重要
この機能は ベータ版です。
データ カタログには膨大な量のデータを含めることができます。多くの場合、既知の機密データと不明な機密データが含まれます。 データ チームは、各テーブルに存在する機密データの種類を理解して、このデータへのアクセスを管理および民主化することが重要です。
この問題に対処するために、Databricks データ分類はカタログ内のテーブルを自動的に分類してタグ付けします。 これにより、Unity Catalog のロールベースのアクセス制御 (RBAC) や属性ベースのアクセス制御 (ABAC) ポリシーなどのツールを使用して、機密データを検出したり、結果にガバナンス制御を適用したりできます。
この機能を使用すると、次のことが可能になります。
- データの分類: エンジンは複合 AI システムを使用して、Unity カタログ内のすべてのテーブルを自動的に分類 (およびタグ付け) します。
- スマート スキャンによるコストの最適化: Unity カタログとデータ インテリジェンス エンジンを利用して、データをスキャンするタイミングがシステムによってインテリジェントに決定されます。 つまり、スキャンは増分され、すべての新しいデータが手動構成なしで分類されるように最適化されます。
- 分類のレビュー: このプレビューでは、カタログ全体の分類結果とダウンストリームへの影響を表示するのに役立つ AI/BI ダッシュボードが提供されます。
フィードバックや質問については、 data-classification-feedback@databricks.comまでお問い合わせください。
免責事項
注
- Databricks データ分類では、Databricks でホストされる大規模言語モデル (LLM) を使用して分類を支援します。 Databricks では、データを保護するためのセキュリティコントロールが実装されています。 詳細については、「 Model Serving と Databricks AI 機能の信頼と安全性のデータ保護」を参照してください。
要求事項
- サーバーレス コンピューティングを有効にする必要があります。 「サーバーレス コンピューティングに接続する」を参照してください。
- データ分類を有効にするには、カタログに対する
MANAGE、CREATE SCHEMA、およびSELECT特権が必要です。 - データ分類は、 標準カタログでのみサポートされます。
データ分類を開始する
機能を有効にする方法:
任意のカタログに移動し、[ 詳細 ] タブをクリックします。
![カタログ エクスプローラーのカタログ ページの [詳細] タブ。](../_static/images/lakehouse-monitoring/data-classification-details-tab.png)
[ データ分類 ] トグルをクリックして有効にします。
(必要に応じて)分類に含めるスキーマを選択します。 既定では、すべてのスキーマが含まれます。
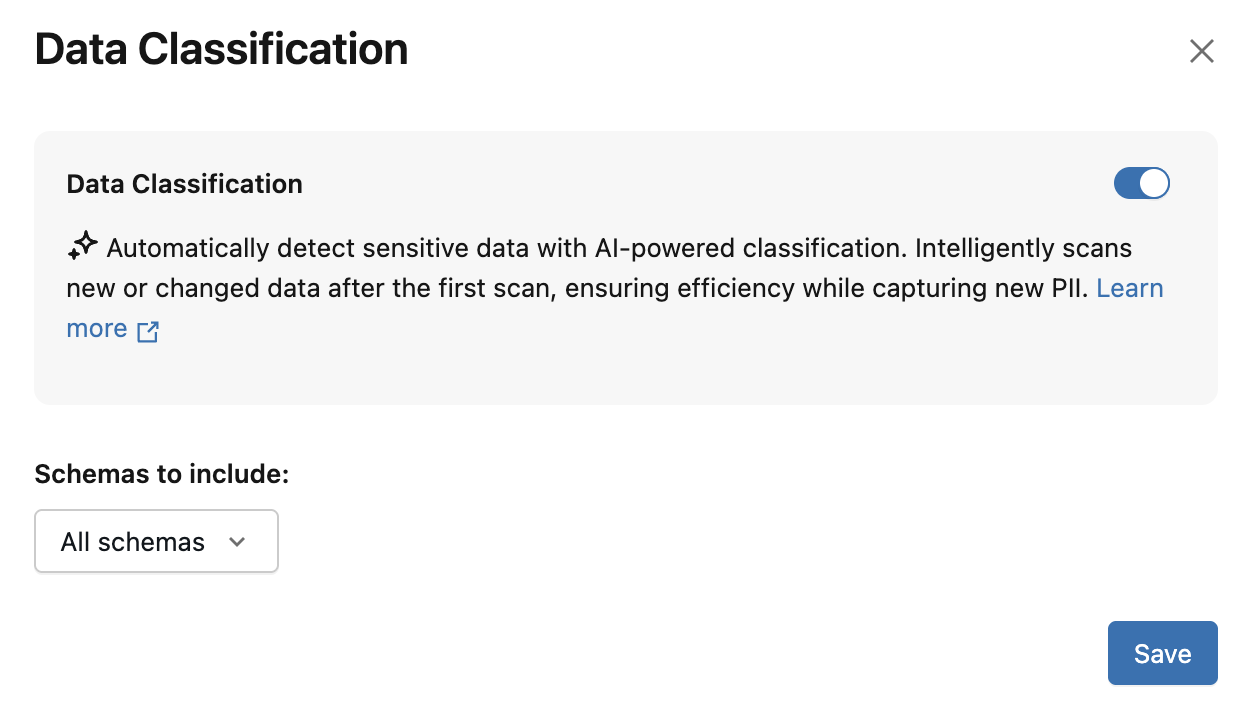
これにより、カタログ内のすべてのテーブルまたは選択したスキーマを増分スキャンするバックグラウンド ジョブが作成されます。
分類の結果を表示する
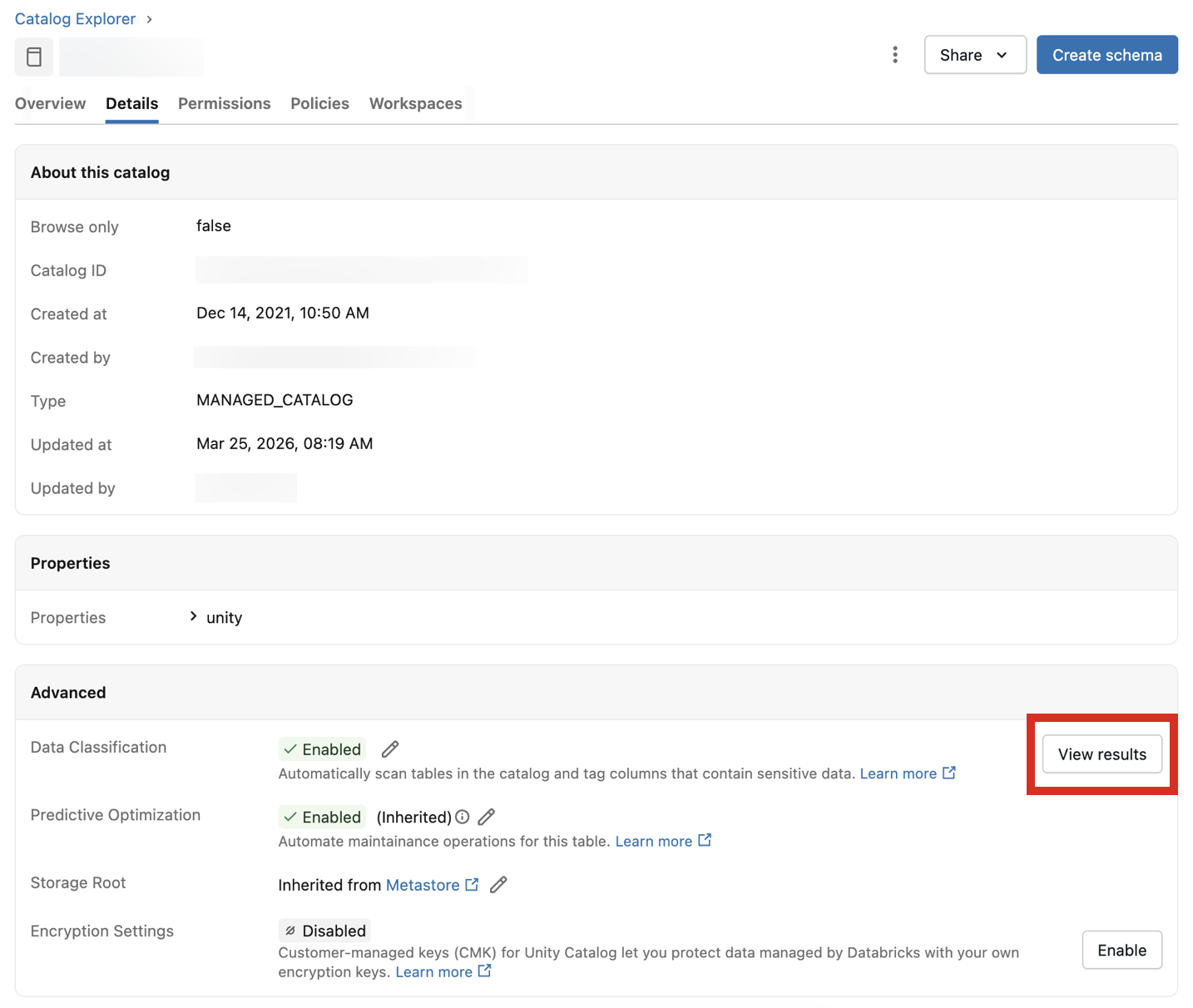
分類結果を表示するには、トグルの横にある [結果の表示 ] をクリックします。 ダッシュボードが開き、カタログ内のすべてのテーブルの分類結果が表示されます。
概要
[ 概要 ] セクションには、分類されたテーブルの数と、カタログ全体の機密データ クラスの分布が表示されます。 結果は、スキーマ、テーブル、または分類でフィルター処理できます。
![データ分類ダッシュボードの [概要] セクション。](../_static/images/lakehouse-monitoring/data-classification-dashboard-overview.png)
ダッシュボードには、アクセス制御された結果を提供するビューが備わっています。つまり、ユーザーが読み取りアクセス権を持つテーブル結果の行のみが返されます (詳細については FAQ を参照してください)。
分類ログ
[ 分類ログ ] セクションには、時間の経過に伴う分類の時系列グラフが表示されます。 これにより、最新の分類を確認し、機密データ クラス別にドリルダウンすることができます。
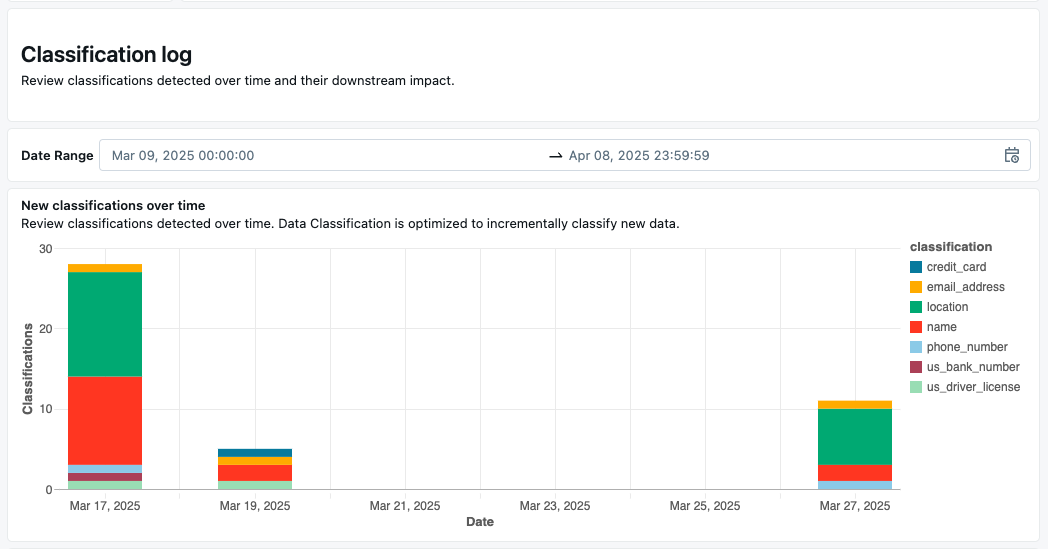
また、次のような各分類の詳細を含むテーブルも提供します。
- 根拠: 分類が行われた理由。 これは、メタデータまたは列名の検出、値の検出、またはその両方の組み合わせが原因である可能性があります。
- 一致スコア: 分類に一致した行のおおよその割合。
- サンプル値: 分類に一致した値のサンプル。 これは、分類のコンテキストを理解し、その精度を確認するのに役立ちます。
- ダウンストリーム資産: ジョブ、ノートブック、クエリ、ダッシュボードなど、分類の影響を受けたダウンストリーム資産の一覧。
- アクティブ ユーザー: 指定された時間範囲内のテーブルのアクティブ ユーザーの数。
![[データ分類] ダッシュボードの [分類ログ] セクション。](../_static/images/lakehouse-monitoring/data-classification-dashboard-detection-log.png)
スキャンエラー
[ スキャンエラー] セクションには、分類に失敗したテーブルが表示されます。 これはさまざまな理由で発生する可能性があり、各テーブルのエラーには詳細なエラー メッセージが伴います。 これらのエラーの解決については、 FAQ を参照してください。
タグ付けとガバナンスコントロール
データ分類の結果により、次のような複数の方法でガバナンス制御を有効にすることができます。
- 機密データの検出: 分類結果を照会して、カタログ内の機密データを検出し、適切なアクションを実行できます。
- 行レベルおよび列レベルのセキュリティ: 分類では、属性ベースのアクセス制御 (ABAC) を使用して行レベルと列レベルのセキュリティを適用するためにダウンストリーム ポリシーで使用できるタグを生成できます。
- テーブル レベルのセキュリティ: 分類結果を使用して、機密性の高いテーブルとスキーマへのアクセスを制限するユーザー グループとアクセス許可を設定できます。
機密データを検出する
ダッシュボードの結果ビューは、機密データが存在する場所と、それがカタログでどのように使用されているかを理解するのに役立ちます。 この情報を使用して、テーブルの所有者に対し、テーブルから個人を特定できる情報 (PII) を削除または修復する要求を自動的に通知するなど、適切なアクションを実行できます。
行レベルと列レベルのセキュリティ
データ分類では、システム タグを使用して機密データに自動的にタグを付けることができます。 これを行うには、次の手順を実行します。
- タグ ポリシー プレビューに登録されている必要があります。
- システム タグ ポリシー (
ASSIGNプレフィックスで始まるタグ) に対するclass.特権が必要です。 - タグが適用されるカタログ、スキーマ、およびテーブルに対する
APPLY TAG権限が必要です。
ABAC プレビューに登録している場合は、ABAC ポリシーの class. タグとマスク機能を使用して、タグ付けされたデータを自動的にマスクできます。
たとえば、特定のユーザー グループに属していないすべてのユーザーに社会保障番号をマスクするポリシーを作成できます。
タグ ポリシーまたは ABAC プレビューへの登録の詳細については、アカウント担当者または Databricks サポートにお問い合わせください。
列レベルのセキュリティを適用するためのもう 1 つのオプションは、タグ付けされた 列に列マスク を適用することです。
テーブル レベルのセキュリティ
分類結果を使用して、ユーザー グループとアクセス許可を使用してテーブル レベルのセキュリティを実装できます。
たとえば、 confidential という名前のユーザー グループを作成し、 name 分類を含むすべてのテーブルに割り当てることができます。また、 restricted というグループを作成して、 us_ssnを含むすべてのテーブルに割り当てることができます。
データ分類の経費を表示する
データ分類の課金方法については、 価格ページを参照してください。 クエリを実行するか、使用状況ダッシュボードを表示することで、データ分類に関連する経費を表示できます。
システム テーブル system.billing.usage から使用状況を表示する
データ分類の経費を確認するには、次のようなクエリを使用します。
SELECT
usage_date,
identity_metadata.run_as AS run_as_user,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
identity_metadata.run_as
ORDER BY
usage_date DESC,
run_as_user;
使用状況ダッシュボードから使用状況を表示する
ワークスペースで使用状況ダッシュボードが既に構成されている場合は、それを使用して、"データ分類" というラベルの付いた Billing Origin プロジェクトを選択して使用状況をフィルター処理できます。 使用状況ダッシュボードが構成されていない場合は、ダッシュボードをインポートし、同じフィルター処理を適用できます。 詳細については、「 使用状況ダッシュボード」を参照してください。
よく寄せられる質問
データ分類の実行にはどのくらいの時間がかかりますか?
分類エンジンは、スマート スキャンを使用して、テーブルをスキャンするタイミングを決定します。 カタログ内の新しいテーブルと列は、作成されてから 24 時間以内にスキャンされます。
24 時間以上の遅延が発生している場合は、 data-classification-feedback@databricks.comにお問い合わせください。
作成された結果テーブルに対するアクセス許可は何ですか?
データ分類では、結果とエラー (それぞれ_result と _errors ) を格納するテーブルが作成されます。既定では、分類を設定したユーザーのみがアクセスできます。
動的ビューは、行レベルのアクセス制御が適用されたこれらのテーブルに対しても作成されるため、これらのビューから結果を読み取るユーザーには、既に所有権または読み取りアクセス権を持っているテーブルに対応するエントリのみが表示されます。
一部のテーブルは分類できませんでした。何が間違っていたのかを理解するにはどうすればよいですか?
既定では、個々のテーブルで発生したエラーはスキップされ、翌日に再試行されます。 エラー ビューを使用すると、分類が失敗した原因となった正確なエラー メッセージを確認できます。
SELECT * FROM <catalog_name>._data_classification.errors
WHERE schema_name = '<schema_name>' and table_name = '<table_name>'
データ分類はビューをサポートしていますか?
ビューと メトリック ビュー はサポートされていません。 ビューが既存のテーブルに基づいている場合、Databricks では、基になるテーブルを分類して、機密データが含まれているかどうかを確認することをお勧めします。
具体化されたビューとストリーミング テーブルがサポートされています。
データ分類はDelta Sharingカタログをサポートしていますか?
Delta Sharing を使用して共有されるカタログはサポートされていません。 代わりに、Databricks では、機密データを分類するために、既存のカタログ内でスキーマとテーブルを共有することをお勧めします。
サポートされているクラス
次の表に、データ分類でサポートされるクラスを示します。
| クラス | 説明 |
|---|---|
| クレジットカード | クレジット カード番号 |
| メールアドレス | メール アドレス |
| IBANコード | 国際銀行口座番号 (IBAN) |
| IPアドレス | インターネット プロトコル アドレス (IPv4 または IPv6) |
| 場所 | ロケーション |
| 名前 | ユーザーの名前 |
| 電話番号 | 電話番号 |
| 米国銀行番号 | 米国の銀行番号 |
| 米国運転免許証 | 米国の運転免許証 |
| "us_itin" | 米国の個人納税者識別番号 |
| 米国パスポート | アメリカ パスポート |
| 米国社会保障番号 (US SSN) | 米国社会保障番号 |