この記事では、Azure Databricks UI のネイティブ コンピューティング メトリック ツールを使用して、主要なハードウェアと Spark のメトリックを収集する方法について説明します。 メトリック UI は多目的に、そしてジョブのコンピューティングに利用できます。
メトリックは、通常 1 分以内の遅延で、ほぼリアルタイムで利用可能です。 メトリックは、顧客のストレージではなく、Azure Databricks で管理されるストレージに格納されます。
ノートブックとジョブのサーバーレス コンピューティングでは、メトリック UI の代わりにクエリ分析情報が使用されます。 サーバーレス コンピューティング メトリックの詳細については、「クエリの分析情報を表示する」を参照してください。
コンピューティング メトリック UI へのアクセス
コンピューティング メトリック UI を表示します。
- サイドバーで、[コンピューティング]をクリックします。
- 表示するメトリックのコンピュートリソースをクリックします。
- [メトリック] タブをクリックします。
既定では、すべてのノードのハードウェア メトリックが表示されます。 Spark メトリックを表示するには、[ ハードウェア ] というラベルのドロップダウン メニューをクリックし、[ Spark] を選択します。 インスタンスが GPU 対応の場合は、GPU を選択することもできます。
期間でメトリックをフィルター処理する
日付の選択フィルターを使用して時間の範囲を選択することで、履歴メトリックを表示できます。 メトリックは 1 分ごとに収集されるため、過去 30 日間の任意の範囲の日、時間、または分でフィルター処理できます。 予定表アイコンをクリックして定義済みのデータ範囲から選択するか、テキスト ボックス内をクリックしてカスタム値を定義します。
注
グラフに表示される時間間隔は、表示している時間の長さに基づいて調整されます。 ほとんどのメトリックは、現在表示している時間間隔に基づく平均です。
[最新の情報に更新] ボタンをクリックして、最新のメトリックを取得することもできます。
ノード レベルでメトリックを表示する
既定では、メトリック ページには、クラスター内のすべてのノード (ドライバーを含む) のメトリックが一定期間の平均で表示されます。
個々のノードのメトリックを表示するには、[ すべてのノード ] ドロップダウン メニューをクリックし、メトリックを表示するノードを選択します。 GPU メトリックは、個々のノード レベルでのみ使用できます。 Spark メトリックは、個々のノードでは使用できません。
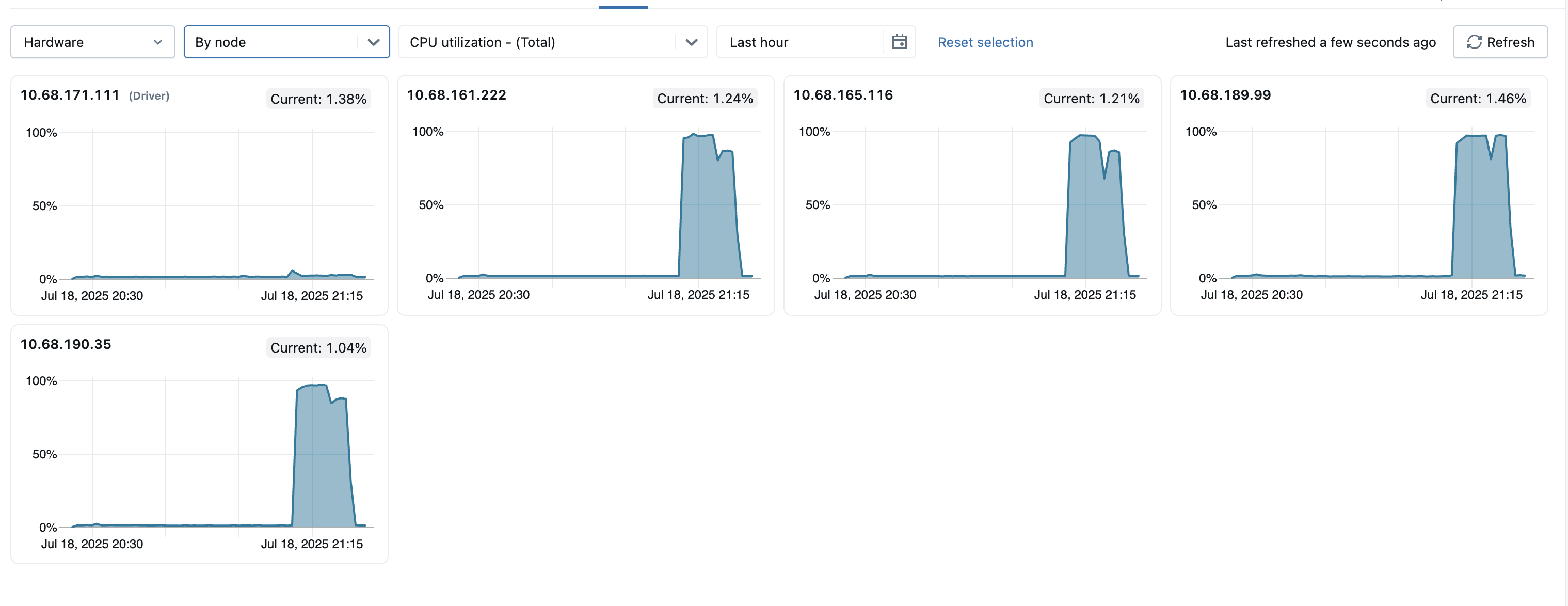
クラスター内の外れ値ノードを特定するために、1 つのページですべての個々のノードのメトリックを表示することもできます。 このビューにアクセスするには、[ すべてのノード ] ドロップダウン メニューをクリックし、[ ノード別] を選択し、表示するメトリック サブカテゴリを選択します。
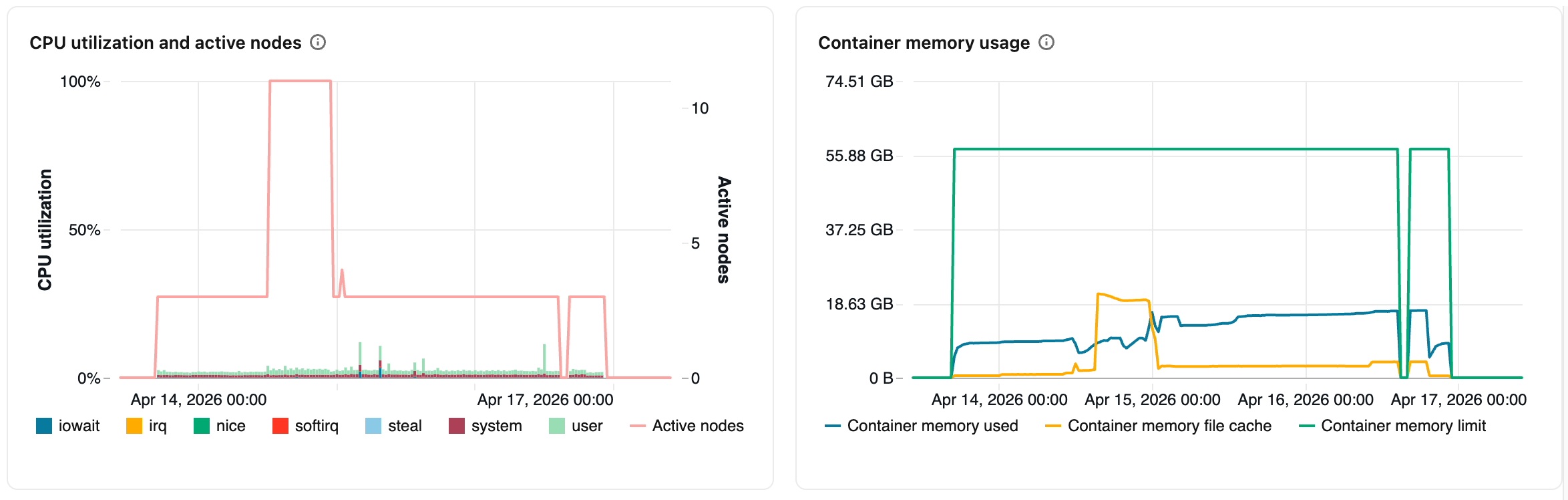
ハードウェア メトリック グラフ
コンピューティング メトリック UI では、次のハードウェア メトリック グラフを表示できます。
-
CPU 使用率とアクティブ ノード: 線グラフには、特定のコンピューティングのタイムスタンプごとにアクティブなノードの数が表示されます。 棒グラフには、CPU の合計コストに基づいて、各モードで CPU が費やされた時間の割合が表示されます。 以下のモードが追跡されます。
-
guest: VM を実行している場合、それらの VM で使用される CPU -
iowait: I/O の待機に費やされた時間 -
idle:CPUが何もする必要がなかった時間 -
irq: 割り込み要求に費やされた時間 -
nice: 他のタスクよりも優先順位が低いことを意味する、肯定的な優れさを持つプロセスによって使用される時間 -
softirq: ソフトウェア割り込み要求に費やされた時間 -
steal: VM の場合、他の VM が CPU から "盗まれた" 時間 -
system: カーネルで費やされた時間 -
user: ユーザーランドで費やされた時間
-
-
コンテナー のメモリ使用量: Spark コンテナーによって消費されるメモリ。該当するすべてのノードで平均化されます。 再利用できないメモリ (
Container memory used)、OS ファイル ページ キャッシュ (Container memory file cache)、構成されたメモリ制限 (Container memory limit) の平均が含まれます。 - JVM ヒープの使用量: 該当するすべてのノードで平均された JVM ヒープ メモリ使用量。 実際のヒープ使用量、ヒープ容量、構成されている最大ヒープ制限の平均が含まれます。
- 受信および送信されたネットワーク: 各デバイスによってネットワークを介して受信および送信されたバイト数。
- ファイル システムの空き領域: 各マウント ポイントによるファイルシステム使用量の合計 (バイト単位)。
[ハードウェア] タブの下部にある [ノード メモリ使用量] をクリックして、次の追加のグラフを展開します。
-
メモリ使用率とスワップ: ライン グラフには、モード別のメモリ スワップ使用量の合計がバイト単位で示されます。 棒グラフには、モード別のメモリ使用量の合計もバイト単位で示されます。 次の使用状況の種類が追跡されます。
-
used: 使用中の OS レベルのメモリの合計 (コンピューティングで実行されているバックグラウンド プロセスによって使用されるメモリを含む)。 ドライバーとバックグラウンド プロセスはメモリを利用するため、Spark ジョブが実行されていない場合でも使用状況が表示される可能性があります。 -
other:used、buffer、またはcached以外の用途に使用されているメモリ -
buffer: カーネル バッファーによって使用されるメモリ -
cached: OS レベルのファイル システム キャッシュによって使用されるメモリ -
free: 未使用のメモリ。 グラフの上記カテゴリに属さないものは無料です。
-
Spark メトリック グラフ
コンピューティング メトリック UI では、次の Spark メトリック グラフを表示できます。
- サーバーの負荷分散: これらのタイルは、コンピューティング リソース内の各ノードの過去 1 分間の CPU 使用率を示します。 各タイルは、個々のノードのメトリック ページへのクリック可能なリンクです。
- アクティブなタスク: 任意の時点で実行されるタスクの合計数。
- 失敗したタスクの合計数: Executor で失敗したタスクの合計数。
- 完了したタスクの合計数: Executor で完了したタスクの合計数。
- タスクの合計数: Executor 内のすべてのタスク (実行中、失敗、完了) の合計数。
-
合計シャッフル読み取り: シャッフル読み取りデータの合計サイズ (バイト単位)。
Shuffle readは、ステージの先頭にあるすべての Executor でシリアル化された読み取りデータの合計を意味します。 -
合計シャッフル書き込み: シャッフル書き込みデータの合計サイズ (バイト単位)。
Shuffle Writeは、送信前 (通常はステージの最後) のすべての Executor で書き込まれたシリアル化されたデータの合計です。 - 合計タスク期間: JVM が Executor でタスクの実行に費やした合計経過時間 (秒単位)。
GPU メトリック グラフ
注
GPU メトリックは、Databricks Runtime ML 13.3 以降でのみ使用できます。
コンピューティング メトリック UI では、次の GPU メトリック グラフを表示できます。
- サーバー負荷分散: このグラフは、各ノードの過去 1 分間の CPU 使用率を示します。
- Per-GPU デコーダー使用率: GPU デコーダー使用率の割合。
- Per-GPU エンコーダー使用率: GPU エンコーダー使用率の割合。
- 各GPUごとのフレームバッファーメモリ使用量(バイト単位):これは、バイト単位で測定されたフレームバッファーメモリの使用量です。
- Per-GPU メモリ使用率: GPU メモリ使用率の割合。
- Per-GPU 使用率: GPU 使用率の割合。
トラブルシューティング
一定期間のメトリックが不完全または不足している場合は、次のいずれかの問題が発生する可能性があります。
- メトリックのクエリと格納を行う Databricks Service に障害が発生しました。
- 顧客側のネットワークの問題。
- コンピューティングは異常な状態であるか、または異常な状態でした。