この記事では、Azure と組み合わせたエンタープライズ アーキテクチャなど、Azure Databricks アーキテクチャの概要について説明します。
Databricks オブジェクト
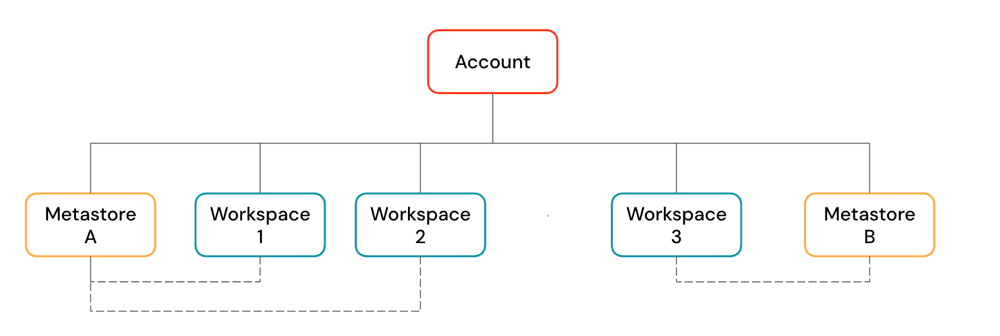
Azure Databricks アカウント は、組織全体で Azure Databricks を管理するために使用する最上位レベルのコンストラクトです。 アカウント レベルでは、次の管理を行います。
- ID とアクセス: ユーザー、グループ、サービス プリンシパル、およびユーザー プロビジョニング。
ワークスペースの管理: 複数のリージョンにまたがるワークスペースを作成、更新、削除します。
Unity カタログメタストア管理: メタストアを作成してワークスペースにアタッチします。
使用状況管理: 課金、コンプライアンス、ポリシー。
アカウントには、複数のワークスペースと Unity カタログ メタストアを含めることができます。
ワークスペース は、ユーザーがインジェスト、対話型探索、スケジュールされたジョブ、ML トレーニングなどのコンピューティング ワークロードを実行するコラボレーション環境です。
Unity カタログ メタストア は、テーブルや ML モデルなどのデータ資産の中央ガバナンス システムです。 メタストア内のデータは、次の 3 レベルの名前空間の下に整理します。
<catalog-name>.<schema-name>.<object-name>
メタストアはワークスペースにアタッチされます。 1 つのメタストアを同じリージョン内の複数の Azure Databricks ワークスペースにリンクし、各ワークスペースに同じデータ ビューを提供できます。 データ アクセス制御は、リンクされているすべてのワークスペースで管理できます。
ワークスペースのアーキテクチャ
Azure Databricks は、"コントロール プレーン" と "コンピューティング プレーン" により動作します。
コントロール プレーンには、Azure Databricks によって Azure Databricks アカウントで管理されるバックエンド サービスが含まれています。 コントロール プレーンは、クラウド アカウントではなく Azure Databricks アカウントにあります。 Web アプリケーションは、コントロール プレーン内にあります。
コンピューティング プレーンは、データが処理される場所です。 コンピューティング プレーンには、使用するコンピューティングに応じて次の 2 つの種類があります。
- サーバーレス コンピューティングの場合、サーバーレス コンピューティング リソースは、Azure Databricks アカウント内の "サーバーレス コンピューティング プレーン" 内で実行されます。
- 従来の Azure Databricks コンピューティングの場合、コンピューティング リソースは、Azure サブスクリプション内にあり、"クラシック コンピューティング プレーン" と呼ばれます。 これは、Azure サブスクリプション内のネットワークとそのリソースを指します。
クラシック コンピューティングとサーバーレス コンピューティングの詳細については、「 コンピューティング」を参照してください。
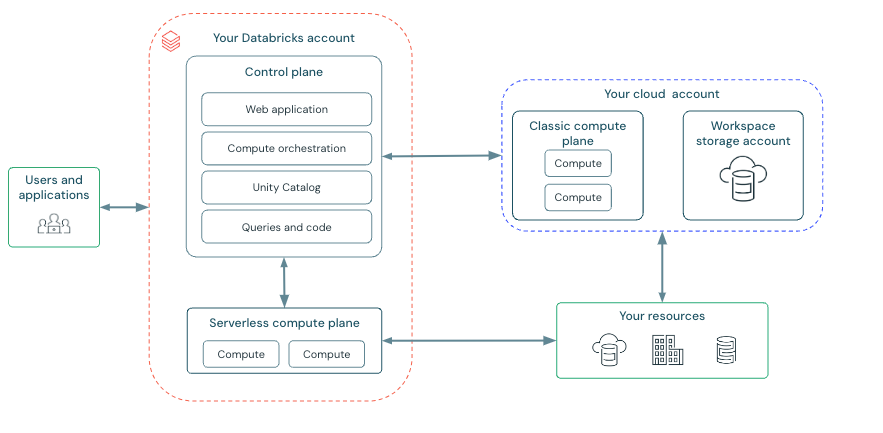
クラシック ワークスペースのアーキテクチャ
注
クラシック ワークスペースは、Azure portal では ハイブリッド ワークスペース と呼ばれます。
クラシック Azure Databricks ワークスペースには、ワークスペース ストレージ アカウントと呼ばれるストレージ アカウントが関連付けられています。 ワークスペース ストレージ アカウントは、Azure サブスクリプション内にあります。
次の図では、クラシック ワークスペースの一般的な Azure Databricks アーキテクチャについて説明します。
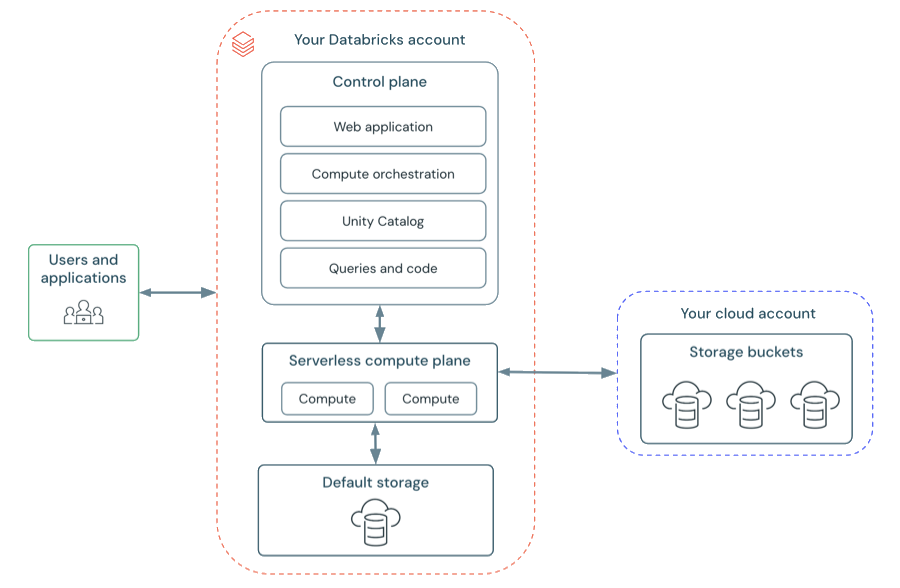
サーバーレス ワークスペースのアーキテクチャ
サーバーレス ワークスペース内のワークスペース ストレージは、ワークスペースの既定のストレージに格納されます。 クラウド ストレージ アカウントに接続してデータにアクセスすることもできます。 次の図では、サーバーレス ワークスペースの一般的なアーキテクチャについて説明します。
サーバーレス コンピューティング プレーン
サーバーレス コンピューティング プレーンでは、Azure Databricks コンピューティング リソースは、Azure Databricks アカウント内のコンピューティング レイヤーで実行されます。 Azure Databricks は、ワークスペースのクラシック コンピューティング プレーンと同じ Azure リージョンにサーバーレス コンピューティング プレーンを作成します。 ワークスペースを作成する場合は、このリージョンを選択します。
サーバーレス コンピューティング プレーン内の顧客データを保護するために、サーバーレス コンピューティングはワークスペースのネットワーク境界内で実行され、Azure Databricks の異なる顧客のワークスペースを隔離するさまざまなセキュリティ レイヤーと、同じ顧客のクラスター間の追加のネットワーク制御を備えています。
サーバーレス コンピューティング プレーン内のネットワークの詳細については、「サーバーレス コンピューティング プレーン ネットワーク」を参照してください。
クラシック コンピューティング プレーン
クラシック コンピューティング プレーンでは、Azure Databricks コンピューティング リソースは Azure サブスクリプションで実行されます。 新しいコンピューティング リソースは、顧客の Azure サブスクリプション内の各ワークスペースの仮想ネットワーク内に作成されます。
クラシック コンピューティング プレーンは、顧客独自の Azure サブスクリプションで実行されるため、自然な分離を備えます。 クラシック コンピューティング プレーン内のネットワークの詳細については、「クラシック コンピューティング プレーン ネットワーク」を参照してください。
リージョンのサポートについては、「Azure Databricks のリージョン」を参照してください。
ワークスペース ストレージ
ワークスペース ストレージの処理方法は、ワークスペースの種類によって異なります。 ワークスペースの種類の詳細については、「ワークスペースの 作成」を参照してください。
ワークスペース ストレージには、ワークスペース ファイル システム データとワークスペース システム データという 2 つのカテゴリのデータが含まれています。 どちらも、独自のデータ オブジェクト (Unity カタログ テーブルやボリュームなど) とは別です。
ワークスペース のファイル システム データ
ワークスペース ファイル システムには、ユーザーが Azure Databricks UI を使用して作成および管理する資産が格納されます。 これらには次のものが含まれます。
- Notebooks
- SQL クエリとダッシュボード
- アラート
- リポジトリ (Git リポジトリにアタッチされているフォルダー)
- ライブラリ (
.whl、.jar) - Python ファイル、YAML 構成ファイル、およびその他の小さなファイル
ワークスペース ファイルの詳細については、「ワークスペース ファイルとは」を参照してください。 ワークスペース資産の完全な一覧については、「 ワークスペース オブジェクトの概要」を参照してください。
ワークスペース システム データ
すべての Azure Databricks ワークスペースには、Azure Databricks 機能によって内部的に生成されたシステム データも格納されます。 このデータは大きすぎてメモリやデータベースに格納できません。または、単一のコンピューティング リソースの有効期間を超えて保持する必要があります。 ワークスペース システム データの例を次に示します。
- SQL クエリの結果とキャッシュされたクエリ結果
- ジョブ実行結果
- ノートブックの改訂
- 監視に使用される SQL クエリ プラン
- クラスターログ
ワークスペースの種類ごとにワークスペース ストレージを構成する方法の詳細については、以下のセクションを参照してください。
サーバーレス ワークスペース
サーバーレス ワークスペースでは、既定のストレージが使用されます。これは、内部ワークスペース システム データと Unity Catalog データ資産の完全に管理されたストレージの場所です。 サーバーレス ワークスペースでは、独自のカタログ、テーブル、およびその他のデータ資産のクラウド ストレージの場所に接続する機能もサポートされています。 Databricks の既定のストレージを参照してください。
クラシック ワークスペース
Important
クラウド アカウント内のワークスペース ストレージを削除または変更しないでください。 Azure Databricks ワークスペースは、正しい操作のためにコントロール プレーン データベースとそのワークスペース ストレージの両方に依存します。 ワークスペース ストレージが削除された場合、ワークスペースを復旧できません。
クラシック ワークスペースでは、ワークスペース システム データは DBFS とは異なります。 どちらもクラシック ワークスペース内の同じクラウド ストレージ アカウントに存在する場合がありますが、異なる目的で機能します。 DBFS ルートはユーザーがアクセスできるファイル システムですが、ワークスペース システム データは Azure Databricks の機能によって内部的に使用されます。
ワークスペース ストレージ アカウントには、次のものが含まれています。
- ワークスペース システム データ: Azure Databricks 機能によって生成された内部データ
- Unity カタログ ワークスペース カタログ: ワークスペースが Unity カタログに対して自動的に有効になっている場合、ワークスペース ストレージ アカウントには既定のワークスペース カタログが含まれます。 ワークスペースのすべてのユーザーは、このカタログ内の既定のスキーマで資産を作成できます。 Unity カタログについて始めに知っておくべきことを参照してください
- DBFS (レガシ): DBFS ルートマウントと DBFS マウントはレガシであり、ワークスペースで無効になる可能性があります。 DBFS (Databricks ファイル システム) は、
dbfs:/名前空間でアクセスできる Azure Databricks 環境の分散ファイル システムです。 DBFS ルートと DBFS マウントは、両方ともdbfs:/名前空間にあります。 DBFS ルートまたは DBFS マウントを使用したデータの保存とアクセスは非推奨のパターンであり、Databricks では推奨されません。 詳細については、「DBFS とは」を参照してください。
ワークスペース ストレージ アカウントへのアクセスを、承認されたリソースとネットワークからのみに制限するには、「ワークスペース ストレージ アカウントのファイアウォール サポートを有効にする」を参照してください。