注
この記事では、Databricks Runtime 13.3 LTS 以降用の Databricks Connect について説明します。
Databricks Connect を使用すると、PyCharm、ノートブック サーバー、その他のカスタム アプリケーションなどの一般的な IDE を Azure Databricks コンピューティングに接続できます。 「Databricks Connect とは」を参照してください。
この記事では、PyCharmを使用して Databricks Connect for Python をすぐに使い始める方法について説明します。
- この記事の R バージョンについては、「Databricks Connect for R」を参照してください。
- この記事の Scala バージョンについては、「Databricks Connect for Scala」を参照してください。
チュートリアル
次のチュートリアルでは、PyCharm でプロジェクトを作成し、Databricks Connect for Databricks Runtime 13.3 LTS 以降をインストールし、PyCharm から Databricks ワークスペースのコンピューティングで単純なコードを実行します。 詳細と例については、「次の手順を参照してください。
必要条件
このチュートリアルを完了するには、次の要件を満たす必要があります。
- ターゲットの Azure Databricks ワークスペースで Unity カタログが有効になっている必要がある。
- PyCharm がインストールされている。 このチュートリアルは、PyCharm Community Edition 2023.3.5 でテストされました。 別のバージョンまたはエディションの PyCharm を使用する場合、次の手順は異なる場合があります。
- ローカル環境とコンピューティングは、Databricks Connect for Python インストール バージョンの要件満たしています。
- クラシック コンピューティングを使用している場合は、クラスターの ID が必要です。 クラスター ID を取得するには、ワークスペースでサイドバーの [コンピューティング ] をクリックし、クラスターの名前をクリックします。 Web ブラウザーのアドレス バーで、URL の
clustersとconfigurationの間で文字の文字列をコピーします。
手順 1: Azure Databricks 認証を構成する
このチュートリアルでは、Azure Databricks ワークスペースへの認証に、Azure Databricks OAuth User-to-Machine (U2M) 認証と Azure Databricks 構成プロファイルを使用します。 別の認証の種類を使うには、「接続プロパティの構成」をご覧ください。
OAuth U2M 認証を構成するには、Databricks CLI が必要です。 Databricks CLI のインストールの詳細については、「Databricks CLI のインストールまたは更新」を参照してください。
次のように OAuth U2M 認証を開始します。
Databricks CLI を使用して、ターゲット ワークスペースごとに次のコマンドを実行して、OAuth トークン管理をローカルで開始します。
次のコマンド内では、
<workspace-url>を Azure Databricks ワークスペース単位の URL (例:https://adb-1234567890123456.7.azuredatabricks.net) に置き換えます。databricks auth login --configure-cluster --host <workspace-url>ヒント
Databricks Connect でサーバーレス コンピューティングを使用するには、「 サーバーレス コンピューティングへの接続を構成する」を参照してください。
Databricks CLI では、入力した情報を Azure Databricks 構成プロファイルとして保存するように求められます。
Enterキーを押して提案されたプロファイル名を受け入れるか、新規または既存のプロファイル名を入力します。 同じ名前の既存のプロファイルは、入力した情報で上書きされます。 プロファイルを使用すると、複数のワークスペース間で認証コンテキストをすばやく切り替えることができます。既存のプロファイルの一覧を取得するには、別のターミナルまたはコマンド プロンプト内で、Databricks CLI を使用してコマンド
databricks auth profilesを実行します。 特定のプロファイルの既存の設定を表示するには、コマンドdatabricks auth env --profile <profile-name>を実行します。Web ブラウザーで、画面の指示に従って Azure Databricks ワークスペースにログインします。
ターミナルまたはコマンド プロンプトに表示される使用可能なクラスターのリストで、上下の方向キーを使ってワークスペース内のターゲット Azure Databricks クラスターを選び、
Enterキーを押します。 クラスターの表示名の任意の部分を入力して、使用可能なクラスターの一覧をフィルター処理することもできます。プロファイルの現在の OAuth トークン値とトークンの今後の有効期限のタイムスタンプを表示するには、次のいずれかのコマンドを実行します。
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
同じ
--host値を持つ複数のプロファイルがある場合は、Databricks CLI が正しく一致する OAuth トークン情報を見つけるのに役立つ--hostと-pのオプションを一緒に指定することが必要になる場合があります。
手順 2: プロジェクトを作成する
- PyCharm を起動します。
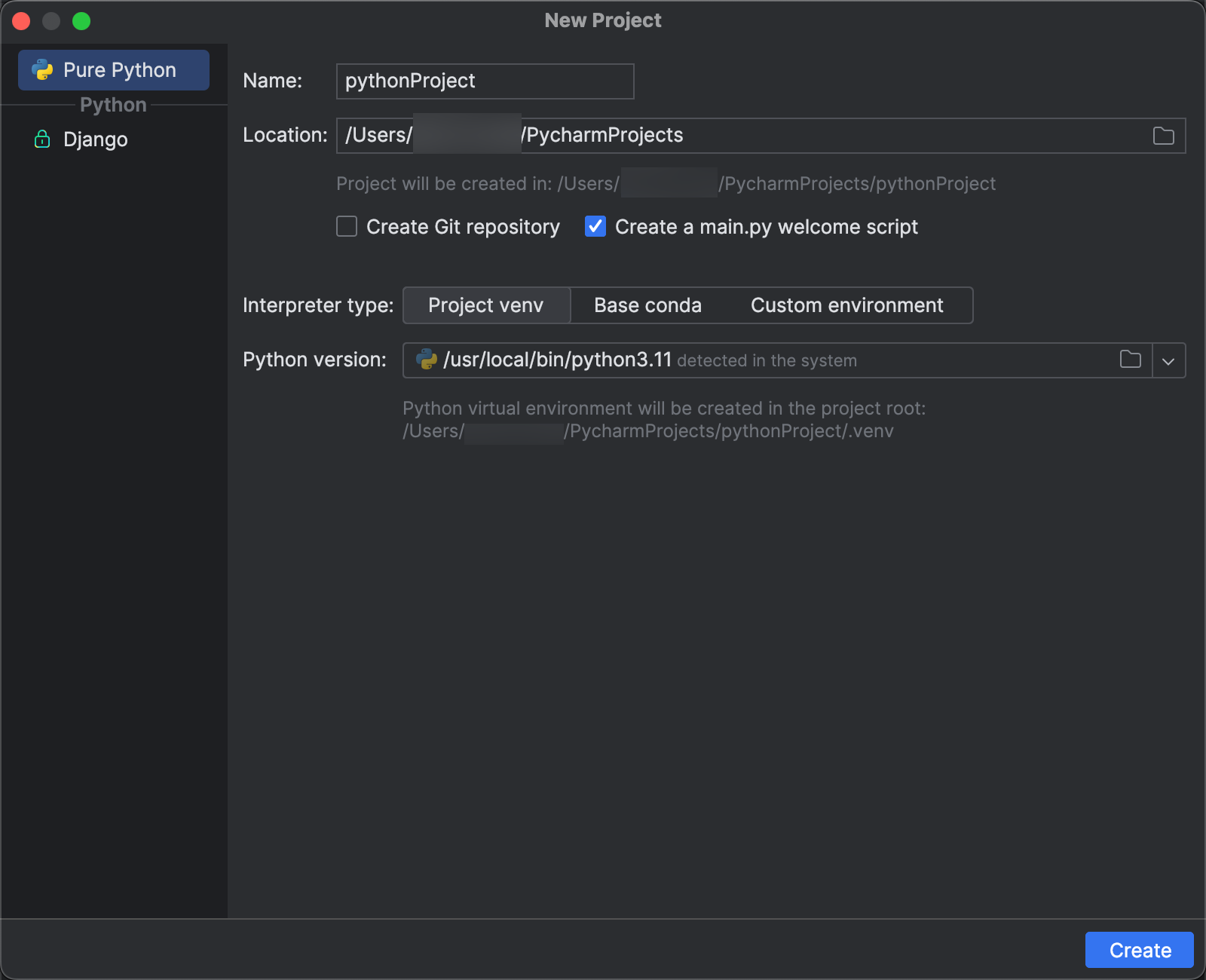
- メイン メニューで、[ファイル]>[新しいプロジェクト] の順にクリックします。
- [新しいプロジェクト] ダイアログで [Pure Python] をクリックします。
- [場所] の場合、フォルダー アイコンをクリックし、画面上の指示を完了して、新しい Python プロジェクトへのパスを指定します。
- [Create a main.py welcome script] (main.py ウェルカム スクリプトの作成) は選択したままにします。
- [Interpreter type] (インタープリターの種類) で、[Project venv] を選択します。
- [Python バージョン] を展開し、フォルダー アイコンまたはドロップダウン リストを使用して、上記の要件から Python インタープリターへのパスを指定します。
- Create をクリックしてください。
手順 3: Databricks Connect パッケージを追加する
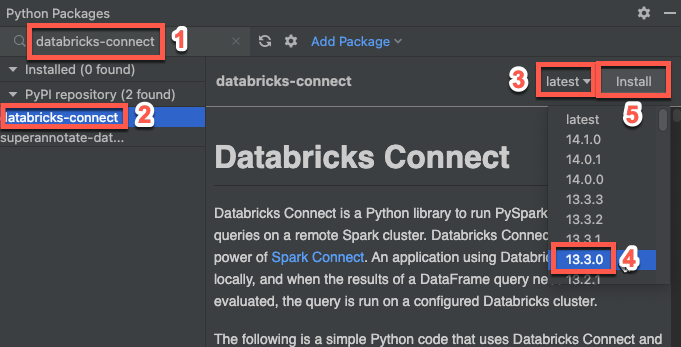
- PyCharm のメイン メニューで、[ View > Tool Windows > Python Packages] をクリックします。
- 検索ボックスに「
databricks-connect」と入力します。 - PyPI リポジトリの一覧で、databricks-connect をクリックします。
- 結果ウィンドウの 最新 のドロップダウン リストで、クラスターの Databricks Runtime バージョンに一致するバージョンを選択します。 たとえば、クラスターに Databricks Runtime 14.3 がインストールされている場合は、[14.3.1] を選択します。
- [パッケージのインストール] をクリックします。
- パッケージがインストールされたら、[Python パッケージ] ウィンドウを閉じることができます。
手順 4: コードを追加する
[プロジェクト] ツール ウィンドウで、プロジェクトのルート フォルダーを右クリックし、[新しい> Python ファイル] をクリックします。
「
main.py」と入力して、[Python ファイル] をダブルクリックします。構成プロファイルの名前に応じて、次のコードをファイルに入力してファイルを保存します。
手順 1 の構成プロファイルの名前が
DEFAULTの場合は、次のコードをファイルに入力して、ファイルを保存します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)手順 1 の構成プロファイルの名前が
DEFAULTではない場合は、代わりに次のコードをファイルに入力します。 プレースホルダー<profile-name>を手順 1 の構成プロファイルの名前に置き換えて、ファイルを保存します。from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
手順 5: コードを実行する
- リモートの Azure Databricks ワークスペースでターゲット クラスターを開始します。
- クラスターが起動したら、メインメニューで 「実行」 > 「main」を実行 をクリックします。
-
[実行] ツール ウィンドウ ([ツール ウィンドウ>実行] >表示) の [実行] タブのメインペインに、
samples.nyctaxi.tripsの最初の5行が表示されます。
手順 6: コードをデバッグする
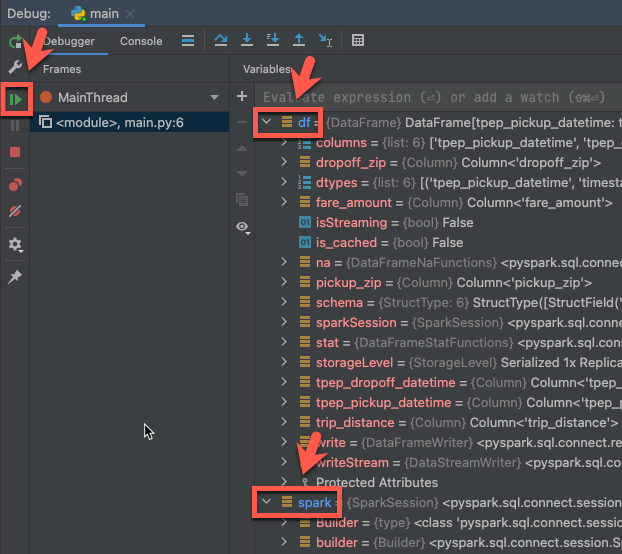
- クラスターがまだ実行中の状態で、前述のコードで、
df.show(5)の横にある余白をクリックしてブレークポイントを設定します。 - メインメニューで > をクリックします。
- デバッグツールウィンドウ (表示 > ツールウィンドウ > >) の>タブの変数ペインで、df変数ノードとspark変数ノードを展開し、コードの変数に関する情報を参照します。
- デバッグ ツール ウィンドウのサイドバーで、緑色の矢印 (プログラムの再開) アイコンをクリックします。
-
[デバッガー] タブの [コンソール] ウィンドウに、
samples.nyctaxi.tripsの最初の 5 行が表示されます。
次のステップ
Databricks Connect の詳細については、次のような記事を参照してください。
- 別の認証の種類を使うには、「接続プロパティの構成」をご覧ください。
- Databricks Connect を他の IDE、ノートブック サーバー、Spark シェルと共に使用します。
- その他の単純なコード例については、「Databricks Connect for Python のコード例」を参照してください。
- より複雑なコード例を表示するには、GitHub の Databricks Connect リポジトリのサンプル アプリケーションを参照してください。具体的には、次を参照してください。
- Databricks Connect で Databricks Utilities を使用するには、「Databricks Utilities と Databricks Connect for Python」を参照してください。
- Databricks Runtime 12.2 LTS 以下用の Databricks Connect から Databricks Runtime 13.3 LTS 以上用の Databricks Connect に移行するには、「Databricks Connect for Python に移行する」を参照してください。
- トラブルシューティングと制限に関する情報も参照してください。