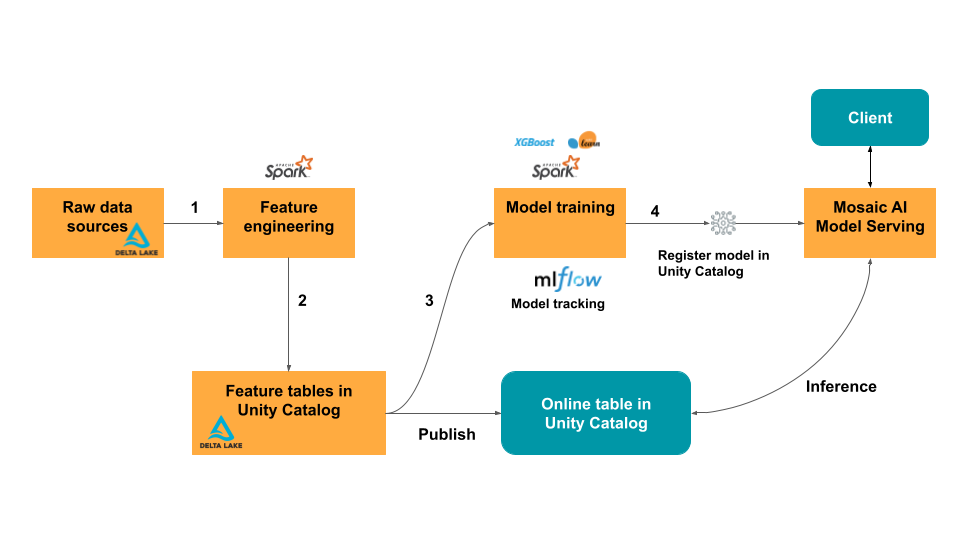
Databricks Feature Store を使用すると、モデル開発プロセスのすべてのステップが Databricks データ インテリジェンス プラットフォームに統合されます。 つまり、Databricks がインフラストラクチャを処理する間に、特徴量の計算と提供を行う自動化されたデータパイプラインを構築できます。 Databricks プラットフォームは、特徴量値のオンデマンド計算などのリアルタイム サービスを、特徴量とモデルの両方に対して提供します。
特徴の自動検索
Databricks Feature Store を使用してモデルをトレーニングし、Databricks Model Serving で提供すると、モデルは Databricks Online Feature Store または サード パーティのオンライン ストアから機能値を自動的に検索します。 これは自動的に行われ、セットアップの必要はありません。
Important
Databricks オンライン テーブルはサポートされなくなりました。 既存のオンライン テーブルがある場合は、Databricks Online Feature Store に移行することをお勧めします。 「レガシおよびサード パーティのオンライン テーブルからの移行」を参照してください。
モデルにスコアリング要求が送られてくると、Model Serving はモデルに必要な公開された特徴量の値を自動的に取得します。 この方法では、常に最新の特徴量値が予測に使われます。 詳細とノートブックの例については、「 自動機能検索を使用したモデル サービス」を参照してください。
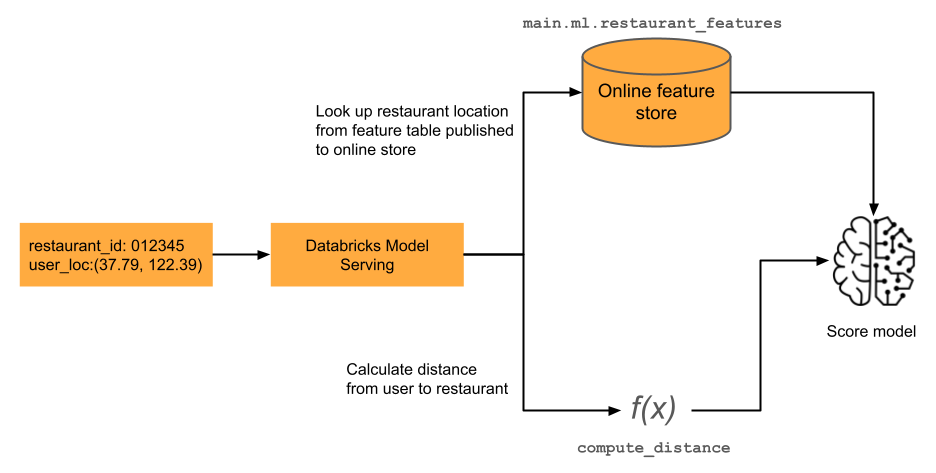
次の図は、リアルタイム提供のためのプラットフォーム コンポーネント間の関係を示したものです。
オンデマンド機能
リアルタイム アプリケーションの機械学習モデルでは、最新の特徴量の値が必要になることがよくあります。 図に示す例では、レストランのレコメンデーション モデルの 1 つの特徴は、レストランからのユーザーの現在の距離です。 この特徴量は、必要に応じて、つまりスコア要求時に計算する必要があります。 スコアリング要求を受け取ると、モデルはレストランの場所を検索し、定義済みの関数を適用して、ユーザーの現在の場所とレストランの間の距離を計算します。 この距離は、特徴量ストアの他の事前計算済み特徴量と共に、モデルへの入力として渡されます。 詳細については、オンデマンドで特徴量をコンピュートする方法に関する記事をご覧ください。