからの逆シリアル化。
Databricks Runtime 7.0 で導入 MAKE_DATE 関数は、YEAR、 MONTH、 DAYの 3 つのパラメーターを受け取り、 DATE 値を構築します。 すべての入力パラメーターは、可能な限り暗黙的に INT 型に変換されます。 関数は、結果の日付がプロレプティック グレゴリオ暦の有効な日付であることを確認し、それ以外の場合は NULLを返します。 例えば次が挙げられます。
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
DataFrame コンテンツを出力するには、 show() アクションを呼び出します。このアクションは、Executor の文字列に日付を変換し、文字列をドライバーに転送してコンソールに出力します。
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
同様に、 MAKE_TIMESTAMP 関数を使用してタイムスタンプ値を作成できます。
MAKE_DATEと同様に、日付フィールドに対して同じ検証が実行され、時間フィールド HOUR (0 から 23)、MINUTE (0- 59)、SECOND (0- 60) も受け入れられます。 SECOND 型は Decimal(precision = 8, scale = 6) です。秒は小数部の精度をマイクロ秒単位まで指定できるためです。 例えば次が挙げられます。
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
日付については、show() アクションを使用して ts DataFrame の内容を出力します。 同様に、 show() はタイムスタンプを文字列に変換しますが、SQL 構成 spark.sql.session.timeZoneによって定義されたセッション タイム ゾーンが考慮されるようになりました。
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
この日付が無効であるため、Spark は最後のタイムスタンプを作成できません。2019 年は閏年ではありません。
前の例ではタイム ゾーン情報がないことに気付くかもしれません。 その場合、Spark は SQL 構成 spark.sql.session.timeZone からタイム ゾーンを取得し、関数呼び出しに適用します。
MAKE_TIMESTAMPの最後のパラメーターとして渡すことで、別のタイム ゾーンを選択することもできます。 次に例を示します。
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
この例で示すように、Spark は指定されたタイム ゾーンを考慮しますが、すべてのローカル タイムスタンプをセッション タイム ゾーンに調整します。
MAKE_TIMESTAMP関数に渡された元のタイム ゾーンは失われます。TIMESTAMP WITH SESSION TIME ZONE型では、すべての値が 1 つのタイム ゾーンに属していると見なされ、すべての値ごとにタイム ゾーンが格納されることさえないためです。
TIMESTAMP WITH SESSION TIME ZONEの定義に従って、Spark はローカル タイムスタンプを UTC タイム ゾーンに格納し、セッション タイム ゾーンを使用して日時フィールドを抽出するか、タイムスタンプを文字列に変換します。
また、キャストを使用することで、LONG型からタイムスタンプを構築することも可能です。 LONG 列にエポック 1970-01-01 00:00:00Z 以降の秒数が含まれている場合は、Spark SQL TIMESTAMPにキャストできます。
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
残念ながら、このアプローチでは、秒の小数部を指定することはできません。
もう 1 つの方法は、 STRING 型の値から日付とタイムスタンプを作成することです。 リテラルは、次の特殊なキーワードを使用して作成できます。
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
別の方法として、キャストを使用することで列内のすべての値に適用することができます。
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
入力タイムスタンプ文字列は、入力文字列でタイム ゾーンが省略されている場合、指定されたタイム ゾーンまたはセッション タイム ゾーンのローカル タイムスタンプとして解釈されます。 通常とは異なるパターンの文字列は、 to_timestamp() 関数を使用してタイムスタンプに変換できます。 サポートされているパターンについては、「 Datetime Patterns for Formatting and Parsing」で説明されています。
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
パターンを指定しない場合、関数は CASTと同様に動作します。
使いやすさのために、Spark SQL は、文字列を受け取り、タイムスタンプまたは日付を返すすべてのメソッドで特殊な文字列値を認識します。
-
epochは、日付1970-01-01またはタイムスタンプ1970-01-01 00:00:00Zのエイリアスです。 -
nowは、セッション タイム ゾーンの現在のタイムスタンプまたは日付です。 1 つのクエリ内では、常に同じ結果が生成されます。 -
todayは、TIMESTAMP型の現在の日付の先頭、またはDATE型の現在の日付です。 -
tomorrowは、タイムスタンプの翌日の始まり、またはDATE型の場合は翌日です。 -
yesterdayは、TIMESTAMP型の現在の前日またはタイプの開始日です。
例えば次が挙げられます。
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
Spark を使用すると、ドライバー側の外部オブジェクトの既存のコレクションから Datasets を作成し、対応する型の列を作成できます。 Spark は、外部型のインスタンスを意味的に同等の内部表現に変換します。 たとえば、Python コレクションからDataset列とDATE列を含むTIMESTAMPを作成するには、次のコマンドを使用します。
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
PySpark は、システム タイム ゾーンを使用して、Python の日時オブジェクトをドライバー側の内部 Spark SQL 表現に変換します。これは、Spark のセッション タイム ゾーン設定 spark.sql.session.timeZoneとは異なる場合があります。 内部値には、元のタイム ゾーンに関する情報は含まれません。 並列化された日付とタイムスタンプの値に対する今後の操作では、 TIMESTAMP WITH SESSION TIME ZONE 型の定義に従って Spark SQL セッションのタイム ゾーンのみが考慮されます。
同様に、Spark は次の型を Java API と Scala API の外部日時型として認識します。
-
java.sql.Dateおよびjava.time.LocalDateはDATE型の外部型として -
java.sql.Timestampとjava.time.InstantのTIMESTAMP型。
java.sql.*型とjava.time.*型には違いがあります。
java.time.LocalDate と java.time.Instant は Java 8 で追加されました。この型は、Databricks Runtime 7.0 以降で使用されているものと同じ、プロレプティック グレゴリオ暦に基づいています。
java.sql.Date
java.sql.Timestampには、Databricks Runtime 6.x 以下で使用されている従来のカレンダーと同じ、ハイブリッド カレンダー (1582-10-15 以降のユリウス暦 + グレゴリオ暦) が存在します。 カレンダー システムが異なるために、Spark は内部の Spark SQL 表現への変換中に追加の操作を実行し、入力日付/タイムスタンプをあるカレンダーから別のカレンダーにリベースする必要があります。 リベース操作では、1900 年以降の最新のタイムスタンプのオーバーヘッドが少なく、古いタイムスタンプの方が重要になる可能性があります。
次の例は、Scala コレクションからタイムスタンプを作成する方法を示しています。 最初の例では、文字列から java.sql.Timestamp オブジェクトを構築します。
valueOfメソッドは、入力文字列を、Spark のセッション タイム ゾーンとは異なる既定の JVM タイム ゾーンのローカル タイムスタンプとして解釈します。 特定のタイム ゾーンで java.sql.Timestamp または java.sql.Date のインスタンスを構築する必要がある場合は、 java.text.SimpleDateFormat (およびそのメソッド setTimeZone) または java.util.Calendar を確認してください。
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
同様に、DATEまたはjava.sql.Dateのコレクションからjava.sql.LocalDate列を作成することもできます。
java.sql.LocalDate インスタンスの並列化は、Spark のセッションまたは JVM の既定のタイム ゾーンに完全に依存しませんが、java.sql.Date インスタンスの並列化についても同様ではありません。 次の違いがあります。
-
java.sql.Dateインスタンスは、ドライバーの既定の JVM タイム ゾーンのローカル日付を表します。 - Spark SQL 値に正しく変換するには、ドライバーと Executor の既定の JVM タイム ゾーンが同じである必要があります。
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
カレンダーとタイム ゾーンに関連する問題を回避するために、Java/Scala コレクションのタイムスタンプまたは日付の並列化では、Java 8 型を外部型として java.sql.LocalDate/Instant することをお勧めします。
日付とタイムスタンプを収集する
並列処理の逆操作では、エグゼキューターからドライバーに日時情報を収集し、外部データ型のコレクションを返します。 たとえば、上の例では、DataFrameアクションを使用してcollect()をドライバーに戻すことができます。
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
Spark は、日付とタイムスタンプ列の内部値を UTC タイム ゾーンのタイム インスタントとして Executor からドライバーに転送し、Spark SQL セッション タイム ゾーンを使用せず、ドライバーのシステム タイム ゾーン内の Python datetime オブジェクトへの変換を実行します。
collect() は、前のセクションで説明した show() アクションとは異なります。
show() では、タイムスタンプを文字列に変換するときにセッション タイム ゾーンを使用し、ドライバーで結果の文字列を収集します。
Java API と Scala API では、Spark は既定で次の変換を実行します。
- Spark SQL
DATE値は、java.sql.Dateのインスタンスに変換されます。 - Spark SQL
TIMESTAMP値は、java.sql.Timestampのインスタンスに変換されます。
どちらの変換も、ドライバーの既定の JVM タイム ゾーンで実行されます。 このように、 Date.getDay()、 getHour()などを使用して取得できる同じ日時フィールドを持つには、Spark SQL 関数の DAY、 HOUR、ドライバーの既定の JVM タイム ゾーンと Executor のセッション タイム ゾーンが同じである必要があります。
databricks Runtime 7.0 は、 java.sql.Date/Timestampから日付/タイムスタンプを作成するのと同様に、プロレプティック グレゴリオ暦からハイブリッド カレンダー (ユリウス + グレゴリオ暦) への再評価を実行します。 この操作は、最新の日付 (1582 年より後) とタイムスタンプ (1900 年以降) にほぼ無料ですが、古い日付とタイムスタンプのオーバーヘッドが発生する可能性があります。
このようなカレンダー関連の問題を回避し、Java 8 以降に追加された java.time 型を返すように Spark に依頼できます。 SQL 構成 spark.sql.datetime.java8API.enabled を true に設定すると、 Dataset.collect() アクションは次を返します。
-
java.time.LocalDateSpark SQLDATE型の場合 -
java.time.InstantSpark SQLTIMESTAMP型の場合
Java 8 型と Databricks Runtime 7.0 以降はどちらもプロレプティック グレゴリオ暦に基づいているため、変換はカレンダー関連の問題に苦しまれません。
collect()アクションは、既定の JVM タイム ゾーンに依存しません。 タイムスタンプ変換は、タイム ゾーンにまったく依存しません。 日付変換では、SQL 構成 spark.sql.session.timeZoneからのセッション タイム ゾーンが使用されます。 たとえば、既定の JVM タイム ゾーンが Dataset に設定され、セッション タイム ゾーンが DATE に設定されている、TIMESTAMP列とEurope/Moscow列を含むAmerica/Los_Angelesについて考えます。
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
show() アクションは、セッション時America/Los_Angelesタイムスタンプを出力しますが、Datasetを収集すると、java.sql.Timestampに変換され、toString メソッドによってEurope/Moscowが出力されます。
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
実際には、ローカル タイムスタンプ 2020-07-01 00:00:00 は UTC の 2020-07-01T07:00:00Z です。 Java 8 API を有効にしてデータセットを収集すると、次のことが確認できます。
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
グローバル JVM タイム ゾーンとは別に、 java.time.Instant オブジェクトを任意のローカル タイムスタンプに変換できます。 これは、java.time.Instantよりもjava.sql.Timestampの利点の 1 つです。 前者はグローバル JVM 設定を変更する必要があり、これは同じ JVM 上の他のタイムスタンプに影響します。 そのため、アプリケーションが異なるタイム ゾーンの日付またはタイムスタンプを処理し、Java または Scala Dataset.collect() API を使用してドライバーにデータを収集するときにアプリケーションが互いに競合しないようにする場合は、SQL 構成 spark.sql.datetime.java8API.enabledを使用して Java 8 API に切り替えることをお勧めします。