このページでは、カタログ エクスプローラーとデータ系列システム テーブルを使用してデータ系列を視覚化する方法について説明します。
データ系列の概要
Unity カタログは、Azure Databricksで実行されるクエリ間でランタイム データ系列をキャプチャします。 系列はすべての言語でサポートされ、列レベルまで取得されます。 系列データには、クエリに関連するノートブック、ジョブ、ダッシュボードが含まれます。 系列は、カタログ エクスプローラーでほぼリアルタイムで視覚化でき、系列システム テーブルを使用してプログラムで取得できます。
系列には、Azure Databricksの外部で実行される外部資産とワークフローを含めることもできます。 この外部系列メタデータ機能はパブリック プレビュー段階です。 「 独自のデータ系列を持ち込む」を参照してください。
系列は、Unity Catalog メタストアにアタッチされているすべてのワークスペースにわたって集約されます。 つまり、1 つのワークスペースでキャプチャされた系列は、そのメタストアを共有する他のワークスペースに表示されます。 具体的には、メタストアに登録されているテーブルとその他のデータ オブジェクトは、メタストアにアタッチされているすべてのワークスペースにわたって、それらのオブジェクトに対する少なくとも BROWSE のアクセス許可を持つユーザーに表示されます。 ただし、他のワークスペースのノートブックやダッシュボードなどのワークスペース レベルのオブジェクトに関する詳細情報はマスクされます ( 系列の制限 と 系列のアクセス許可を参照)。
系列データは無期限に保持されます。 2024 年 9 月 1 日以降にキャプチャされたすべての系列データを利用できます。 その日付より後に作成されたメタストアの場合、カタログ エクスプローラーには系列の時間範囲ドロップダウンに [すべての時刻 ] オプションが含まれます。 古いメタストアの場合、ドロップダウンには、2024 年 9 月 1 日から始まる すべての使用可能な オプションが含まれています。 既定の選択は 1 年です。
以下は系列グラフのサンプル画像です。
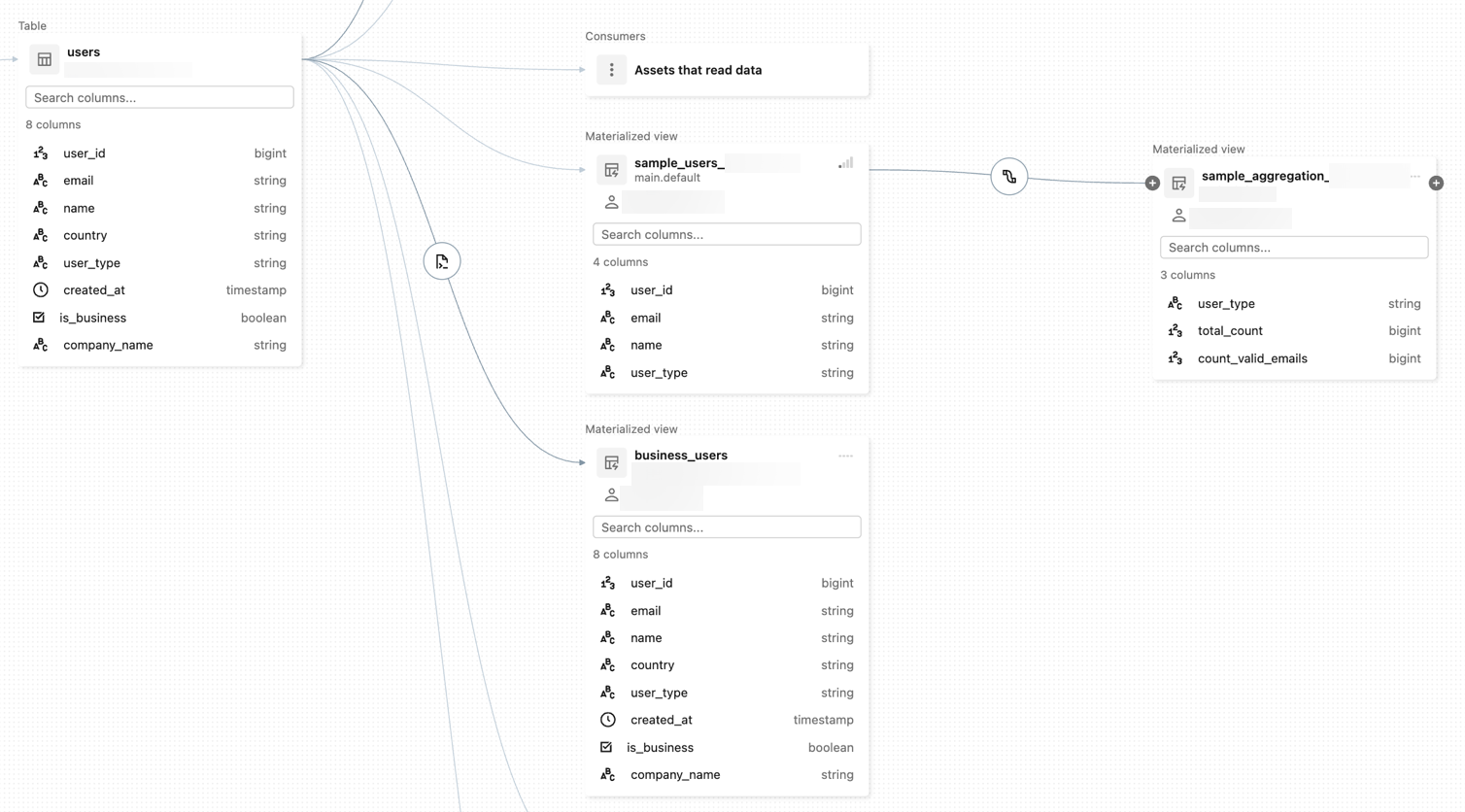
データ系列の表示のデモについては、「 Unity カタログ - データ系列」を参照してください。
機械学習モデルの系列追跡については、「Unity Catalog でモデルのデータ系列を追跡する」を参照してください。
要件
Unity カタログを使用してデータ系列をキャプチャするには:
- テーブルは Unity Catalog メタストアに登録する必要があります。
- 外部アセット (Unity カタログ メタストアに登録されていないもの) は、Unity カタログの 外部メタデータ オブジェクトとして追加する必要があります。このオブジェクトは、Unity カタログメタストアに登録されている他のセキュリティ保護可能なオブジェクトとの関係を持つよう構成されている必要があります。 「 独自のデータ系列を持ち込む」を参照してください。
- クエリでは、Spark DataFrame (DataFrame を返す Spark SQL 関数など) またはノートブックや SQL クエリ エディターなどの Databricks SQL インターフェイスを使用する必要があります。
データ系列を表示するには:
- テーブルまたはビューの親カタログに対する
BROWSE権限が少なくとも必要です。 親カタログにもワークスペースからアクセスできる必要があります。 「特定のワークスペースにカタログ アクセスを制限する」を参照してください。 - ノートブック、ジョブ、またはダッシュボードの場合、ワークスペースのアクセス制御設定で定義されているこれらのオブジェクトに対するアクセス許可が必要です。 詳細については、「 系列のアクセス許可」を参照してください。
- Unity カタログ対応パイプラインの場合は、パイプラインに対する CAN VIEW アクセス許可が必要です。
コンピューティング要件:
- Delta テーブル間のストリーミングの系列追跡には、Databricks Runtime 11.3 LTS 以降が必要です。
- Lakeflow Spark 宣言パイプライン ワークロードの列系列の追跡には、Databricks Runtime 13.3 LTS 以降が必要です。
ネットワーク要件:
- Azure Databricks コントロール プレーン内の Event Hubs エンドポイントへの接続を許可するように、送信ファイアウォール規則を更新することが必要になる場合があります。 通常、これは、Azure Databricks ワークスペースが独自の VNet (VNet インジェクションとも呼ばれます) にデプロイされている場合に適用されます。 ワークスペース リージョンの Event Hubs エンドポイントを取得するには、「メタストア、成果物 BLOB ストレージ、システム テーブル ストレージ、ログ BLOB ストレージ、Event Hubs エンドポイントの IP アドレス」を参照してください。 Azure Databricks用にユーザー定義ルート (UDR) を設定する方法については、「
Azure Databricks 。
カタログ エクスプローラーを使用してデータ系列を表示する
カタログ エクスプローラーを使用してテーブル系列を表示するには:
Azure Databricks ワークスペースで、
 Catalog をクリックします。
Catalog をクリックします。テーブルを検索または参照します。
[ 系列 ] タブを選択します。系列パネルが表示され、関連テーブルが表示されます。
データ系列のインタラクティブ グラフを表示するには、[See Lineage Graph] (系列グラフの表示) をクリックします。
既定では、1 つのレベルがグラフに表示されます。 ノード上の
 アイコンをクリックすると、追加の接続情報があれば表示されます。
アイコンをクリックすると、追加の接続情報があれば表示されます。系列グラフ内の各ノードを接続する矢印をクリックして、[系列接続] パネルを開きます。
その接続の詳細 (ソースとターゲットのテーブル、ノートブック、ジョブなど) が [系列接続] パネルに表示されます。
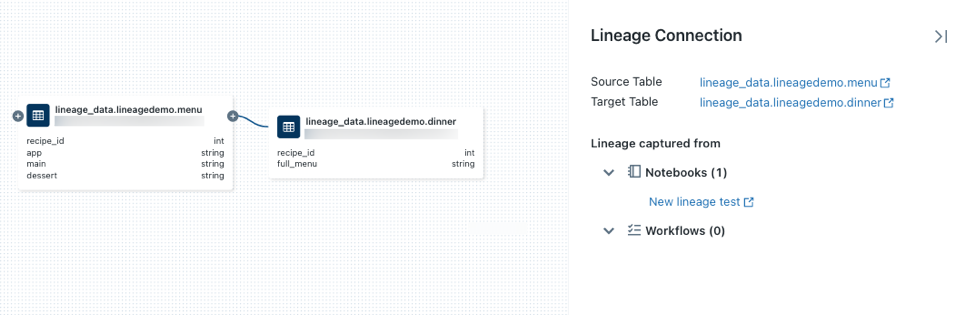
テーブルに関連付けられているノートブックを表示するには、[ 系列接続 ] パネルでノートブックを選択するか、系列グラフを閉じて [ ノートブック] をクリックします。
新しいタブでノートブックを開くには、ノートブック名をクリックします。
列レベルの系列を表示するには、グラフ内の列をクリックして、関連する列へのリンクを表示します。 たとえば、このサンプル グラフの
full_menu列をクリックすると、列が派生した上流の列が表示されます。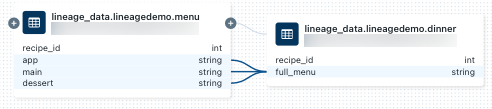
ジョブ系列の表示
ジョブ系列を表示するには、テーブルの [ 系列 ] タブに移動し、[ ジョブ] を選択して、[ダウンストリーム] を選択 します。 ジョブ名は、テーブルのコンシューマーとして [ジョブ名] の下に表示されます。
ダッシュボードの系列を表示する
ダッシュボード系列を表示するには、テーブルの [ 系列 ] タブに移動し、[ ダッシュボード] をクリックします。 ダッシュボードは、テーブルのコンシューマーとして [ダッシュボード名] の下に表示されます。
Genie Code を使用してテーブル系列を取得する
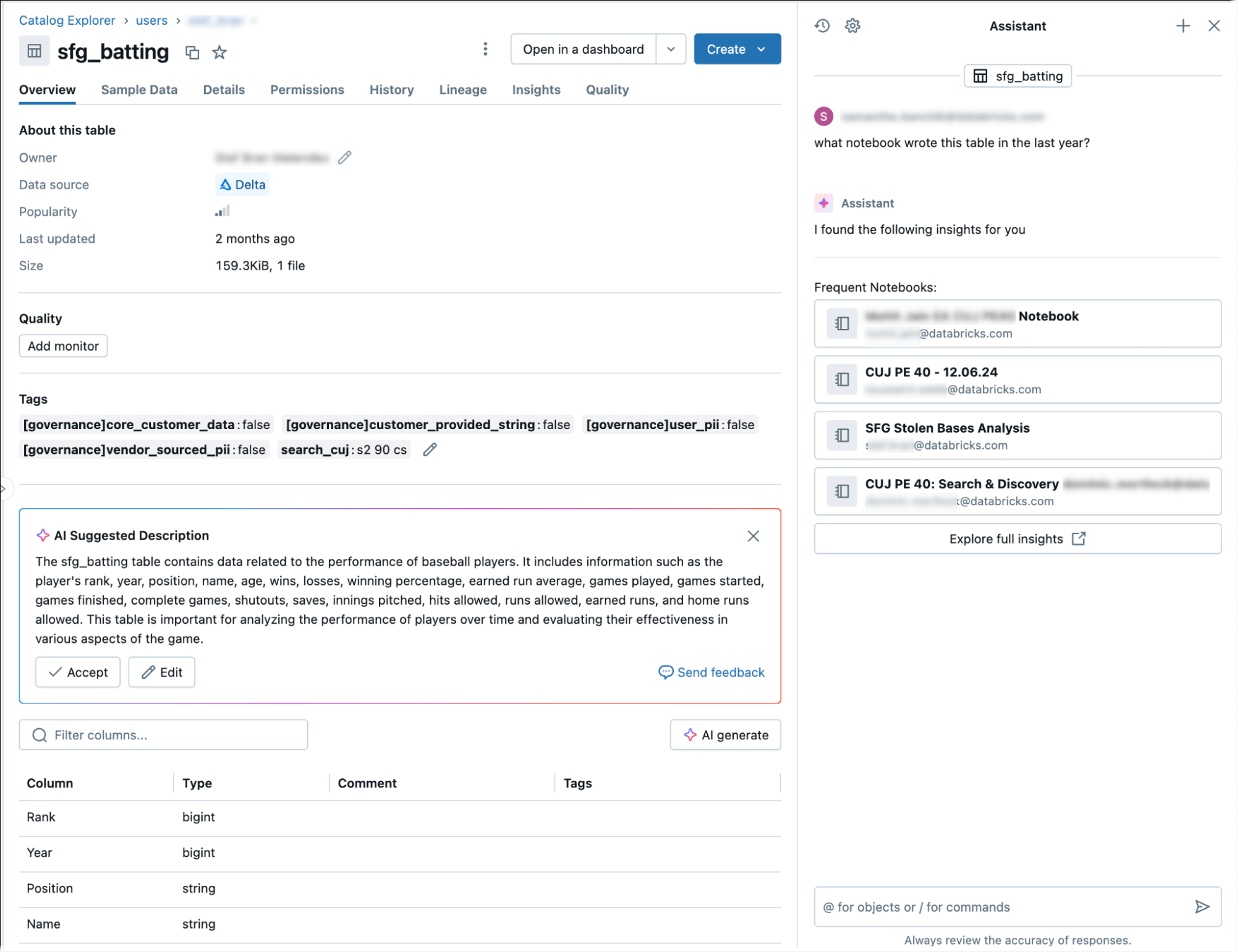
Genie Code では、テーブルの系列と分析情報に関する詳細情報が提供されます。
Genie Code を使用して系列情報を取得するには:
- ワークスペースのサイドバーで、[データ] アイコンをクリック カタログ。
- カタログを参照または検索し、カタログ名をクリックします。その後、右上隅にあるアシスタントの色アイコンをクリックし、Genie Code アイコンをクリックします。
- Genie Code プロンプトで、次のように入力します。
- /getTableLineages を使用してアップストリームとダウンストリームの依存関係を表示します。
- /getTableInsights を使用して、ユーザー アクティビティやクエリ パターンなどのメタデータ駆動型の分析情報にアクセスします。
これらのクエリを使用すると、Genie Code は、"ダウンストリーム系列を表示する" や "このテーブルに最も頻繁にクエリを実行するユーザー" などの質問に回答できます。
システム テーブルを使用して系列データをクエリする
系列システム テーブルを使用して、系列データをプログラムでクエリできます。 詳細な手順については、 システム テーブルのリファレンス と 系列システム テーブルのリファレンスを参照してください。
系列のアクセス許可
系列グラフは、Unity Catalog と同じ アクセス許可モデル を共有します。 Unity カタログ メタストアに登録されているテーブルおよびその他のデータ オブジェクトは、それらのオブジェクトに対するアクセス許可が少なくとも BROWSE ユーザーにのみ表示されます。 ユーザーがテーブルに対する BROWSE または SELECT 権限を持っていない場合、その系列を調べることはできません。 系列グラフは、ユーザーが適切なオブジェクト権限を持っている限り、メタストアにアタッチされているすべてのワークスペースにわたって Unity カタログ オブジェクトを表示します。
たとえば、userAに対して次のコマンドを実行します。
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
たとえば、userA が lineage_data.lineagedemo.menu テーブルの系列グラフを表示すると、menu テーブルを確認できます。 しかし、下流の lineage_data.lineagedemo.dinner テーブルなど、関連する他のテーブル情報は参照できません。
dinner に対する表示では、masked テーブルが userA ノードとして表示されます。userA がグラフを展開して、自分に権限がないテーブルのダウンストリーム テーブルを表示することはできません。
次のコマンドを実行して、BROWSEにuserBアクセス許可を付与すると、そのユーザーは、lineage_data スキーマ内の任意のテーブルの系列グラフを表示できます。
GRANT BROWSE on lineage_data to `userB@company.com`;
同様に、系列ユーザーには、ノートブック、ジョブ、ダッシュボードなどのワークスペース オブジェクトを表示するための特定のアクセス許可が必要です。 さらに、ワークスペース オブジェクトが作成されたワークスペースにログインしている場合にのみ、ワークスペース オブジェクトに関する詳細情報を表示できます。 他のワークスペース内のワークスペース レベルのオブジェクトに関する詳細情報は、系列グラフでマスクされます。
Unity Catalog でセキュリティ保護可能なオブジェクトへのアクセスの管理については、「Unity Catalog で権限を管理する」を参照してください。 ノートブック、ジョブ、ダッシュボードなどのワークスペース オブジェクトへのアクセスの管理については、「アクセス制御リスト」を参照してください。
系列の制限
データ系列には、次の制限があります。 これらの制限は、系列システム テーブルにも適用されます。
- 系列は、同じ Unity カタログ メタストアにアタッチされているすべてのワークスペースに対して集計されますが、ノートブックやダッシュボードなどのワークスペース オブジェクトの詳細は、作成されたワークスペースにのみ表示されます。
- 2024 年 9 月 1 日より前にキャプチャされた系列データは使用できません。
- ジョブ API
runs submit要求またはspark submitタスクの種類を使用するジョブは、系列ビューでは使用できません。 これらのワークフローのテーブル レベルと列レベルの系列は引き続きキャプチャされますが、ジョブ実行へのリンクはキャプチャされません。 - 名前が変更されたオブジェクトの系列は保持されません。これは、カタログ、スキーマ、テーブル、ビュー、および列に適用されます。
- Spark SQL データセットのチェックポイントを使用する場合、系列はキャプチャされません。
- Unity カタログは、ほとんどの場合、Lakeflow Spark 宣言パイプラインから系列をキャプチャします。 ただし、パイプラインで PRIVATE テーブルを使用する場合など、完全な系列カバレッジを保証できない場合があります。
- 回復性のある分散データセット (RDD) は系列にキャプチャされません。
- グローバル一時ビューは系列に記録されません。
- トランザクションは、 読み取りと書き込みが行われるたびに系列を生成します。 系列イベントは、トランザクションがロールバックされた場合でも保持されます。
-
system.information_schema下にあるテーブルは系列に記録されません。 - Unity Catalog は、可能な限り列レベルに系列を取り込みます。 ただし、列レベルの系列を取り込むことができない場合があります。 次に示します。
ソースまたはターゲットがパスとして参照されている場合、列の系列をキャプチャできません (例:
select * from delta."s3://<bucket>/<path>")。 列の系列は、ソースとターゲットの両方がテーブル名で参照されている場合にのみサポートされます (例:select * from <catalog>.<schema>.<table>)。ユーザー定義関数 (UDF) を使用すると、ソース列とターゲット列の間のマッピングが隠される可能性があります。