Azure Databricks には、次の場所にあるファイルを操作するための複数のユーティリティと API があります。
- Unity のカタログボリューム
- ワークスペース ファイル
- クラウド オブジェクト ストレージ
- DBFS マウントと DBFS ルート
- クラスターのドライバー ノードに接続されているエフェメラル ストレージ
この記事では、次のツールのこれらの場所にあるファイルを操作する例を示します。
- Apache Spark
- Spark SQL と Databricks SQL
- Databricks ファイル システム ユーティリティ (
dbutils.fsまたは%fs) - Databricks CLI(コマンドラインインターフェース)
- Databricks REST API
- Bash シェル コマンド (
%sh) - ノートブック スコープのライブラリのインストール (
%pipを使用) - パンダ
- OSS Python ファイル管理および処理ユーティリティ
重要
Databricks の一部の操作 (特に Java または Scala ライブラリを使用する操作) は、JVM プロセスとして実行されます。次に例を示します。
- Spark 構成で
--jarsを使用して JAR ファイルの依存関係を指定する - Scala ノートブックでの
catまたはjava.io.Fileの呼び出し - カスタム データ ソース (例:
spark.read.format("com.mycompany.datasource") - Java の
FileInputStreamまたはPaths.get()を使用してファイルを読み込むライブラリ
これらの操作では、 /Volumes/my-catalog/my-schema/my-volume/my-file.csvなどの標準ファイル パスを使用した Unity カタログ ボリュームまたはワークスペース ファイルの読み取りまたは書き込みはサポートされていません。 JAR 依存関係または JVM ベースのライブラリからボリューム ファイルまたはワークスペース ファイルにアクセスする必要がある場合は、まず、Python または %sh コマンド ( %sh mv. など) を使用してローカル ストレージを計算するためにファイルをコピーします。 JVM を使用する %fs と dbutils.fs は使用しないでください。 既にローカルにコピーされているファイルにアクセスするには、Python shutil などの言語固有のコマンドを使用するか、 %sh コマンドを使用します。 クラスターの開始時にファイルが存在する必要がある場合は、最初に init スクリプトを使用してファイルを移動します。 「init スクリプトとは?」を参照してください。
データにアクセスするための URI スキームを指定する必要がありますか?
Azure Databricks のデータ アクセス パスは、次のいずれかの標準に従います。
URI スタイルのパス URI スキームを含めます。 Databricks ネイティブ データ アクセス ソリューションの場合、ほとんどのユース ケースでは URI スキームは省略可能です。 クラウド オブジェクト ストレージ内のデータに直接アクセスする場合は、ストレージの種類に対して適切な URI スキームを指定する必要があります。
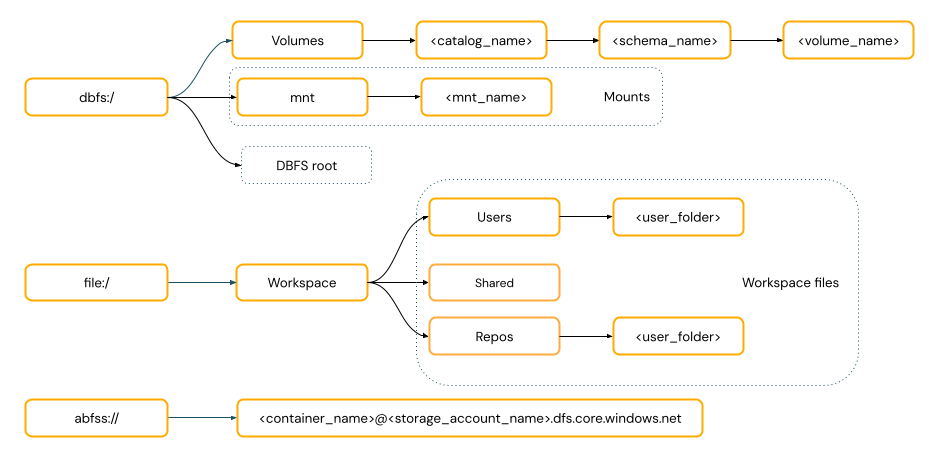
POSIX スタイルのパス、ドライバー ルート (
/) に対するデータ アクセスを提供します。 POSIX スタイルのパスにはスキームは必要ありません。 Unity カタログ ボリュームまたは DBFS マウントを使用して、クラウド オブジェクト ストレージ内のデータへの POSIX スタイルのアクセスを提供できます。 多くの ML フレームワークやその他の OSS Python モジュールでは FUSE が必要であり、POSIX スタイルのパスのみを使用できます。POSIX パスの
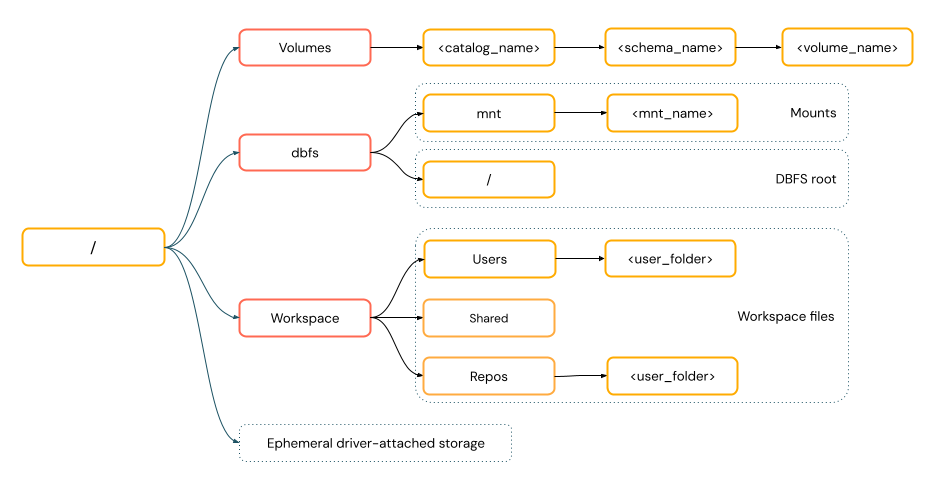
手記
FUSE データ アクセスを必要とするファイル操作は、URI を使用してクラウド オブジェクト ストレージに直接アクセスすることはできません。 Databricks では、Unity カタログ ボリュームを使用して FUSE のこれらの場所へのアクセスを構成することをお勧めします。
専用アクセス モード (以前のシングル ユーザー アクセス モード) と Databricks Runtime 14.3 以降で構成されたコンピューティングでは、Scala では、Scala コマンド "cat /Volumes/path/to/file".!!など、Scala から生成されたサブプロセスを除き、Unity カタログ ボリュームとワークスペース ファイルに対する FUSE がサポートされます。
Unity カタログ ボリューム内のファイルを操作する
Databricks では、Unity カタログ ボリュームを使用して、クラウド オブジェクト ストレージに格納されている表形式以外のデータ ファイルへのアクセスを構成することをお勧めします。 詳細な手順やベスト プラクティスなど、ボリューム内のファイルの管理に関する完全なドキュメントについては、「 Unity カタログ ボリューム内のファイルの操作」を参照してください。
次の例は、さまざまなツールとインターフェイスを使用する一般的な操作を示しています。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL と Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks CLI(コマンドラインインターフェース) | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Bash シェル コマンド | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| ライブラリのインストール | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| オープンソースソフトウェア Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
ボリュームの制限事項と回避策については、「 ボリューム内のファイルを操作する際の制限事項」を参照してください。
ワークスペース ファイルを操作する
Databricks ワークスペース ファイル は、ワークスペース ストレージ アカウントに格納されているワークスペース内のファイルです。 ワークスペース ファイルを使用して、ノートブック、ソース コード ファイル、データ ファイル、その他のワークスペース資産などのファイルを格納およびアクセスできます。
重要
ワークスペース ファイルには サイズ制限があるため、Databricks では、主に開発とテストのために小さなデータ ファイルのみをここに格納することをお勧めします。 他のファイルの種類を格納する場所に関する推奨事項については、「 ファイルの種類」を参照してください。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL と Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks CLI(コマンドラインインターフェース) | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Bash シェル コマンド | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| ライブラリのインストール | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| オープンソースソフトウェア Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
手記
Databricks Utilities、Apache Spark、または SQL を使用する場合は、file:/ スキーマが必要です。
DBFS ルートとマウントが無効になっているワークスペースでは、 dbfs:/Workspace を使用して Databricks ユーティリティを使用してワークスペース ファイルにアクセスすることもできます。 これには、Databricks Runtime 13.3 LTS 以降が必要です。
「既存の Azure Databricks ワークスペースで DBFS ルートとマウントへのアクセスを無効にする」を参照してください。
ワークスペース ファイルの操作に関する制限事項については、「制限事項を参照してください。
削除されたワークスペース ファイルはどこに移動しますか?
ワークスペース ファイルを削除すると、ごみ箱に送信されます。 UI を使用して、ごみ箱からファイルを回復または完全に削除できます。
「オブジェクトを削除する」を参照してください。
クラウド オブジェクト ストレージ内のファイルを操作する
Databricks では、Unity カタログ ボリュームを使用して、クラウド オブジェクト ストレージ内のファイルへの安全なアクセスを構成することをお勧めします。 URI を使用してクラウド オブジェクト ストレージ内のデータに直接アクセスする場合は、アクセス許可を構成する必要があります。 「マネージド ボリュームと外部ボリューム」を参照してください。
次の例では、URI を使用してクラウド オブジェクト ストレージ内のデータにアクセスします。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL と Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path';
|
| Databricks ファイル システム ユーティリティ |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/
|
| Databricks CLI(コマンドラインインターフェース) | サポートされていません |
| Databricks REST API | サポートされていません |
| Bash シェル コマンド | サポートされていません |
| ライブラリのインストール | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | サポートされていません |
| オープンソースソフトウェア Python | サポートされていません |
DBFS マウントと DBFS ルート内のファイルを操作する
重要
DBFS ルートマウントと DBFS マウントはどちらも非推奨であり、Databricks では推奨されません。 新しいアカウントは、これらの機能にアクセスせずにプロビジョニングされます。 Databricks では、代わりに Unity カタログ ボリューム、 外部の場所、または ワークスペース ファイル を使用することをお勧めします。
| ツール | 例 |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL と Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Databricks CLI(コマンドラインインターフェース) | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Bash シェル コマンド | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| ライブラリのインストール | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| オープンソースソフトウェア Python | os.listdir('/dbfs/mnt/path/to/directory') |
手記
Databricks CLI を使用する場合は、dbfs:/ スキームが必要です。
ドライバー ノードに接続されているエフェメラル ストレージ内のファイルを操作する
ドライバー ノードに接続されているエフェメラル ストレージは、POSIX ベースのパス アクセスが組み込まれたブロック ストレージです。 この場所に格納されているデータは、クラスターが終了または再起動すると消えます。
| ツール | 例 |
|---|---|
| Apache Spark | サポートされていません |
| Spark SQL と Databricks SQL | サポートされていません |
| Databricks ファイル システム ユーティリティ | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Databricks CLI(コマンドラインインターフェース) | サポートされていません |
| Databricks REST API | サポートされていません |
| Bash シェル コマンド | %sh curl http://<address>/text.zip > /tmp/text.zip |
| ライブラリのインストール | サポートされていません |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| オープンソースソフトウェア Python | os.listdir('/path/to/directory') |
手記
Databricks Utilities を使用する場合は、file:/ スキーマが必要です。
エフェメラル ストレージからボリュームにデータを移動する
Apache Spark を使用して、一時ストレージにダウンロードまたは保存されたデータにアクセスできます。 エフェメラル ストレージはドライバーに接続され、Spark は分散処理エンジンであるため、すべての操作がここでデータに直接アクセスできるわけではありません。 ドライバー ファイルシステムから Unity カタログ ボリュームにデータを移動する必要があるとします。 その場合は、次の例のように、マジック コマンド または Databricks ユーティリティを使用してファイルをコピーできます。
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>