この記事では、特定の時点の正確性を使用して、ラベルの観測が記録された時点の特徴値を正確に反映するトレーニング データセットを作成する方法について説明します。 これは、 データ漏えいを防ぐために重要です。これは、ラベルが記録された時点では使用できなかったモデル トレーニングに特徴値を使用するときに発生します。 この種類のエラーは検出が困難であり、モデルのパフォーマンスに悪影響を及ぼす可能性があります。
** 時間系列特徴テーブルには、各行がそのタイムスタンプ時点での最新の既知の特徴値を表していることを保証するタイムスタンプキー列が含まれています。 時系列データ、イベント ベースのデータ、時間集計データなど、時系列の特徴値が時間と共に変化するときは常に、時系列特徴テーブルを使う必要があります。
次の図は、タイムスタンプ キーの使用方法を示しています。 各タイムスタンプに記録される特徴値は、そのタイムスタンプの前の最新の値であり、輪郭を描いたオレンジ色の円で示されます。 値が記録されていない場合、特徴値は null になります。 詳細については、「 時系列フィーチャ テーブルのしくみを参照してください。
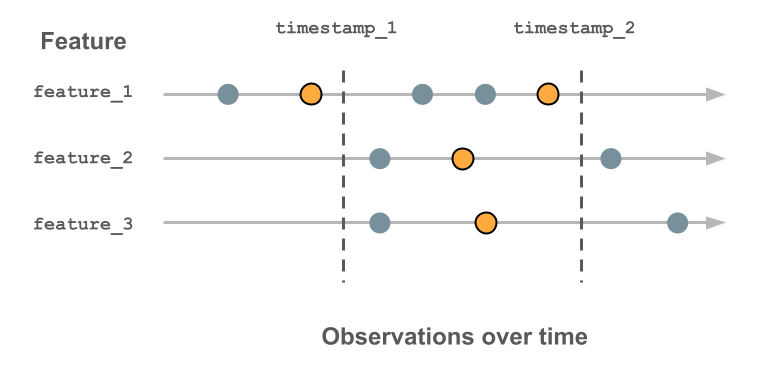
注
- Databricks Runtime 13.3 LTS 以降では、主キーとタイムスタンプ キーを持つ Unity Catalog 内のすべての Delta テーブルを時系列特徴量テーブルとして使用できます。
- ポイントインタイム ルックアップのパフォーマンスを向上させるため、Databricks では、時系列テーブルに Liquid Clustering (
databricks-feature-engineering0.6.0 以上の場合) または Z-Ordering (databricks-feature-engineering0.6.0 以下の場合) を適用することをお勧めします。 - ポイントインタイム ルックアップ機能は、"タイム トラベル" と呼ばれる場合があります。 Databricks Feature Store のポイントインタイム機能は、Delta Lake のタイム トラベルとは関連がありません。
時系列特徴テーブルのしくみ
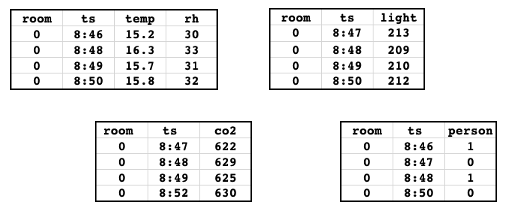
次の特徴テーブルがあるとします。 このデータは、ノートブックの例から取得されています。
テーブルには、室内の温度、相対湿度、環境光、二酸化炭素を測定するセンサー データが含まれています。 実測値テーブルは、人が部屋にいたかどうかを示しています。 各テーブルには、主キー ('room') とタイムスタンプ キー ('ts') があります。 わかりやすくするために、主キー ('0') の 1 つの値のデータのみが表示されます。
次の図は、タイムスタンプ キーを使用して、トレーニング データセット内の特定の時点の正確性を確保する方法を示しています。 特徴値は、AS OF 結合を使用して、主キー (図に示されていない) とタイムスタンプ キーに基づいて照合されます。 AS OF 結合を使用すると、タイムスタンプ時の特徴の最新の値がトレーニング セットで使用されるようになります。
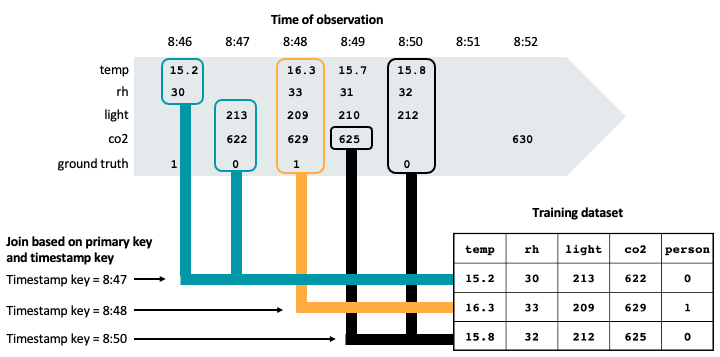
図に示すように、トレーニング データセットには、観測された実測値のタイムスタンプより前の各センサーの最新の特徴値が含まれています。
タイムスタンプ キーを考慮せずにトレーニング データセットを作成した場合は、次のような特徴値と観測された実測値の行が存在する可能性があります。
| 一時 (for temporary context) 臨時の労働者 or 派遣労働者 (for temporary worker context) | rh | 光 | co2 | 実測値 |
|---|---|---|---|---|
| 15.8 | 32 | 212 | 630 | 0 |
しかし、これはトレーニングに有効な観測値ではありません。630 という co2 読み取り値は 8 時 50 分に実測値が観測された後、8 時 52 分に取得されたためです。 将来のデータは、モデルのパフォーマンスを損なうトレーニング セットに "リーク" しています。
要件
- Unity Catalog の特徴エンジニアリングの場合: Unity Catalog の特徴エンジニアリング クライアント (任意のバージョン)。
- ワークスペース フィーチャー ストア (レガシ) の場合: Feature Store クライアント v0.3.7 以降。
時間関連のキーを指定する方法
ポイントインタイム機能を使用するには、timeseries_columns 引数 (Unity Catalog の Feature Engineering の場合) または timestamp_keys 引数 (ワークスペース Feature Store の場合) を使って、時間関連のキーを指定する必要があります。 これは、時間の正確な一致に基づいて結合するのではなく、timestamps_keys 列の値より後ではない特定の主キーの最新の値と一致させることによって、特徴テーブルの行を結合する必要があることを示します。
timeseries_columns または timestamp_keys を使っておらず、時系列の列のみを主キー列として指定した場合、Feature Store では結合中にポイントインタイム ロジックが時系列の列に適用されません。 代わりに、タイムスタンプより前のすべての行と一致させるのではなく、時刻が正確に一致する行のみと一致させます。
Unity Catalog で時系列特徴テーブルを作成する
Unity Catalog では、TIMESERIES 主キーを持つテーブルは、時系列特徴テーブルです。 作成方法については、「Unity Catalog で特徴テーブルを作成する」を参照してください。
ローカル ワークスペースで時系列特徴テーブルを作成する
ローカル Workspace Feature Store で時系列特徴量テーブルを作成するには、DataFrame またはスキーマはタイムスタンプ キーとして指定する列を含んでいる必要があります。
Feature Store クライアント v0.13.4 以降では、primary_keys 引数内でタイムスタンプ キー列を指定する必要があります。 タイムスタンプ キーは、特徴テーブルの各行を一意に識別する "主キー" の一部です。 他の主キー列と同様に、タイムスタンプ キー列に NULL 値を含めることはできません。
Unity Catalog の特徴エンジニアリング
fe = FeatureEngineeringClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.create_table(
name="ml.ads_team.user_features",
primary_keys=["user_id", "ts"],
timeseries_columns="ts",
features_df=user_features_df,
)
ワークスペース Feature Store クライアント v0.13.4 以降
fs = FeatureStoreClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.create_table(
name="ads_team.user_features",
primary_keys=["user_id", "ts"],
timestamp_keys="ts",
features_df=user_features_df,
)
ワークスペース Feature Store クライアント v0.13.3 以下
fs = FeatureStoreClient()
# user_features_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.create_table(
name="ads_team.user_features",
primary_keys="user_id",
timestamp_keys="ts",
features_df=user_features_df,
)
時系列機能テーブルには 1 つのタイムスタンプ キーが必要であり、パーティション列を含めることはできません。 タイムスタンプ キー列は TimestampType または DateType のものである必要があります。
Databricks では、パフォーマンスの高い書き込みと参照のために、時系列特徴テーブルに含める主キー列は 2 つ以下である必要があります。
時系列機能テーブルを更新する
時系列特徴テーブルに特徴を書き込む場合、DataFrame は、通常の特徴テーブルとは異なり、特徴テーブルのすべての特徴の値を指定する必要があります。 この制約により、時系列特徴テーブルのタイムスタンプ全体に特徴値が分散することを軽減できます。
Unity Catalog の特徴エンジニアリング
fe = FeatureEngineeringClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.write_table(
"ml.ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
ワークスペース Feature Store クライアント v0.13.4 以降
fs = FeatureStoreClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.write_table(
"ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
時系列機能テーブルへのストリーミング書き込みはサポートされています。
時系列特徴テーブルを使用してトレーニング セットを作成する
時系列フィーチャ テーブルからフィーチャ値のポイントインタイム ルックアップを実行するには、フィーチャのtimestamp_lookup_keyでFeatureLookupを指定する必要があります。これは、時系列フィーチャを参照するタイムスタンプを含む DataFrame 列の名前を示します。 Databricks Feature Store は、DataFrame の timestamp_lookup_key 列で指定されたタイムスタンプの前に最新の機能値を取得し、主キー (タイムスタンプ キーを除く) が DataFrame の lookup_key 列の値と一致するか、そのような機能値が存在しない場合は null します。
Unity Catalog の特徴エンジニアリング
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ml.ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fe.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
ヒント
Photon が有効になっているときにルックアップのパフォーマンスを向上させるには、use_spark_native_join=True を FeatureEngineeringClient.create_training_set に渡します。 これには、databricks-feature-engineering バージョン 0.6.0 以降が必要です。
ワークスペース Feature Store
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fs.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
時系列特徴テーブル上の FeatureLookup はポイントインタイム ルックアップである必要があります。そのため、DataFrame で使用する timestamp_lookup_key 列を指定する必要があります。 ポイントインタイム ルックアップでは、時系列特徴テーブルに格納されている null 特徴値を含む行はスキップされません。
古い特徴量値の制限時間を設定する
Feature Store クライアント v0.13.0 以降、または Unity Catalog の Feature Engineering クライアントの任意のバージョンでは、古いタイムスタンプの特徴量値をトレーニング セットから除外できます。 これを行うには、lookback_window の FeatureLookup パラメーターを使用します。
lookback_window のデータ型は datetime.timedelta である必要があり、既定値は None です (経過時間に関係なく、すべての特徴量値が使用されます)。
たとえば、次のコードでは、7 日を超える特徴量値は除外されます。
Unity Catalog の特徴エンジニアリング
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
ワークスペース Feature Store
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
上記の create_training_set で FeatureLookup を呼び出すと、ポイントインタイム結合が自動的に実行され、7 日より前の特徴量値は除外されます。
ルックバック ウィンドウは、トレーニングとバッチ推論中に適用されます。 オンライン推論中は、ルックバック ウィンドウに関係なく、常に最新の特徴量値が使用されます。
時系列特徴テーブルを使用してモデルをスコア付けする
時系列特徴テーブルの特徴を使用してトレーニングされたモデルをスコア付けすると、Databricks Feature Store は、トレーニング中にモデルと一緒にパッケージ化されたメタデータを使用して、特定の時点の参照を使用して適切な特徴を取得します。
FeatureEngineeringClient.score_batch (Unity Catalog のFeature Engineering の場合) または FeatureStoreClient.score_batch (ワークスペース Feature Store の場合) に指定する DataFrame には、DataType または timestamp_lookup_key に指定された FeatureLookup の FeatureEngineeringClient.create_training_set と同じ名前と FeatureStoreClient.create_training_set のタイムスタンプ列が含まれている必要があります。
ヒント
Photon が有効になっているときにルックアップのパフォーマンスを向上させるには、use_spark_native_join=True を FeatureEngineeringClient.score_batch に渡します。 これには、databricks-feature-engineering バージョン 0.6.0 以降が必要です。
時系列特徴をオンライン ストアに公開する
FeatureEngineeringClient.publish_table (Unity Catalog の Feature Engineering の場合) または FeatureStoreClient.publish_table (ワークスペース Feature Store の場合) を使用して、時系列特徴テーブルをオンライン ストアに公開できます。 Databricks Feature Store は、機能テーブル内の各主キーの最新の機能値のスナップショットをオンライン ストアに発行します。 オンライン ストアでは主キー参照がサポートされますが、ポイントインタイム ルックアップはサポートされていません。
ノートブックの例l: 時系列特徴テーブル
これらのサンプル ノートブックは、時系列特徴テーブルのポイントインタイム検索を示しています。
これらのノートブックをワークスペースで使用して、Unity Catalog を有効にします。
時系列特徴テーブルのノートブックの例 (Unity Catalog)
次のノートブックは、Unity Catalog が有効になっていないワークスペース向けに設計されています。 このノートブックは、ワークスペース特徴量ストアを使用します。