このページでは、ノートブックとジョブ タスクのサーバーレス環境を構成する方法について説明します。 ノートブックの場合は、[ 環境 ] サイド ウィンドウを使用して、基本環境の選択、依存関係のインストール、メモリの構成、使用ポリシーの適用を行います。 ジョブ タスクの場合は、タスクを作成または編集するときに環境を構成します。
[環境] サイド ウィンドウを展開するには、ノートブックの右側にある ![]() ] ボタンをクリックします。
] ボタンをクリックします。
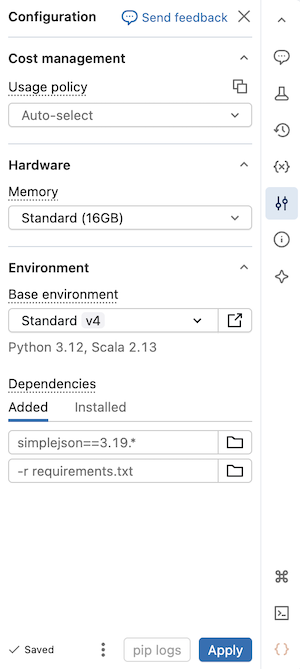
基本環境を選択する
基本環境によって、サーバーレス ノートブックで使用できるプレインストール済みのライブラリと環境のバージョンが決まります。 [環境] サイド ウィンドウの [基本環境] セレクターでは、環境を選択します。 各環境バージョンの詳細については、 サーバーレス環境のバージョンに関するページを参照してください。 Databricks では、最新バージョンを使用して、ノートブック機能を最新の状態に保つことをお勧めします。
基本環境セレクターには、次のオプションが含まれています。
- Standard: Databricks で提供されるライブラリを備えた既定のサーバーレス ベース環境。
- ML: Databricks Runtime for Machine Learning の Python パッケージとシステム パッケージがプリインストールされた基本環境。 この環境を使用して、Machine Learningワークロード用の従来の Databricks Runtime をサーバーレス コンピューティングに移行します。 ML 基本環境を参照してください。
- AI: 事前にインストールされた機械学習 (ML) ライブラリを備えた AI 最適化ベース環境。 このオプションは、アクセラレータ (GPU) が選択されている場合にのみ表示されます。
-
その他: 展開して追加のオプションを表示します。
- Standard、ML、AI の各環境の旧バージョン。
- カスタム: YAML ファイルを使用してカスタム環境を指定します。
- ワークスペース環境: 管理者によってワークスペース用に構成されたすべての互換性のある基本環境が一覧表示されます。
基本環境を選択するには:
- ノートブック UI で、[ 環境 ] サイド ウィンドウ
 をクリックします。
をクリックします。 - [ 基本環境] で、ドロップダウン メニューから環境を選択します。
- [適用] をクリックします。
ノートブックに依存関係を追加する
サーバーレスはコンピューティング ポリシーや init スクリプトをサポートしていないため、[ 環境 ] サイド ウィンドウを使用してカスタム依存関係をインストールする必要があります。 依存関係を個別にインストールすることも、共有可能な基本環境を使用して複数の依存関係をインストールすることもできます。
Azure Databricksはノートブックの仮想環境をキャッシュするため、ノートブックを再度開いたり、非アクティブ状態の後に再開したりするたびに依存関係が再インストールされることはありません。 同じ依存関係セットを共有するジョブ タスクも、実行内でこのキャッシュを利用できます。
依存関係を個別にインストールするには:
ノートブック UI で、[ 環境 ] サイド ウィンドウ
をクリックします。[ 依存関係 ] セクションで、[ 依存関係の追加 ] をクリックし、フィールドに依存関係のパスを入力します。 依存関係は、requirements.txt ファイルで有効な形式であれば、どの形式でも指定できます。 Pythonホイール ファイルまたはPython プロジェクト (たとえば、
pyproject.tomlまたはsetup.pyを含むディレクトリ) は、ワークスペース ファイルまたは Unity カタログ ボリュームに配置できます。- ワークスペース ファイルを使用する場合、パスは絶対パスで、
/Workspace/で始まる必要があります。 - Unity カタログ ボリュームでファイルを使用する場合、パスは次の形式にする必要があります:
/Volumes/<catalog>/<schema>/<volume>/<path>.whl。
- ワークスペース ファイルを使用する場合、パスは絶対パスで、
Apply をクリックして依存関係をインストールし、Python プロセスを再起動します。
Important
サーバーレス ノートブックには、PySpark または PySpark を依存関係としてインストールするライブラリをインストールしないでください。 インストールすると、セッションが停止しエラーが発生します。 これが発生した場合は、そのライブラリを削除し、環境をリセットしてください。
インストールされている依存関係を表示するには、[環境] サイド ウィンドウの [インストール済み] タブをクリックします。 ウィンドウの下部にある pip ログ をクリックして、ノートブック環境の pip インストール ログを開きます。
Note
ワークスペース管理者は、プライベートまたは認証済みのパッケージ リポジトリを、サーバーレス ノートブックとジョブの既定の pip ソースとして構成できます。 これにより、ユーザーは index-url や extra-index-urlを指定せずに、内部リポジトリからパッケージをインストールできます。
パッケージ リポジトリの既定のPython構成を参照してください。
カスタム環境仕様を作成する
カスタム環境仕様を作成して再利用できます。
- サーバーレス ノートブックで、基本環境を選択し、必要な依存関係をインストールします。
- Kebab メニュー ボタンの
 をクリックします。環境ウィンドウの下部にある [ 環境のエクスポート] をクリックします。
をクリックします。環境ウィンドウの下部にある [ 環境のエクスポート] をクリックします。 - 仕様をワークスペース ファイルまたは Unity カタログ ボリュームとして保存します。 宛先に書き込むアクセス許可があることを確認してください。または、エクスポートが
Forbiddenエラーで失敗します。
ノートブックでカスタム環境仕様を使用するには、[基本環境] ドロップダウン メニューから [カスタム] を選択し、フォルダー ![]() を使用します。YAML ファイルを選択します。
を使用します。YAML ファイルを選択します。
ワークスペース間で共有する一般的なツールを作成する
この例では、ワークスペース ファイルにユーティリティを格納し、サーバーレス ノートブックの依存関係としてインストールします。
次の構造のフォルダーを作成します。 他のユーザーがこのパスへの読み取りアクセス権を持っていることを確認します。
helper_utils/ ├── helpers/ │ └── __init__.py # your common functions live here ├── pyproject.tomlpyproject.tomlを次の形式で入力してください。[project] name = "common_utils" version = "0.1.0"init.pyファイルに関数を追加します。 例えば次が挙げられます。def greet(name: str) -> str: return f"Hello, {name}!"ノートブック UI で、[ 環境 ] サイド ウィンドウの
![[環境] アイコン](../../_static/images/product-icons/slidersicon.svg) をクリックします。
をクリックします。[ 依存関係 ] セクションで、[ 依存関係の追加 ] をクリックし、util ファイルのパスを入力します。 たとえば、
/Workspace/helper_utilsと指定します。[適用] をクリックします。
これで、ノートブックで関数を使用できるようになりました。
from helpers import greet
print(greet('world'))
これは次のように出力されます。
Hello, world!
AI ランタイム (サーバーレス GPU) の使用
Important
AI ランタイムは パブリック プレビュー段階です。
Azure Databricks ノートブックで、サーバーレス GPU コンピューティングを利用して AI ランタイムを構成するには、次の手順に従います。
- ノートブックで、上部にあるコンピューティング ドロップダウン メニューをクリックし、[ サーバーレス GPU] を選択します。
- [ をクリックして、[ 環境 ] サイド ウィンドウを開きます。
- [アクセラレータ] フィールドから A10 を選択します。
- ベース環境 で、既定の環境には Standard を、機械学習(ML)ライブラリがあらかじめインストールされた AI に最適化された環境には AI を選択します。
- [ 適用 ] をクリックし、AI ランタイムをノートブック環境に適用することを 確認 します。
詳細については、 AI ランタイムに関するページを参照してください。
高メモリ サーバーレス コンピューティングを使用する
Important
この機能は パブリック プレビュー段階です。
ノートブックでメモリ不足エラーが発生した場合は、より大きなメモリ サイズを使用するようにノートブックを構成します。 このメモリ サイズ設定により、ノートブックでコードを実行するときに使用される REPL メモリのサイズが大きくなります。 Spark セッションのメモリ サイズには影響しません。 メモリが多いサーバーレス使用量は、標準メモリよりも DBU の放射率が高くなります。
使用可能なメモリ オプションは次のとおりです。
- Standard: 16 GB の合計メモリ。
- 高: 合計 32 GB のメモリ。
ノートブックのメモリ設定を構成するには:
- ノートブック UI で、[ 環境 ] サイド ウィンドウ をクリックします。
- [メモリ] で、[大容量メモリ] を選択します。
- [適用] をクリックします。
このメモリ設定は、ノートブックのメモリ設定を使用して実行されるノートブック ジョブ タスクにも適用されます。 ノートブックのメモリ設定を更新すると、次のジョブの実行に影響します。
サーバーレス使用ポリシーを選択する
Important
この機能は パブリック プレビュー段階です。
サーバーレス使用ポリシーを 使用すると、組織は、詳細な課金属性のために、サーバーレスの使用状況にカスタム タグを適用できます。
ワークスペースでサーバーレス使用ポリシーが使用されている場合は、ノートブックに適用するポリシーを選択します。 ユーザーが 1 つのサーバーレス使用ポリシーにのみ割り当てられている場合、そのポリシーは既定で適用されます。
サーバーレス コンピューティングに接続した後、[ 環境 ] サイド ウィンドウからポリシーを選択します。
- ノートブック UI で、[ 環境 ] サイド ウィンドウ をクリックします。
- [ サーバーレス使用ポリシー ] で、ノートブックに適用するサーバーレス使用ポリシーを選択します。
- [適用] をクリックします。
適用後、すべてのノートブックの使用状況でポリシーのカスタム タグが取得されます。
Note
ノートブックが Git リポジトリから作成された場合、または サーバーレス使用ポリシーが割り当てられない場合は、次にサーバーレス コンピューティングにアタッチされるときに、最後に選択したサーバーレス使用ポリシーが既定で設定されます。
ソース ファイルのエクスポートに環境を含める
Python ノートブックの場合は、環境設定でソース ファイルのエクスポートに含めるをオンまたはオフにできます。 有効にすると、基本環境と依存関係は、ソース ファイルのエクスポートで PEP 723 形式で格納されます。 これにより、ノートブックが Git フォルダー に格納されるか 、ソース ファイルとしてダウンロードされるときに、環境の構成を保持できます。
たとえば、 Standard v5 を使用するノートブックでは、その環境構成がインライン メタデータとしてファイルの先頭にエクスポートされます。
# Databricks notebook source
# /// script
# [tool.databricks.environment]
# environment_version = "5"
# ///
print("Hello World!")
環境の依存関係をリセットする
ノートブックがサーバーレス コンピューティングに接続されている場合、Databricks はノートブックの仮想環境のコンテンツを自動的にキャッシュします。 つまり、一般に、既存のノートブックを開くときに、Environment サイド ウィンドウで指定されたPython依存関係を再インストールする必要はありません。これは、非アクティブ状態が原因で切断されている場合でもです。
Python仮想環境のキャッシュもジョブに適用されます。 ジョブを実行すると、同じ実行で完了したタスクと同じ依存関係のセットを共有するタスクは、キャッシュに必要な依存関係が既に含まれているため、より高速に完了します。
Note
サーバーレスのジョブで使用されるカスタム Python パッケージの実装を変更する場合は、ジョブが最新の実装を取得できるように、そのバージョン番号も更新する必要があります。
環境キャッシュをクリアし、サーバーレス コンピューティングに接続されているノートブックの [環境 ] サイド ウィンドウで指定された依存関係の新しいインストールを実行するには、[ 適用 ] の横にある矢印をクリックし、[ 既定値にリセット] をクリックします。
コア ノートブックまたは Apache Spark 環境を中断または変更するパッケージをインストールする場合は、問題のあるパッケージを削除してから、環境をリセットします。 新しいセッションを開始しても、環境キャッシュ全体がクリアされるわけではありません。
ジョブ タスクの環境を構成する
各ジョブ タスクは、基本環境と指定した追加のライブラリを含む分離された環境で実行されます。 基本環境では、Pythonと Scala ランタイムのバージョンとプレインストールされたライブラリが設定されます。 タスクは、インストールされているライブラリの既定のセットを環境バージョンから継承します。 何が含まれているかを確認するには、インストールされているPythonライブラリまたは使用しているenvironment バージョンのJavaライブラリと Scala ライブラリセクションを参照してください。
事前にインストールされたライブラリを 、ワークスペース ファイル、Unity カタログ ボリューム、またはパブリック パッケージ リポジトリのライブラリで補完できます。 タスクに必要な依存関係のみが実行時にインストールされます。
Important
JAR タスクにサーバーレス コンピューティングを使用することは、 パブリック プレビュー段階です。
Important
マネージド ベース環境の選択はベータ版です。 [環境の構成] ダイアログの [基本環境] ドロップダウンでは、Databricks が提供する環境 (Standard や ML など) またはワークスペースで構成された環境から選択できます。 この機能がない場合、ダイアログには代わりに [環境バージョン ] ドロップダウンが表示されます。 ワークスペース管理者は、[ プレビュー] ページからこの機能を有効にすることができます。
![Databricks 環境とワークスペース環境セクションで展開された [基本環境] ドロップダウンを示す [環境の構成] ダイアログ](../../_static/images/serverless-compute/jobs-configure-environment-base-env.png)
タスクの種類別に環境を構成する
ジョブで環境を構成する方法は、タスクの種類によって異なります。
ノートブックのタスク
ノートブック タスクは既定で Notebook Environment に設定され、ノートブック独自に構成された基本環境と依存関係が使用されます。 ジョブレベルの環境でこれを上書きできます。
![ノートブック環境とジョブ環境のオプションを示すノートブック タスクの [環境とライブラリ] ドロップダウン](../../_static/images/serverless-compute/jobs-notebook-task-environment-dropdown.png)
ジョブレベル環境を設定するには:
- タスクの構成で、[ 環境とライブラリ ] ドロップダウン メニューをクリックします。
- ジョブ環境で、[既定] の横にある鉛筆アイコンをクリックするか、[+ 新しいジョブ環境の追加] をクリックします。
- [ 環境の構成 ] ダイアログで、[ 基本環境 ] ドロップダウン メニューから選択します。
- Databricks 環境: Standard、ML などのAzure Databricks指定のオプション。
- ワークスペース環境: ワークスペース管理者によって構成されたカスタム環境。 「ワークスペースの基本環境を管理する」を参照してください。
- その他: 以前のバージョンと カスタム (YAML ファイルを指定)。
- [ 依存関係] で、ライブラリを追加します。 requirements.txt ファイルで有効な任意の形式でライブラリを指定することも、ワークスペース ファイルまたは Unity カタログ ボリュームへの絶対パスを使用することもできます。
- 確定 をクリックします。
Note
ワークスペースでジョブのプレビュー用のワークスペース基本環境が有効になっていない場合、[環境の構成] ダイアログには、[基本環境] ではなく [環境バージョン] ドロップダウンが表示されます。
環境を構成するには、バージョンを選択し、[ + ライブラリの追加] をクリックします。 ワークスペース ファイル パス ( /Workspace/ 以降)、Unity カタログ ボリューム パス ( /Volumes/ 以降)、または要件ファイル参照 ( -r /Workspace/path/to/requirements.txt など) を指定できます。
Python スクリプト タスクと Python ホイール タスク
Python スクリプト タスクおよび Python ホイール タスクでは、環境を設定しておく必要があります。
![[依存関係の追加] リンクが表示された Python ホイール タスクの [Environment and Libraries](環境とライブラリ)セクション](../../_static/images/serverless-compute/jobs-python-task-add-dependency.png)
- タスク構成の [ 環境とライブラリ] で、[ + 依存関係の追加] をクリックします。
- [ 環境の構成 ] ダイアログで、[ 基本環境 ] ドロップダウン メニューから選択します。
- Databricks 環境: Standard、ML などのAzure Databricks指定のオプション。
- ワークスペース環境: ワークスペース管理者によって構成されたカスタム環境。 「ワークスペースの基本環境を管理する」を参照してください。
- その他: 以前のバージョンと カスタム (YAML ファイルを指定)。
- [ 依存関係] で、ライブラリを追加します。
- 確定 をクリックします。
Note
ワークスペースでジョブのプレビュー用のワークスペース基本環境が有効になっていない場合、[環境の構成] ダイアログには、[基本環境] ではなく [環境バージョン] ドロップダウンが表示されます。
環境を構成するには、バージョンを選択し、[ + ライブラリの追加] をクリックします。 ワークスペース ファイル パス ( /Workspace/ 以降)、Unity カタログ ボリューム パス ( /Volumes/ 以降)、または要件ファイル参照 ( -r /Workspace/path/to/requirements.txt など) を指定できます。
Dbt タスク
DBT タスクは、ライブラリ構成にジョブ レベルの環境を使用します。
![ジョブ環境オプションを示す dbt タスクの [環境とライブラリ] ドロップダウン](../../_static/images/serverless-compute/jobs-dbt-task-environment-dropdown.png)
ジョブレベル環境を設定するには:
- タスクの構成で、[ 環境とライブラリ ] ドロップダウン メニューをクリックします。
- ジョブ環境で、既存の環境の横にある鉛筆アイコンをクリックするか、[+ 新しいジョブ環境の追加] をクリックします。
- [ 環境の構成 ] ダイアログで、[ 基本環境 ] ドロップダウン メニューから選択します。
- Databricks 環境: Standard、ML などのAzure Databricks指定のオプション。
- ワークスペース環境: ワークスペース管理者によって構成されたカスタム環境。 「ワークスペースの基本環境を管理する」を参照してください。
- その他: 以前のバージョンと カスタム (YAML ファイルを指定)。
- [ 依存関係] で、ライブラリを追加します。 requirements.txt ファイルで有効な任意の形式でライブラリを指定することも、ワークスペース ファイルまたは Unity カタログ ボリュームへの絶対パスを使用することもできます。
- 確定 をクリックします。
Note
ワークスペースでジョブのプレビュー用のワークスペース基本環境が有効になっていない場合、[環境の構成] ダイアログには、[基本環境] ではなく [環境バージョン] ドロップダウンが表示されます。
環境を構成するには、バージョンを選択し、[ + ライブラリの追加] をクリックします。 ワークスペース ファイル パス ( /Workspace/ 以降)、Unity カタログ ボリューム パス ( /Volumes/ 以降)、または要件ファイル参照 ( -r /Workspace/path/to/requirements.txt など) を指定できます。
JAR タスク
ワークスペースの基本環境は、JAR タスクではサポートされていません。 JAR タスクの環境を構成するには:
![JAR 依存関係の追加リンクを示す JAR タスクの [環境とライブラリ] セクション](../../_static/images/serverless-compute/jobs-jar-task-add-dependency.png)
- タスク構成の [ 環境とライブラリ] で、[ + JAR 依存関係の追加] をクリックします。
- [ 環境の構成 ] ダイアログで、次の手順を実行します。
- 必要に応じて、[ 基本環境 ] フィールドに YAML ファイルへのパスを入力します。
- [環境バージョン] ドロップダウン メニューから 環境バージョン を選択します。
- [ JAR 依存関係] で、JAR ファイルへのパスを追加します。
- 確定 をクリックします。
カスタム YAML ベースの基本環境を作成するには、「 カスタム環境仕様の作成」を参照してください。
環境とコンピューティングの互換性
選択する基本環境は、タスクのコンピューティングの種類と互換性がある必要があります。 たとえば、GPU コンピューティング用に構築された環境は、CPU コンピューティングと互換性がありません。 ジョブ UI では、基本環境のドロップダウン メニューで互換性のない環境を使用できません。
ノートブック タスクを構成する場合、コンピューティングの種類 (CPU または GPU) と基本環境はそれぞれ、ジョブ設定またはノートブック設定から取得できます。
- ジョブ レベルでハードウェア アクセラレータ (GPU) を設定する場合は、ジョブ レベルで基本環境も選択する必要があります。 ジョブ レベル アクセラレータでは、ノートブックの環境を使用できません。
- ノートブックを参照するジョブ タスクがあり、参照先のノートブックのコンピューティングの種類 (CPU から GPU など) を更新すると、既存のタスクが構成済みの環境と互換性を持たなくなる可能性があります。 ノートブックのコンピューティング構成を変更した後、ジョブの環境設定を確認します。
- API ユーザーの場合: 基本環境をジョブ レベルで設定したが、ノートブックでコンピューティングの種類が定義されている場合、Azure Databricksは、ジョブの作成時ではなく実行時に互換性を検証します。 構成に互換性がない場合、実行はエラーで失敗します。