注
この記事の組織では、単純なフォームコンピューティング UI を使用していることを前提としています。 単純なフォームの更新の概要については、「 単純なフォームを使用してコンピューティングを管理する」を参照してください。
この記事では、新しい汎用またはジョブ コンピューティング リソースを作成するときに使用できる構成設定について説明します。 ほとんどのユーザーは、割り当てられたポリシーを使用してコンピューティング リソースを作成しますが、これにより、構成可能な設定が制限されます。 UI に特定の設定が表示されない場合は、選択したポリシーでその設定を構成できないためです。
ワークロードのコンピューティングの構成に関する推奨事項については、「 コンピューティング構成の推奨事項」を参照してください。
この記事で説明する構成および管理ツールは、汎用およびジョブ コンピューティングの両方に適用されます。 ジョブ コンピューティングの構成に関する考慮事項の詳細については、「ジョブ用にコンピューティングを構成する」を参照してください。
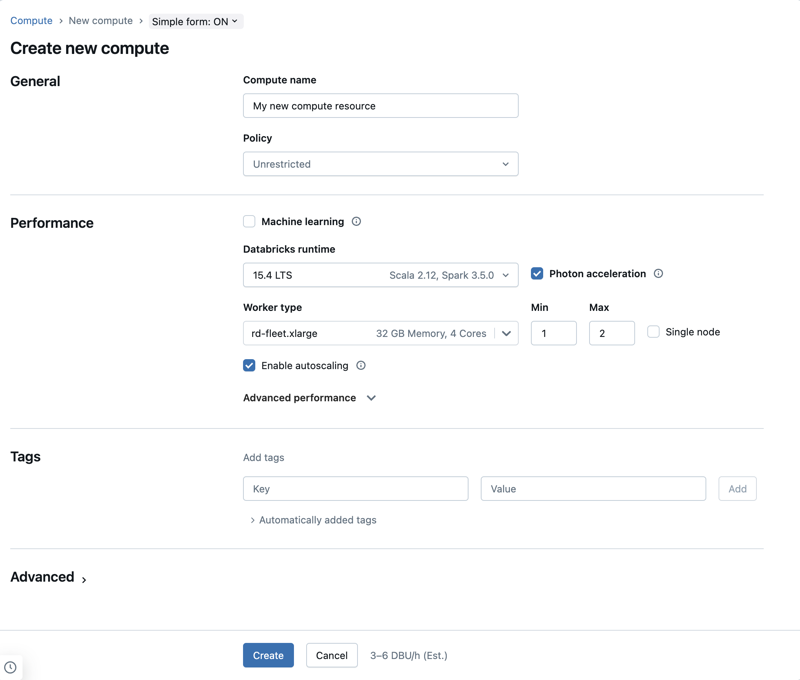
新しい汎用コンピューティング リソースを作成する
次のように、新しい汎用コンピューティング リソースを作成します。
- ワークスペースのサイドバーで [コンピューティング] をクリックします。
- [コンピューティングの作成] ボタンをクリックします。
- コンピューティング リソースを構成します。
- Create をクリックしてください。
新しいコンピューティング リソースが自動的に起動し、すぐに使用できるようになります。
コンピューティング ポリシー
ポリシーは、ユーザーがコンピューティング リソースを作成するときに使用できる構成オプションを制限するために使用される一連のルールです。 ユーザーが 無制限のクラスター作成 エンタイトルメントを持っていない場合、付与されたポリシーを使用してのみコンピューティング リソースを作成できます。
ポリシーに従ってコンピューティング リソースを作成するには、[ポリシー] ドロップダウン メニューからポリシーを選択します。
既定では、すべてのユーザーが個人用コンピューティング ポリシーにアクセスできるため、単一コンピューターのコンピューティング リソースを簡単に作成できます。 パーソナル コンピューティングまたは追加のポリシーにアクセスする必要がある場合は、ワークスペース管理者に連絡してください。
パフォーマンス設定
単純なフォーム コンピューティング UI の [パフォーマンス ] セクションに、次の設定が表示されます。
- Databricks Runtime のバージョン
- Photon アクセラレーションを使用する
- ワーカー ノードの種類
- 単一ノード コンピューティング
- 自動スケールを有効にする
- 高度なパフォーマンス設定
Databricks Runtime のバージョン
Databricks Runtime は、コンピューティングで実行されるコア コンポーネントのセットです。 [Databricks Runtime バージョン] ドロップダウン メニューを使用してランタイムを選択します。 Databricks Runtime の特定バージョンの詳細については、「Databricks Runtime リリース ノートのバージョンと互換性」を参照してください。 すべてのバージョンに Apache Spark が含まれています。 Databricks では次を行うことを推奨しています。
- 汎用コンピューティングの場合は、最新バージョンを使用して、最新の最適化と、コードと事前に読み込まれたパッケージ間の最新の互換性が確保されます。
- 運用ワークロードを実行するジョブ コンピューティングの場合は、長期サポート (LTS) バージョンの Databricks Runtime を使用することを検討してください。 LTS バージョンを使用すると、互換性の問題が発生しないようにし、アップグレードする前にワークロードを十分にテストできます。
- データ サイエンスおよび機械学習に関するユース ケースは、Databricks Runtime ML バージョンを検討してください。
Photon アクセラレーションを使用する
Photon は、既定で Databricks Runtime 9.1 LTS 以上を実行しているコンピューティングで有効です。
Photon アクセラレーションを有効または無効にするには、[Photon アクセラレーションを使用] チェックボックスをオンにします。 Photon の詳細については、「Photon とは」を参照してください。
ワーカー ノードの種類
コンピューティング リソースは、1 台のドライバー ノードと 0 台以上のワーカー ノードで構成されます。 ドライバー ノードとワーカー ノードに対して別々のクラウド プロバイダー インスタンスの種類を選択することもできますが、既定では、ドライバー ノードではワーカー ノードと同じインスタンスの種類が使用されます。 ドライバー ノードの設定は、[ 高度なパフォーマンス ] セクションの下にあります。
インスタンスの種類の異なるファミリは、メモリ集中型やコンピューティング集中型のワークロードなど、異なるユース ケースに適合します。 ワーカーまたはドライバー ノードとして使用するプールを選択することもできます。
重要
ドライバーの種類としてスポット インスタンスを含むプールを使用するのは避けてください。 オンデマンド ドライバーの種類を選択して、ドライバーが再利用されないようにします。 「プールに接続する」を参照してください。
マルチノード コンピューティングでは、コンピューティング リソースが適切に機能するために必要な Spark Executor やその他のサービスがワーカー ノードで実行されます。 Spark を使用してワークロードを分散する場合、すべての分散処理はワーカー ノードで行われます。 Azure Databricksは、ワーカー ノードごとに 1 つの Executor を実行します。 そのため、Executor とワーカーという用語は、Databricks アーキテクチャのコンテキストでは同じ意味で使用されます。
ヒント
Spark ジョブを実行するには、少なくとも 1 台のワーカー ノードが必要です。 コンピューティング リソース内のワーカーの数が 0 の場合は、Spark 以外のコマンドはドライバー ノードで実行できますが、Spark コマンドは失敗します。
柔軟なノード タイプ
ワークスペースでフレキシブル ノード タイプが有効になっている場合は、コンピューティング リソースにフレキシブル ノード タイプを使用できます。 柔軟なノードの種類を使用すると、指定したインスタンスの種類が使用できない場合に、コンピューティング リソースを代替の互換性のあるインスタンスの種類にフォールバックできます。 この動作により、コンピューティングの起動中の容量エラーを減らすことで、コンピューティングの起動の信頼性が向上します。 フレキシブル ノード タイプを使用したコンピューティング起動の信頼性の向上を参照してください。
ワーカー ノードの IP アドレス
Azure Databricksは、それぞれ 2 つのプライベート IP アドレスを持つワーカー ノードを起動します。 ノードのプライマリ プライベート IP アドレスは、Azure Databricks の内部トラフィックを処理します。 セカンダリ プライベート IP アドレスは、クラスター内通信のために Spark コンテナーによって使用されます。 このモデルにより、Azure Databricksは同じワークスペース内の複数のコンピューティング リソース間で分離を提供できます。
GPU インスタンスの種類
ディープ ラーニングに関連するタスクと同様に、高いパフォーマンスを必要とする計算が困難なタスクの場合、Azure Databricksはグラフィックス処理装置 (GPU) を使用して高速化されるコンピューティング リソースをサポートします。 詳細については、GPU 対応コンピューティングに関するページを参照してください。
Azure コンフィデンシャル コンピューティング 仮想マシン
Azureコンフィデンシャル コンピューティング VM の種類により、クラウド オペレーターを含め、使用中のデータへの不正アクセスが防止されます。 この VM の種類は、規制の厳しい業界や地域だけでなく、クラウド上に機密データを持つ企業にも役立ちます。 Azureのコンフィデンシャル コンピューティングの詳細については、「Azure コンフィデンシャル コンピューティングを参照してください。
Azureコンフィデンシャル コンピューティング VM を使用してワークロードを実行するには、ワーカー ノードとドライバー ノードのドロップダウンで DC または EC シリーズの VM の種類から選択します。 Azure Confidential VM オプションを参照してください。
単一ノード コンピューティング
[ 単一ノード ] チェックボックスを使用すると、単一ノードのコンピューティング リソースを作成できます。
単一ノード コンピューティングは、少量のデータを使用するジョブや、単一ノードの機械学習ライブラリなどの非分散ワークロードを対象にしています。 マルチ ノード コンピューティングは、分散ワークロードを使用した大規模なジョブ用に使用する必要があります。
単一ノードのプロパティ
単一ノード コンピューティング リソースには、次のプロパティがあります。
- Spark をローカルで実行します。
- ドライバーは、マスターとワーカーの両方の役割を果たし、ワーカーノードはありません。
- コンピューティング リソースの論理コアごとに、ドライバーの 1 コアを差し引いた 1 つの Executor スレッドを生成します。
- すべての
stderr、stdout、およびlog4jログ出力をドライバー ログに保存します。 - マルチノード コンピューティング リソースに変換することはできません。
単一またはマルチノードを選択する
単一およびマルチ ノード コンピューティングのどちらかを決定する場合は、ユース ケースを考慮してください。
大規模なデータ処理では、単一ノード コンピューティング リソースのリソースを使い果たします。 これらのワークロードについては、Databricks でマルチノード コンピューティングを使用することをお勧めします。
マルチノード コンピューティング リソースを 0 ワーカーにスケーリングすることはできません。 代わりに単一ノード コンピューティングを使用してください。
GPU スケジューリングは、単一ノード コンピューティングでは有効になっていません。
単一ノード コンピューティングでは、Spark は UDT 列を含む Parquet ファイルを読み取ることができません。 次のエラー メッセージが表示されます。
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.この問題を回避するには、ネイティブの Parquet 閲覧者を無効にします。
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
自動スケールの有効化
[自動スケールを有効にする] がオンになっている場合は、コンピューティング リソースのワーカーの最小数と最大数を指定できます。 その後、Databricks でジョブの実行に必要な適切なワーカー数が選択されます。
コンピューティング リソースが自動スケールするワーカーの最小数と最大数を設定するには、[ワーカーの種類] ドロップダウンの横にある [最小] フィールドと [最大] フィールドを使用します。
自動スケールを有効にしない場合は、[ワーカーの種類] ドロップダウンの横にある [ Worker] フィールドに固定数 のワーカー を入力する必要があります。
注
コンピューティング リソースが実行されている場合、コンピューティング リソースの詳細ページに、割り当てられたワーカーの数が表示されます。 割り当てられたワーカーの数をワーカー構成と比較し、必要に応じて調整を行うことができます。
自動スケーリングの利点
自動スケールを使用すると、Azure Databricksは、ジョブの特性を考慮するようにワーカーを動的に再割り当てします。 パイプラインの特定の部分は、他の部分よりも計算負荷が高い場合があり、Databricks はジョブのこれらのフェーズ中に自動的にワーカーを追加します (不要になったときに削除されます)。
自動スケールを使用すると、ワークロードに合わせてコンピューティングをプロビジョニングする必要がないため、高い使用率を実現しやすくなります。 これは特に、(1 日の流れの中でデータセットの探索を行うなど、) 時間の経過とともに要件が変化するワークロードに適用されますが、プロビジョニング要件が不明な 1 回限りの短いワークロードにも適用できます。 したがって、自動スケーリングには次の 2 つの利点があります。
- プロビジョニング数が不足している一定サイズのコンピューティング リソースと比較して、より高速にワークロードを実行できます。
- 自動スケーリングでは、静的にサイズ設定されたコンピューティング リソースと比較して、全体的にコストを削減できます。
コンピューティング リソースとワークロードの一定サイズに応じて、自動スケーリングを使用すると、これらの利点の一方または両方を同時に得ることができます。 コンピューティング サイズは、クラウド プロバイダーがインスタンスを終了するときに選択されたワーカーの最小数を下回る場合があります。 この場合、Azure Databricksは、ワーカーの最小数を維持するためにインスタンスの再プロビジョニングを継続的に再試行します。
注
自動スケーリングは、spark-submit ジョブには使用できません。
注
コンピューティングの自動スケールには、構造化ストリーミング ワークロードのクラスター サイズのスケールダウンに制限があります。 Databricks では、ストリーミング ワークロード用に拡張された自動スケーリングを備えた Lakeflow Spark 宣言型パイプラインを使用することをお勧めします。 自動スケールを使用した Lakeflow Spark 宣言パイプラインのクラスター使用率の最適化に関するページを参照してください。
オートスケールの動作
Premium プランのワークスペースでは、最適化された自動スケールが使用されます。 スタンダードプランのワークスペースでは、標準の自動スケーリングを使用します。
最適化された自動スケーリングには、次のような特徴があります。
- 最大 2 つのスケーリング イベントで最小から最大にスケールアップします。
- シャッフル ファイルの状態を確認することで、コンピューティング リソースがアイドル状態でなくてもスケールダウンできます。
- 現在のノードの割合に基づいてスケールダウンします。
- ジョブ コンピューティングでは、コンピューティング リソースの使用率が低い状態が 40 秒間続くとスケールダウンします。
- 汎用コンピューティングでは、コンピューティング リソースの使用率が低い状態が 150 秒間続くとスケールダウンします。
-
spark.databricks.aggressiveWindowDownSSpark 構成プロパティは、コンピューティングでスケールダウンの決定が行われる頻度を秒単位で指定します。 この値を大きくすると、コンピューティングでのスケールダウンが遅くなります。 最大値は 600 です。
標準の自動スケーリングは、Standard プラン ワークスペースで使用されます。 標準の自動スケーリングには、次のような特徴があります。
- 8 台のノードの追加で開始されます。 その後、最大に達するために必要なだけのステップを実行して、指数関数的にスケールアップします。
- ノードの 90% が 10 分間ビジー状態ではなく、コンピューティングが 30 秒以上アイドル状態になっている場合にスケールダウンします。
- 1 台のノードから開始して、指数関数的にスケールダウンします。
Warnung
Databricks 自動スケールを使用するコンピューティング リソースで Apache Spark 動的割り当て (spark.dynamicAllocation.enabled) を有効にしないでください。 Databricks の自動スケールでは、ワーカー ノードと Executor ライフサイクルがプラットフォーム レベルで管理されます。 Spark 動的割り当てを並列で有効にすると、スケーリングの決定が競合し、Executor のチャーン、 NODES_LOST エラー、および取得されないタスクが発生する可能性があります。
プールを使用した自動スケーリング
コンピューティング リソースをプールにアタッチする場合は、次の点を考慮してください。
- 要求されたコンピューティング サイズが、プール内のアイドル状態のインスタンスの最小数以下になるようにします。 より大きい場合、コンピューティングの起動時間は、プールを使用しないコンピューティングと同じになります。
- 最大コンピューティング サイズが、プールの最大容量以下になるようにします。 それより大きい場合、コンピューティングの作成は失敗します。
自動スケーリングの例
静的コンピューティング リソースを自動スケールに再構成すると、Azure Databricksはコンピューティング リソースのサイズを最小値と最大値の範囲内で直ちに変更し、自動スケールを開始します。 例として、次の表では、5 から 10 台のノードの間で自動スケーリングするようにコンピューティング リソースを再構成した場合に、特定の初期サイズを持つコンピューティング リソースがどうなるかを示しています。
| 初期サイズ | 再構成後のサイズ |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
高度なパフォーマンス設定
次の設定は、単純なフォーム コンピューティング UI の [Advanced performance]\(パフォーマンスの詳細設定 \) セクションの下に表示されます。
スポット インスタンス
コストを節約するには、spot インスタンス (Azure スポット VM とも呼ばれます) を使用するには、Spot インスタンス チェック ボックスをオンにします。

最初のインスタンスは常にオンデマンド (ドライバー ノードは常にオンデマンド) であり、後続のインスタンスはスポット インスタンスになります。
使用できないためにインスタンスが削除された場合、Azure Databricksは、削除されたインスタンスを置き換えるために新しいスポット インスタンスの取得を試みます。 スポット インスタンスを取得できない場合は、削除されたインスタンスを置き換えるためにオンデマンド インスタンスがデプロイされます。 このオンデマンド フェールバックは、完全に取得されて実行されているスポット インスタンスでのみサポートされます。 セットアップ中に失敗するスポット インスタンスは自動的に置き換えされません。
さらに、新しいノードが既存のコンピューティング リソースに追加されると、Azure Databricksはこれらのノードのスポット インスタンスの取得を試みます。
自動終了
コンピューティングの自動終了は、[ 高度なパフォーマンス ] セクションで設定できます。 コンピューティングの作成時に、コンピューティング リソースを終了するまでの非アクティブな期間を分単位で指定してください。
コンピューティング リソースで実行された現在の時刻と最後のコマンドの差が、指定された非アクティブ期間を超える場合、Azure Databricksはそのコンピューティング リソースを自動的に終了します。 コンピューティング終了の詳細については、「 コンピューティングの終了」を参照してください。
ドライバーの種類
[Advanced performance]\(高度なパフォーマンス\) セクションでドライバーの種類を選択できます。 ドライバー ノードでは、コンピューティング リソースに接続されているすべてのノートブックの状態情報が保持されます。 また、ドライバー ノードでは SparkContext が保持され、コンピューティング リソース上のノートブックやライブラリから実行されるコマンドが解釈され、Spark Executor との調整を行う Apache Spark マスターが実行されます。
ドライバー ノードの種類の既定値は、ワーカー ノードの種類と同じです。 Spark ワーカーから多くのデータを collect() し、それらをノートブックで分析することを計画している場合は、より多くのメモリを備えたより大規模なドライバー ノードの種類を選択できます。
ヒント
ドライバー ノードには、接続されているノートブックのすべての状態情報が保持されるため、使用されていないノートブックはドライバー ノードから切断するようにしてください。
タグ
タグを使用すると、組織内のさまざまなグループで使用されるコンピューティング リソースのコストを簡単に監視できます。 コンピューティングの作成時にキーと値のペアとしてタグを指定Azure Databricks、VM やディスク ボリュームなどのクラウド リソースと Databricks の使用状況ログにこれらのタグを適用します。
プールから起動されたコンピューティングの場合、カスタム タグは DBU 使用状況レポートにのみ適用され、クラウド リソースには伝播しません。
プールとコンピューティング タグの種類の連携の詳細については、「タグを使用して使用状況を属性化および追跡する」を参照してください。
コンピューティング リソースにタグを追加するには:
- [タグ] セクションで、カスタム タグごとにキーと値のペアを追加します。
- [追加] をクリックします。
詳細設定
単純なフォーム コンピューティング UI の [詳細設定 ] セクションに、次の設定が表示されます。
アクセス モード
アクセス モードは、誰がコンピューティング リソースを使用できるかと、その人物がコンピューティング リソースを使用してアクセスできるデータを決定するセキュリティ機能です。 Azure Databricksのすべてのコンピューティング リソースにはアクセス モードがあります。 アクセス モードの設定は、単純なフォーム コンピューティング UI の [詳細設定 ] セクションにあります。
アクセス モードの選択は既定では 自動 です。つまり、選択した Databricks ランタイムに基づいてアクセス モードが自動的に選択されます。 自動では、機械学習ランタイムまたは 14.3 未満の Databricks ランタイムが選択されていない限り、既定では Standard になります。この場合は Dedicated が使用されます。
Databricks では、必要な機能がサポートされていない場合を除き、標準アクセス モードを使用することをお勧めします。
| アクセス モード | Description | サポートされている言語 |
|---|---|---|
| Standard | 複数のユーザーが、ユーザー間でデータを分離して使用できます。 | Python、SQL、Scala |
| Dedicated | 1 人のユーザーまたはグループに割り当て、使用できます。 | Python、SQL、Scala、R |
これらの各アクセス モードの機能サポートの詳細については、 標準のコンピューティング要件と制限事項、 および 専用コンピューティングの要件と制限事項に関する記事を参照してください。
注
Databricks Runtime 13.3 LTS 以上では、init スクリプトとライブラリはすべてのアクセス モードでサポートされています。 要件とサポート レベルは異なります。 init スクリプトをインストールできる場所とコンピューティング スコープのライブラリを参照してください。
ローカル ストレージの自動スケールを有効にする
多くの場合、特定のジョブに必要となるディスク領域を見積もることは困難です。 作成時にコンピューティングにアタッチするマネージド ディスクのギガバイト数を見積もる必要をなくすために、Azure Databricksは、すべてのAzure Databricks コンピューティングでローカル ストレージの自動スケールを自動的に有効にします。
ローカル ストレージの自動スケーリングを使用すると、Azure Databricksはコンピューティングの Spark ワーカーで使用可能な空きディスク領域の量を監視します。 ワーカーでディスク領域の量が少なくなり始めると、ディスク領域が枯渇する前に、Databricks によって自動的に新しいマネージド ディスクがワーカーに接続されます。 ディスクは、仮想マシンごとに最大 5 TB の合計ディスク領域 (仮想マシンの初期ローカル ストレージを含む) に接続されます。
仮想マシンに接続されているマネージド ディスクは、仮想マシンがAzureに返された場合にのみデタッチされます。 つまり、マネージド ディスクは、実行中のコンピューティングの一部である限り、仮想マシンから切断されません。 マネージド ディスクの使用量をスケールダウンするには、Azure Databricks自動スケーリング コンピューティングまたは自動終了 で構成されたコンピューティングでこの機能を使用することをお勧めします。
ローカル ディスク暗号化
重要
この機能はパブリック プレビュー段階にあります。
コンピューティングの実行に使用するインスタンスの種類によっては、ローカルに接続されたディスクがある場合があります。 Azure Databricksは、これらのローカル接続ディスクにシャッフル データまたはエフェメラル データを格納できます。 コンピューティング リソースのローカル ディスクに一時的に格納されるシャッフル データを含め、保存されているすべてのデータがすべてのストレージの種類で暗号化されるようにするには、ローカル ディスク暗号化を有効にします。
重要
ローカル ボリュームとの間の暗号化されたデータの読み取りと書き込みによるパフォーマンスへの影響により、ワークロードの実行速度が低下する可能性があります。
ローカル ディスク暗号化が有効になっている場合、Azure Databricksは、各コンピューティング ノードに固有の暗号化キーをローカルで生成し、ローカル ディスクに格納されているすべてのデータを暗号化するために使用されます。 このキーのスコープは各コンピューティング ノードに対してローカルであり、コンピューティング ノード自体と共に破棄されます。 有効期間中、キーは暗号化と暗号化解除のためにメモリ内に存在し、ディスク上に暗号化されて格納されます。
ローカル ディスク暗号化を有効にするには、Clusters API を使用する必要があります。 コンピューティングの作成または編集中に、enable_local_disk_encryption を true に設定します。
Spark の構成
Spark ジョブを微調整するために、カスタムの Spark 構成プロパティを指定できます。
[コンピューティング構成] ページで、[ 詳細設定 ] トグルをクリックします。
[Spark] タブをクリックします。
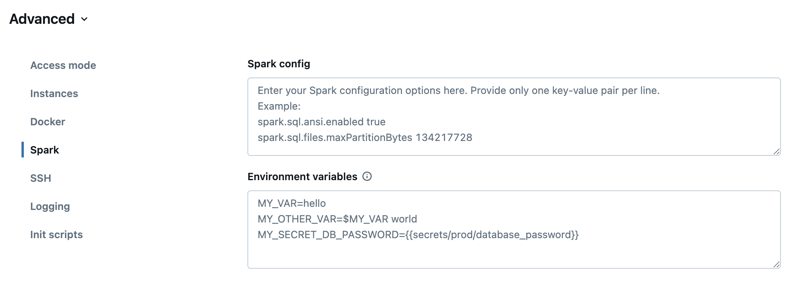
Spark 構成で、構成プロパティを 1 行につき 1 つのキーと値のペアとして入力します。
Clusters API を使用してコンピューティングを構成する場合は、spark_confまたはクラスター API の更新の フィールドに Spark プロパティを設定します。
コンピューティングに Spark 構成を適用するために、ワークスペース管理者は コンピューティング ポリシーを使用できます。
シークレットから Spark 構成プロパティを取得する
Databricks では、パスワードなどの機密情報は、プレーンテキストではなくシークレットに格納することをお勧めしています。 Spark 構成でシークレットを参照するには、次の構文を使用します。
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
たとえば、password という Spark 構成プロパティを、secrets/acme_app/password に格納されているシークレットの値に設定するには、次のようにします。
spark.password {{secrets/acme-app/password}}
詳細については、「 シークレットの管理」を参照してください。
コンピューティング ログの配信
汎用コンピューティングまたはジョブ コンピューティングを作成するときに、Spark ドライバー、ワーカー ノード、イベントからのログなど、クラスター ログの場所を指定できます。 ログは 5 分ごとに配信され、選択した宛先に 1 時間ごとにアーカイブされます。 Databricks は、コンピューティング リソースが終了するまでログの配信を続行します。
ログは、次のいずれかの場所に格納できます。
- ボリューム (推奨): Unity カタログのボリューム パスにログを格納します。 これは、Unity カタログ対応のコンピューティング リソースを使用する場合に推奨される最も安全なオプションです。
- DBFS (レガシ): Databricks ファイル システム (DBFS) パスにログを格納します。 このオプションは、DBFS ルートとマウントがワークスペースで無効にされていない場合にのみ使用できます。 既存のAzure Databricks ワークスペース内のDBFSルートとマウントへのアクセスを無効にする方法を参照してください。
ログの配信場所を構成するには、次のようにします。
- コンピューティング ページで、[ 詳細設定 ] トグルをクリックします。
- [ログ] タブをクリックします。
- 送信先の種類を選択します。
- ログ パスを入力します。
Databricks は、ログを格納するために、選択したログパスにコンピューティングのcluster_id名のサブフォルダーを作成します。
たとえば、指定したログ パスが /Volumes/catalog/schema/volume場合、 06308418893214 のログは /Volumes/catalog/schema/volume/06308418893214に配信されます。
注
ボリュームへのログの配信は、 Standard アクセス モードまたは 専用 アクセス モードがユーザーに割り当てられている Unity カタログ対応コンピューティングでのみサポートされます。 グループに割り当てられた 専用 アクセス モードではサポートされていません。 パスとしてボリュームを選択した場合は、コンピューティングの所有者または割り当てられているユーザーに、ボリュームに対する READ VOLUME と WRITE VOLUME のアクセス許可があることを確認します。
Unity カタログ ボリュームの特権を参照してください。
コンピューティングへの SSH アクセス
セキュリティ上の理由から、Azure Databricksでは、SSH ポートは既定で閉じられます。 Spark クラスターへの SSH アクセスを有効にする場合は、「ドライバー ノードへの SSH 接続」を参照してください。
注
SSH を有効にできるのは、ワークスペースが独自の Azure 仮想ネットワークにデプロイされている場合のみです。
環境変数
コンピューティング リソースで実行されている init スクリプトからアクセスできる環境変数を構成します。 Databricks には、init スクリプトで使用できる定義済みの環境変数も用意されています。 これらの定義済みの環境変数をオーバーライドすることはできません。
コンピューティング構成ページで、[ 詳細設定] をクリックします。
[Spark] タブをクリックします。
[環境変数] フィールドに 環境変数 を設定します。
![[環境変数] フィールド](../_static/images/clusters/environment-variables.png)
spark_env_varsまたはクラスター API の更新 の フィールドを使用して環境変数を設定することもできます。